
企业级MCP部署实战:从开发到生产的完整DevOps流程
🌟 Hello,我是摘星!
🌈 在彩虹般绚烂的技术栈中,我是那个永不停歇的色彩收集者。
🦋 每一个优化都是我培育的花朵,每一个特性都是我放飞的蝴蝶。
🔬 每一次代码审查都是我的显微镜观察,每一次重构都是我的化学实验。
🎵 在编程的交响乐中,我既是指挥家也是演奏者。让我们一起,在技术的音乐厅里,奏响属于程序员的华美乐章。
摘要
作为一名深耕AI基础设施多年的技术博主摘星,我深刻认识到Model Context Protocol(MCP)在企业级应用中的巨大潜力和部署挑战。随着AI Agent技术的快速发展,越来越多的企业开始将MCP集成到其核心业务系统中,但从开发环境到生产环境的部署过程往往充满了复杂性和不确定性。在过去的项目实践中,我见证了许多企业在MCP部署过程中遇到的各种问题:从架构设计的不合理导致的性能瓶颈,到容器化部署中的资源配置错误,再到生产环境中的监控盲区和运维困难。这些问题不仅影响了系统的稳定性和性能,更重要的是阻碍了企业AI能力的快速迭代和创新。因此,建立一套完整的企业级MCP部署DevOps流程变得至关重要。本文将从企业环境下的部署架构设计出发,深入探讨容器化部署与Kubernetes集成的最佳实践,详细介绍CI/CD流水线配置与自动化测试的实施方案,并提供生产环境监控与运维管理的完整解决方案。通过系统性的方法论和实战经验分享,帮助企业技术团队构建稳定、高效、可扩展的MCP部署体系,实现从开发到生产的无缝衔接,为企业AI能力的持续发展奠定坚实的基础设施基础。
1. 企业级MCP部署架构设计
1.1 整体架构概览
企业级MCP部署需要考虑高可用性、可扩展性、安全性和可维护性等多个维度。以下是推荐的整体架构设计:
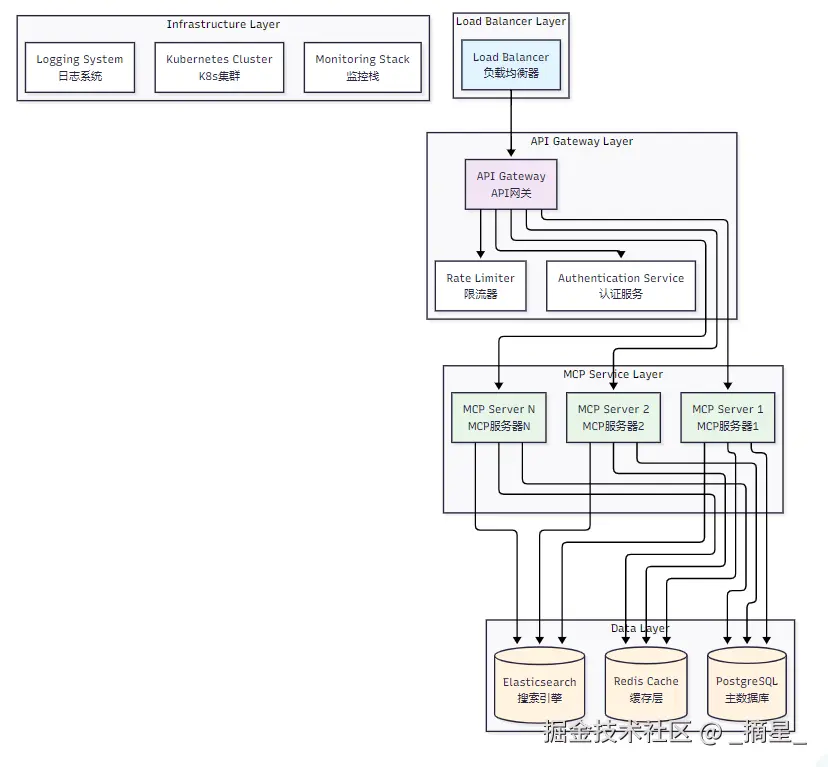
图1:企业级MCP部署整体架构图
1.2 核心组件设计
1.2.1 MCP服务器集群配置
```typescript // mcp-server-config.ts interface MCPServerConfig { server: { port: number; host: string; maxConnections: number; timeout: number; }; cluster: { instances: number; loadBalancing: 'round-robin' | 'least-connections' | 'ip-hash'; healthCheck: { interval: number; timeout: number; retries: number; }; }; resources: { memory: string; cpu: string; storage: string; }; }
const productionConfig: MCPServerConfig = { server: { port: 8080, host: '0.0.0.0', maxConnections: 1000, timeout: 30000 }, cluster: { instances: 3, loadBalancing: 'least-connections', healthCheck: { interval: 10000, timeout: 5000, retries: 3 } }, resources: { memory: '2Gi', cpu: '1000m', storage: '10Gi' } };
yaml
<h4 id="MJhEh">1.2.2 高可用性设计模式</h4>
| 组件 | 高可用策略 | 故障转移时间 | 数据一致性 |
| --- | --- | --- | --- |
| MCP服务器 | 多实例部署 + 健康检查 | < 5秒 | 最终一致性 |
| 数据库 | 主从复制 + 自动故障转移 | < 30秒 | 强一致性 |
| 缓存层 | Redis Cluster | < 2秒 | 最终一致性 |
| 负载均衡器 | 双机热备 | < 1秒 | 无状态 |
<h3 id="vmNVm">1.3 安全架构设计</h3>
```yaml
# security-config.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: mcp-security-config
data:
security.yaml: |
authentication:
type: "jwt"
secret: "${JWT_SECRET}"
expiration: "24h"
authorization:
rbac:
enabled: true
policies:
- role: "admin"
permissions: ["read", "write", "delete"]
- role: "user"
permissions: ["read"]
encryption:
tls:
enabled: true
cert: "/etc/ssl/certs/mcp.crt"
key: "/etc/ssl/private/mcp.key"
network:
allowedOrigins:
- "https://app.company.com"
- "https://admin.company.com"
rateLimiting:
requests: 1000
window: "1h"2. 容器化部署与Kubernetes集成
2.1 Docker容器化配置
2.1.1 多阶段构建Dockerfile
```dockerfile # Dockerfile # 第一阶段:构建阶段 FROM node:18-alpine AS builder
WORKDIR /app
复制依赖文件
COPY package*.json ./ COPY tsconfig.json ./
安装依赖
RUN npm ci --only=production && npm cache clean --force
复制源代码
COPY src/ ./src/
构建应用
RUN npm run build
第二阶段:运行阶段
FROM node:18-alpine AS runtime
创建非root用户
RUN addgroup -g 1001 -S nodejs &&
adduser -S mcp -u 1001
WORKDIR /app
复制构建产物
COPY --from=builder --chown=mcp:nodejs /app/dist ./dist COPY --from=builder --chown=mcp:nodejs /app/node_modules ./node_modules COPY --from=builder --chown=mcp:nodejs /app/package.json ./
健康检查
HEALTHCHECK --interval=30s --timeout=3s --start-period=5s --retries=3
CMD curl -f http://localhost:8080/health || exit 1
切换到非root用户
USER mcp
暴露端口
EXPOSE 8080
启动命令
CMD "node", "dist/server.js"
yaml
<h4 id="f2HPu">2.1.2 容器优化配置</h4>
```yaml
# docker-compose.yml
version: '3.8'
services:
mcp-server:
build:
context: .
