如今,大规模机器学习和深度学习模型正变得越来越普遍,最典型的例子就是 GPT-3------ 它的训练基于足足 570GB 的文本数据,模型内部包含的参数更是多达 1750 亿个。这样的规模意味着模型能够从海量数据中学习到更丰富的模式,从而在很多任务上达到顶尖性能。但凡事有利有弊,训练出这样的大型模型固然能推高性能上限,可真要把它们用起来,尤其是部署到手机、智能手表、工业传感器这些边缘设备上时,麻烦就来了。这些设备往往算力有限、内存不大,还可能受限于电池容量,根本撑不起大型模型的运行需求,光是加载模型可能就要花上好几秒,更别说实时处理数据了。
除此之外,现在大多数数据科学领域的建模工作,其实都有个隐藏的问题:大家花大量精力训练单个超大模型,或者把好几个不同模型凑成一个集合,目标都是让它们在一个专门划分出来的验证集上表现出色。但问题是,这个验证集往往是经过精心挑选的,数据分布相对规整,甚至可能和真实世界里乱糟糟的数据完全不是一回事。
这种训练时的目标(在验证集上刷高分)和实际测试时的需求(在真实数据上好用)之间的错位,直接导致了很多尴尬的结果:模型在实验室的验证集上准确率高得喜人,可一旦拿到真实场景中去做推理 ------ 比如在医院的监护设备上实时分析生理数据,或者在工厂的传感器上识别设备异常 ------ 就常常掉链子。要么是处理速度太慢,延迟高到影响决策;要么是吞吐量跟不上,没办法同时处理多个数据请求,根本达不到实际应用的性能标准。
而知识提炼这项技术,正是为了解决这些难题而生的。简单来说,它能把那些复杂的机器学习模型(或者好几个模型凑成的集合)里蕴含的 "知识" 给提取出来,再 "压缩" 到一个更小的单一模型里。这里的 "知识" 可能包括模型对特征的理解、决策时的逻辑倾向,甚至是对不同结果的概率判断等。通过这样的提炼,得到的小模型不仅保留了原模型的大部分性能,还变得更轻巧、更容易部署,尤其适合那些资源受限的边缘设备。
在这篇博客里,我会把知识提炼的来龙去脉讲清楚:从它的基本原理是什么,到具体有哪些训练方案和算法;再深入到实际应用中,看看它在图像识别、文本处理、音频分析这些深度学习的重要领域里,是怎么发挥作用的。
什么是知识提炼?
