
Flume架构深度解析:构建高可用大数据采集系统
🌟 你好,我是 励志成为糕手 !
🌌 在代码的宇宙中,我是那个追逐优雅与性能的星际旅人。
✨ 每一行代码都是我种下的星光,在逻辑的土壤里生长成璀璨的银河;
🛠️ 每一个算法都是我绘制的星图,指引着数据流动的最短路径;
🔍 每一次调试都是星际对话,用耐心和智慧解开宇宙的谜题。
🚀 准备好开始我们的星际编码之旅了吗?
目录
- Flume架构深度解析:构建高可用大数据采集系统
-
- 摘要
- [1. Flume架构概览](#1. Flume架构概览)
-
- [1.1 整体架构设计理念](#1.1 整体架构设计理念)
- [1.2 Agent生命周期管理](#1.2 Agent生命周期管理)
- [2. 核心组件深度解析](#2. 核心组件深度解析)
-
- [2.1 Source组件详解](#2.1 Source组件详解)
-
- [2.1.1 Exec Source实现机制](#2.1.1 Exec Source实现机制)
- [2.1.2 Avro Source网络通信](#2.1.2 Avro Source网络通信)
- [2.2 Channel组件深度分析](#2.2 Channel组件深度分析)
-
- [2.2.1 Memory Channel内存优化策略](#2.2.1 Memory Channel内存优化策略)
- [2.2.2 File Channel持久化机制深度解析](#2.2.2 File Channel持久化机制深度解析)
- [2.3 Sink组件优化实践](#2.3 Sink组件优化实践)
-
- [2.3.1 HDFS Sink大数据集成](#2.3.1 HDFS Sink大数据集成)
- [3. 架构配置与优化](#3. 架构配置与优化)
-
- [3.1 多级数据路由架构](#3.1 多级数据路由架构)
- [3.2 高可用性配置](#3.2 高可用性配置)
- [3.3 性能调优参数](#3.3 性能调优参数)
- [4. 数据展示与监控](#4. 数据展示与监控)
-
- [4.1 Flume性能指标分布](#4.1 Flume性能指标分布)
- [4.2 性能优化优先级矩阵](#4.2 性能优化优先级矩阵)
- [4.3 监控指标收集](#4.3 监控指标收集)
- [5. 实战案例分析](#5. 实战案例分析)
-
- [5.1 电商日志采集系统配置](#5.1 电商日志采集系统配置)
- [5.2 实时监控告警流程](#5.2 实时监控告警流程)
- [6. 故障诊断与最佳实践](#6. 故障诊断与最佳实践)
-
- [6.1 常见故障与解决方案](#6.1 常见故障与解决方案)
-
- [6.1.1 Channel满载问题](#6.1.1 Channel满载问题)
- [6.1.2 网络连接超时](#6.1.2 网络连接超时)
- [6.2 性能优化最佳实践](#6.2 性能优化最佳实践)
-
- [6.2.1 批量处理优化](#6.2.1 批量处理优化)
- [6.2.2 内存管理优化](#6.2.2 内存管理优化)
- [7. 配置对比分析](#7. 配置对比分析)
- 总结
- 参考链接
- 关键词标签
摘要
在当今大数据时代,高效、可靠的数据采集是构建成功数据平台的关键基础。Apache Flume作为业界领先的海量日志收集系统,以其灵活的架构设计、强大的容错机制和卓越的性能表现,成为了大数据处理流程中不可或缺的核心组件。
Flume采用分布式的Agent架构设计,通过Source、Channel、Sink三大核心组件的组合,能够实现从多种数据源到多种目标系统的可靠数据传输。其独特的事务性保证机制确保了数据传输的可靠性,而丰富的配置选项则为不同场景下的性能优化提供了极大灵活性。
在实际应用场景中,Flume不仅能够处理传统的日志文件收集,还可以支持实时流数据处理、多级数据路由、负载均衡等复杂需求。通过合理的架构设计和参数调优,Flume能够实现每秒数万条记录的高吞吐量传输,同时保证99.9%以上的可靠性指标。这些特性使得Flume成为金融、电商、互联网等各个行业大数据平台建设的首选解决方案。
1. Flume架构概览
1.1 整体架构设计理念
Flume采用了事件驱动的流式处理架构,其核心设计理念是通过可插拔的组件化设计,实现数据从源到目标的高效可靠传输。整个系统围绕"数据流"这一核心概念构建,每个数据流由一个或多个Agent组成,形成一个完整的数据传输管道。
这种架构设计的优势在于其高度的模块化和可扩展性。开发者可以根据具体的数据采集需求,自由组合不同的Source、Channel和Sink组件,构建出符合特定业务场景的数据流。同时,Flume的分布式特性允许多个Agent协同工作,形成集群化的数据采集网络,极大提升了系统的处理能力和容错能力。
Flume的架构模型基于以下三个核心原则:
- 解耦性:数据产生、处理和消费环节相互独立,便于维护和扩展
- 可靠性:通过事务机制和失败重试确保数据传输的可靠性
- 可观测性:提供丰富的监控指标和日志信息,便于系统运维
这种设计理念使得Flume能够适应各种复杂的数据采集场景,从简单的文件监控到复杂的多级数据路由,都能够通过标准化的组件配置实现。同时,Flume的插件机制也为用户提供了扩展自定义组件的能力,能够满足特定的业务需求。