dockerfile: Dockerfile
target: runtime
image: mcp-server:latest
container_name: mcp-server
restart: unless-stopped
# 资源限制
deploy:
resources:
limits:
memory: 2G
cpus: '1.0'
reservations:
memory: 1G
cpus: '0.5'
# 环境变量
environment:
- NODE_ENV=production
- LOG_LEVEL=info
- DB_HOST=postgres
- REDIS_HOST=redis
# 端口映射
ports:
- "8080:8080"
# 健康检查
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8080/health"]
interval: 30s
timeout: 10s
retries: 3
start_period: 40s
# 依赖服务
depends_on:
postgres:
condition: service_healthy
redis:
condition: service_healthy
# 网络配置
networks:
- mcp-network
postgres:
image: postgres:15-alpine
container_name: mcp-postgres
restart: unless-stopped
environment:
- POSTGRES_DB=mcp
- POSTGRES_USER=mcp_user
- POSTGRES_PASSWORD=${DB_PASSWORD}
volumes:
- postgres_data:/var/lib/postgresql/data
healthcheck:
test: ["CMD-SHELL", "pg_isready -U mcp_user -d mcp"]
interval: 10s
timeout: 5s
retries: 5
networks:
- mcp-network
redis:
image: redis:7-alpine
container_name: mcp-redis
restart: unless-stopped
command: redis-server --appendonly yes --requirepass ${REDIS_PASSWORD}
volumes:
- redis_data:/data
healthcheck:
test: ["CMD", "redis-cli", "ping"]
interval: 10s
timeout: 3s
retries: 3
networks:
- mcp-network
volumes:
postgres_data:
redis_data:
networks:
mcp-network:
driver: bridge2.2 Kubernetes部署配置
2.2.1 命名空间和资源配置
```yaml # k8s/namespace.yaml apiVersion: v1 kind: Namespace metadata: name: mcp-production labels: name: mcp-production environment: production
k8s/deployment.yaml
apiVersion: apps/v1 kind: Deployment metadata: name: mcp-server namespace: mcp-production labels: app: mcp-server version: v1.0.0 spec: replicas: 3 strategy: type: RollingUpdate rollingUpdate: maxSurge: 1 maxUnavailable: 0 selector: matchLabels: app: mcp-server template: metadata: labels: app: mcp-server version: v1.0.0 spec: # 安全上下文 securityContext: runAsNonRoot: true runAsUser: 1001 fsGroup: 1001
yaml
# 容器配置
containers:
- name: mcp-server
image: mcp-server:v1.0.0
imagePullPolicy: Always
# 端口配置
ports:
- containerPort: 8080
name: http
protocol: TCP
# 环境变量
env:
- name: NODE_ENV
value: "production"
- name: DB_HOST
valueFrom:
secretKeyRef:
name: mcp-secrets
key: db-host
- name: DB_PASSWORD
valueFrom:
secretKeyRef:
name: mcp-secrets
key: db-password
# 资源限制
resources:
requests:
memory: "1Gi"
cpu: "500m"
limits:
memory: "2Gi"
cpu: "1000m"
# 健康检查
livenessProbe:
httpGet:
path: /health
port: 8080
initialDelaySeconds: 30
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3
readinessProbe:
httpGet:
path: /ready
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
timeoutSeconds: 3
failureThreshold: 3
# 卷挂载
volumeMounts:
- name: config-volume
mountPath: /app/config
readOnly: true
- name: logs-volume
mountPath: /app/logs
# 卷配置
volumes:
- name: config-volume
configMap:
name: mcp-config
- name: logs-volume
emptyDir: {}
# 节点选择
nodeSelector:
kubernetes.io/os: linux
# 容忍度配置
tolerations:
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule"
yaml
<h4 id="bq0Is">2.2.2 服务和Ingress配置</h4>
```yaml
# k8s/service.yaml
apiVersion: v1
kind: Service
metadata:
name: mcp-server-service
namespace: mcp-production
labels:
app: mcp-server
spec:
type: ClusterIP
ports:
- port: 80
targetPort: 8080
protocol: TCP
name: http
selector:
app: mcp-server
---
# k8s/ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: mcp-server-ingress
namespace: mcp-production
annotations:
kubernetes.io/ingress.class: "nginx"
nginx.ingress.kubernetes.io/ssl-redirect: "true"
nginx.ingress.kubernetes.io/use-regex: "true"
nginx.ingress.kubernetes.io/rate-limit: "100"
nginx.ingress.kubernetes.io/rate-limit-window: "1m"
cert-manager.io/cluster-issuer: "letsencrypt-prod"
spec:
tls:
- hosts:
- mcp-api.company.com
secretName: mcp-tls-secret
rules:
- host: mcp-api.company.com
http:
paths:
- path: /api/v1/mcp
pathType: Prefix
backend:
service:
name: mcp-server-service
port:
number: 802.3 配置管理和密钥管理
```yaml # k8s/configmap.yaml apiVersion: v1 kind: ConfigMap metadata: name: mcp-config namespace: mcp-production data: app.yaml: | server: port: 8080 timeout: 30000
yaml
logging:
level: info
format: json
features:
rateLimiting: true
caching: true
metrics: truek8s/secret.yaml
apiVersion: v1 kind: Secret metadata: name: mcp-secrets namespace: mcp-production type: Opaque data: db-host: cG9zdGdyZXNxbC1zZXJ2aWNl # base64 encoded db-password: c3VwZXJfc2VjcmV0X3Bhc3N3b3Jk # base64 encoded jwt-secret: and0X3NlY3JldF9rZXlfZm9yX2F1dGg= # base64 encoded
yaml
<h2 id="quk1x">3. CI/CD流水线配置与自动化测试</h2>
<h3 id="KFVsL">3.1 GitLab CI/CD配置</h3>
```yaml
# .gitlab-ci.yml
stages:
- test
- build
- security-scan
- deploy-staging
- integration-test
- deploy-production
variables:
DOCKER_REGISTRY: registry.company.com
IMAGE_NAME: mcp-server
KUBERNETES_NAMESPACE_STAGING: mcp-staging
KUBERNETES_NAMESPACE_PRODUCTION: mcp-production
# 单元测试阶段
unit-test:
stage: test
image: node:18-alpine
cache:
paths:
- node_modules/
script:
- npm ci
- npm run test:unit
- npm run test:coverage
coverage: '/Lines\s*:\s*(\d+\.\d+)%/'
artifacts:
reports:
coverage_report:
coverage_format: cobertura
path: coverage/cobertura-coverage.xml
paths:
- coverage/
expire_in: 1 week
only:
- merge_requests
- main
- develop
# 代码质量检查
code-quality:
stage: test
image: node:18-alpine
script:
- npm ci
- npm run lint
- npm run type-check
- npm audit --audit-level moderate
artifacts:
reports:
codequality: gl-code-quality-report.json
only:
- merge_requests
- main
# 构建Docker镜像
build-image:
stage: build
image: docker:20.10.16
services:
- docker:20.10.16-dind
variables:
DOCKER_TLS_CERTDIR: "/certs"
before_script:
- echo $CI_REGISTRY_PASSWORD | docker login -u $CI_REGISTRY_USER --password-stdin $CI_REGISTRY
script:
- docker build -t $CI_REGISTRY_IMAGE:$CI_COMMIT_SHA .
- docker build -t $CI_REGISTRY_IMAGE:latest .