知识提炼是指将知识从一个庞大而笨重的模型或模型集迁移到一个可在实际约束条件下实际部署的小型模型的过程。本质上,它是一种模型压缩形式,由 Bucilua 及其同事于 2006 年首次成功演示 。
知识蒸馏更常用于包含多层和多个模型参数的复杂架构的神经网络模型。因此,随着近十年深度学习的出现及其在语音识别、图像识别和自然语言处理等多个领域的成功,知识蒸馏技术在实际应用中日益受到重视 。
对于内存和计算能力有限的边缘设备而言,部署大型深度神经网络模型的挑战尤为突出。为了应对这一挑战,一种模型压缩方法首次被提出,旨在将大型模型中的知识迁移到训练小型模型中,且性能不会受到显著损失。这种从大型模型中学习小型模型的过程被 Hinton 等人正式定义为"知识蒸馏"框架。
如图 1 所示,在知识蒸馏中,一个小的"学生"模型学习模仿一个大的"老师"模型,并利用老师的知识来获得相似甚至更高的准确率。在下一节中,我将深入探讨知识蒸馏框架及其底层架构和机制。
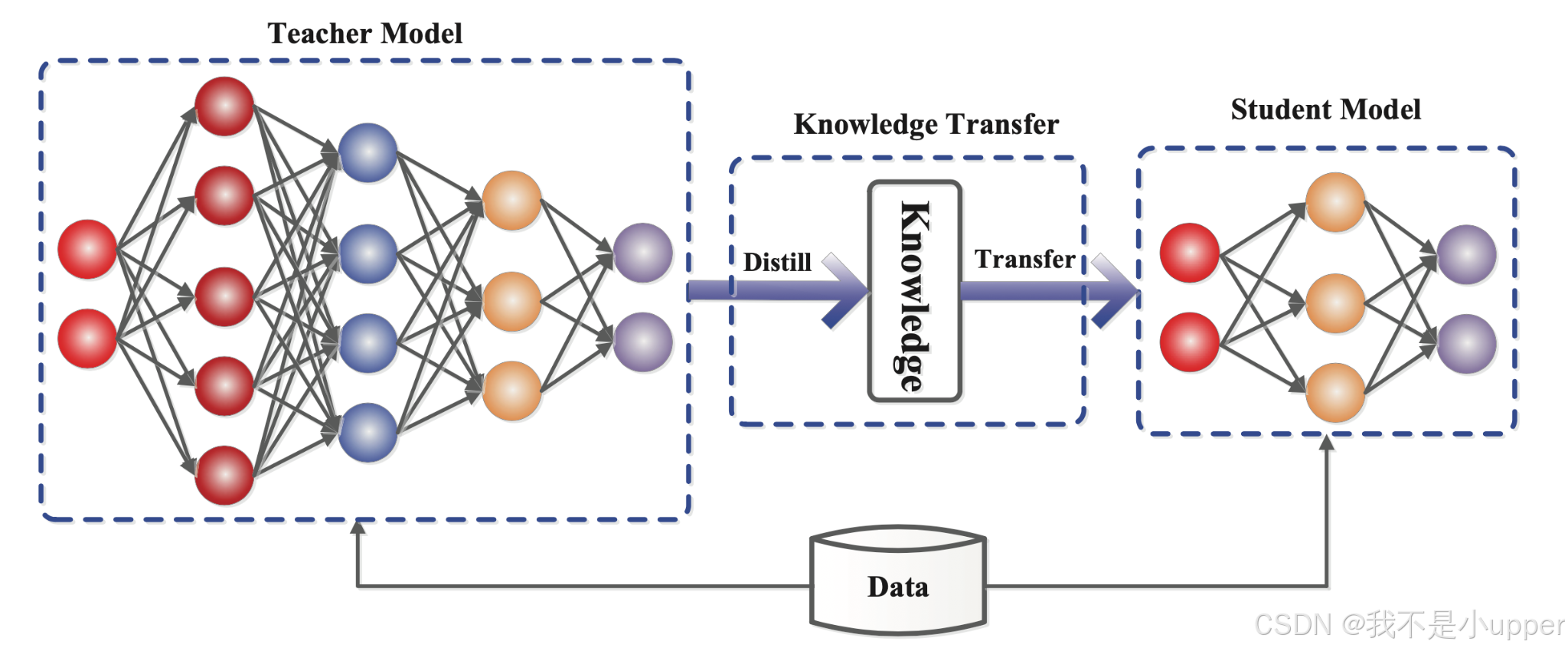
图 1. 知识提炼的师生框架 | 来源:Arxiv
深入探究知识提炼
知识蒸馏系统由三个主要组成部分组成:知识、蒸馏算法和师生架构。
知识
在神经网络中,知识通常指的是学习到的权重和偏差。同时,大型深度神经网络中的知识来源也极其丰富多样。典型的知识蒸馏使用对数函数作为教师知识的来源,而其他一些知识蒸馏则侧重于中间层的权重或激活函数。其他相关知识包括不同类型的激活函数与神经元之间的关系,或教师模型本身的参数。
不同形式的知识分为三种:基于响应的知识 、基于特征的知识 和基于关系的知识 。图 2 展示了教师模型中这三种不同类型的知识。我将在下一节中详细讨论每种不同的知识来源。
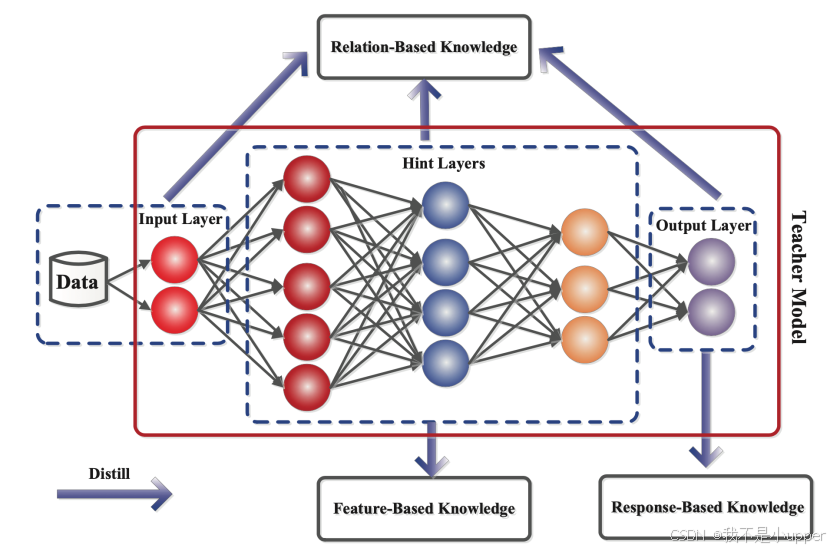
图 2. 教师模型中的不同知识类型 | 来源:Arxiv
1.基于响应的知识
如图 2 所示,基于响应的知识侧重于教师模型的最终输出层。假设学生模型将学习模仿教师模型的预测。如图 3 所示,这可以通过使用称为蒸馏损失的损失函数来实现,该损失函数分别捕捉学生模型和教师模型的对数函数之间的差异。随着这种损失在训练过程中最小化,学生模型将能够更好地做出与教师模型相同的预测。