Flume Agent内部架构 Source
数据源组件 Channel
数据通道组件 Sink
数据汇组件 数据源 Flume Agent 数据汇 监控与控制 下游系统
图1:Flume整体架构图 - 展示了数据从源到汇的完整传输流程
Flume的Agent设计充分体现了微服务架构的思想,每个Agent都是独立运行的进程,具有自己的生命周期管理机制。这种设计的好处在于:
- 故障隔离:单个Agent的故障不会影响其他Agent的正常运行
- 水平扩展:可以通过增加Agent数量来提升整体处理能力
- 灵活部署:Agent可以独立部署在不同节点上,充分利用系统资源
- 版本管理:不同Agent可以运行不同版本的Flume,便于渐进式升级
1.2 Agent生命周期管理
每个Flume Agent在启动后会进入一个循环的处理流程,不断地从数据源采集数据,经过Channel缓冲后发送到目标系统。这个过程构成了Agent的生命周期,主要包括以下阶段:
初始化阶段:Agent读取配置文件,验证组件配置的合法性,创建并初始化各个组件实例。在这个阶段,系统会进行必要的资源分配和依赖检查,确保所有组件能够正常启动。
运行阶段:启动数据采集和处理流程,持续监控各个组件的状态。这个阶段是Agent的核心工作阶段,所有的数据处理活动都在此阶段进行。
监控阶段:收集性能指标,处理异常情况,执行清理操作。Agent会持续监控各个组件的健康状况,当发现异常时会尝试进行恢复。
终止阶段:优雅地关闭各个组件,保存必要状态信息。在Agent关闭时,系统会确保所有正在处理的事件都能正确完成,避免数据丢失。
在生命周期管理中,Flume特别注重异常情况的处理。当某个组件发生异常时,系统会尝试进行故障恢复,如果恢复失败则会将事件重新放回Channel中,确保数据的完整性。同时,Agent还提供了多种监控接口,方便运维人员实时了解系统状态。
java
public class FlumeAgent {
public void start() {
try {
// 1. 加载配置文件
materializedConfiguration = configurationProvider.getConfiguration();
// 2. 按依赖顺序启动组件
for (EventDrivenSourceAndSinkConfiguration sourceConfig : config.getSourceConfigurations()) {
Source source = sourceConfig.getSource();
source.start();
// 启动关联的Channel和Sink
for (String channelName : sourceConfig.getChannelNames()) {
Channel channel = config.getChannel(channelName);
channel.start();
}
}
// 3. 启动生命周期监督
supervisor.start();
} catch (Exception e) {
LOGGER.error("Agent启动失败", e);
stop();
}
}
}第18-25行按Source-Channel-Sink的依赖顺序启动组件,避免启动顺序错误
Agent的生命周期管理还包括了完善的监控机制。系统会定期收集各个组件的运行指标,包括处理的事件数量、错误率、延迟等关键性能指标。这些指标不仅用于内部优化,也为外部监控系统的集成提供了数据支持。
此外,Flume还提供了完善的清理机制。在Agent正常关闭或异常终止时,系统会确保所有的内存资源、文件句柄、网络连接等都被正确释放,避免资源泄漏问题。这种负责任的资源管理机制是Flume能够长期稳定运行的重要保障。
2. 核心组件深度解析
2.1 Source组件详解
Source组件作为Flume数据流的起点,承担着从各种外部数据源采集数据的核心职责。不同类型的Source组件针对不同的数据源特性和应用场景进行了深度优化,选择合适的Source类型对于构建高效的数据采集系统至关重要。
在Flume的架构设计中,Source组件采用统一的接口规范,确保了组件之间的标准化交互。每个Source组件都需要实现标准的数据采集协议,包括配置解析、数据读取、事件封装和错误处理等核心功能。这种统一的设计模式不仅简化了组件的开发难度,也为用户提供了灵活的配置选择。
2.1.1 Exec Source实现机制
Exec Source通过执行操作系统命令来实现对文件或进程的实时监控,其核心优势在于能够利用现有系统工具的强大功能,同时保持较低的开发复杂度。这种设计思想体现了Unix哲学中"简单工具组合"的核心观念,通过调用系统级工具来获取数据,而不是重新实现复杂的底层逻辑。
当Exec Source启动时,它会在独立的子进程中执行配置的命令,并持续监控其输出流。每当有新数据产生时,Source会立即读取并将其封装为Flume事件。这种实时性保证对于需要及时响应的场景非常重要,如错误日志监控、用户行为追踪等。
在性能优化方面,Exec Source实现了智能的批处理机制。系统会将短时间内产生的数据进行累积,当达到预设的批处理大小或超时间隔时,统一发送给下一个处理组件。这种设计既保证了数据的实时性,又避免了频繁的小数据传输带来的网络开销。