- docker push $CI_REGISTRY_IMAGE:$CI_COMMIT_SHA
- docker push $CI_REGISTRY_IMAGE:latest
only:
- main
- develop
# 安全扫描
security-scan:
stage: security-scan
image:
name: aquasec/trivy:latest
entrypoint: [""]
script:
- trivy image --exit-code 0 --format template --template "@contrib/sarif.tpl" -o gl-sast-report.json $CI_REGISTRY_IMAGE:$CI_COMMIT_SHA
- trivy image --exit-code 1 --severity HIGH,CRITICAL $CI_REGISTRY_IMAGE:$CI_COMMIT_SHA
artifacts:
reports:
sast: gl-sast-report.json
only:
- main
- develop
# 部署到测试环境
deploy-staging:
stage: deploy-staging
image: bitnami/kubectl:latest
environment:
name: staging
url: https://mcp-staging.company.com
script:
- kubectl config use-context $KUBE_CONTEXT_STAGING
- kubectl set image deployment/mcp-server mcp-server=$CI_REGISTRY_IMAGE:$CI_COMMIT_SHA -n $KUBERNETES_NAMESPACE_STAGING
- kubectl rollout status deployment/mcp-server -n $KUBERNETES_NAMESPACE_STAGING --timeout=300s
only:
- develop
# 集成测试
integration-test:
stage: integration-test
image: node:18-alpine
services:
- postgres:13-alpine
- redis:6-alpine
variables:
POSTGRES_DB: mcp_test
POSTGRES_USER: test_user
POSTGRES_PASSWORD: test_password
REDIS_URL: redis://redis:6379
script:
- npm ci
- npm run test:integration
- npm run test:e2e
artifacts:
reports:
junit: test-results.xml
only:
- develop
- main
# 生产环境部署
deploy-production:
stage: deploy-production
image: bitnami/kubectl:latest
environment:
name: production
url: https://mcp-api.company.com
script:
- kubectl config use-context $KUBE_CONTEXT_PRODUCTION
- kubectl set image deployment/mcp-server mcp-server=$CI_REGISTRY_IMAGE:$CI_COMMIT_SHA -n $KUBERNETES_NAMESPACE_PRODUCTION
- kubectl rollout status deployment/mcp-server -n $KUBERNETES_NAMESPACE_PRODUCTION --timeout=600s
when: manual
only:
- main3.2 自动化测试策略
3.2.1 测试金字塔实现
图2:自动化测试金字塔架构图
3.2.2 单元测试配置
```typescript // tests/unit/mcp-server.test.ts import { MCPServer } from '../../src/server/mcp-server'; import { MockToolProvider } from '../mocks/tool-provider.mock';
describe('MCPServer', () => { let server: MCPServer; let mockToolProvider: MockToolProvider;
beforeEach(() => { mockToolProvider = new MockToolProvider(); server = new MCPServer({ port: 8080, toolProviders: mockToolProvider }); });
afterEach(async () => { await server.close(); });
describe('Tool Execution', () => { it('should execute tool successfully', async () => { // Arrange const toolName = 'test-tool'; const toolArgs = { input: 'test-input' }; const expectedResult = { output: 'test-output' };
scss
mockToolProvider.mockTool(toolName, expectedResult);
// Act
const result = await server.executeTool(toolName, toolArgs);
// Assert
expect(result).toEqual(expectedResult);
expect(mockToolProvider.getCallCount(toolName)).toBe(1);
});
it('should handle tool execution errors', async () => {
// Arrange
const toolName = 'failing-tool';
const error = new Error('Tool execution failed');
mockToolProvider.mockToolError(toolName, error);
// Act & Assert
await expect(server.executeTool(toolName, {}))
.rejects.toThrow('Tool execution failed');
});});
describe('Resource Management', () => { it('should list available resources', async () => { // Arrange const expectedResources = { uri: 'file://test.txt', name: 'Test File' }, { uri: 'db://users', name: 'Users Database' } ;
scss
mockToolProvider.mockResources(expectedResources);
// Act
const resources = await server.listResources();
// Assert
expect(resources).toEqual(expectedResources);
});}); });
dart
<h4 id="l6iSH">3.2.3 集成测试配置</h4>
```typescript
// tests/integration/api.integration.test.ts
import request from 'supertest';
import { TestContainers, StartedTestContainer } from 'testcontainers';
import { PostgreSqlContainer } from '@testcontainers/postgresql';
import { RedisContainer } from '@testcontainers/redis';
import { createApp } from '../../src/app';
describe('MCP API Integration Tests', () => {
let app: any;
let postgresContainer: StartedTestContainer;
let redisContainer: StartedTestContainer;
beforeAll(async () => {
// 启动测试容器
postgresContainer = await new PostgreSqlContainer()
.withDatabase('mcp_test')
.withUsername('test_user')
.withPassword('test_password')
.start();
redisContainer = await new RedisContainer()
.start();
// 创建应用实例
app = createApp({
database: {
host: postgresContainer.getHost(),
port: postgresContainer.getPort(),
database: 'mcp_test',
username: 'test_user',
password: 'test_password'
},
redis: {
host: redisContainer.getHost(),
port: redisContainer.getPort()
}
});
}, 60000);
afterAll(async () => {
await postgresContainer.stop();
await redisContainer.stop();
});
describe('POST /api/v1/mcp/tools/execute', () => {
it('should execute tool successfully', async () => {
const response = await request(app)
.post('/api/v1/mcp/tools/execute')
.send({
name: 'file-reader',
arguments: {
path: '/test/file.txt'
}
})
.expect(200);
expect(response.body).toHaveProperty('result');
expect(response.body.success).toBe(true);
});
it('should return error for invalid tool', async () => {
const response = await request(app)
.post('/api/v1/mcp/tools/execute')
.send({
name: 'non-existent-tool',
arguments: {}
})
.expect(404);
expect(response.body.error).toContain('Tool not found');
});
});
describe('GET /api/v1/mcp/resources', () => {
it('should list available resources', async () => {
const response = await request(app)
.get('/api/v1/mcp/resources')
.expect(200);
expect(response.body).toHaveProperty('resources');
expect(Array.isArray(response.body.resources)).toBe(true);
});
});
});3.3 性能测试和负载测试
3.3.1 性能测试配置
```javascript // tests/performance/load-test.js import http from 'k6/http'; import { check, sleep } from 'k6'; import { Rate } from 'k6/metrics';
// 自定义指标 const errorRate = new Rate('errors');
export const options = { stages: { duration: '2m', target: 100 }, // 预热阶段 { duration: '5m', target: 100 }, // 稳定负载 { duration: '2m', target: 200 }, // 增加负载 { duration: '5m', target: 200 }, // 高负载稳定 { duration: '2m', target: 0 }, // 降负载 , thresholds: { http_req_duration: 'p(95)\<500', // 95%的请求响应时间小于500ms http_req_failed: 'rate\<0.1', // 错误率小于10% errors: 'rate\<0.1', // 自定义错误率小于10% }, };