在图像分类等计算机视觉任务中,软目标包含基于响应的知识。软目标表示输出类别的概率分布,通常使用softmax函数进行估算。每个软目标对知识的贡献都通过一个称为"温度"的参数进行调节。基于软目标的响应式知识提炼通常用于监督学习。
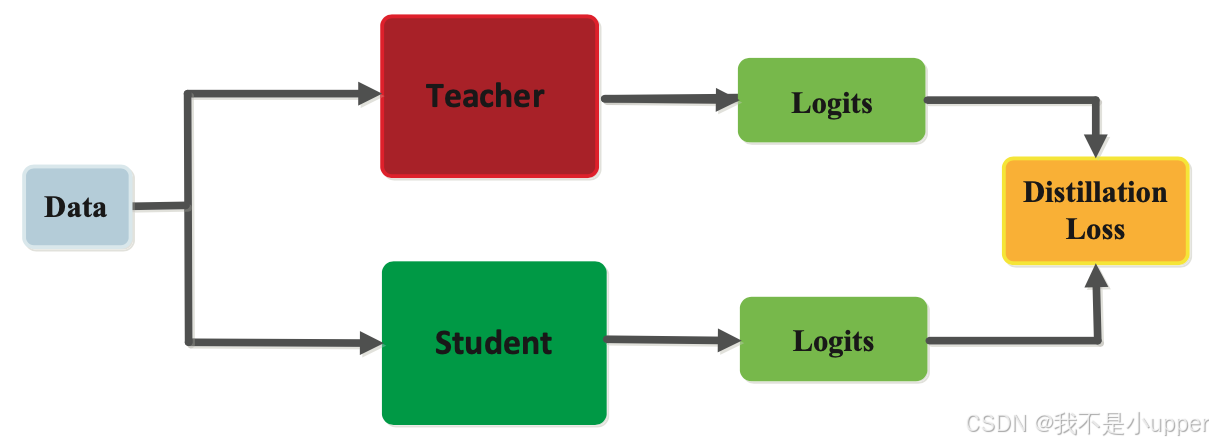
图 3. 基于响应的知识提炼 | 来源:Arxiv
2.基于特征的知识
经过训练的教师模型还能捕获中间层数据的知识,这对于深度神经网络尤为重要。中间层学习区分特定特征,这些知识可用于训练学生模型。如图 4 所示,目标是训练学生模型学习与教师模型相同的特征激活。蒸馏损失函数通过最小化教师模型和学生模型的特征激活之间的差异来实现这一点。
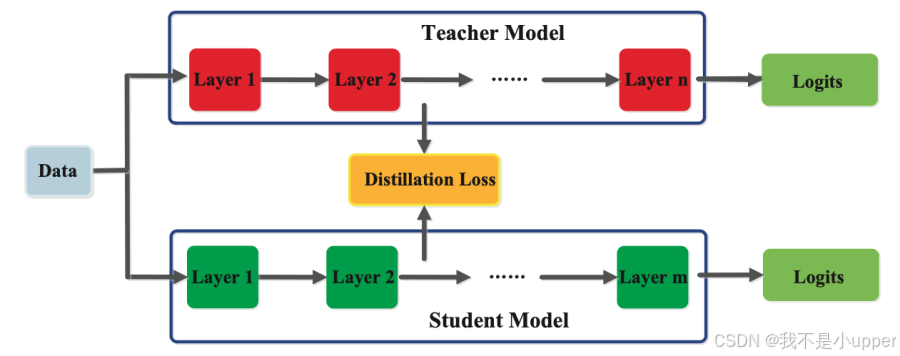
图 4. 基于特征的知识提炼 | 来源:Arxiv
3.基于关系的知识
除了神经网络输出层和中间层所表示的知识之外,捕捉特征图之间关系的知识也可用于训练学生模型。这种形式的知识被称为基于关系的知识,如图 5 所示。这种关系可以建模为特征图、图、相似度矩阵、特征嵌入或基于特征表示的概率分布之间的相关性。
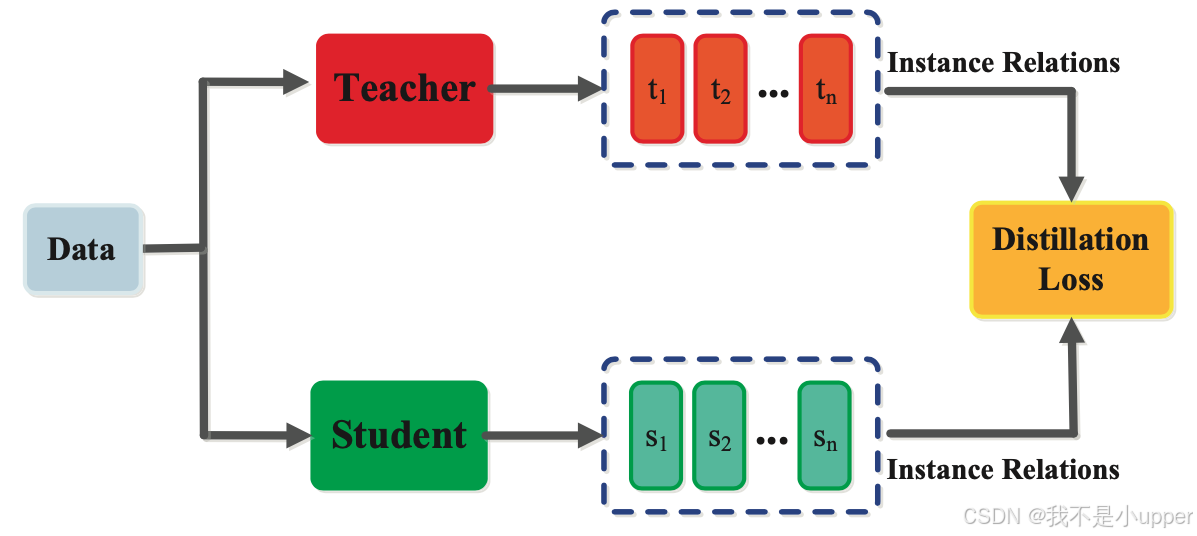
图 5. 基于关系的知识提炼 | 来源:Arxiv
训练
训练学生和教师模型的方法主要有三种:离线、在线和自我蒸馏。蒸馏训练方法的分类取决于教师模型是否与学生模型同时修改,如图 6 所示。
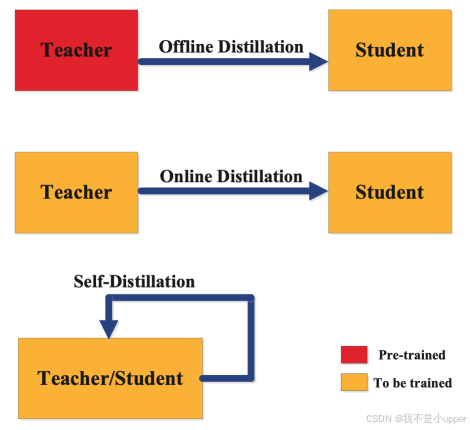
图 6. 知识蒸馏训练方案的类型 | 来源:Arxiv
1. 离线蒸馏
离线知识蒸馏是最常用的方法,其中使用预先训练好的教师模型来指导学生模型。在此方案中,教师模型首先在训练数据集上进行预训练,然后从教师模型中提炼知识来训练学生模型。鉴于深度学习的最新进展,各种预先训练好的神经网络模型已经公开可用,可以根据用例充当教师模型。离线知识蒸馏是深度学习中一项成熟的技术,并且更易于实现。