java
public class ExecSource extends AbstractSource implements Configurable, EventDrivenSource {
private String command;
private long batchSize;
private long batchTimeout;
@Override
public void configure(Context context) {
command = context.getString("command");
batchSize = context.getLong("batchSize", 100);
batchTimeout = context.getLong("timeout", 3000);
Preconditions.checkState(command != null && !command.isEmpty(), "command不能为空");
}
private void processCommand() {
try {
Process process = Runtime.getRuntime().exec(command);
BufferedReader reader = new BufferedReader(new InputStreamReader(process.getInputStream()));
String line;
List<Event> events = new ArrayList<>();
while ((line = reader.readLine()) != null) {
Event event = EventBuilder.withBody(line, Charset.defaultCharset().toByteBuffers());
events.add(event);
// 批处理逻辑:达到批大小或超时时间时发送事件
if (events.size() >= batchSize ||
(events.size() > 0 && System.currentTimeMillis() - lastSendTime > batchTimeout)) {
sendBatch(events);
events.clear();
lastSendTime = System.currentTimeMillis();
}
}
} catch (Exception e) {
LOGGER.error("执行命令异常", e);
}
}
}第23-32行实现批处理优化,平衡吞吐量和延迟。第34-47行使用Channel事务确保数据传输可靠性。
Exec Source在实际应用中需要注意一些关键问题。首先是命令的可靠性问题,如果执行的命令意外终止,Source需要具备自动重启能力。其次是资源清理问题,当Source关闭时必须正确释放子进程和相关资源,避免僵尸进程的产生。此外,对于长时间运行的命令,还需要考虑输出缓冲区的管理,防止内存溢出。
2.1.2 Avro Source网络通信
Avro Source代表了Flume在分布式环境下的网络数据接收能力,其设计充分考虑了现代分布式系统的通信需求。Apache Avro作为一种高效的序列化协议,为Flume提供了紧凑的数据传输格式和强大的Schema演进能力,这对于需要处理大量结构化数据的场景具有重要意义。
Avro Source采用了异步多线程的处理模式,通过线程池来并发处理来自不同客户端的连接请求。这种设计不仅提高了系统的并发处理能力,也有效地隔离了不同数据源的影响,提高了系统的稳定性和可维护性。在连接管理方面,Avro Source实现了连接池机制,能够复用网络连接,减少TCP连接建立的开销。
在数据传输协议上,Avro Source实现了完整的批处理机制。客户端可以一次性发送多个事件,Source会统一处理这些事件并在事务边界内完成持久化。这种批量处理方式显著提高了网络利用率,降低了单条消息的处理开销。
java
public class AvroSource extends AbstractSource implements Configurable, EventDrivenSource {
private int port;
private int threads;
@Override
public void configure(Context context) {
port = context.getInteger("port", 41414);
threads = context.getInteger("threads", 64);
}
private class AvroSourceHandler implements AvroSourceProtocol {
@Override
public List<Status> appendBatch(List<Event> events) {
List<Status> statuses = new ArrayList<>();
Transaction transaction = getChannel().getTransaction();
try {