export default function () { const payload = JSON.stringify({ name: 'test-tool', arguments: { input: 'performance test data' } });
const params = { headers: { 'Content-Type': 'application/json', 'Authorization': 'Bearer test-token' }, };
const response = http.post( 'mcp-staging.company.com/api/v1/mcp/...', payload, params );
const result = check(response, { 'status is 200': (r) => r.status === 200, 'response time < 500ms': (r) => r.timings.duration < 500, 'response has result': (r) => r.json('result') !== undefined, });
errorRate.add(!result); sleep(1); }
kotlin
<h2 id="mF1sV">4. 生产环境监控与运维管理</h2>
<h3 id="BpyBh">4.1 监控体系架构</h3>
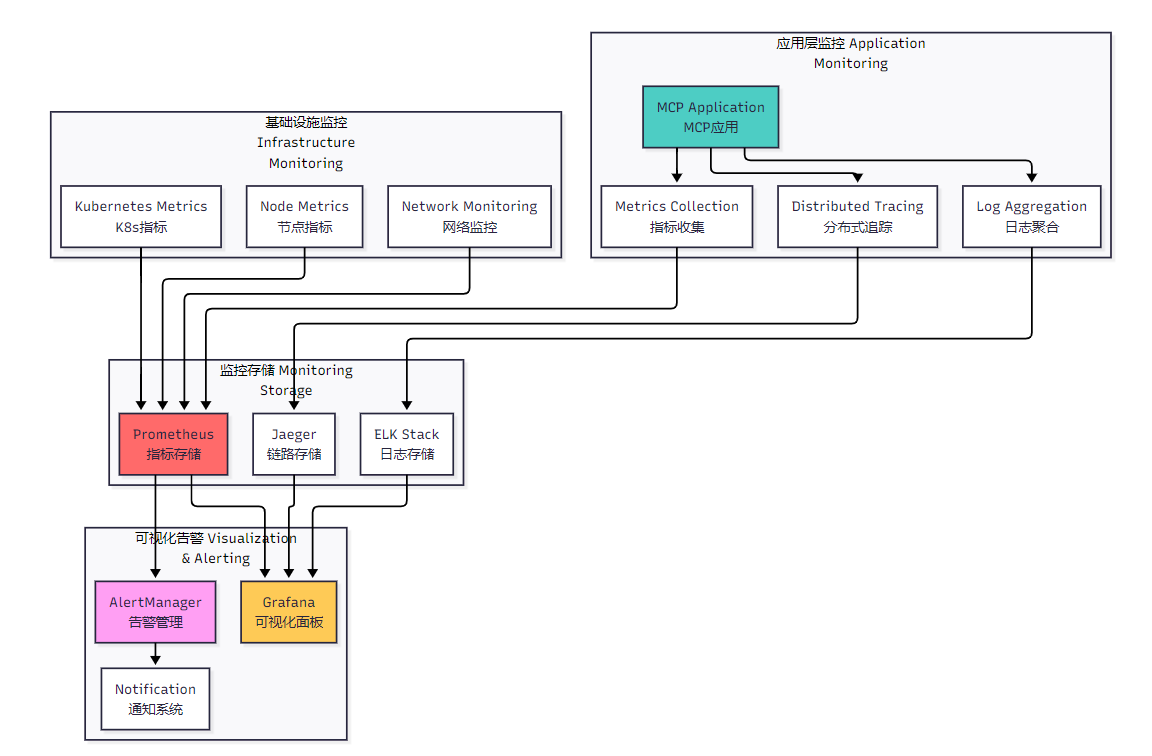
**图3:生产环境监控体系架构图**
<h3 id="gfBc9">4.2 Prometheus监控配置</h3>
<h4 id="XZEOz">4.2.1 监控指标定义</h4>
```typescript
// src/monitoring/metrics.ts
import { register, Counter, Histogram, Gauge } from 'prom-client';
export class MCPMetrics {
// 请求计数器
private requestCounter = new Counter({
name: 'mcp_requests_total',
help: 'Total number of MCP requests',
labelNames: ['method', 'status', 'endpoint']
});
// 请求持续时间直方图
private requestDuration = new Histogram({
name: 'mcp_request_duration_seconds',
help: 'Duration of MCP requests in seconds',
labelNames: ['method', 'endpoint'],
buckets: [0.1, 0.5, 1, 2, 5, 10]
});
// 活跃连接数
private activeConnections = new Gauge({
name: 'mcp_active_connections',
help: 'Number of active MCP connections'
});
// 工具执行指标
private toolExecutions = new Counter({
name: 'mcp_tool_executions_total',
help: 'Total number of tool executions',
labelNames: ['tool_name', 'status']
});
// 资源访问指标
private resourceAccess = new Counter({
name: 'mcp_resource_access_total',
help: 'Total number of resource accesses',
labelNames: ['resource_type', 'operation']
});
constructor() {
register.registerMetric(this.requestCounter);
register.registerMetric(this.requestDuration);
register.registerMetric(this.activeConnections);
register.registerMetric(this.toolExecutions);
register.registerMetric(this.resourceAccess);
}
// 记录请求指标
recordRequest(method: string, endpoint: string, status: string, duration: number) {
this.requestCounter.inc({ method, endpoint, status });
this.requestDuration.observe({ method, endpoint }, duration);
}
// 记录工具执行
recordToolExecution(toolName: string, status: string) {
this.toolExecutions.inc({ tool_name: toolName, status });
}
// 记录资源访问
recordResourceAccess(resourceType: string, operation: string) {
this.resourceAccess.inc({ resource_type: resourceType, operation });
}
// 更新活跃连接数
setActiveConnections(count: number) {
this.activeConnections.set(count);
}
// 获取指标端点
async getMetrics(): Promise<string> {
return register.metrics();
}
}4.2.2 Prometheus配置文件
```yaml # prometheus.yml global: scrape_interval: 15s evaluation_interval: 15s
rule_files:
- "mcp_rules.yml"
alerting: alertmanagers: - static_configs: - targets: - alertmanager:9093
scrape_configs:
MCP服务器监控
- job_name: 'mcp-server' static_configs:
- targets: 'mcp-server:8080' metrics_path: '/metrics' scrape_interval: 10s scrape_timeout: 5s
Kubernetes监控
- job_name: 'kubernetes-apiservers' kubernetes_sd_configs:
- role: endpoints scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs:
- source_labels: __meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name action: keep regex: default;kubernetes;https
节点监控
- job_name: 'kubernetes-nodes' kubernetes_sd_configs:
- role: node scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs:
- action: labelmap regex: _meta_kubernetes_node_label(.+)
Pod监控
- job_name: 'kubernetes-pods' kubernetes_sd_configs:
- role: pod relabel_configs:
- source_labels: __meta_kubernetes_pod_annotation_prometheus_io_scrape action: keep regex: true
- source_labels: __meta_kubernetes_pod_annotation_prometheus_io_path action: replace target_label: metrics_path regex: (.+)
yaml
<h3 id="Xl42F">4.3 告警规则配置</h3>
```yaml
# mcp_rules.yml
groups:
- name: mcp_alerts
rules:
# 高错误率告警
- alert: MCPHighErrorRate
expr: rate(mcp_requests_total{status=~"5.."}[5m]) / rate(mcp_requests_total[5m]) > 0.05
for: 2m
labels:
severity: critical
annotations:
summary: "MCP服务器错误率过高"
description: "MCP服务器在过去5分钟内错误率超过5%,当前值:{{ $value | humanizePercentage }}"
# 响应时间过长告警
- alert: MCPHighLatency
expr: histogram_quantile(0.95, rate(mcp_request_duration_seconds_bucket[5m])) > 1
for: 5m
labels:
severity: warning
annotations:
summary: "MCP服务器响应时间过长"
description: "MCP服务器95%分位响应时间超过1秒,当前值:{{ $value }}s"
# 服务不可用告警
- alert: MCPServiceDown
expr: up{job="mcp-server"} == 0
for: 1m
labels:
severity: critical
annotations:
summary: "MCP服务器不可用"
description: "MCP服务器 {{ $labels.instance }} 已停止响应超过1分钟"
# 内存使用率过高告警
- alert: MCPHighMemoryUsage
expr: (container_memory_usage_bytes{pod=~"mcp-server-.*"} / container_spec_memory_limit_bytes) > 0.85
for: 5m
labels:
severity: warning
annotations:
summary: "MCP服务器内存使用率过高"
description: "Pod {{ $labels.pod }} 内存使用率超过85%,当前值:{{ $value | humanizePercentage }}"
# CPU使用率过高告警
- alert: MCPHighCPUUsage
expr: rate(container_cpu_usage_seconds_total{pod=~"mcp-server-.*"}[5m]) > 0.8
for: 5m
labels:
severity: warning
annotations:
summary: "MCP服务器CPU使用率过高"
description: "Pod {{ $labels.pod }} CPU使用率超过80%,当前值:{{ $value | humanizePercentage }}"4.4 Grafana仪表板配置
```json { "dashboard": { "id": null, "title": "MCP服务器监控仪表板", "tags": "mcp", "monitoring", "timezone": "browser", "panels": { "id": 1, "title": "请求速率", "type": "graph", "targets": \[ { "expr": "rate(mcp_requests_total\[5m)", "legendFormat": "总请求速率" }, { "expr": "rate(mcp_requests_total{status=~\"2..\"}5m)", "legendFormat": "成功请求速率" }, { "expr": "rate(mcp_requests_total{status=~\"5..\"}5m)", "legendFormat": "错误请求速率" } ], "yAxes": { "label": "请求/秒", "min": 0 } , "gridPos": { "h": 8, "w": 12, "x": 0, "y": 0 } }, { "id": 2, "title": "响应时间分布", "type": "graph", "targets": { "expr": "histogram_quantile(0.50, rate(mcp_request_duration_seconds_bucket\[5m))", "legendFormat": "50th percentile" }, { "expr": "histogram_quantile(0.95, rate(mcp_request_duration_seconds_bucket5m))", "legendFormat": "95th percentile" }, { "expr": "histogram_quantile(0.99, rate(mcp_request_duration_seconds_bucket5m))", "legendFormat": "99th percentile" } ], "yAxes": { "label": "秒", "min": 0 } , "gridPos": { "h": 8, "w": 12, "x": 12, "y": 0 } }, { "id": 3, "title": "错误率", "type": "singlestat", "targets": { "expr": "rate(mcp_requests_total{status=\~\\"5..\\"}\[5m) / rate(mcp_requests_total5m) * 100", "legendFormat": "错误率" } ], "valueName": "current", "format": "percent", "thresholds": "1,5", "colorBackground": true, "gridPos": { "h": 4, "w": 6, "x": 0, "y": 8 } }, { "id": 4, "title": "活跃连接数", "type": "singlestat", "targets": { "expr": "mcp_active_connections", "legendFormat": "活跃连接" } , "valueName": "current", "format": "short", "gridPos": { "h": 4, "w": 6, "x": 6, "y": 8 } } ], "time": { "from": "now-1h", "to": "now" }, "refresh": "5s" } } ```
