引言
在生成式人工智能(AIGC)飞速演进的时代,内容生成已不再局限于静态文本或图像。无论是文本驱动的图像生成(text-to-image)、图像生成视频(image-to-video),还是实时驱动的虚拟人、数字分身,AIGC正将内容创作从"离线处理"推进到"实时交互"的新阶段。
然而,支撑这些智能生成能力顺利落地的前提,是一条高效、低延迟、跨平台的视频通感链路。从模型输入的连续视频帧,到生成结果在终端的实时呈现,视频早已不只是结果的承载,更是生成过程的触发器与反馈通道。
在这一架构中,大牛直播SDK凭借其成熟稳定的视频采集、编解码、传输与播放能力,成为构建"AIGC感知---生成---呈现"闭环的关键基础模块。本文将围绕AIGC系统对视频链路的严苛需求,深入解析大牛直播SDK如何提供可靠的实时支撑能力,并推动生成式AI从实验走向工程化落地。
一、AIGC系统中的"视频链路挑战"
随着AIGC在工业制造、智慧城市、虚拟直播、远程医疗等领域的迅速渗透,其对"视频输入"和"生成输出"的实时性、连续性与结构化程度提出了远高于传统媒体的技术要求。相比传统静态图片或离线视频处理,AIGC系统正面临以下关键视频链路挑战:
类型
挑战点描述
工程影响
⏱ 实时性挑战
AIGC需要基于实时视频流完成驱动或决策,延迟需压缩至 <300ms
延迟过高将导致交互失真、误触发或错过关键帧
🎥 视频质量挑战
模型识别依赖清晰、高帧率、低压缩损耗的视频输入
传统压缩可能导致边缘模糊、目标信息丢失,影响识别精度
🔄 通道对齐挑战
多模态协同(如视频、音频、传感器)需精确时间戳对齐
时序误差会导致生成结果与画面错位,如口型不同步、定位偏差
🌐 协议兼容挑战
多设备异构系统需兼容RTMP、RTSP、GB28181等协议
无法统一封装与拉流,增加系统集成复杂度
⚙️ 接入能力挑战
多路高并发视频通道,需灵活适配边缘设备、云平台与多终端展示
性能瓶颈或资源浪费,难以规模部署
🔐 数据可控挑战
生成过程需要完整记录、审核与追踪,支持本地录像与数据注入(如元数据)
缺乏记录/监管能力会影响落地合规与数据价值闭环
这一系列挑战表明,AIGC系统中的视频链路不仅是"视觉输入",更是算法驱动与业务控制的"实时触发器"。
要实现真正意义上的AIGC系统闭环,仅靠传统视频采集或播放器无法满足工程化落地需求,必须引入具备低延迟、强兼容、可回调、易扩展特性的视频通路能力------这正是大牛直播SDK所专注解决的核心价值所在。
二、大牛直播SDK × AIGC:打造实时视频生成链路
