
一、DAG
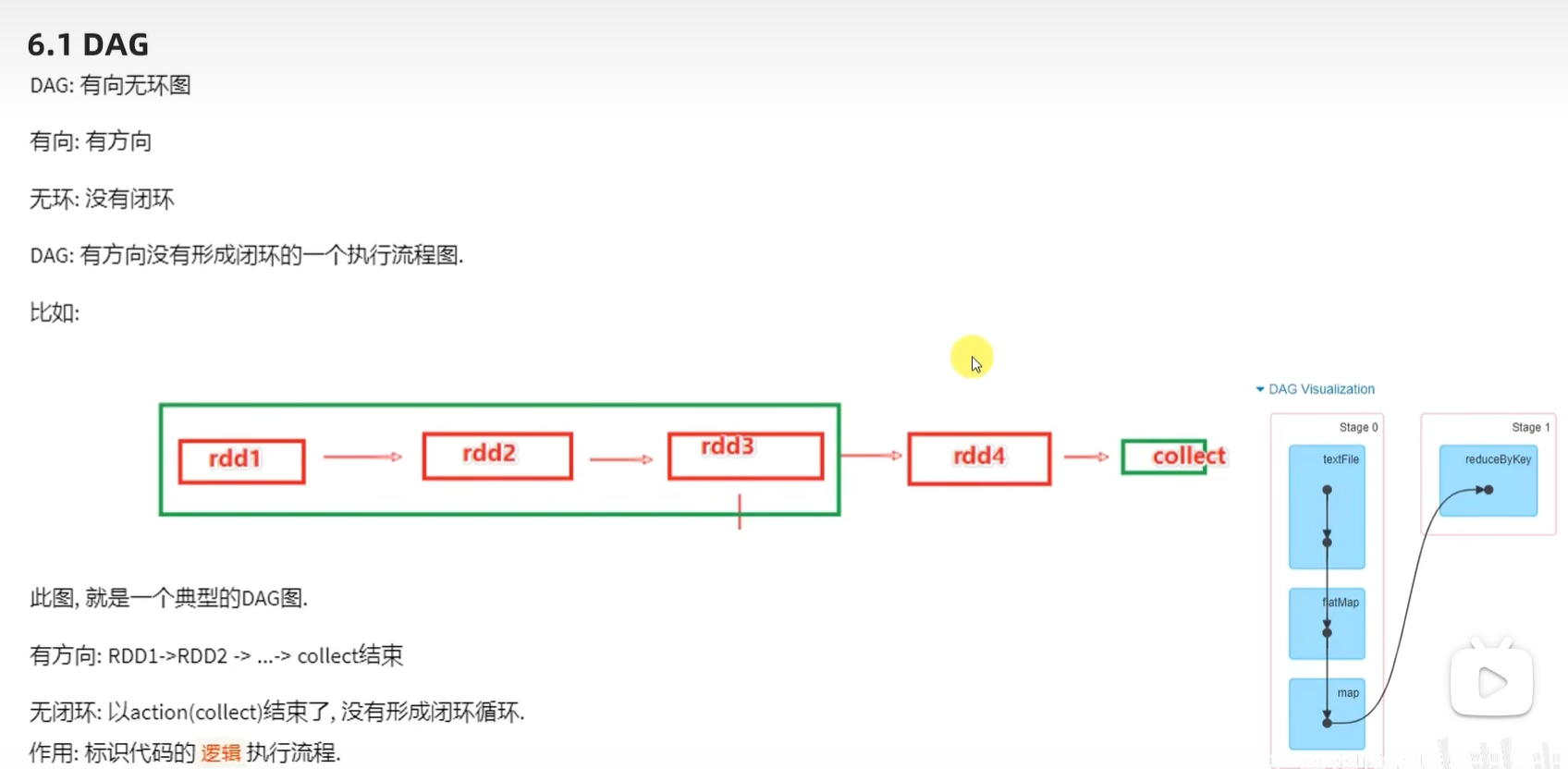
DAG的方向其实就是代码的实现流程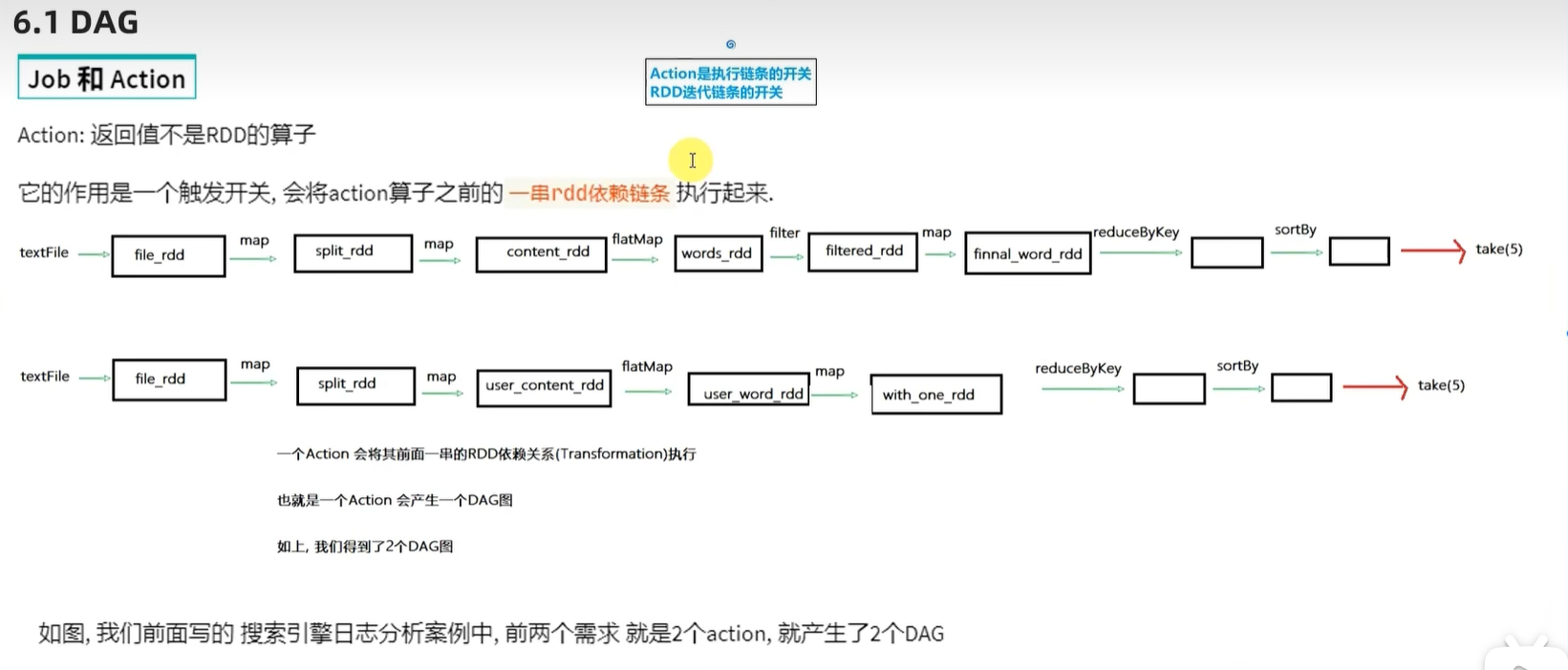
演示代码
# coding:utf8
# 导入Spark的相关包
from pyspark import SparkConf,SparkContext
from pyspark.storagelevel import StorageLevel
from defs import context_jieba,filter_words,append_words,extract_user_and_word
from operator import add
import time
if __name__ == "__main__":