4.5 日志管理与分析
4.5.1 结构化日志配置
```typescript // src/logging/logger.ts import winston from 'winston'; import { ElasticsearchTransport } from 'winston-elasticsearch';
export class MCPLogger { private logger: winston.Logger;
constructor() { const esTransport = new ElasticsearchTransport({ level: 'info', clientOpts: { node: process.env.ELASTICSEARCH_URL || 'http://elasticsearch:9200' }, index: 'mcp-logs', indexTemplate: { name: 'mcp-logs-template', pattern: 'mcp-logs-*', settings: { number_of_shards: 1, number_of_replicas: 1 }, mappings: { properties: { '@timestamp': { type: 'date' }, level: { type: 'keyword' }, message: { type: 'text' }, service: { type: 'keyword' }, traceId: { type: 'keyword' }, userId: { type: 'keyword' }, toolName: { type: 'keyword' }, duration: { type: 'float' } } } } });
css
this.logger = winston.createLogger({
level: process.env.LOG_LEVEL || 'info',
format: winston.format.combine(
winston.format.timestamp(),
winston.format.errors({ stack: true }),
winston.format.json()
),
defaultMeta: {
service: 'mcp-server',
version: process.env.APP_VERSION || '1.0.0'
},
transports: [
new winston.transports.Console({
format: winston.format.combine(
winston.format.colorize(),
winston.format.simple()
)
}),
esTransport
]
});}
info(message: string, meta?: any) { this.logger.info(message, meta); }
error(message: string, error?: Error, meta?: any) { this.logger.error(message, { error: error?.stack, ...meta }); }
warn(message: string, meta?: any) { this.logger.warn(message, meta); }
debug(message: string, meta?: any) { this.logger.debug(message, meta); }
// 记录工具执行日志 logToolExecution(toolName: string, userId: string, duration: number, success: boolean, traceId?: string) { this.info('Tool execution completed', { toolName, userId, duration, success, traceId, type: 'tool_execution' }); }
// 记录资源访问日志 logResourceAccess(resourceUri: string, operation: string, userId: string, traceId?: string) { this.info('Resource accessed', { resourceUri, operation, userId, traceId, type: 'resource_access' }); } }
csharp
<h4 id="xOiGS">4.5.2 分布式链路追踪</h4>
```typescript
// src/tracing/tracer.ts
import { NodeSDK } from '@opentelemetry/sdk-node';
import { JaegerExporter } from '@opentelemetry/exporter-jaeger';
import { Resource } from '@opentelemetry/resources';
import { SemanticResourceAttributes } from '@opentelemetry/semantic-conventions';
import { trace, context, SpanStatusCode } from '@opentelemetry/api';
export class MCPTracer {
private sdk: NodeSDK;
private tracer: any;
constructor() {
const jaegerExporter = new JaegerExporter({
endpoint: process.env.JAEGER_ENDPOINT || 'http://jaeger:14268/api/traces',
});
this.sdk = new NodeSDK({
resource: new Resource({
[SemanticResourceAttributes.SERVICE_NAME]: 'mcp-server',
[SemanticResourceAttributes.SERVICE_VERSION]: process.env.APP_VERSION || '1.0.0',
}),
traceExporter: jaegerExporter,
});
this.sdk.start();
this.tracer = trace.getTracer('mcp-server');
}
// 创建工具执行跨度
async traceToolExecution<T>(
toolName: string,
operation: () => Promise<T>,
attributes?: Record<string, string | number>
): Promise<T> {
return this.tracer.startActiveSpan(`tool.${toolName}`, async (span: any) => {
try {
span.setAttributes({
'tool.name': toolName,
'operation.type': 'tool_execution',
...attributes
});
const result = await operation();
span.setStatus({ code: SpanStatusCode.OK });
return result;
} catch (error) {
span.setStatus({
code: SpanStatusCode.ERROR,
message: error instanceof Error ? error.message : 'Unknown error'
});
span.recordException(error as Error);
throw error;
} finally {
span.end();
}
});
}
// 创建资源访问跨度
async traceResourceAccess<T>(
resourceUri: string,
operation: string,
handler: () => Promise<T>
): Promise<T> {
return this.tracer.startActiveSpan(`resource.${operation}`, async (span: any) => {
try {
span.setAttributes({
'resource.uri': resourceUri,
'resource.operation': operation,
'operation.type': 'resource_access'
});
const result = await handler();
span.setStatus({ code: SpanStatusCode.OK });
return result;
} catch (error) {
span.setStatus({
code: SpanStatusCode.ERROR,
message: error instanceof Error ? error.message : 'Unknown error'
});
span.recordException(error as Error);
throw error;
} finally {
span.end();
}
});
}
// 获取当前跟踪ID
getCurrentTraceId(): string | undefined {
const activeSpan = trace.getActiveSpan();
return activeSpan?.spanContext().traceId;
}
}5. 运维自动化与故障处理
5.1 自动化运维脚本
```bash #!/bin/bash # scripts/deploy.sh - 自动化部署脚本
set -e
配置变量
NAMESPACE= NAMESPACE:−"mcp−production"IMAGETAG={IMAGE_TAG:-"latest"} KUBECTL_TIMEOUT=${KUBECTL_TIMEOUT:-"300s"}
颜色输出
RED='\033[0;31m' GREEN='\033[0;32m' YELLOW='\033[1;33m' NC='\033[0m' # No Color
log_info() { echo -e " GREENINFO{NC} $1" }
log_warn() { echo -e " YELLOWWARN{NC} $1" }
log_error() { echo -e " REDERROR{NC} $1" }
检查前置条件
check_prerequisites() { log_info "检查部署前置条件..."
bash
# 检查kubectl
if ! command -v kubectl &> /dev/null; then
log_error "kubectl 未安装"
exit 1
fi
# 检查集群连接
if ! kubectl cluster-info &> /dev/null; then
log_error "无法连接到Kubernetes集群"
exit 1
fi
# 检查命名空间
if ! kubectl get namespace $NAMESPACE &> /dev/null; then
log_warn "命名空间 $NAMESPACE 不存在,正在创建..."
kubectl create namespace $NAMESPACE
fi
log_info "前置条件检查完成"}
部署配置
deploy_configs() { log_info "部署配置文件..."