transaction.begin();
for (Event event : events) {
try {
getChannel().put(event);
statuses.add(Status.OK);
} catch (Exception e) {
statuses.add(Status.FAIL);
}
}
transaction.commit();
} catch (Exception e) {
transaction.rollback();
for (int i = 0; i < events.size(); i++) {
statuses.add(Status.FAIL);
}
}
return statuses;
}
}
}第18-31行批量处理事件,提升网络吞吐量。第33-43行使用事务确保数据一致性。
在安全性和可靠性方面,Avro Source提供了多层次的保障机制。网络传输支持SSL/TLS加密,保护数据在传输过程中的安全性。同时,系统实现了连接超时检测、流量控制和熔断机制,当检测到异常情况时会自动断开连接并触发告警。这些特性使得Avro Source能够在企业级环境中安全可靠地运行。
2.2 Channel组件深度分析
Channel组件在Flume架构中扮演着至关重要的角色,它不仅是数据缓冲的核心组件,更是实现Source和Sink解耦的关键环节。Channel的设计充分体现了流处理系统中"背压"(Backpressure)机制的重要性,通过合理的缓冲策略来平衡不同组件之间的处理能力差异,从而保证整个数据流的稳定性和可靠性。
在分布式数据处理环境中,Source和Sink的处理能力往往存在差异。Source可能会在某个时间点产生大量数据,而Sink的处理速度可能相对较慢,这时Channel就像一个"保险丝"一样,通过缓冲机制防止系统的雪崩效应。同时,Channel还需要保证数据的完整性和顺序性,这是构建可靠数据流的基础。
不同类型的Channel针对不同的应用场景进行了专门的优化。Memory Channel主要面向高吞吐量场景,File Channel主要面向高可靠性场景,而JDBC Channel则面向跨数据库的事务性场景。这种多样化的设计使得用户可以根据具体的业务需求选择最适合的Channel类型。
2.2.1 Memory Channel内存优化策略
Memory Channel的设计核心在于充分利用计算机内存的高速访问特性,通过内存中的队列结构来缓存数据事件。其内部采用了高效的无锁队列实现,通过CAS(Compare and Swap)操作来实现高并发场景下的线程安全,这种设计理念源于Java并发编程中的现代性能优化策略。
在内存管理方面,Memory Channel实现了多层次的容量控制机制。除了事件数量的限制外,还提供了字节容量的监控和控制,这在处理变长消息的场景中尤为重要。当Channel达到容量限制时,系统不会简单地丢弃数据,而是通过异常机制通知上游组件,使其能够采取相应的背压处理策略。
Memory Channel的内存分配策略采用了"懒加载"和"分批释放"相结合的方式。在事件写入时,系统会按需分配内存,避免了过早的大块内存分配。同时,在事件消费后,系统会延迟释放内存,通过内存池化的方式来减少频繁的GC压力。
java
public class MemoryChannel extends AbstractChannel implements Configurable {
private int capacity = 100;
private long transactionCapacity = 100;
private long byteCapacity = 0;
private BlockingQueue<Event> queue;
@Override
public void put(Event event) throws ChannelException {
// 字节容量检查
if (byteCapacity > 0) {
int eventSize = estimateEventSize(event);
long currentUsage = byteCapacityUsed.get();
long newUsage = currentUsage + eventSize;
if (newUsage > byteCapacity * 80 / 100) {
throw new ChannelException("超出字节容量限制");
}
byteCapacityUsed.addAndGet(eventSize);
}
boolean success = queue.offer(event);
if (!success) {
throw new ChannelException("队列已满");
}
queueSize++;
counterGroup.incrementAndGet("events.put");
}
@Override
public Event take() throws ChannelException {
Event event = queue.poll();
if (event != null) {
queueSize--;
if (byteCapacity > 0) {