面对 AIGC 对视频链路在延迟控制、帧数据精度、协议适配、多端渲染等方面的高要求,大牛直播SDK凭借其在视频采集、推流、播放与转码等环节的全链路技术栈,正在成为 AIGC 系统中感知与生成之间的"通信枢纽"。

其核心价值体现在三个方面:低延迟传输、裸数据直达、跨平台封装能力。
📐 架构概览:感知 → 生成 → 呈现的闭环引擎
以下是基于大牛直播SDK与AIGC系统融合的参考架构:
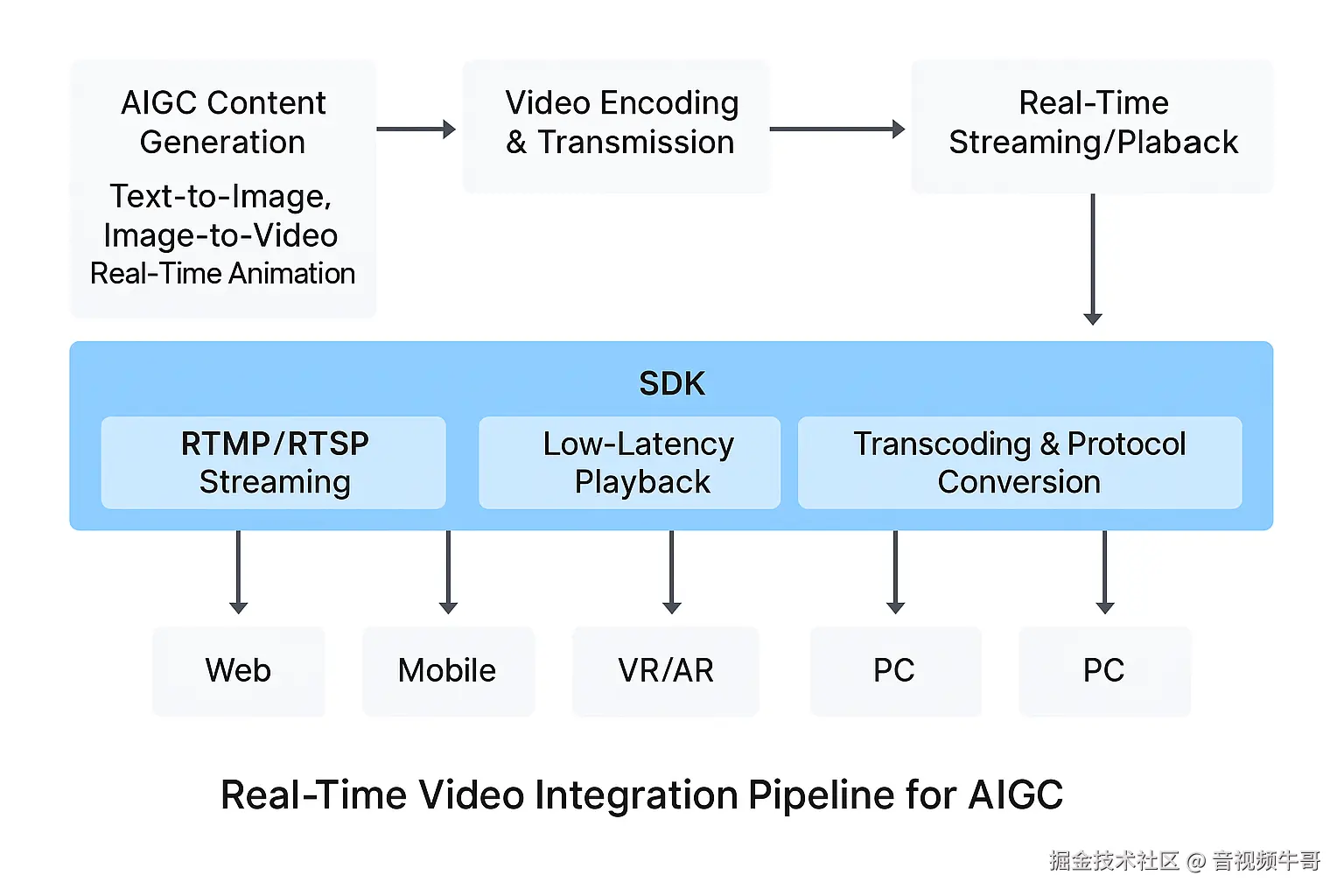
构成层级
技术组成
功能描述
🟣 视频采集层
摄像头/屏幕采集、第三方输入、无人机回传
提供实时原始图像输入源
🔵 编码与传输层
RTMP/RTSP/HLS 推流,YUV/RGB 回调,SEI注入
将AI生成或感知帧结构化、低延迟传送
🟢 数据协同层
帧级元数据嵌入(SEI)、时间戳同步
实现图像与传感数据、位置信息的协同对齐
🟡 播放与输出层
Android/iOS/PC/VR播放器,本地录像
实时呈现生成结果,支持回放、监管与边缘部署
🎯 SDK 模块能力矩阵(面向 AIGC)
模块
AIGC 场景作用
RTMP/RTSP 推流
封装生成视频内容,实时推送至多端或云平台
解码帧回调接口
YUV、RGB 帧数据直通 AI 模型,提升识别效率与精度
多协议兼容
同时支持 RTSP/RTMP/GB28181 等,适配终端生态
SEI 元数据注入
将传感器/GPS/语义标签同步封装进视频帧,供模型调用
录像与截图能力
实现生成过程记录与调试复现,支撑安全/合规/留存需求
多路并发播放/推流
支持单端多路并发任务,适配云边混合部署
✅ 工程价值总结

-
⏱ 端到端延迟压缩至 100-250ms,适配工业控制、实时交互类AIGC任务
-
📦 跨平台部署支持(Android/iOS/Windows/Linux/Unity),支持不同运行环境落地
-
🎯 高度模块化集成,支持与AI模型、感知系统解耦部署,可嵌入任意AI工作流中
大牛直播SDK不仅是视频播放工具,更是一条可控、可调用、可记录的智能视频通路,是将AIGC推向"在线实时"应用的关键基础设施。
四、典型应用场景矩阵
随着AIGC技术不断深入垂直行业,低延迟、高质量的视频输入与生成输出成为核心驱动。以下是结合大牛直播SDK能力的典型落地场景矩阵:
应用场景
视频链路方案
AIGC生成内容
业务价值与技术收益
🏭 工业视觉质检
YUV/RGB 数据回调 + RTMP上行至边缘/云端
缺陷识别报告、工艺建议生成
实现产线自动剔除、良品率提升,延迟控制在200ms内
🚁 无人机巡查
RTSP/GB28181 视频传输 + 多通道光谱元数据同步
灾情总结报告、可视化路径、指挥指令生成