bash
kubectl apply -f k8s/configmap.yaml -n $NAMESPACE
kubectl apply -f k8s/secret.yaml -n $NAMESPACE
log_info "配置文件部署完成"}
部署应用
deploy_application() { log_info "部署MCP服务器..."
bash
# 更新镜像标签
sed -i.bak "s|image: mcp-server:.*|image: mcp-server:$IMAGE_TAG|g" k8s/deployment.yaml
# 应用部署配置
kubectl apply -f k8s/deployment.yaml -n $NAMESPACE
kubectl apply -f k8s/service.yaml -n $NAMESPACE
kubectl apply -f k8s/ingress.yaml -n $NAMESPACE
# 等待部署完成
log_info "等待部署完成..."
kubectl rollout status deployment/mcp-server -n $NAMESPACE --timeout=$KUBECTL_TIMEOUT
# 恢复原始文件
mv k8s/deployment.yaml.bak k8s/deployment.yaml
log_info "应用部署完成"}
健康检查
health_check() { log_info "执行健康检查..."
bash
# 检查Pod状态
READY_PODS=$(kubectl get pods -n $NAMESPACE -l app=mcp-server -o jsonpath='{.items[*].status.conditions[?(@.type=="Ready")].status}' | grep -o True | wc -l)
TOTAL_PODS=$(kubectl get pods -n $NAMESPACE -l app=mcp-server --no-headers | wc -l)
if [ "$READY_PODS" -eq "$TOTAL_PODS" ] && [ "$TOTAL_PODS" -gt 0 ]; then
log_info "健康检查通过: $READY_PODS/$TOTAL_PODS pods ready"
else
log_error "健康检查失败: $READY_PODS/$TOTAL_PODS pods ready"
exit 1
fi
# 检查服务端点
SERVICE_IP=$(kubectl get service mcp-server-service -n $NAMESPACE -o jsonpath='{.spec.clusterIP}')
if curl -f http://$SERVICE_IP/health &> /dev/null; then
log_info "服务端点健康检查通过"
else
log_warn "服务端点健康检查失败,但继续部署"
fi}
回滚函数
rollback() { log_warn "执行回滚操作..." kubectl rollout undo deployment/mcp-server -n NAMESPACEkubectlrolloutstatusdeployment/mcp−server−nNAMESPACE --timeout=$KUBECTL_TIMEOUT log_info "回滚完成" }
主函数
main() { log_info "开始MCP服务器部署流程..."
bash
check_prerequisites
deploy_configs
deploy_application
# 健康检查失败时自动回滚
if ! health_check; then
log_error "部署失败,执行回滚..."
rollback
exit 1
fi
log_info "MCP服务器部署成功完成!"
# 显示部署信息
echo ""
echo "部署信息:"
echo "- 命名空间: $NAMESPACE"
echo "- 镜像标签: $IMAGE_TAG"
echo "- Pod状态:"
kubectl get pods -n $NAMESPACE -l app=mcp-server
echo ""
echo "- 服务状态:"
kubectl get services -n $NAMESPACE -l app=mcp-server}
错误处理
trap 'log_error "部署过程中发生错误,退出码: $?"' ERR
执行主函数
main "$@"
python
<h3 id="qr9YE">5.2 故障自动恢复</h3>
```python
# scripts/auto_recovery.py - 自动故障恢复脚本
import time
import logging
import requests
import subprocess
from typing import Dict, List
from dataclasses import dataclass
from enum import Enum
class HealthStatus(Enum):
HEALTHY = "healthy"
DEGRADED = "degraded"
UNHEALTHY = "unhealthy"
@dataclass
class HealthCheck:
name: str
url: str
timeout: int = 5
retries: int = 3
expected_status: int = 200
class AutoRecoveryManager:
def __init__(self, config: Dict):
self.config = config
self.logger = self._setup_logging()
self.health_checks = self._load_health_checks()
self.recovery_actions = self._load_recovery_actions()
def _setup_logging(self) -> logging.Logger:
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
return logging.getLogger('auto_recovery')
def _load_health_checks(self) -> List[HealthCheck]:
checks = []
for check_config in self.config.get('health_checks', []):
checks.append(HealthCheck(**check_config))
return checks
def _load_recovery_actions(self) -> Dict:
return self.config.get('recovery_actions', {})
def check_health(self, check: HealthCheck) -> bool:
"""执行单个健康检查"""
for attempt in range(check.retries):
try:
response = requests.get(
check.url,
timeout=check.timeout
)
if response.status_code == check.expected_status:
return True
except requests.RequestException as e:
self.logger.warning(
f"健康检查失败 {check.name} (尝试 {attempt + 1}/{check.retries}): {e}"
)
if attempt < check.retries - 1:
time.sleep(2 ** attempt) # 指数退避
return False
def get_system_health(self) -> HealthStatus:
"""获取系统整体健康状态"""
failed_checks = 0
total_checks = len(self.health_checks)
for check in self.health_checks:
if not self.check_health(check):
failed_checks += 1
self.logger.error(f"健康检查失败: {check.name}")
if failed_checks == 0:
return HealthStatus.HEALTHY
elif failed_checks < total_checks / 2:
return HealthStatus.DEGRADED
else:
return HealthStatus.UNHEALTHY
def execute_recovery_action(self, action_name: str) -> bool:
"""执行恢复操作"""
action = self.recovery_actions.get(action_name)
if not action:
self.logger.error(f"未找到恢复操作: {action_name}")
return False
try:
self.logger.info(f"执行恢复操作: {action_name}")
if action['type'] == 'kubectl':
result = subprocess.run(
action['command'].split(),
capture_output=True,
text=True,
timeout=action.get('timeout', 60)
)
if result.returncode == 0:
self.logger.info(f"恢复操作成功: {action_name}")
return True
else:
self.logger.error(f"恢复操作失败: {result.stderr}")
return False
elif action['type'] == 'http':
response = requests.post(
action['url'],
json=action.get('payload', {}),
timeout=action.get('timeout', 30)
)
if response.status_code in [200, 201, 202]:
self.logger.info(f"恢复操作成功: {action_name}")
return True
else:
self.logger.error(f"恢复操作失败: HTTP {response.status_code}")
return False
except Exception as e:
self.logger.error(f"执行恢复操作时发生异常: {e}")
return False
def run_recovery_cycle(self):
"""运行一次恢复周期"""
health_status = self.get_system_health()
self.logger.info(f"系统健康状态: {health_status.value}")
if health_status == HealthStatus.HEALTHY:
return
# 根据健康状态执行相应的恢复操作
if health_status == HealthStatus.DEGRADED:
recovery_actions = ['restart_unhealthy_pods', 'clear_cache']
else: # UNHEALTHY
recovery_actions = ['restart_deployment', 'scale_up', 'notify_oncall']
for action in recovery_actions:
if self.execute_recovery_action(action):
# 等待恢复操作生效
time.sleep(30)
# 重新检查健康状态
if self.get_system_health() == HealthStatus.HEALTHY:
self.logger.info("系统已恢复健康状态")
return
self.logger.warning("自动恢复操作完成,但系统仍未完全恢复")
def start_monitoring(self, interval: int = 60):
"""启动持续监控"""
self.logger.info(f"启动自动恢复监控,检查间隔: {interval}秒")
while True:
try:
self.run_recovery_cycle()
time.sleep(interval)
except KeyboardInterrupt:
self.logger.info("监控已停止")
break
except Exception as e:
self.logger.error(f"监控过程中发生异常: {e}")
time.sleep(interval)
# 配置示例
config = {
"health_checks": [
{
"name": "mcp_server_health",
"url": "http://mcp-server-service/health",
"timeout": 5,
"retries": 3
},
{
"name": "mcp_server_ready",
"url": "http://mcp-server-service/ready",
"timeout": 5,
"retries": 2
}
],
"recovery_actions": {
"restart_unhealthy_pods": {
"type": "kubectl",
"command": "kubectl delete pods -l app=mcp-server,status=unhealthy -n mcp-production",
"timeout": 60
},
"restart_deployment": {
"type": "kubectl",
"command": "kubectl rollout restart deployment/mcp-server -n mcp-production",