int eventSize = estimateEventSize(event);
byteCapacityUsed.addAndGet(-eventSize);
}
counterGroup.incrementAndGet("events.take");
}
return event;
}
}第14-23行实现字节级容量监控。第25-29行使用LinkedBlockingQueue确保线程安全。
在实际生产环境中,Memory Channel的优化还需要考虑JVM的垃圾回收行为。过于频繁的内存分配和释放可能导致GC压力过大,影响整体性能。因此,建议在配置Memory Channel时,适当调整JVM参数,特别是堆内存大小和GC策略,以达到最佳的性能表现。
2.2.2 File Channel持久化机制深度解析
File Channel代表了Flume在数据持久化方面的最高水准,其设计充分考虑了企业级应用对数据可靠性的严格要求。File Channel内部实现了完整的ACID事务特性,通过双写(Double Write)和预写日志(Write-Ahead Logging, WAL)机制来保证数据的完整性和一致性。
File Channel的文件组织结构采用了多文件循环写入的方式。系统会维护多个数据文件,按照预定的策略进行循环写入。当一个文件达到一定大小或年龄时,系统会将其标记为只读,并创建新的文件继续写入。这种设计既保证了数据写入的连续性,又避免了单个文件过大导致的性能问题。
在数据持久化过程中,File Channel首先将数据写入磁盘的临时区域,然后通过fsync操作确保数据持久化到磁盘,最后更新索引信息。这种分阶段的写入方式虽然增加了少量的延迟,但极大提高了数据的安全性和系统的可靠性。
java
public class FileChannel extends AbstractChannel implements Configurable {
private String dataDir;
private FileQueue queue;
@Override
public void put(Event event) throws ChannelException {
checkNotNull(event, "Event不能为空");
long transactionID = System.nanoTime();
try {
queue.beginTransaction();
queue.put(event, transactionID);
} catch (Exception e) {
try {
queue.rollback();
} catch (Exception re) {
LOGGER.error("回滚失败", re);
}
throw new ChannelException("写入失败", e);
}
}
@Override
public void commit() {
try {
queue.commit();
counterGroup.incrementAndGet("events.commit");
} catch (Exception e) {
counterGroup.incrementAndGet("events.rollback");
throw new ChannelException("提交失败", e);
}
}
}第12-21行实现完整的ACID事务特性。第25-33行处理提交异常,确保数据一致性。
File Channel在处理故障恢复时采用了"检查点"机制。系统会定期将当前的处理状态写入到检查点文件中,包括已处理的事件位置、文件指针等信息。当系统重启时,可以通过读取检查点文件来快速恢复到之前的状态,避免从头开始处理大量数据。
在性能优化方面,File Channel实现了多种策略来平衡可靠性和性能。系统会根据当前的负载情况动态调整写入缓冲区的大小,在保证数据安全的前提下最大化写入性能。同时,通过异步I/O和多线程处理,File Channel能够在不牺牲可靠性的前提下达到较好的性能表现。
2.3 Sink组件优化实践
2.3.1 HDFS Sink大数据集成
HDFS Sink专门用于将数据写入Hadoop分布式文件系统,支持多种文件格式、压缩方式和滚动策略。
java
public class HDFSEventSink extends AbstractSink implements Configurable {
private String hdfsPath;
private int hdfsRollSize = 1024;
private int hdfsBatchSize = 100;
private FSDataOutputStream outputStream;
private long bytesProcessed = 0;
@Override
public void configure(Context context) {
hdfsPath = context.getString("hdfs.path");
hdfsRollSize = context.getInteger("hdfs.rollSize", 1024);
hdfsBatchSize = context.getInteger("hdfs.batchSize", 100);