# 0.初始化执行环境,构建SparkContext对象
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
# 1.读取数据文件
file_rdd = sc.textFile("hdfs://node1:8020/input/SogouQ.txt")
# 2.对数据进行切分\t
split_rdd = file_rdd.map(lambda x:x.split("\t"))
# 3.因为要做多个需求,split_rdd作为基础的rdd,会被多次使用
split_rdd.persist(StorageLevel.DISK_ONLY)
# TODO:需求1:用户搜索的关键’词‘分析
# 主要分析热点词
# 将所有的搜索内容取出
# print(split_rdd.takeSample(True, 3))
context_rdd = split_rdd.map(lambda x:x[2])
# 对搜索的内容进行分词分析
words_rdd = context_rdd.flatMap(context_jieba)
# print(words_rdd.collect())
# 院校 帮 -> 院校帮
# 博学 谷 -> 博学谷
# 传智播 客 -> 传智播客
filtered_rdd =words_rdd.filter(filter_words)
# 将关键词转换:传智播 -> 传智播客
final_words_rdd = filtered_rdd.map(append_words)
# 对单词进行分组、聚合、排序求出前5名
result1 = final_words_rdd.reduceByKey(lambda a,b:a+b).\
sortBy(lambda x:x[1],ascending=False,numPartitions=1).\
take(5)
print("需求1结果:",result1)