"timeout": 120
},
"scale_up": {
"type": "kubectl",
"command": "kubectl scale deployment/mcp-server --replicas=5 -n mcp-production",
"timeout": 60
},
"clear_cache": {
"type": "http",
"url": "http://mcp-server-service/admin/cache/clear",
"timeout": 30
},
"notify_oncall": {
"type": "http",
"url": "https://alerts.company.com/webhook",
"payload": {
"severity": "critical",
"message": "MCP服务器自动恢复失败,需要人工干预"
},
"timeout": 10
}
}
}
if __name__ == "__main__":
manager = AutoRecoveryManager(config)
manager.start_monitoring()5.3 性能调优与容量规划
5.3.1 资源使用分析
```python # scripts/capacity_planning.py - 容量规划分析 import pandas as pd import numpy as np from datetime import datetime, timedelta import matplotlib.pyplot as plt from sklearn.linear_model import LinearRegression from sklearn.preprocessing import PolynomialFeatures
class CapacityPlanner: def init(self, prometheus_url: str): self.prometheus_url = prometheus_url self.metrics_data = {}
python
def fetch_metrics(self, query: str, start_time: datetime, end_time: datetime) -> pd.DataFrame:
"""从Prometheus获取指标数据"""
# 这里简化实现,实际应该调用Prometheus API
# 模拟数据生成
time_range = pd.date_range(start_time, end_time, freq='5min')
data = {
'timestamp': time_range,
'value': np.random.normal(50, 10, len(time_range)) # 模拟CPU使用率
}
return pd.DataFrame(data)
def analyze_resource_trends(self, days: int = 30) -> dict:
"""分析资源使用趋势"""
end_time = datetime.now()
start_time = end_time - timedelta(days=days)
# 获取各项指标
cpu_data = self.fetch_metrics('mcp_cpu_usage', start_time, end_time)
memory_data = self.fetch_metrics('mcp_memory_usage', start_time, end_time)
request_data = self.fetch_metrics('mcp_requests_rate', start_time, end_time)
# 趋势分析
trends = {}
for name, data in [('cpu', cpu_data), ('memory', memory_data), ('requests', request_data)]:
X = np.arange(len(data)).reshape(-1, 1)
y = data['value'].values
# 线性回归
model = LinearRegression()
model.fit(X, y)
# 预测未来30天
future_X = np.arange(len(data), len(data) + 8640).reshape(-1, 1) # 30天的5分钟间隔
future_y = model.predict(future_X)
trends[name] = {
'current_avg': np.mean(y[-288:]), # 最近24小时平均值
'trend_slope': model.coef_[0],
'predicted_30d': future_y[-1],
'growth_rate': (future_y[-1] - np.mean(y[-288:])) / np.mean(y[-288:]) * 100
}
return trends
def calculate_capacity_requirements(self, target_growth: float = 50) -> dict:
"""计算容量需求"""
trends = self.analyze_resource_trends()
recommendations = {}
# CPU容量规划
current_cpu = trends['cpu']['current_avg']
predicted_cpu = current_cpu * (1 + target_growth / 100)
if predicted_cpu > 70: # CPU使用率阈值
cpu_scale_factor = predicted_cpu / 70
recommendations['cpu'] = {
'action': 'scale_up',
'current_usage': f"{current_cpu:.1f}%",
'predicted_usage': f"{predicted_cpu:.1f}%",
'recommended_scale': f"{cpu_scale_factor:.1f}x",
'new_replicas': int(np.ceil(3 * cpu_scale_factor)) # 当前3个副本
}
else:
recommendations['cpu'] = {
'action': 'maintain',
'current_usage': f"{current_cpu:.1f}%",
'predicted_usage': f"{predicted_cpu:.1f}%"
}
# 内存容量规划
current_memory = trends['memory']['current_avg']
predicted_memory = current_memory * (1 + target_growth / 100)
if predicted_memory > 80: # 内存使用率阈值
memory_scale_factor = predicted_memory / 80
recommendations['memory'] = {
'action': 'increase_limits',
'current_usage': f"{current_memory:.1f}%",
'predicted_usage': f"{predicted_memory:.1f}%",
'recommended_memory': f"{int(2 * memory_scale_factor)}Gi" # 当前2Gi
}
else:
recommendations['memory'] = {
'action': 'maintain',
'current_usage': f"{current_memory:.1f}%",
'predicted_usage': f"{predicted_memory:.1f}%"
}
# 请求量容量规划
current_rps = trends['requests']['current_avg']
predicted_rps = current_rps * (1 + target_growth / 100)
if predicted_rps > 1000: # RPS阈值
rps_scale_factor = predicted_rps / 1000
recommendations['throughput'] = {
'action': 'scale_out',
'current_rps': f"{current_rps:.0f}",
'predicted_rps': f"{predicted_rps:.0f}",
'recommended_replicas': int(np.ceil(3 * rps_scale_factor))
}
else:
recommendations['throughput'] = {
'action': 'maintain',
'current_rps': f"{current_rps:.0f}",
'predicted_rps': f"{predicted_rps:.0f}"
}
return recommendations
def generate_capacity_report(self) -> str:
"""生成容量规划报告"""
recommendations = self.calculate_capacity_requirements()
report = f"""MCP服务器容量规划报告
生成时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}
当前资源使用情况
CPU使用率
- 当前平均使用率: {recommendations'cpu''current_usage'}
- 预测使用率: {recommendations'cpu''predicted_usage'}
- 建议操作: {recommendations'cpu''action'}
内存使用率
- 当前平均使用率: {recommendations'memory''current_usage'}
- 预测使用率: {recommendations'memory''predicted_usage'}
- 建议操作: {recommendations'memory''action'}
请求吞吐量
- 当前平均RPS: {recommendations'throughput''current_rps'}
- 预测RPS: {recommendations'throughput''predicted_rps'}
- 建议操作: {recommendations'throughput''action'}
扩容建议
"""
less
if recommendations['cpu']['action'] == 'scale_up':
report += f"- **CPU扩容**: 建议将副本数扩展到 {recommendations['cpu']['new_replicas']} 个\n"
if recommendations['memory']['action'] == 'increase_limits':
report += f"- **内存扩容**: 建议将内存限制提升到 {recommendations['memory']['recommended_memory']}\n"
if recommendations['throughput']['action'] == 'scale_out':
report += f"- **吞吐量扩容**: 建议将副本数扩展到 {recommendations['throughput']['recommended_replicas']} 个\n"
report += """实施建议
- 监控告警: 设置资源使用率告警阈值
- 自动扩缩容: 配置HPA (Horizontal Pod Autoscaler)
- 定期评估: 每月进行一次容量规划评估
- 成本优化: 在非高峰期适当缩容以节省成本
风险评估
-
高风险: CPU/内存使用率超过80%
-
中风险: 请求响应时间超过500ms
-
低风险: 资源使用率在正常范围内 """
kotlinreturn report
使用示例
if name == "main ": planner = CapacityPlanner("http://prometheus:9090") report = planner.generate_capacity_report() print(report)
python
# 保存报告
with open(f"capacity_report_{datetime.now().strftime('%Y%m%d')}.md", "w") as f:
f.write(report)
yaml
<h2 id="bOYfl">6. 安全加固与合规性</h2>
<h3 id="wSUNP">6.1 安全扫描与漏洞管理</h3>
```yaml
# .github/workflows/security-scan.yml
name: Security Scan
on:
push:
branches: [ main, develop ]
pull_request:
branches: [ main ]
schedule:
- cron: '0 2 * * 1' # 每周一凌晨2点
jobs:
dependency-scan:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Run Snyk to check for vulnerabilities
uses: snyk/actions/node@master
env:
SNYK_TOKEN: ${{ secrets.SNYK_TOKEN }}
with:
args: --severity-threshold=high
- name: Upload result to GitHub Code Scanning
uses: github/codeql-action/upload-sarif@v2
with:
sarif_file: snyk.sarif
container-scan:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Build Docker image
run: docker build -t mcp-server:scan .