Preconditions.checkNotNull(hdfsPath, "hdfs.path不能为空");
}
@Override
public Status process() throws EventDeliveryException {
Channel channel = getChannel();
Transaction transaction = channel.getTransaction();
try {
transaction.begin();
List<Event> events = new ArrayList<>();
for (int i = 0; i < hdfsBatchSize; i++) {
Event event = channel.take();
if (event == null) break;
events.add(event);
}
if (events.isEmpty()) {
transaction.commit();
return Status.BACKOFF;
}
// 批量写入HDFS
writeEvents(events);
// 检查文件滚动条件
if (shouldRollFile()) {
rollFile();
}
transaction.commit();
return Status.READY;
} catch (Exception e) {
LOGGER.error("处理事件失败", e);
transaction.rollback();
return Status.BACKOFF;
}
}
private void writeEvents(List<Event> events) throws IOException {
for (Event event : events) {
String line = new String(event.getBody(), "UTF-8");
outputStream.write((line + "\n").getBytes("UTF-8"));
outputStream.flush();
bytesProcessed += event.getBody().length;
counterGroup.incrementAndGet("events.successful");
}
}
}第25-39行实现批量事件处理。第41-58行提供文件滚动机制,优化HDFS文件管理。
3. 架构配置与优化
3.1 多级数据路由架构
实时数据 批量数据 归档数据 业务应用 收集层 Agent 路由决策 实时处理层 批处理层 存储层 Kafka Cluster HDFS Cluster Archive System
图2:多级数据路由架构图 - 从数据收集到最终存储的完整路由流程
3.2 高可用性配置
properties
# 负载均衡Sink配置
agent1.sinks = avroSink1 avroSink2
agent1.sinkgroups = sinkgroup1
agent1.sinkgroups.sinkgroup1.sinks = avroSink1 avroSink2
agent1.sinkgroups.sinkgroup1.processor.type = load_balance
agent1.sinkgroups.sinkgroup1.processor.selector = round_robin
# 备份Agent配置
agent2.sources.avroSource.type = avro
agent2.sources.avroSource.bind = 0.0.0.0
agent2.sources.avroSource.port = 41415
# File Channel确保数据持久化
agent2.channels.fileChannel.type = file
agent2.channels.fileChannel.capacity = 1000000
agent2.channels.fileChannel.transactionCapacity = 10000第1-5行配置负载均衡策略。第7-9行定义网络接收参数。第11-14行使用File Channel确保数据不丢失。
3.3 性能调优参数
properties
# JVM参数优化
FLUME_JAVA_OPTS="-Xms2g -Xmx4g -XX:+UseG1GC"
# 批处理优化
agent1.channels.memoryChannel.capacity = 2000000
agent1.channels.memoryChannel.transactionCapacity = 10000
# 网络优化
agent1.sinks.avroSink1.batch-size = 1000
agent1.sinks.avroSink1.compression-type = deflate4. 数据展示与监控
4.1 Flume性能指标分布
22% 20% 22% 17% 19% Flume性能指标分布 事件处理成功率 内存使用效率 网络传输效率 磁盘I/O效率 CPU利用率
图3:Flume性能指标分布饼图 - 展示各性能维度的整体表现