2. 在线蒸馏
在离线蒸馏中,预训练的教师模型通常是一个大容量的深度神经网络。在某些用例中,预训练模型可能无法用于离线蒸馏。为了解决这一限制,可以使用在线蒸馏,在单个端到端训练过程中同时更新教师模型和学生模型。在线蒸馏可以通过并行计算实现,因此是一种高效的方法。
3. 自蒸馏
如图 6 所示,在自蒸馏中,教师模型和学生模型使用相同的模型。例如,深度神经网络较深层的知识可以用来训练浅层。这可以被视为在线蒸馏的一个特例,并以多种方式实例化。教师模型早期迭代中积累的知识可以迁移到后期迭代中,用于训练学生模型。
架构|Architecture
师生网络架构的设计对于高效的知识获取和提炼至关重要。通常,较复杂的教师模型与较简单的学生模型之间存在模型容量差距。通过优化高效的师生网络架构,可以缩小这种结构性差距,从而优化知识迁移。
由于深度神经网络的深度和广度,从深度神经网络迁移知识并非易事。最常见的知识迁移架构包括一个学生模型,该模型具有以下特点:
- 教师模型的浅层版本,层数更少,每层的神经元也更少,
- 教师模型的量化版本,
- 规模较小、基本运行高效的网络,
- 具有优化的全局网络架构的小型网络,
- 和老师一样的模特。
除了上述方法之外,还可以利用神经架构搜索等最新进展,根据特定的教师模型设计最佳的学生模型架构。
知识提炼算法
在本节中,我将重点介绍训练学生模型从教师模型中获取知识的算法。
1. 对抗性蒸馏
对抗性学习是最近在生成对抗网络背景下提出的概念,用于训练生成器模型和鉴别器模型,生成器模型学习生成尽可能接近真实数据分布的合成数据样本,鉴别器模型学习区分真实数据样本和合成数据样本。这一概念已应用于知识提炼,使学生模型和教师模型能够学习到更好地表征真实数据分布的方法。
为了达到学习真实数据分布的目标,对抗学习可以用来训练生成器模型,以获得合成的训练数据,用于直接使用或扩充原始训练数据集。第二种基于对抗学习的蒸馏方法侧重于判别器模型,该模型基于对数或特征图区分来自学生模型和教师模型的样本。这种方法可以帮助学生更好地模仿教师模型。第三种基于对抗学习的蒸馏技术侧重于在线蒸馏,其中学生模型和教师模型进行联合优化。
2. 多教师提炼