# TODO:需求2:用户和关键词组合分析
# 1,我喜欢传智播客
# 1+我 1+喜欢 1+传智播客
user_context_rdd = split_rdd.map(lambda x:(x[1],x[2]))
# 对用户的搜索内容进行分词,分词后和用户ID再次组合
user_word_with_one_rdd = user_context_rdd.flatMap(extract_user_and_word)
# 对内容进行 分组、聚合、排序 ,求前5
result2 = user_word_with_one_rdd.reduceByKey(lambda a,b:a+b).\
sortBy(lambda x:x[1],ascending=False,numPartitions=1).\
take(5)
print("需求2结果:",result2)
# TODO:需求3:热门搜索时间段分析
# 取出来所有的时间
time_rdd = split_rdd.map(lambda x:x[0])
# 对时间进行处理,只保留小时精度即可
hour_with_one_rdd = time_rdd.map(lambda x:(x.split(":")[0],1))
# 分组 聚合 排序
result3 = hour_with_one_rdd.reduceByKey(add).\
sortBy(lambda x:x[1],ascending=False,numPartitions=1).\
collect()
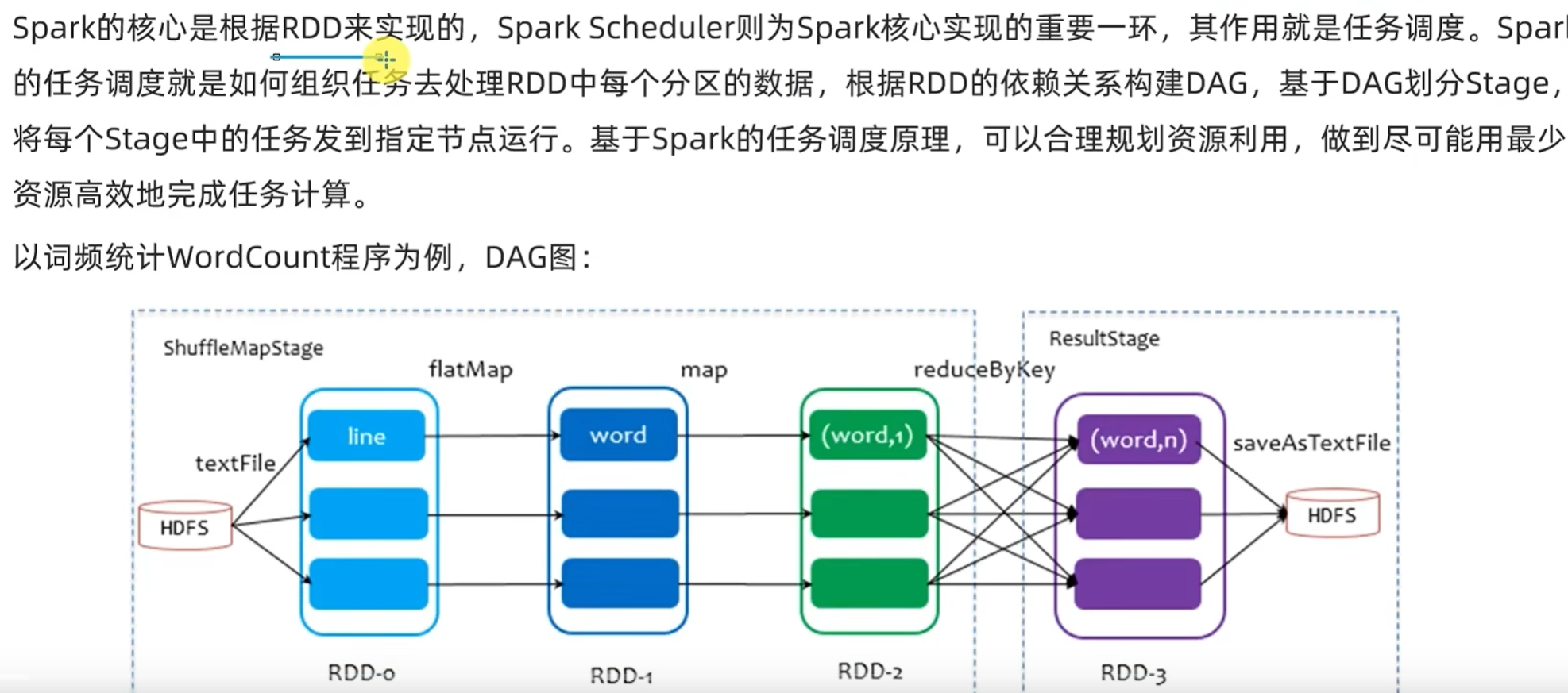
print("需求3结果:",result3)针对代码的DAG图
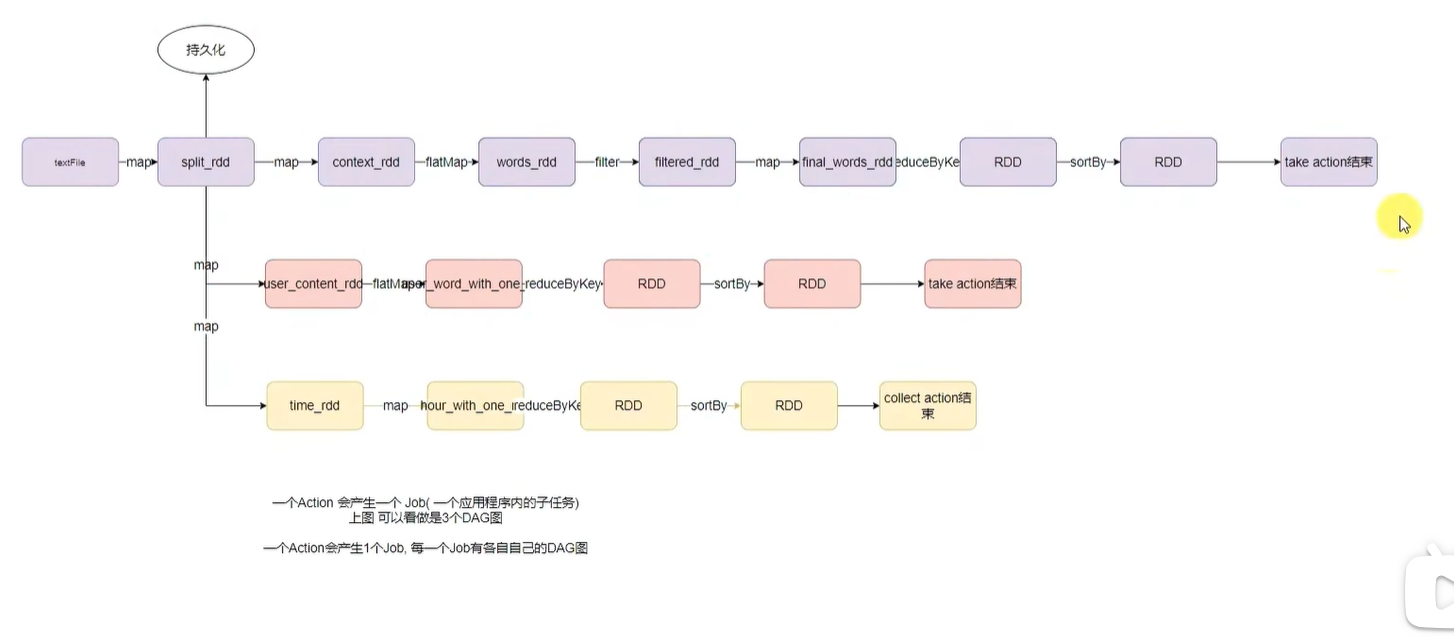
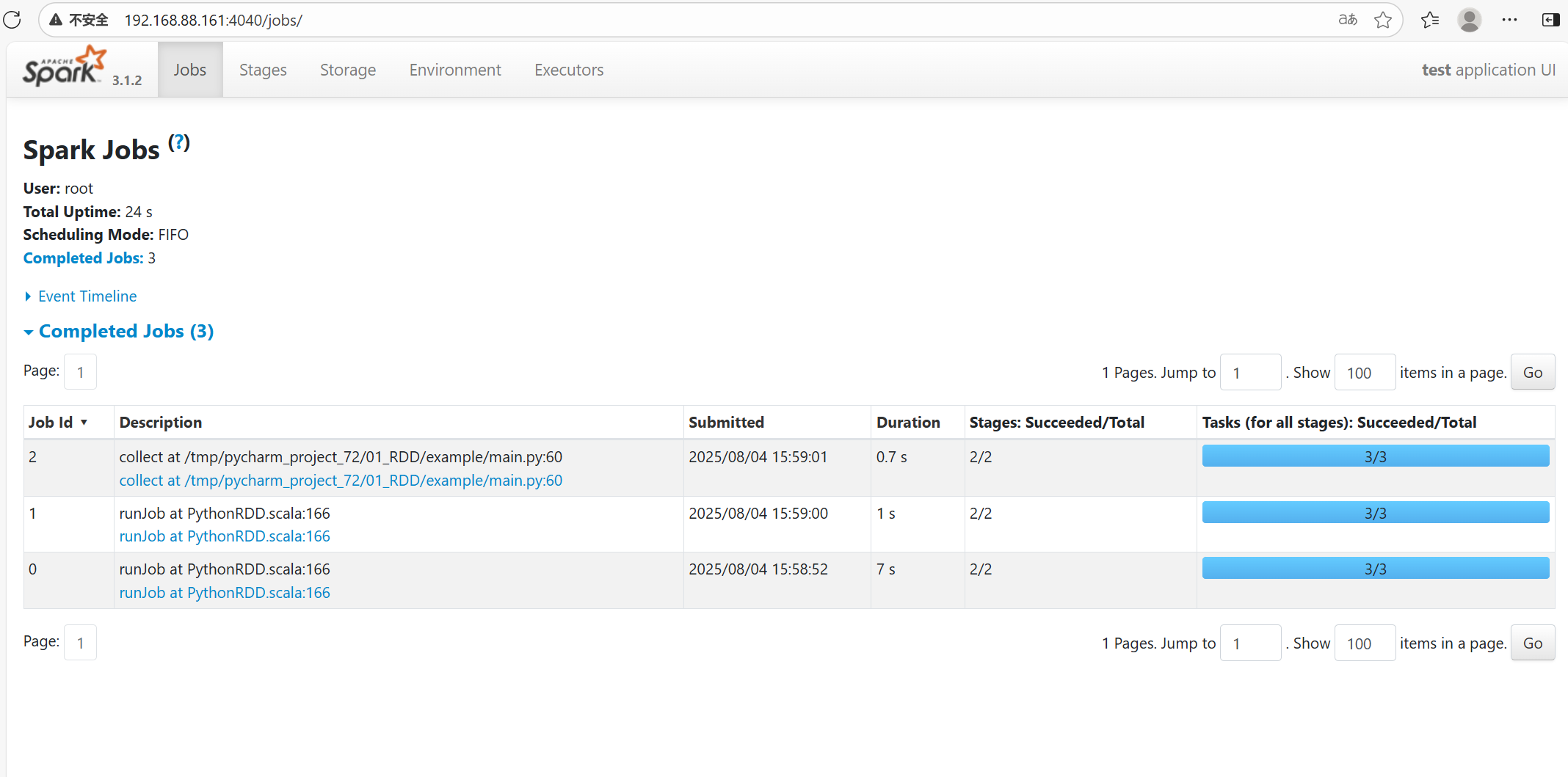