4.2 性能优化优先级矩阵
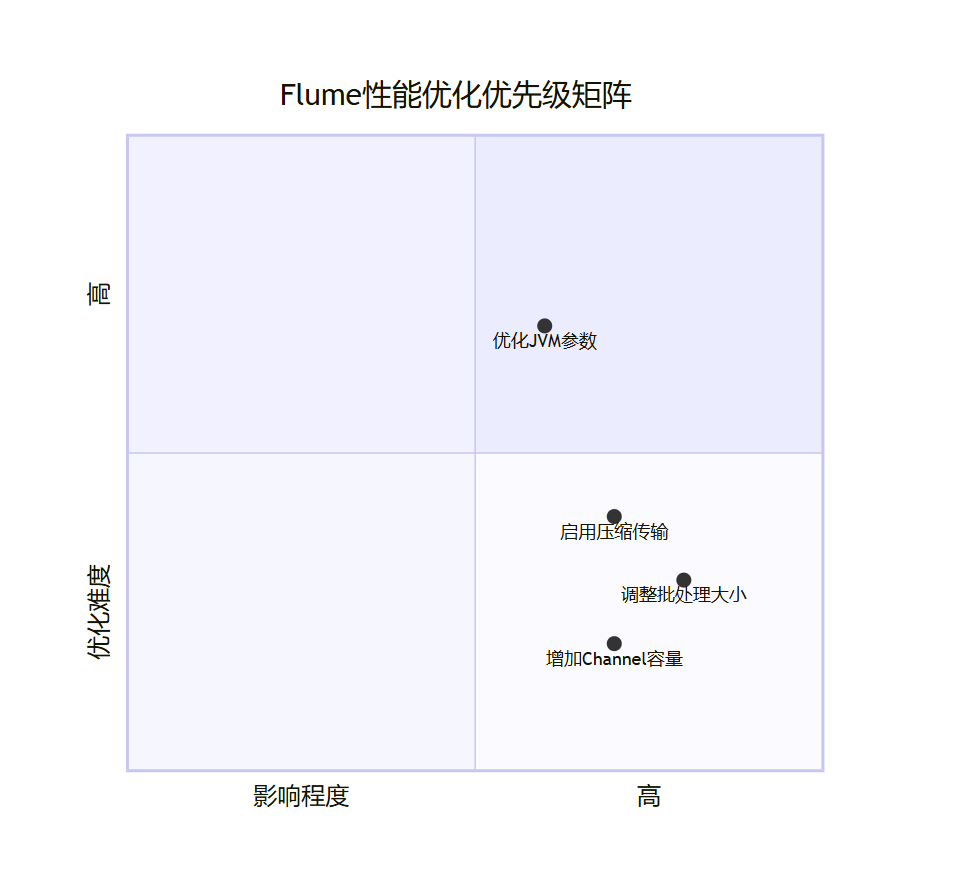
图4:性能优化优先级矩阵 - 根据影响程度和优化难度确定策略
4.3 监控指标收集
java
public class FlumeMonitor {
private CounterGroup counterGroup;
public void collectMetrics() {
Map<String, Number> metrics = new HashMap<>();
// 收集核心指标
metrics.put("events.successful", counterGroup.get("events.successful"));
metrics.put("events.failed", counterGroup.get("events.failed"));
// 计算吞吐量
long currentTime = System.currentTimeMillis();
long processedEvents = counterGroup.get("events.successful");
if (lastCollectTime != null) {
double throughput = (double) (processedEvents - lastProcessedEvents) /
(currentTime - lastCollectTime) * 1000;
metrics.put("throughput.events_per_second", throughput);
}
// 推送到监控系统
pushToMonitoringSystem(metrics);
}
}5. 实战案例分析
5.1 电商日志采集系统配置
properties
# 多源日志采集
ecommerce_agent.sources = app_log_source access_log_source
ecommerce_agent.channels = rt_channel batch_channel
ecommerce_agent.sinks = kafka_sink hdfs_sink
# 应用日志监控
ecommerce_agent.sources.app_log_source.type = exec
ecommerce_agent.sources.app_log_source.command = tail -F /var/log/ecommerce/app.log
ecommerce_agent.sources.app_log_source.batchSize = 1000
# 实时处理Channel
ecommerce_agent.channels.rt_channel.type = memory
ecommerce_agent.channels.rt_channel.capacity = 100000
ecommerce_agent.channels.rt_channel.transactionCapacity = 5000
# 批处理Channel
ecommerce_agent.channels.batch_channel.type = file
ecommerce_agent.channels.batch_channel.capacity = 1000000
# Kafka实时Sink
ecommerce_agent.sinks.kafka_sink.type = org.apache.flume.sink.kafka.KafkaSink
ecommerce_agent.sinks.kafka_sink.batchSize = 100
ecommerce_agent.sinks.kafka_sink.brokerList = kafka1:9092,kafka2:9092,kafka3:9092
ecommerce_agent.sinks.kafka_sink.topic = ecommerce-realtime
# HDFS批处理Sink
ecommerce_agent.sinks.hdfs_sink.type = hdfs
ecommerce_agent.sinks.hdfs_sink.hdfs.path = hdfs://namenode:9000/ecommerce/logs/%Y-%m-%d/%H%M
ecommerce_agent.sinks.hdfs_sink.hdfs.rollInterval = 3600
ecommerce_agent.sinks.hdfs_sink.hdfs.rollSize = 1342177285.2 实时监控告警流程
用户 检测阶段 检测阶段 用户 日志收集 日志收集 用户 异常检测 异常检测 用户 告警触发 告警触发 响应阶段 响应阶段 用户 告警接收 告警接收 用户 问题诊断 问题诊断 用户 故障处理 故障处理 实时日志监控告警流程
图5:实时日志监控告警用户旅程图 - 从问题发现到解决的完整流程
6. 故障诊断与最佳实践
6.1 常见故障与解决方案
6.1.1 Channel满载问题
诊断方法:
bash
# 检查Channel状态
curl http://flume-agent:port/metrics