- name: Run Trivy vulnerability scanner
uses: aquasecurity/trivy-action@master
with:
image-ref: 'mcp-server:scan'
format: 'sarif'
output: 'trivy-results.sarif'
- name: Upload Trivy scan results
uses: github/codeql-action/upload-sarif@v2
with:
sarif_file: 'trivy-results.sarif'
code-scan:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Initialize CodeQL
uses: github/codeql-action/init@v2
with:
languages: javascript
- name: Autobuild
uses: github/codeql-action/autobuild@v2
- name: Perform CodeQL Analysis
uses: github/codeql-action/analyze@v26.2 网络安全策略
```yaml # k8s/network-policy.yaml apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: mcp-server-network-policy namespace: mcp-production spec: podSelector: matchLabels: app: mcp-server policyTypes: - Ingress - Egress
ingress:
允许来自API网关的流量
- from:
- namespaceSelector: matchLabels: name: api-gateway ports:
- protocol: TCP port: 8080
允许来自监控系统的流量
- from:
- namespaceSelector: matchLabels: name: monitoring ports:
- protocol: TCP port: 8080
egress:
允许访问数据库
- to:
- namespaceSelector: matchLabels: name: database ports:
- protocol: TCP port: 5432
允许访问Redis
- to:
- namespaceSelector: matchLabels: name: cache ports:
- protocol: TCP port: 6379
允许DNS查询
- to: \[\] ports:
- protocol: UDP port: 53
允许HTTPS出站流量
- to: \[\] ports:
- protocol: TCP port: 443
Pod安全策略
apiVersion: policy/v1beta1 kind: PodSecurityPolicy metadata: name: mcp-server-psp spec: privileged: false allowPrivilegeEscalation: false requiredDropCapabilities: - ALL volumes: - 'configMap' - 'emptyDir' - 'projected' - 'secret' - 'downwardAPI' - 'persistentVolumeClaim' runAsUser: rule: 'MustRunAsNonRoot' seLinux: rule: 'RunAsAny' fsGroup: rule: 'RunAsAny'
yaml
<h2 id="BhEdI">7. 成本优化与资源管理</h2>
<h3 id="E3DWA">7.1 资源配额管理</h3>
```yaml
# k8s/resource-quota.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: mcp-production-quota
namespace: mcp-production
spec:
hard:
requests.cpu: "10"
requests.memory: 20Gi
limits.cpu: "20"
limits.memory: 40Gi
persistentvolumeclaims: "10"
pods: "20"
services: "10"
secrets: "20"
configmaps: "20"
---
apiVersion: v1
kind: LimitRange
metadata:
name: mcp-production-limits
namespace: mcp-production
spec:
limits:
- default:
cpu: "1000m"
memory: "2Gi"
defaultRequest:
cpu: "500m"
memory: "1Gi"
type: Container
- max:
cpu: "2000m"
memory: "4Gi"
min:
cpu: "100m"
memory: "128Mi"
type: Container7.2 自动扩缩容配置
```yaml # k8s/hpa.yaml apiVersion: autoscaling/v2 kind: HorizontalPodAutoscaler metadata: name: mcp-server-hpa namespace: mcp-production spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: mcp-server minReplicas: 2 maxReplicas: 10 metrics: - type: Resource resource: name: cpu target: type: Utilization averageUtilization: 70 - type: Resource resource: name: memory target: type: Utilization averageUtilization: 80 - type: Pods pods: metric: name: mcp_requests_per_second target: type: AverageValue averageValue: "100" behavior: scaleDown: stabilizationWindowSeconds: 300 policies: - type: Percent value: 50 periodSeconds: 60 scaleUp: stabilizationWindowSeconds: 60 policies: - type: Percent value: 100 periodSeconds: 60 - type: Pods value: 2 periodSeconds: 60
垂直扩缩容配置
apiVersion: autoscaling.k8s.io/v1 kind: VerticalPodAutoscaler metadata: name: mcp-server-vpa namespace: mcp-production spec: targetRef: apiVersion: apps/v1 kind: Deployment name: mcp-server updatePolicy: updateMode: "Auto" resourcePolicy: containerPolicies: - containerName: mcp-server maxAllowed: cpu: "2" memory: "4Gi" minAllowed: cpu: "100m" memory: "128Mi"
markdown
<h2 id="yb7Hl">总结</h2>
作为博主摘星,通过深入研究和实践企业级MCP部署的完整DevOps流程,我深刻认识到这不仅是一个技术实施过程,更是一个系统性的工程管理实践。在当今数字化转型的浪潮中,MCP作为AI应用的核心基础设施,其部署质量直接决定了企业AI能力的上限和业务创新的速度。从我多年的项目经验来看,成功的企业级MCP部署需要在架构设计、容器化实施、CI/CD流水线、监控运维等多个维度上精心规划和执行。本文详细介绍的从开发到生产的完整流程,不仅涵盖了技术实现的各个环节,更重要的是体现了现代DevOps理念在AI基础设施建设中的最佳实践。通过标准化的容器化部署、自动化的CI/CD流水线、全方位的监控体系和智能化的运维管理,我们能够构建出既稳定可靠又高效灵活的MCP服务平台。特别值得强调的是,安全性和合规性在企业级部署中的重要性不容忽视,从网络隔离到数据加密,从访问控制到审计日志,每一个环节都需要严格把控。同时,成本优化和资源管理也是企业级部署中必须考虑的现实问题,通过合理的资源配额、智能的自动扩缩容和有效的容量规划,我们可以在保证服务质量的前提下最大化资源利用效率。展望未来,随着AI技术的不断演进和企业数字化程度的持续提升,MCP部署的复杂性和重要性还将进一步增加,这也为我们技术人员提供了更多的挑战和机遇。我相信,通过持续的技术创新、流程优化和经验积累,我们能够构建出更加智能、安全、高效的企业级AI基础设施,为企业的数字化转型和智能化升级提供强有力的技术支撑,最终推动整个行业向更高水平发展。
<h2 id="dhhQ1">参考资料</h2>
1. [Kubernetes官方文档](https://kubernetes.io/docs/)
2. [Docker最佳实践指南](https://docs.docker.com/develop/dev-best-practices/)
3. [GitLab CI/CD文档](https://docs.gitlab.com/ee/ci/)
4. [Prometheus监控指南](https://prometheus.io/docs/introduction/overview/)
5. [Grafana可视化文档](https://grafana.com/docs/)
6. [企业级DevOps实践](https://www.devops.com/enterprise-devops-best-practices/)
7. [云原生安全最佳实践](https://www.cncf.io/blog/2021/11/12/cloud-native-security-best-practices/)
8. [Kubernetes安全加固指南](https://kubernetes.io/docs/concepts/security/)
---
_本文由博主摘星原创,专注于AI基础设施与DevOps实践的深度分析。如有技术问题或合作需求,欢迎通过评论区或私信联系。_
🌈_ 我是摘星!如果这篇文章在你的技术成长路上留下了印记:_
👁️_ 【关注】与我一起探索技术的无限可能,见证每一次突破_
👍_ 【点赞】为优质技术内容点亮明灯,传递知识的力量_
🔖_ 【收藏】将精华内容珍藏,随时回顾技术要点_
💬_ 【评论】分享你的独特见解,让思维碰撞出智慧火花_
🗳️_ 【投票】用你的选择为技术社区贡献一份力量_
_技术路漫漫,让我们携手前行,在代码的世界里摘取属于程序员的那片星辰大海!_