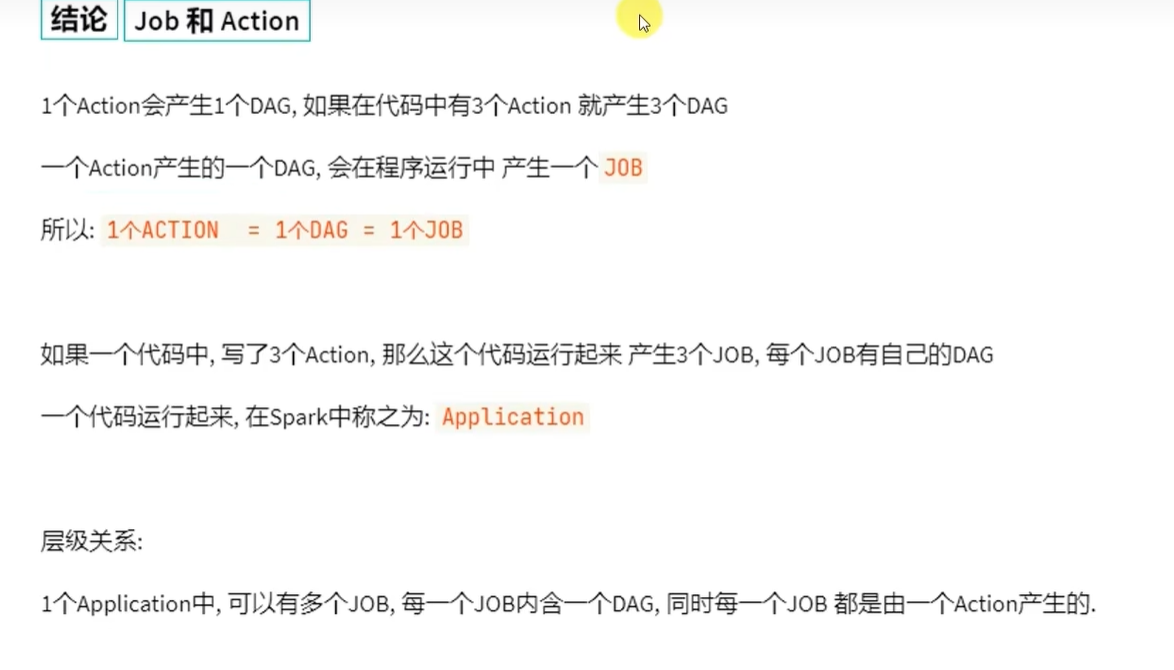
一个action会产生1个job,每一个job有各自自己的DAG图
执行以上代码,可以在4040端口查看,有三个job
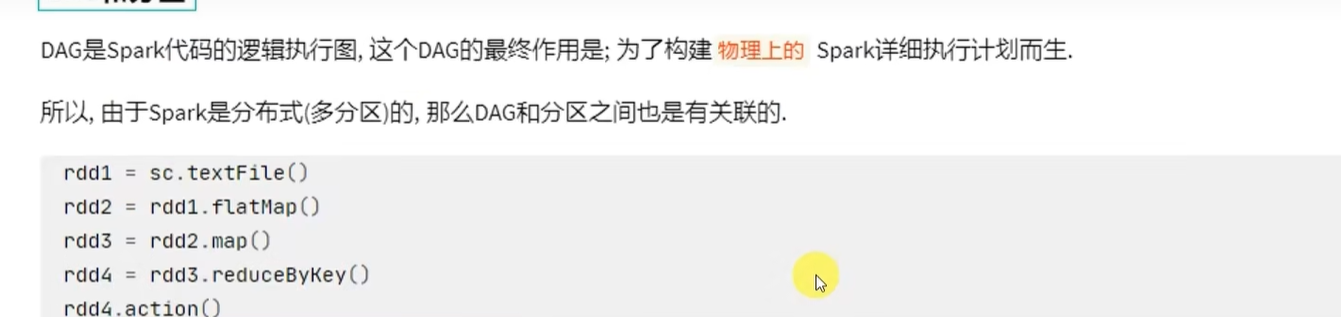
带有分区关系的DAG图
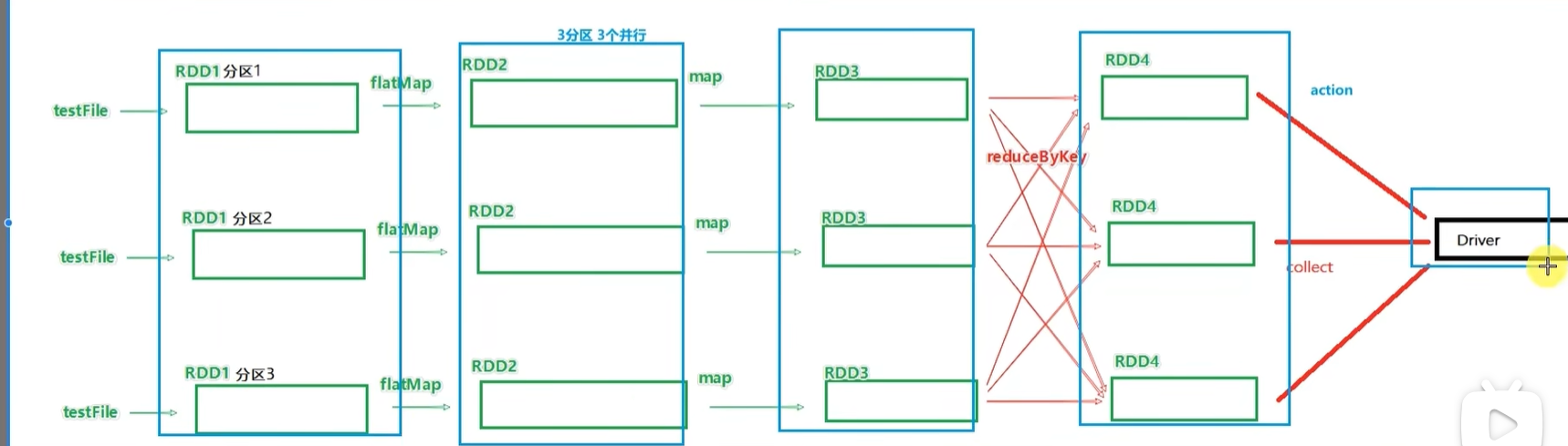
二、DAG的宽窄依赖和阶段划分
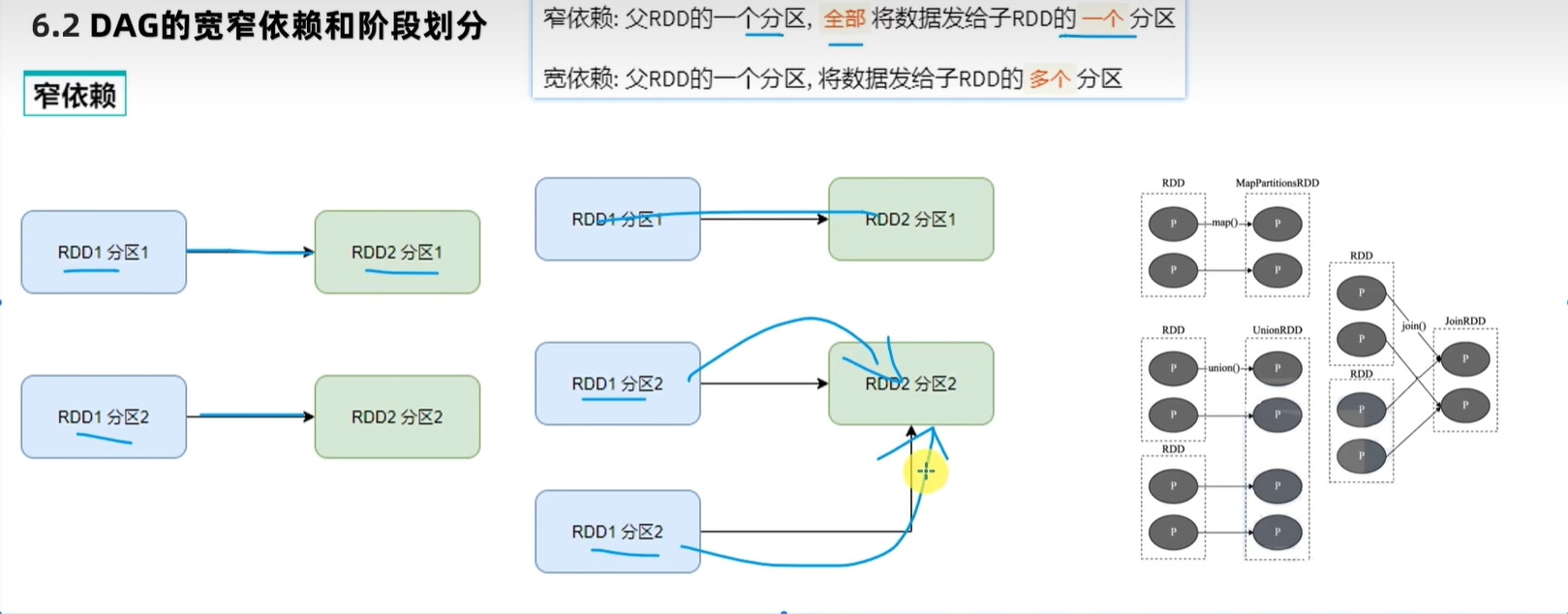
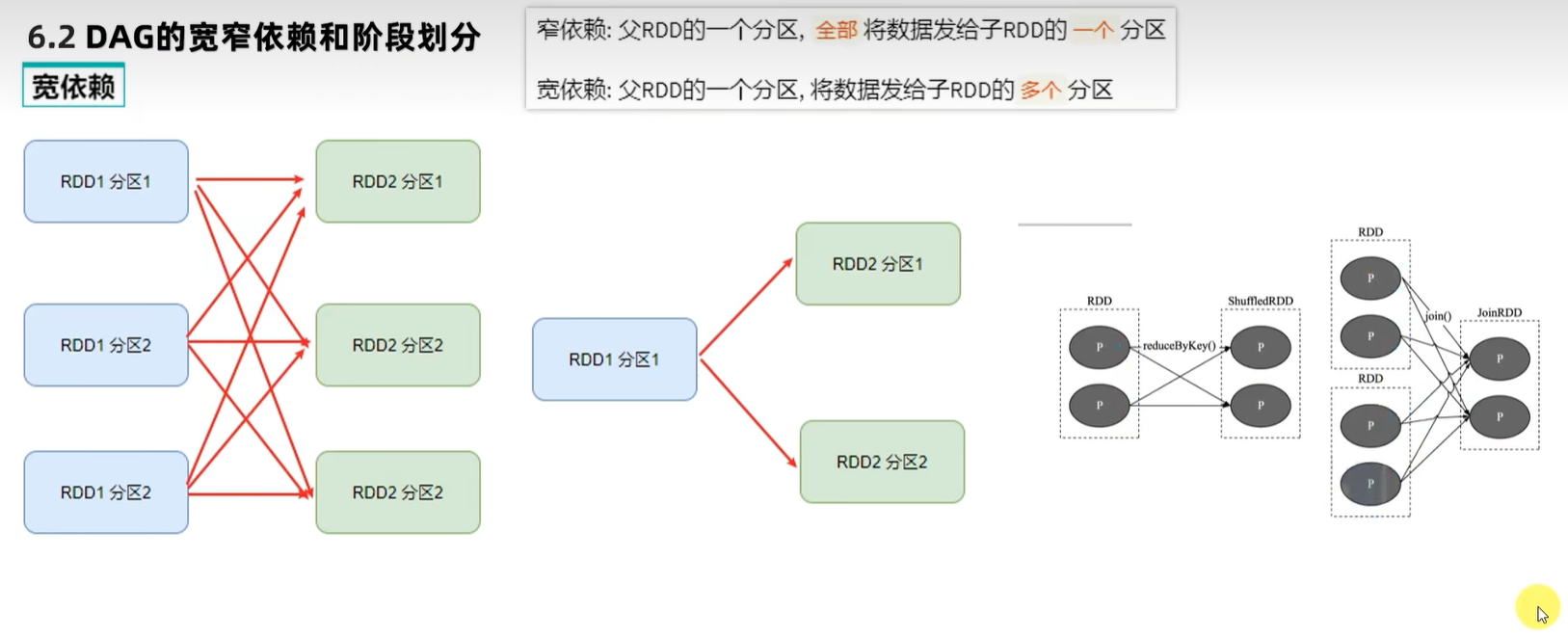
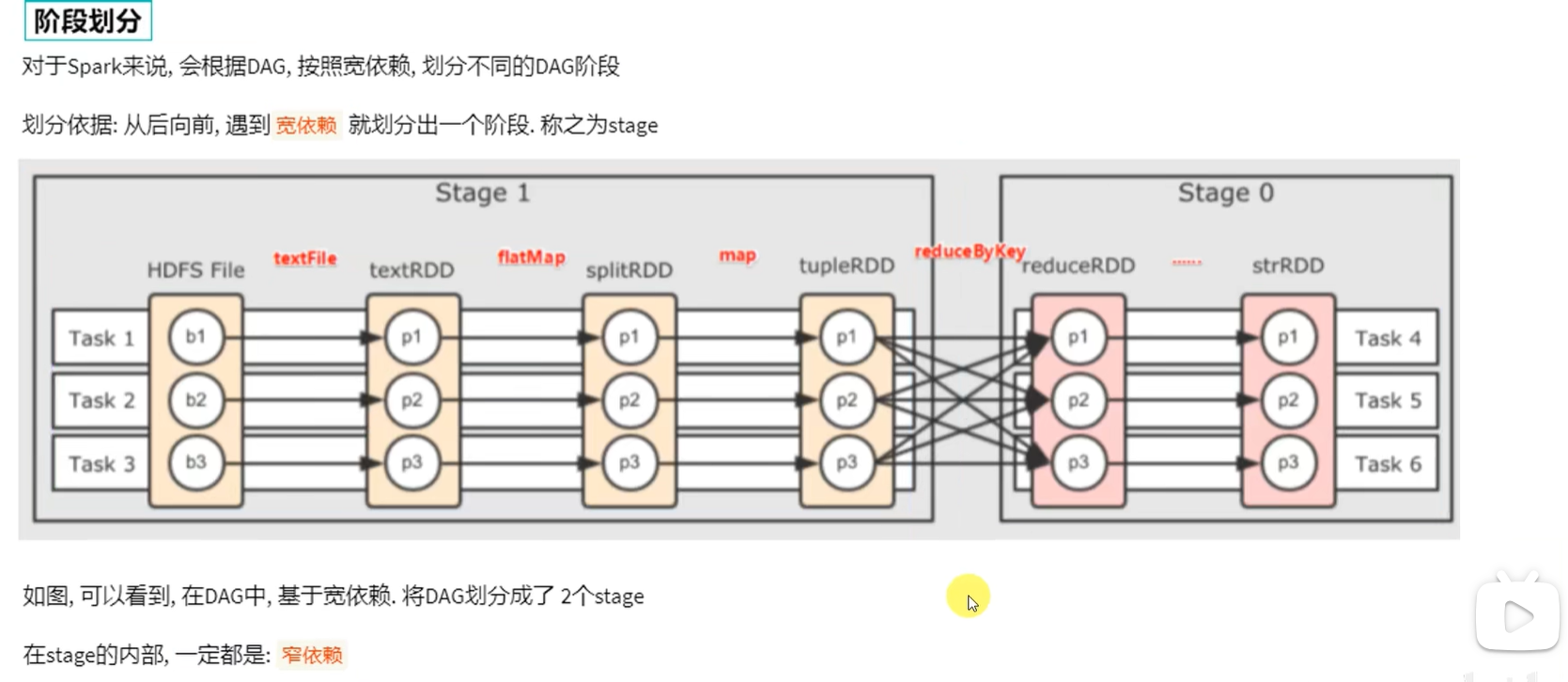 当我们遇到一个宽依赖就划分,这样就可以保证每一个阶段内都是窄依赖
当我们遇到一个宽依赖就划分,这样就可以保证每一个阶段内都是窄依赖
三、内存迭代计算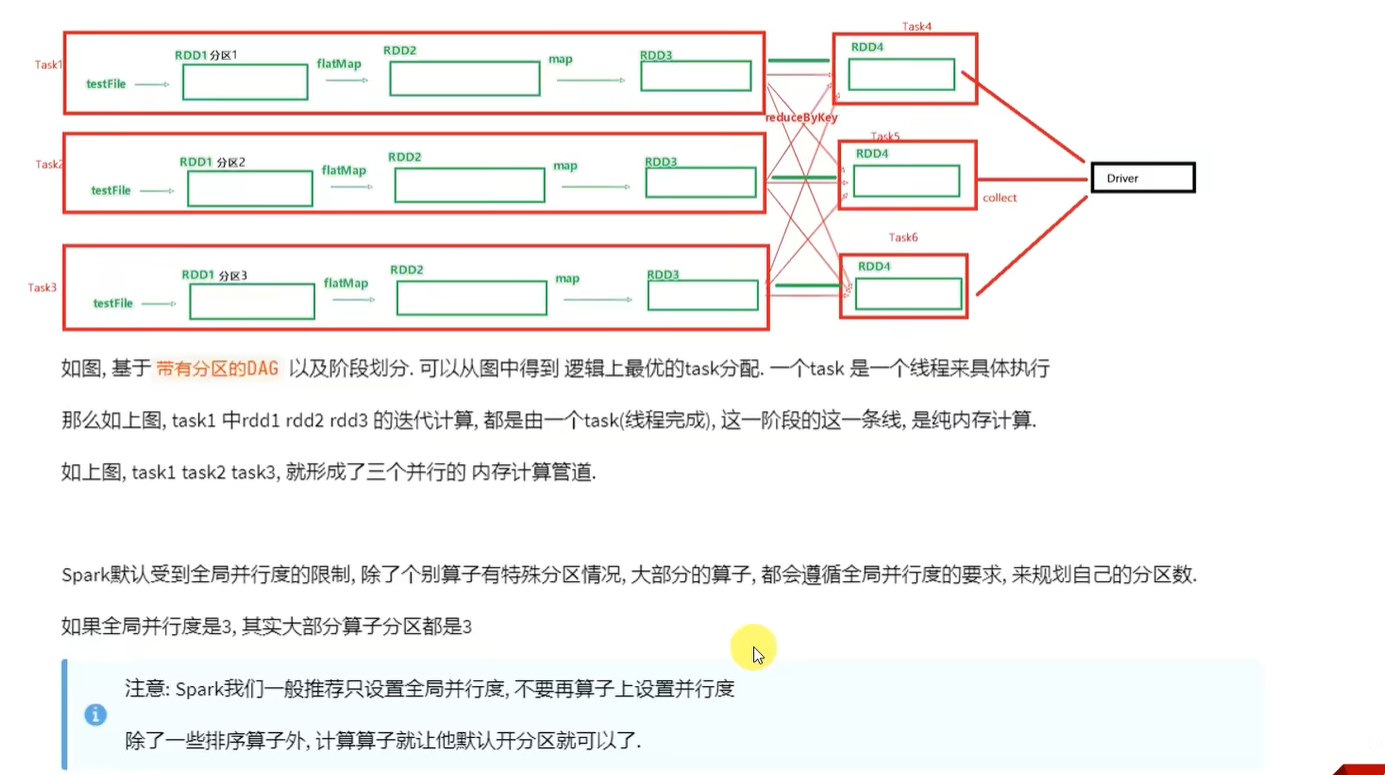