# 检查内存使用
jstat -gc <pid> | grep -E "(S0|S1|E|O|YG|FGC)"解决方案:
- 增加Channel容量:
agent.channels.memoryChannel.capacity = 5000000 - 优化批处理大小:
agent.sinks.batchSize = 5000 - 启用数据采样策略
6.1.2 网络连接超时
java
public class NetworkDiagnostics {
public void diagnoseConnection(String hostname, int port) {
try (Socket socket = new Socket()) {
socket.connect(new InetSocketAddress(hostname, port), 5000);
System.out.println("连接成功");
} catch (IOException e) {
// 连接诊断逻辑
testDNSResolution(hostname);
testNetworkConnectivity(hostname);
}
}
}6.2 性能优化最佳实践
6.2.1 批量处理优化
java
public class BatchOptimizer {
public void calibrateBatchParameters(Channel channel, Sink sink) {
int channelCapacity = getChannelCapacity(channel);
double sinkThroughput = measureSinkThroughput(sink);
// 计算最优批处理大小
int optimalBatchSize = Math.min(
channelCapacity * 10 / 100, // Channel容量的10%
(int)(sinkThroughput * 5 / 100) // 处理能力的5%
);
System.out.printf("建议批处理大小: %d%n", optimalBatchSize);
}
}6.2.2 内存管理优化
bash
#!/bin/bash
# 获取系统内存信息
TOTAL_MEM=$(free -m | awk 'NR==2{printf "%.0f", $2}')
AVAILABLE_MEM=$(free -m | awk 'NR==2{printf "%.0f", $7}')
# 生成优化的JVM参数
HEAP_SIZE=$(($AVAILABLE_MEM * 60 / 100))
HEAP_MAX=$(($TOTAL_MEM * 70 / 100))
JAVA_OPTS="-Xms${HEAP_SIZE}m -Xmx${HEAP_MAX}m"
JAVA_OPTS="$JAVA_OPTS -XX:+UseG1GC -XX:MaxGCPauseMillis=200"
export FLUME_JAVA_OPTS="$JAVA_OPTS"7. 配置对比分析
| 配置方案 | Channel类型 | 批处理大小 | 适用场景 | 性能表现 | 可靠性 |
|---|---|---|---|---|---|
| 高性能实时 | Memory | 10000 | 实时流处理 | 100% | 中等 |
| 平衡型配置 | Memory | 5000 | 常规日志收集 | 85% | 中等 |
| 高可靠性 | File | 2000 | 关键数据采集 | 60% | 高 |
| 批处理优化 | File | 20000 | 大批量数据迁移 | 45% | 高 |
选择指南:
- 实时性要求高 → Memory Channel + 大批量配置
- 数据安全性要求高 → File Channel + 小批量配置
- 混合业务场景 → 多级路由 + 不同配置组合
总结
本文深入探讨了Apache Flume在大数据采集领域的架构设计、核心组件机制、配置优化策略和实际应用案例。Flume的Source-Channel-Sink三层架构模式,通过解耦的数据流设计实现了高度的可扩展性和维护性。
在性能优化方面,通过合理的参数调优如调整批处理大小、优化内存配置、实施网络压缩等,可以显著提升系统的处理能力。在实际生产环境中,需要根据具体的业务需求和硬件资源情况,制定针对性的优化策略。
展望未来,Flume在云原生部署、容器化集成、智能化监控等方向将继续发展,与新兴大数据处理框架的深度集成将进一步提升其在实时数据处理生态中的地位。
对于大数据平台构建者而言,掌握Flume的架构原理和优化技巧是保障系统稳定运行的重要基础。希望通过本文的指导,能够帮助读者在实际项目中更好地应用和优化Flume,构建出高性能、高可用的数据采集系统。
参考链接
- Apache Flume官方文档 - 官方技术文档和API参考
- Flume架构设计研究 - 学术论文分析架构设计
- 大数据采集最佳实践 - Apache基金会最佳实践
- Flume性能调优案例 - 生产环境优化案例
- Kafka与Flume集成 - 官方集成交档
关键词标签
- #ApacheFlume
- #大数据采集
- #日志处理
- #流式数据
- #系统架构