在多教师提炼中,学生模型从几个不同的教师模型中获取知识,如图 7 所示。使用教师模型集合可以为学生模型提供不同类型的知识,这些知识比从单个教师模型获取的知识更有益。
来自多位教师的知识可以合并为所有模型的平均响应。通常从教师迁移的知识类型基于对数变换和特征表示。如第 2.1 节所述,多位教师可以迁移不同类型的知识。
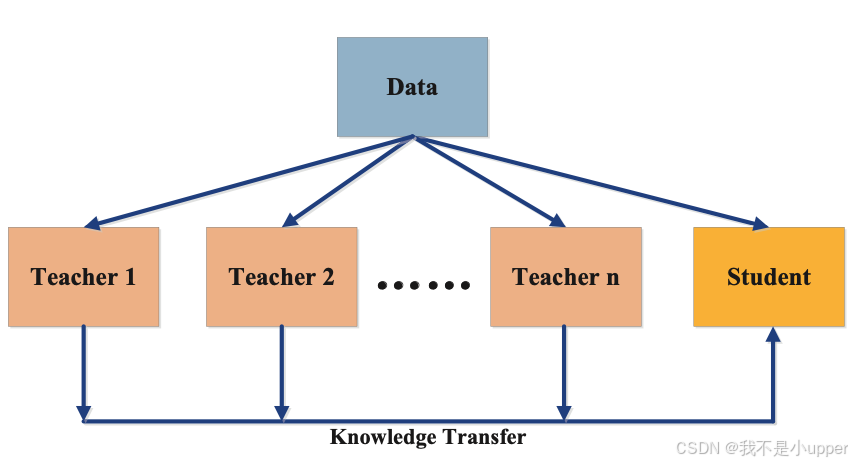
图 7. 多教师模型提炼 | 来源:Arxiv
3. 跨模式蒸馏
图 8 展示了跨模态知识提炼训练方案。在这里,教师模型接受一种模态的训练,并将其知识提炼到需要不同模态知识的学生模型中。这种情况发生在训练或测试期间特定模态的数据或标签不可用时,因此需要跨模态进行知识迁移。
跨模态模型蒸馏在视觉领域应用最为广泛。例如,教师模型在带标签的图像数据上训练的知识,可以用于学生模型的模型蒸馏,该模型的输入域可以是光流、文本或音频等未带标签的领域。在这种情况下,从教师模型的图像中学习到的特征将用于学生模型的监督训练。跨模态模型蒸馏在视觉问答、图像字幕等应用中非常有用。
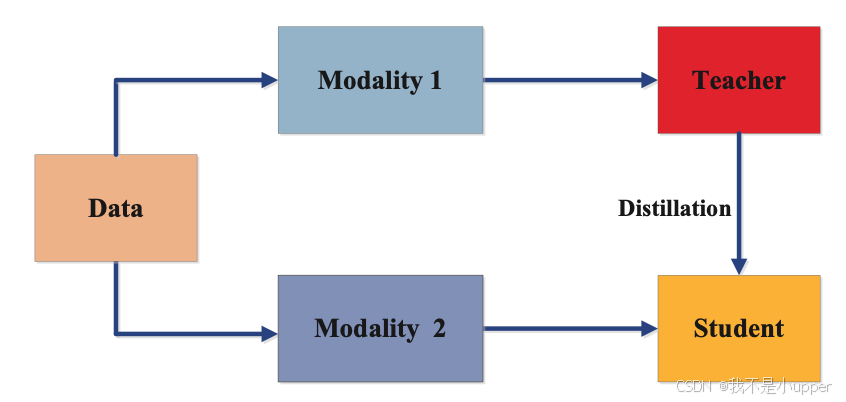
图 8. 跨模态蒸馏 | 来源:Arxiv
4. 其他
除了上面讨论的蒸馏算法之外,还有其他几种算法已被应用于知识蒸馏。
- 基于图的蒸馏使用图来捕捉数据内部关系,而不是将单个实例知识从教师传递到学生。图的用途有两种:作为知识转移的手段,以及控制教师知识的转移。在基于图的蒸馏中,图的每个顶点代表一个自监督教师,它可以基于基于响应的知识,也可以基于基于特征的知识,例如逻辑回归和特征图。
- 基于注意力的蒸馏是基于使用注意力图从特征嵌入中传输知识。
- 无数据蒸馏是基于合成数据,由于隐私、安全或保密原因,在没有训练数据集的情况下进行。合成数据通常由预先训练好的教师模型的特征表示生成。在其他应用中,GAN 也用于生成合成训练数据。
- 量化蒸馏用于将知识从高精度教师模型(例如 32 位浮点)迁移到低精度学生网络(例如 8 位)。
- 终身提炼基于持续学习、终身学习和元学习的学习机制,其中先前学到的知识被积累并转移到未来的学习中。