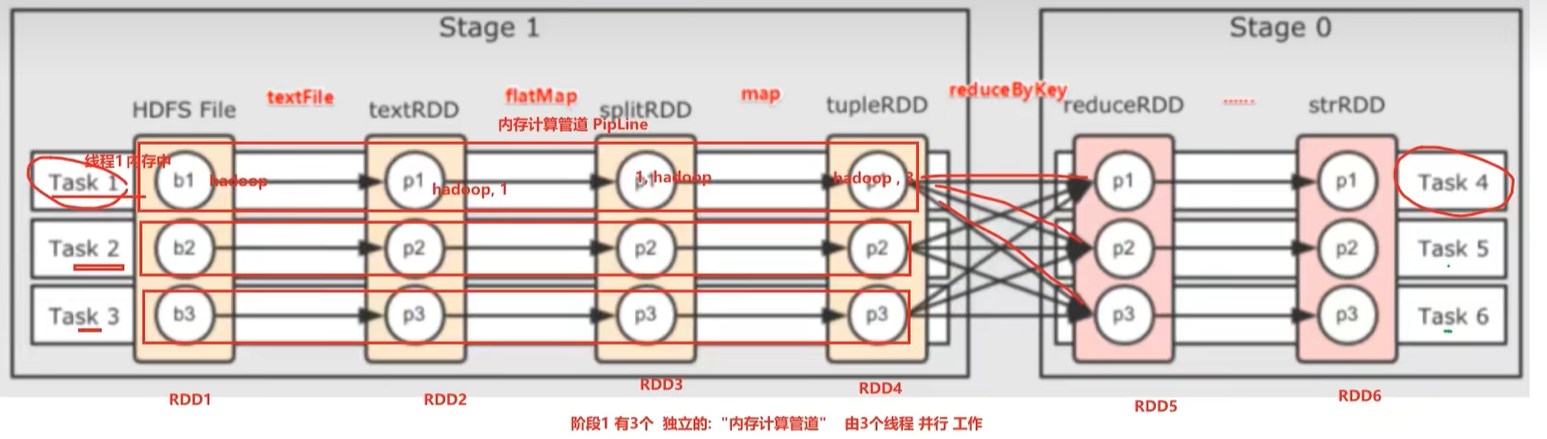
面试题


四、spark并行度

先有并行度才有分区,比如先有三个并行度,对应才有了三个分区
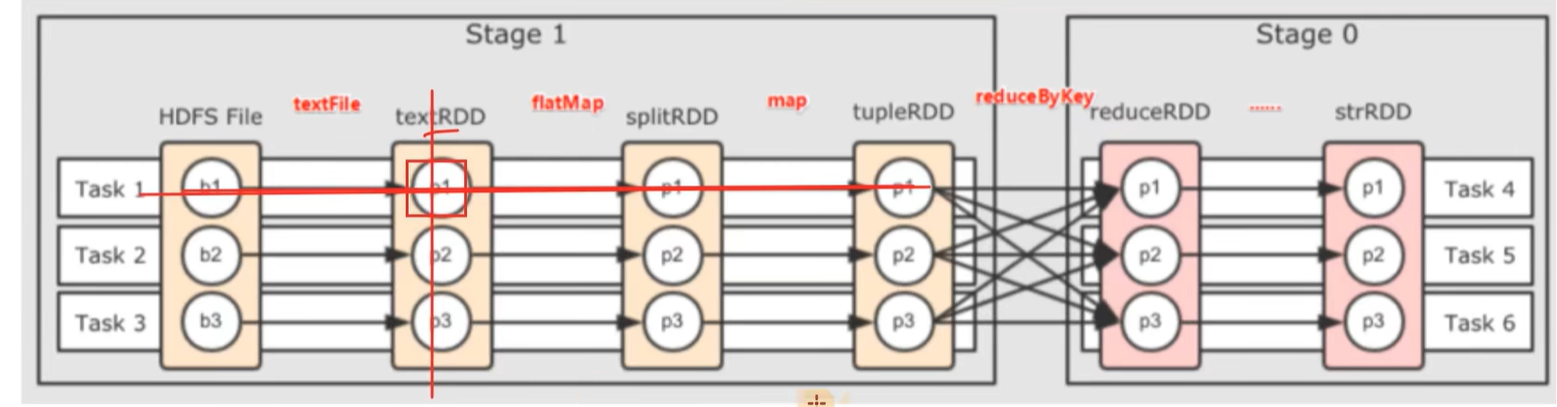
rdd的一个分区只会被一个并行处理,也就是一个task处理
一个task可以处理多个rdd,但是只能处理rdd的一个分区
也就是在横向纵向上,都是一对一的关系

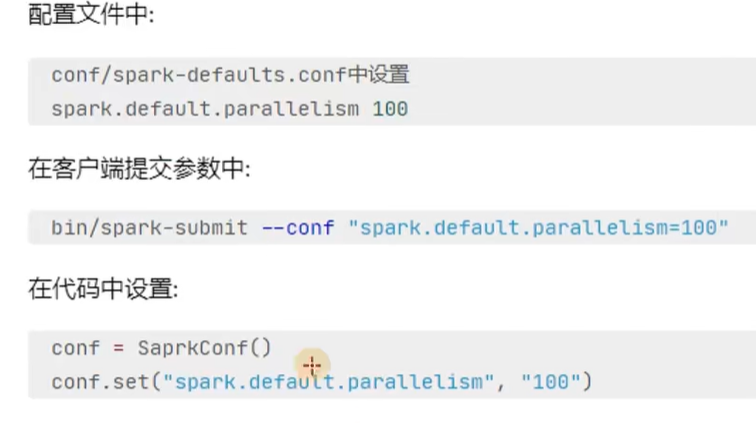
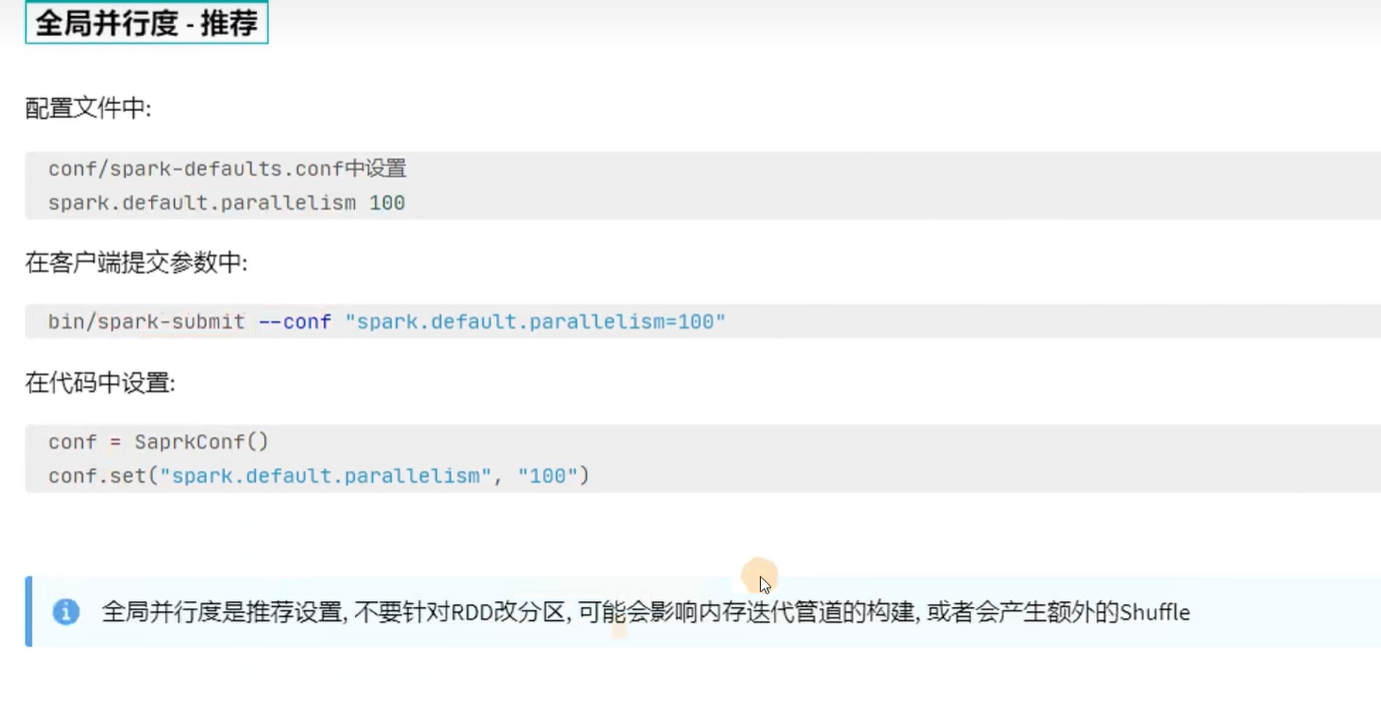

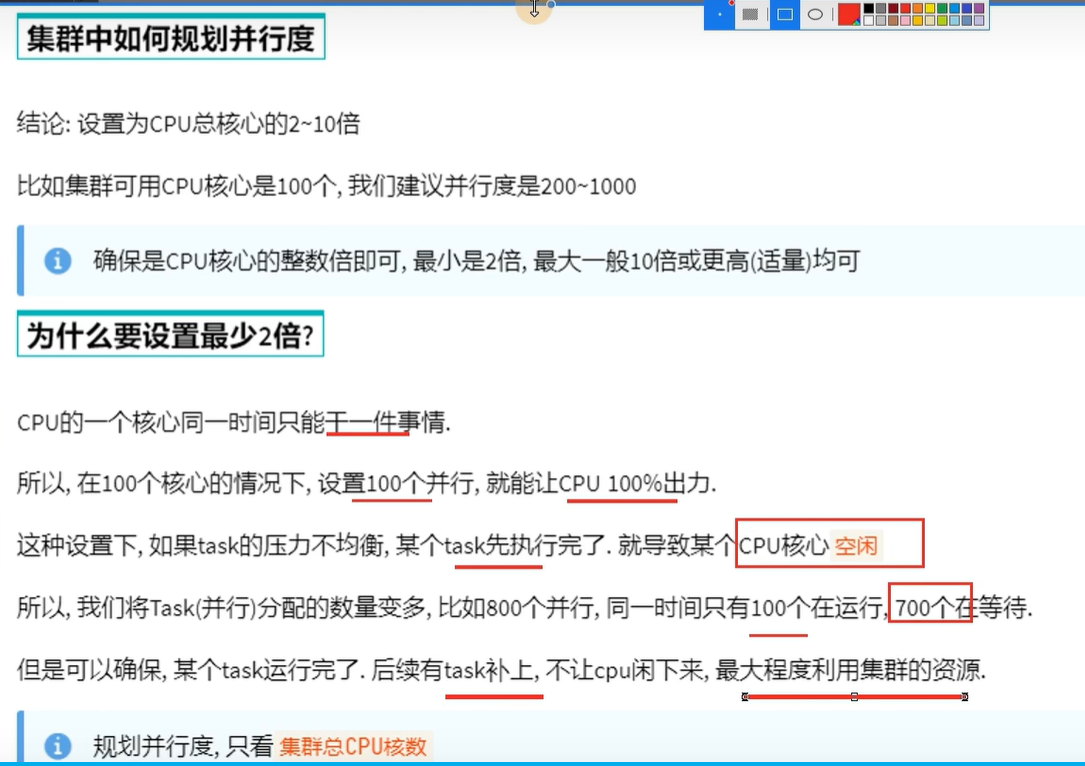
设置多个并行度的目的就是为了不让cpu闲下来,最大程度利用集群的资源
五、spark的任务调度
