环境与版本
-
win10,Python 3.13.7
-
库版本
crewai1.5.0
crewai-tools1.5.0langchain-classic1.0.0
langchain-community0.4.1langchain-core1.0.5
langchain-openai1.0.3langchain-text-splitters==1.0.0
-
llama.cpp 下载最新win版本
测试代码
python
# test_crewai_minimal.py
import os
from langchain_openai import ChatOpenAI
from crewai import Agent, Task, Crew
from langchain_core.globals import set_debug
set_debug(True)
os.environ["OPENAI_API_BASE"] = "http://127.0.0.1:8080/v1"
os.environ["OPENAI_API_KEY"] = "not-needed"
local_llm = ChatOpenAI(
model_name="local-model",
openai_api_base="http://127.0.0.1:8080/v1",
openai_api_key="not-needed",
temperature=0.7,
request_timeout=30,
)
# 3. 创建一个简单的 Agent,并显式指定 LLM
general_agent = Agent(
role='Simple Agent',
goal='Just answer a simple question',
backstory='You are a helpful assistant.',
verbose=True,
llm=local_llm # <--- 显式指定
)
# 4. 创建一个简单的 Task
simple_task = Task(
description="What is the capital of France? Just give the name of the city.",
expected_output="The name of the city.",
agent=general_agent
)
# 5. 创建 Crew 并执行
crew = Crew(
agents=[general_agent],
tasks=[simple_task],
verbose=True
)
print("Starting the minimal CrewAI test...")
result = crew.kickoff()
print("\n--- Final Result ---")
print(result)llama.cpp运行命令:
powershell
llama-server -m e:\llama\Qwen3VL-8B-Instruct-Q4_K_M.gguf --no-mmproj-offload --no-warmup --jinja -t 8 -c 4096 -b 1没有GPU显卡,纯CPU。
正常结果:
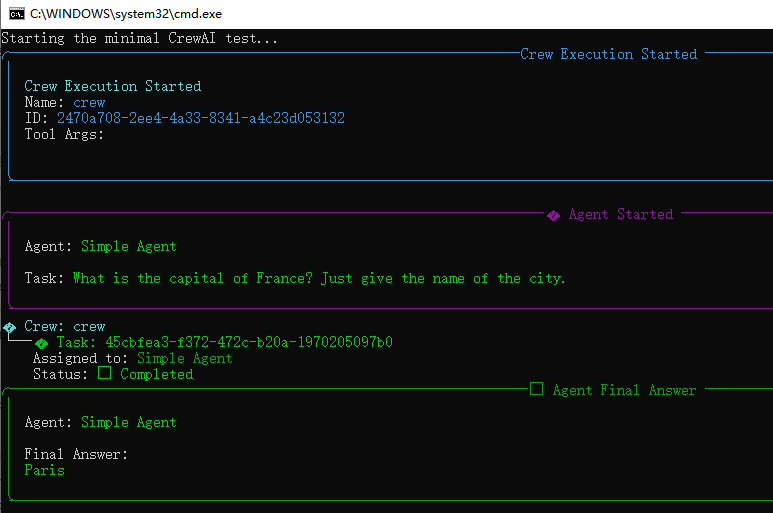
llama.cpp后端会有请求和相应:

修改ompletion.py
路径:D:\Python\Lib\site-packages\crewai\llms\providers\openai\completion.py
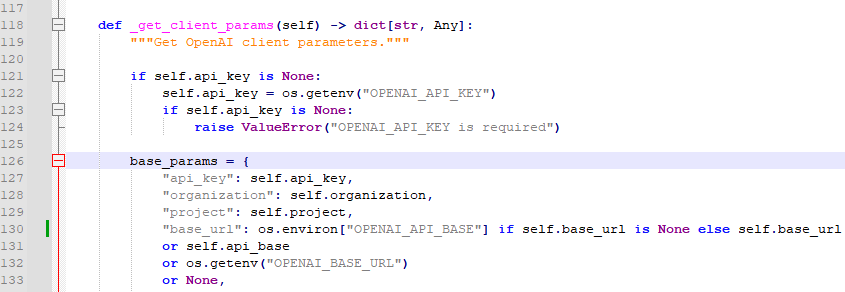
python
"base_url": os.environ["OPENAI_API_BASE"] if self.base_url is None else self.base_url