- 基于神经架构搜索的提炼用于识别合适的学生模型架构,以优化从教师模型的学习。
知识提炼的应用
知识蒸馏已成功应用于图像识别、自然语言处理和语音识别等多种机器学习和深度学习用例。在本节中,我将重点介绍知识蒸馏技术的现有应用及其未来潜力。
1. 愿景
知识蒸馏在计算机视觉领域应用广泛。最先进的计算机视觉模型越来越多地基于深度神经网络,而深度神经网络可以从模型压缩中获益,便于部署。知识蒸馏已成功应用于以下用例:
- 图像分类,
- 人脸识别
- 图像分割,
- 动作识别,
- 物体检测,
- 车道检测,
- 行人检测,
- 面部特征点检测,
- 姿态估计,
- 视频字幕,
- 图像检索,
- 阴影检测,
- 文本到图像合成,
- 视频分类,
- 视觉问答等。
知识蒸馏也可用于跨分辨率人脸识别等小众用例,其中基于高分辨率人脸教师模型和低分辨率人脸学生模型的架构可以提升模型性能并降低延迟。由于知识蒸馏可以利用不同类型的知识,包括跨模态数据、多领域数据、多任务数据和低分辨率数据,因此可以针对特定的视觉识别用例训练各种经过蒸馏的学生模型。
2. 自然语言处理
鉴于语言模型或翻译模型等大容量深度神经网络的普及,知识蒸馏在自然语言处理 (NLP) 应用中的应用尤为重要。最先进的语言模型包含数十亿个参数,例如 GPT-3 包含 1750 亿个参数。这比之前最先进的语言模型 BERT(基础版本包含 1.1 亿个参数)高出几个数量级。
因此,知识蒸馏在自然语言处理 (NLP) 中非常流行,它可以获得快速、轻量级的模型,这些模型更容易训练,计算成本也更低。除了语言建模之外,知识蒸馏还用于以下 NLP 用例:
- 神经机器翻译,
- 文本生成,
- 问答
- 文档检索,
- 文本识别。
通过知识提炼,可以构建高效轻量级的自然语言处理模型,从而降低内存和计算需求。师生训练也可用于解决多语言自然语言处理问题,实现多语言模型知识的迁移和共享。
案例研究:DistilBERT