实时回传至指挥中心大屏,形成空地一体协同响应系统
🏬 智慧零售门店
多路摄像头视频推流 + 客流热区元数据注入
推荐话术、动态广告文案、布局优化建议
支持千人千面的AI交互促销,显著提升客单价与坪效
🌾 数字农业平台
红外+可见光+环境传感数据 → 视频SEI注入 → 本地分析
病虫识别报告、农药喷洒路径、种植建议生成
建立精准农业视频感知闭环,提升农作物产量与防治时效
🏥 医疗远程会诊
手术过程低延迟推流 + 医疗数据实时嵌入
病历摘要、术语转写、辅助诊断建议
实现异地专家实时指导手术或会诊,提高边缘医院专业服务能力
🎓 教育直播互动
课件+教师视频推送至边缘 → AIGC辅助实时翻译/摘要生成
多语种字幕、章节归纳、实时提问应答
降低跨语种/跨文化教学壁垒,提升直播课交互深度
🎮 虚拟空间协作
Unity3D画面RTMP推流 + 手势/语音指令SEI注入
虚拟形象驱动、实时语义生成、场景补全
实现跨地协同建模、指挥调度等复杂任务,支持元宇宙级别交互精度
总结与展望:让"视频通路"成为AIGC系统的标准神经元
在生成式AI日益演进的今天,从文本生成到多模态融合,从内容创造到实时决策,AIGC不再只停留在模型层的智能,而是正快速迈向"系统层级的智能协作" 。在这个过程中,视频,作为现实世界中信息密度最高的感知通道,已经不只是模型的输入素材,更是构建AIGC闭环的神经主轴。
本文系统梳理了 AIGC 在落地过程中对视频链路的关键挑战,包括低延迟、原始帧支持、多协议兼容、多端适配与数据可控性等需求。而作为一套成熟稳定的视频通信与封装能力框架,大牛直播SDK 正在成为这一基础设施中的"底层通感模块"------不仅实现视频采集与编码的优化,还打通了生成结果的多终端分发与监管。
从工业制造到智慧农业,从虚拟直播到远程诊疗,从边缘AI感知到云端大模型生成,大牛直播SDK 已经在多个典型场景中验证了其高稳定性与高适配能力,为 AIGC 应用提供了可扩展的"视频生成引擎"。
未来,随着 LVM(Large Vision Model)、多模态对齐技术与视频生成模型的不断演进,视频不仅将成为 AIGC 的标准输入接口,更将反向驱动模型生成内容以视频方式直接参与实时交互与控制,构建出真正意义上的"感知---生成---执行"智能系统闭环。
✅ 视频不只是AIGC的输入源,更是它感知世界、理解环境的"眼与耳";大牛直播SDK,则提供了连接模型与现实的稳定桥梁。
✅ 每一帧视频,都有可能触发一次智能生成,每一次交互,都是AI理解世界的再现。
我们正站在从"视频记录"走向"视频驱动智能决策"的拐点,一种全新的系统范式正悄然重构。