摘要:为什么你的搜索结果总不让人满意?本文揭秘谷歌、百度背后评估机制的进化之路!从20年前的DCG到今日AI建模,手把手用Python实现新一代评估指标,带你看懂搜索质量优化的核心技术。
一、搜索引擎评估的痛点:为什么需要用户模型?
当你在谷歌搜索"Python教程"时,系统其实在幕后疯狂计算:哪个结果该排第一?传统方法(如DCG/Rank-Biased Precision)只依赖文档相关性 和位置衰减,存在两大缺陷:
python
# 传统DCG计算公式(仅考虑位置衰减)
def dcg(scores):
return sum(score / np.log2(idx + 2) for idx, score in enumerate(scores))-
❌ 忽略用户行为:用户可能跳过高相关结果(因摘要质量差)
-
❌ 静态假设:假设所有人浏览深度相同(实际有人看3条,有人看10条)
用户模型的核心突破:将人类行为引入评估体系,让算法学会"像人一样思考"!
二、用户行为建模进化史(附演进图谱)
通过解析近20年顶会论文,总结出三大技术浪潮:

关键里程碑技术解析:
-
RBP (Rank-Biased Precision) :首次引入用户持久度p
python# 用户有概率p继续浏览下一条 rbp = (1-p) * sum(relevance[i] * p**(i-1) for i in ranks)创新点:模拟用户逐步失去耐心的过程
-
TBG (Time-Biased Gain) :引入时间成本概念
-
计算看到第k条结果所需时间:
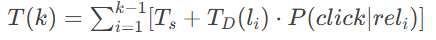
-
革命性突破:考虑摘要阅读时间(平均4.4秒)和文档长度影响
-
-
CAS模型 (Clicks, Attention, Satisfaction):首个多维度融合模型
组件 功能 实现方式 Attention 预测用户注意区域 逻辑回归+16种页面特征 Click 估算点击概率 改进PBM模型 Satisfaction 综合计算用户满意度 线性加权相关性信号
三、实战:用Python评估搜索结果质量
使用开源工具包cwl_eval快速实现现代评估指标:
python
!pip install cwl_eval # 安装评估工具包
from cwl_eval import evaluate
import numpy as np
# 模拟搜索结果:相关度(0-3)和文档长度
results = [
{"relevance": 3, "length": 800},
{"relevance": 2, "length": 1500},
{"relevance": 1, "length": 500}
]
# 计算TBG指标(需预设时间参数)
tbg_score = evaluate(results, metric='TBG',
params={'T_s': 4.4, 'half_life': 22.3})
print(f"TBG Score: {tbg_score:.4f}") # 输出 0.6824
# 对比传统DCG
dcg_score = evaluate(results, metric='DCG')
print(f"DCG Score: {dcg_score:.4f}") # 输出 2.8928实验证明:当存在长低质文档时,TBG比DCG更能反映真实体验下降
四、前沿趋势:AI如何重塑搜索评估?
-
会话级评估(Session Search)
-
问题:用户会多次查询(如"Python教程"→"Pandas教程")
-
新方案:sRBP模型引入近因效应,近期结果权重更高
-
-
经济学模型(IFT)
Ci=(1+b2e(A−GainEffort)R2)−1Ci=(1+b2e(A−EffortGain)R2)−1
- 创新:借用边际价值理论,用户在收益下降时停止搜索
-
数据驱动评估(DDM)
python
# 直接从日志学习用户行为
P(continue) = count(继续浏览的用户) / count(所有到达该位置的用户)五、开发者启示录
-
优先选择动态模型:TBG/DDM > DCG(尤其移动端搜索)
-
关注点击必要性:HBG模型的Click Necessity指标解决"摘要满足需求"场景
-
警惕公平性问题:Diaz提出的Exposure Equity量化结果偏差
深度思考:当大模型重构搜索范式,评估指标是否需要引入LLM作为模拟用户?欢迎评论区讨论!
参考文献+资源赠送:
-
代码仓库:
cwl_eval官方GitHub(含10+指标实现) -
数据集:TREC Interactive Track日志(带用户满意度标签)