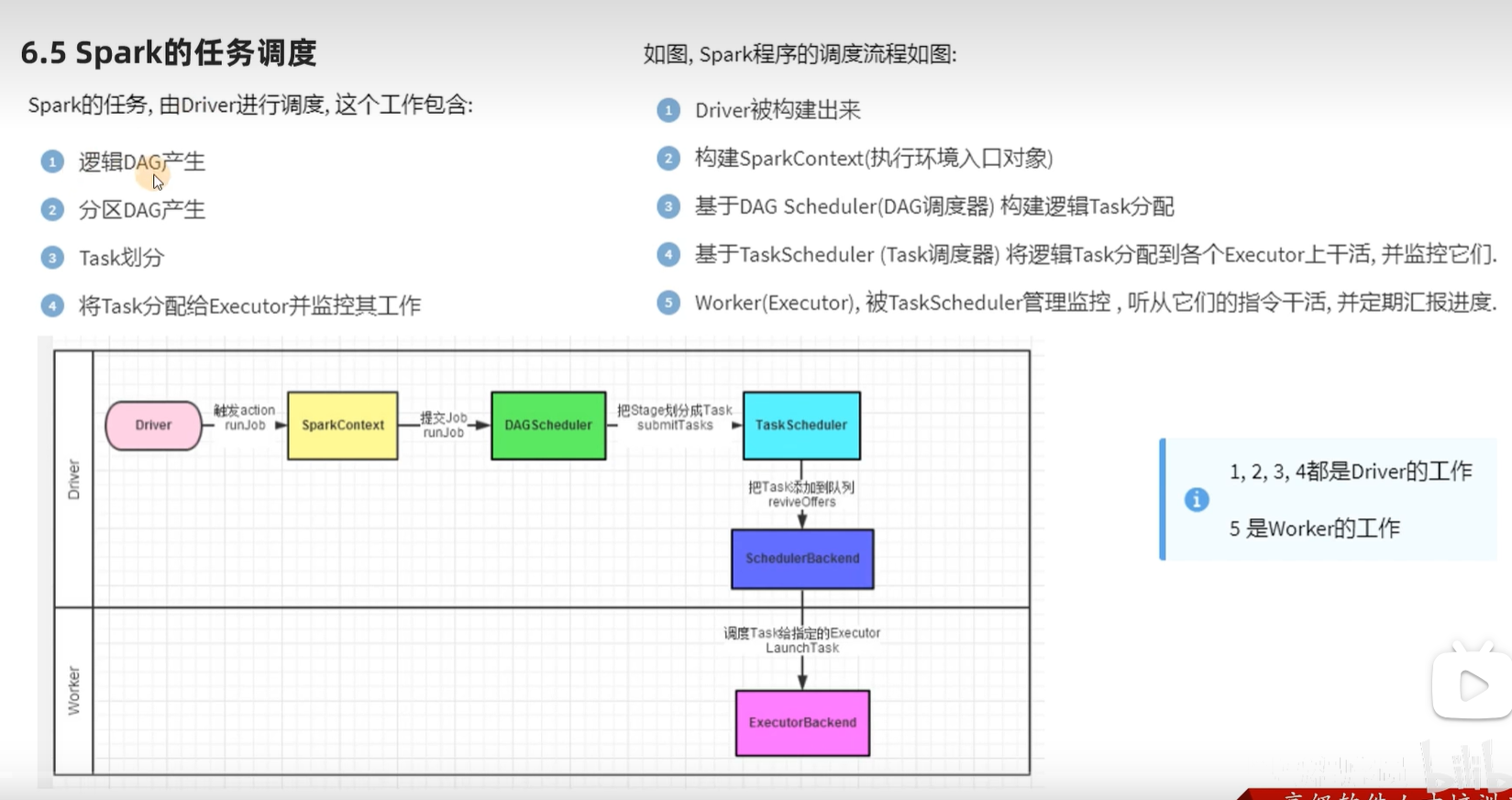

注意: executors 的数量和并行度无关
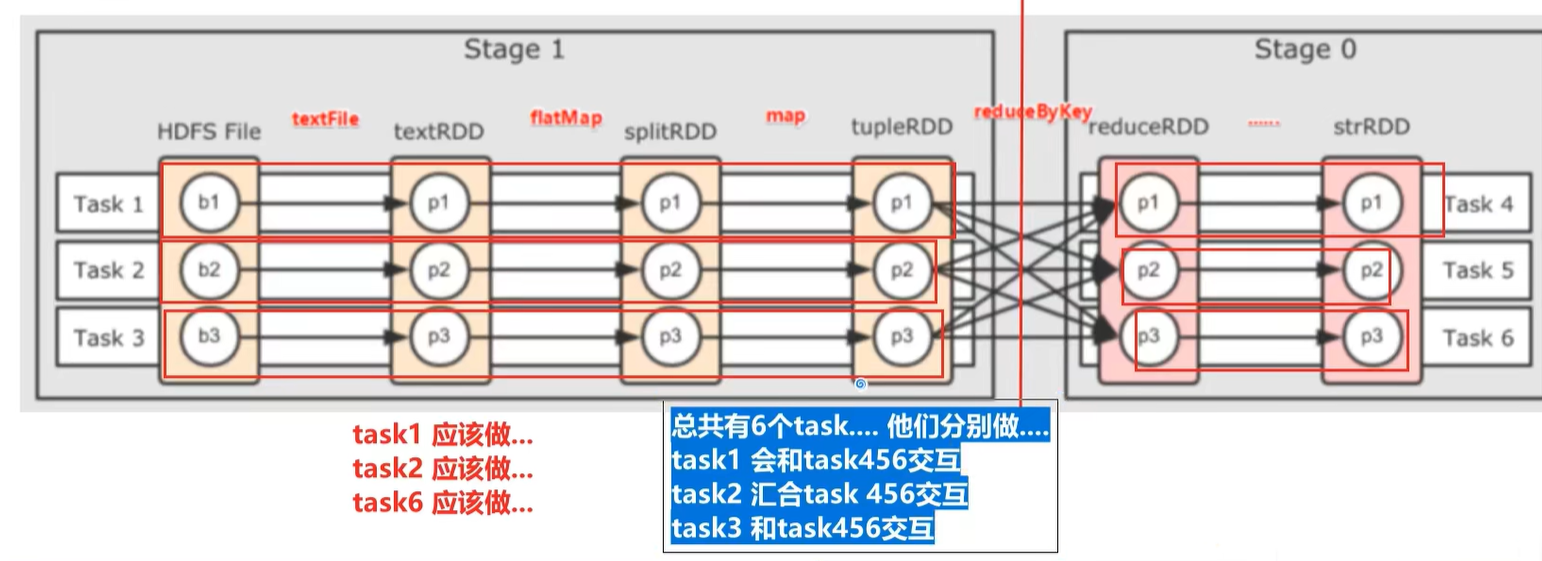
先规划出task,在根据executors进行分配
为了保证并行能力,将六个task合理分配到executors
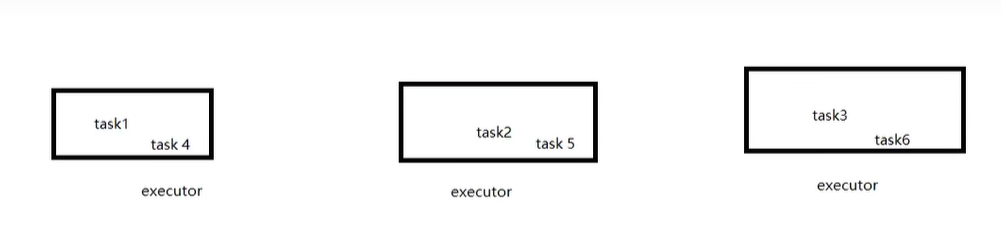
如果一台服务器上运行两个executor,相当于两个进程,之间也是走网络,只不过是走的本地回环网络,比跨机器的网络快一点,因为进程之间是无法通过内存传输的
假设一台服务器上有四个task,一个executor,task之间就是通过内存传输,两个executor,不同executor中的task就是通过网络传输
建议多少台服务器,设置多少个executor
六、扩展 - spark运行中的概念名词大全

七、总结