DistilBERT是由 Hugging Face 开发的更小、更快、更便宜、更轻量的 BERT 模型。在此,作者预训练了一个较小的 BERT 模型,该模型可以在各种 NLP 任务上进行微调,并具有相当高的准确率。在预训练阶段应用了知识蒸馏,以获得蒸馏版的 BERT 模型,该模型小了 40%(6600 万个参数 vs. 1.1 亿个参数),速度提高了 60%(在 GLUE 情感分析任务上的推理时间为 410 秒 vs. 668 秒),同时保持了相当于原始 BERT 模型准确率 97% 的模型性能。在 DistilBERT 中,学生模型具有与 BERT 相同的架构,并使用了一种新颖的三元组损失函数获得,该损失函数结合了与语言建模、蒸馏和余弦距离损失相关的损失。
3. 演讲
最先进的语音识别模型也基于深度神经网络。现代 ASR 模型采用端到端训练,并基于包含卷积层、带注意力机制的序列到序列模型以及近期推出的 Transformer 等架构。对于实时设备端语音识别而言,获得更小、更快的模型以实现高效性能至关重要。
知识提炼在语音中有以下几种用例:
- 语音识别,
- 口语识别,
- 音频分类,
- 说话人识别,
- 声音事件检测,
- 语音合成,
- 语音增强,
- 抗噪ASR,
- 多语言ASR,
- 口音检测10。
案例研究:Amazon Alexa 的声学建模
Parthasarathi 和 Strom (2019) 利用学生-教师训练,为 100 万小时的未标记语音数据生成软目标,其中训练数据集仅包含 7000 小时的标记语音。教师模型生成了所有输出类别的概率分布。学生模型也生成了给定相同特征向量的输出类别的概率分布,并且目标函数优化了这两个分布之间的交叉熵损失。在这里,知识蒸馏有助于简化在大型语音数据语料库上生成目标标签的过程。
结论
现代深度学习应用基于庞大的神经网络,这些神经网络容量大、内存占用高、推理延迟慢。将此类模型部署到生产环境中是一项巨大的挑战。知识蒸馏是一种优雅的机制,可以从庞大复杂的教师模型中训练出更小、更轻量、更快、更经济的学生模型。自 Hinton 及其同事 (2015) 提出知识蒸馏的概念以来,人们越来越多地采用知识蒸馏方案来获取高效轻量级的生产用例模型。知识蒸馏是一项复杂的技术,基于不同类型的知识、训练方案、架构和算法。知识蒸馏已在计算机视觉、自然语言处理、语音等多个领域取得了巨大成功。