背景
在跨系统之间的数据写入场景下,上下游系统极有可能因为网络超时/抖动、或写本地DB与调外部接口不能同时成功等原因,而出现数据不一致的问题,因此需要有及时发现不一致问题、并自动修复的能力。下面结合笔者的经验,把对账做个总结。
需要注意的是,这里提的对账不特指资金对账,而是跨系统的字段对账,如B端与C端系统之间的对账。
对账的指标
判断对账是否做得好,主要看这几个指标:
- 完备性:确保所有字段都有对账
- 时效性:越高越好,秒级 > 分钟级 > 小时级 > 天级
- 自动修复:对账发现不一致后自动修复,然后再次对账,确保修复后是最终一致的,形成闭环
下面分别介绍一下实时对账、离线对账,最好是两个都做。
1. 实时对账(秒级到分钟级对账)
实时对账可以尽快发现不一致,一般由数据写入方发起对账,数据接收方提供对账查询接口(例如查从库)。
触发方式分2种:
- (不推荐)数据库变更事件触发:监听业务主表的binlog变更
- (推荐)业务消息触发:监听业务消息变更
推荐由业务消息触发,是因为数据库变更事件触发有局限:
- 如果有的写入操作不更新业务主表,比如只更新了扩展表,则需要新消费扩展表的binlog事件消息。
- 如果存在中间状态,则需要等到记录变成终态后才能对账,需要过滤很多无效消息。
实现方案:
- 监听业务消息变更。业务消息需做成事务消息,即业务操作完成必发出、不完成不发出。业务消息可以携带多个表的信息,能减少一定的查DB请求。
- 延迟、批量消费变更消息,然后批量查询本地DB数据、以及上下游接口。
- 最后逐个字段做比较。
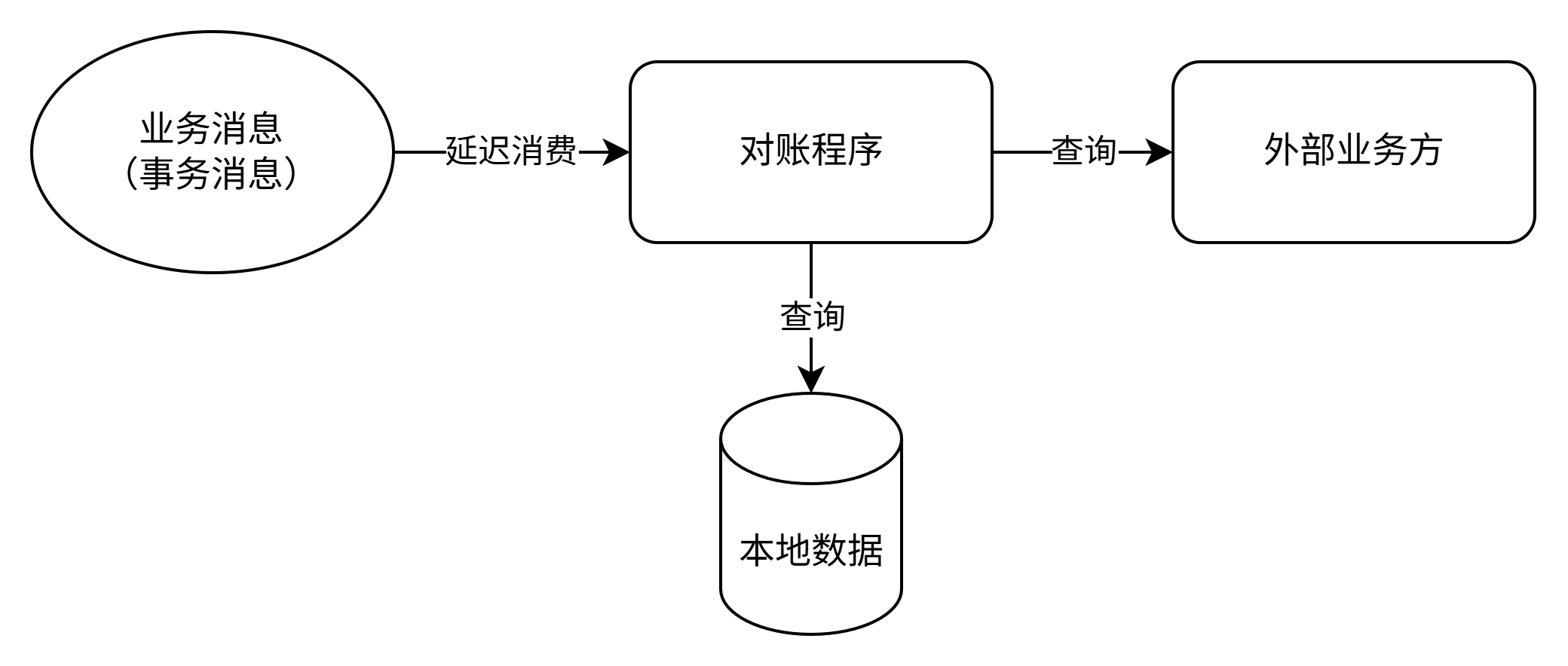
之所以要写入方发起对账,而不是接收方,是因为写入方调接收方的接口可能失败,接收方在写入失败时无法触发对账。
之所以要延迟消费,是为了避免短时间内的不一致造成误告警(例如数据库主从延迟、接口超时重试等原因),比如延迟15秒再消费。
之所以要积攒一批消息做批量消费,是为了避免对账查询qps过高,给本服务和上下游系统带来较大负载。
2. 离线对账(小时级到天级对账)
有了在线对账,为什么还需要离线对账呢?
- 离线对账作为在线对账的兜底,可以定期跑历史存量数据
- 离线对账不影响在线业务的稳定性
- 外部第三方系统,一般只能定期提供离线数据,无法提供对账查询接口。典型的如第三方支付系统的对账单
实现方案:
- 离线采集:导出各系统的数据到hive表,可以是mysql表、或者是对账单
- 归一化数据:解析出所有的对账字段,按统一格式生成新的宽表a、宽表b
- 离线对比:
(1)需要比较条数是否一致
(2)以及数据内容是否一致:通过左连接找到只存在于左表的数据,通过右连接找到只存在于右表的数据,通过内连接并比较各个字段来找到存在差异的数据
下面看sql例子。
sql
-- (1)比较两个表的条数是否一致
select count(1) from table_a; -- 查出左表的条数
select count(1) from table_b; -- 查出右表的条数
-- (2)比较数据内容是否一致
-- (2.1)只存在于左表的数据:左连接查询,左表记录都会保留,右表字段为空则说明右表缺少数据:
select * from
table_a left outer join table_b
on table_a.biz_field=table_b.biz_field
where table_b.biz_field is null;
-- (2.2)只存在于右表的数据:右连接查询,右表记录都会保留,左表字段为空则说明左表缺少数据:
select * from
table_a right outer join table_b
on table_a.biz_field=table_b.biz_field
where table_a.biz_field is null;
-- (2.3)两个表存在差异的数据,内连接查询,比对各个字段是否一致:
select * from
table_a inner join table_b
on table_a.biz_field=table_b.biz_field
where
(table_a.field_1 <> table_b.field_1
or table_a.field_2 <> table_b.field_2
or table_a.field_3 <> table_b.field_3);3. 自动修复
一般是写入方发现不一致后,需要做自动修复。流程如下:
- 记录差异,供后续定位排查
- 自动修复
- 修复后再次对账,确保数据最终一致
结论
实时对账和离线对账,互为补充、缺一不可。新需求除了保证功能正确性,还要同时做好对账,避免有不一致问题时发现不了,或很久才发现。
对账发现不一致后自动修复,能保证系统的最终一致性。