文章目录
- 概述
- [一、从 Prompt 到 Skill:为什么需要新一层抽象](#一、从 Prompt 到 Skill:为什么需要新一层抽象)
-
- [1. 临时 Prompt 的天花板](#1. 临时 Prompt 的天花板)
- [2. Skills 想解决什么问题](#2. Skills 想解决什么问题)
- [二、Skills 的运行机制:模型是怎么"用技能"的](#二、Skills 的运行机制:模型是怎么“用技能”的)
-
- [1. 三层结构:从 Metadata 到 Resources](#1. 三层结构:从 Metadata 到 Resources)
- [2. 自动激活:路由器如何决定"用不用这个 Skill"](#2. 自动激活:路由器如何决定“用不用这个 Skill”)
- [三、和 MCP、命令、Agent 的关系:各司其职](#三、和 MCP、命令、Agent 的关系:各司其职)
- [四、从 0 到 1:设计你的第一个 Skill](#四、从 0 到 1:设计你的第一个 Skill)
- [五、把 Skills 嵌进真实工作流:几个典型场景](#五、把 Skills 嵌进真实工作流:几个典型场景)
-
- [1. PR Review 自动化流水线](#1. PR Review 自动化流水线)
- [2. 日志分析与故障诊断](#2. 日志分析与故障诊断)
- [3. 文档与报告生成](#3. 文档与报告生成)
- 六、最佳实践与踩坑指南
-
- [1. 从"小而专"开始,避免"万能 Skill"](#1. 从“小而专”开始,避免“万能 Skill”)
- [2. 强调可测试性:把 Skill 当代码管](#2. 强调可测试性:把 Skill 当代码管)
- [3. 权限与共享:团队维度的治理](#3. 权限与共享:团队维度的治理)
- [七、从今天开始:一步步搭起你的 Skill 体系](#七、从今天开始:一步步搭起你的 Skill 体系)
概述
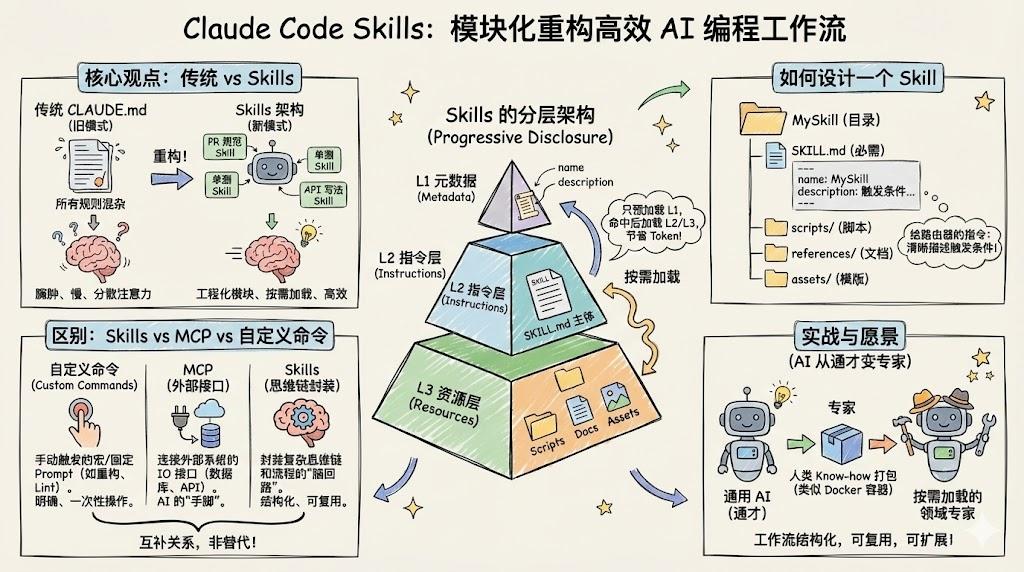
在大模型已经能熟练写代码的 2026 年,真正拉开团队差距的,不再是"模型聪不聪明",而是"你如何把 AI 工程化地嵌入开发流程"。Claude Code 推出的 Skills 机制,正是在这一背景下出现:它让 AI 不再只是一个临时对话助手,而变成一组可组合、可复用、可治理的"技能包",可以像架构组件一样被设计和演进。
接下来我将面向一线开发者、技术负责人和对 AI 工程化感兴趣的技术爱好者,系统拆解 Claude Code Skills 的原理、设计方法与落地路径,帮助你把"好用一次的 AI"升级成"稳定托管的 AI 工作流"。
一、从 Prompt 到 Skill:为什么需要新一层抽象
1. 临时 Prompt 的天花板
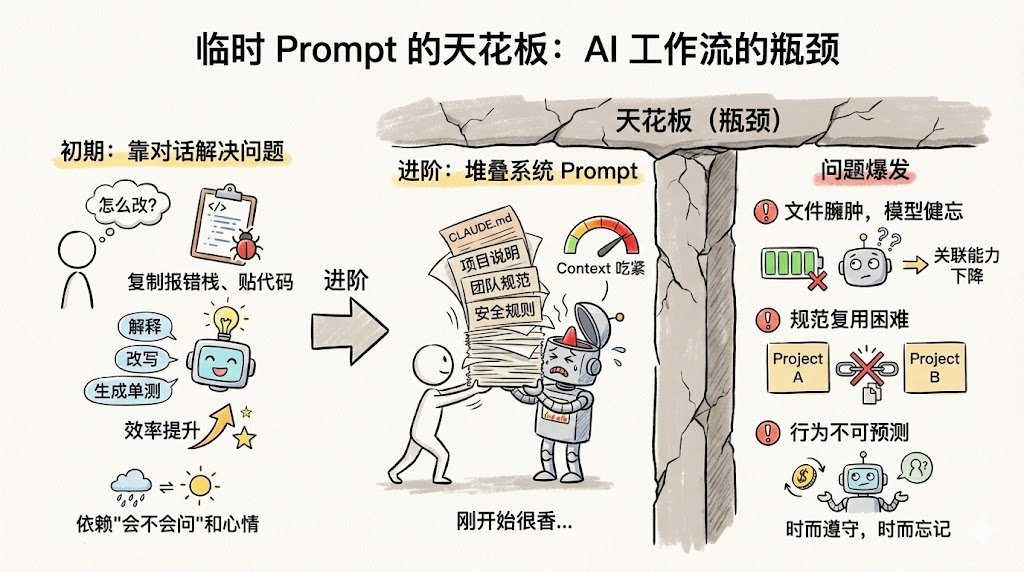
大多数团队把 AI 拉进工作流时,会经历这样的过程:
-
初期:靠对话解决问题
复制报错栈、贴一段代码,让模型帮忙解释、改写、生成单测,效率肉眼可见地提升,但高度依赖"会不会问"和"当天心情好不好"。
-
进阶:堆叠系统 Prompt
项目越来越多后,会开始搞各种"项目说明""团队规范""安全规则",把这些东西塞进开头的系统提示或 CLAUDE.md 之类的文件。刚开始很香,过一阵子问题就来了:
- 文件越写越长,上下文吃紧,模型关联能力反而下降
- 规范跨项目复用困难,只能复制粘贴
- 行为不可预测:你以为模型"记住了",但它时而遵守、时而忘记
简而言之:Prompt 很适合"一次性任务说明",但并不适合作为"长期演进的工作流载体"。
2. Skills 想解决什么问题
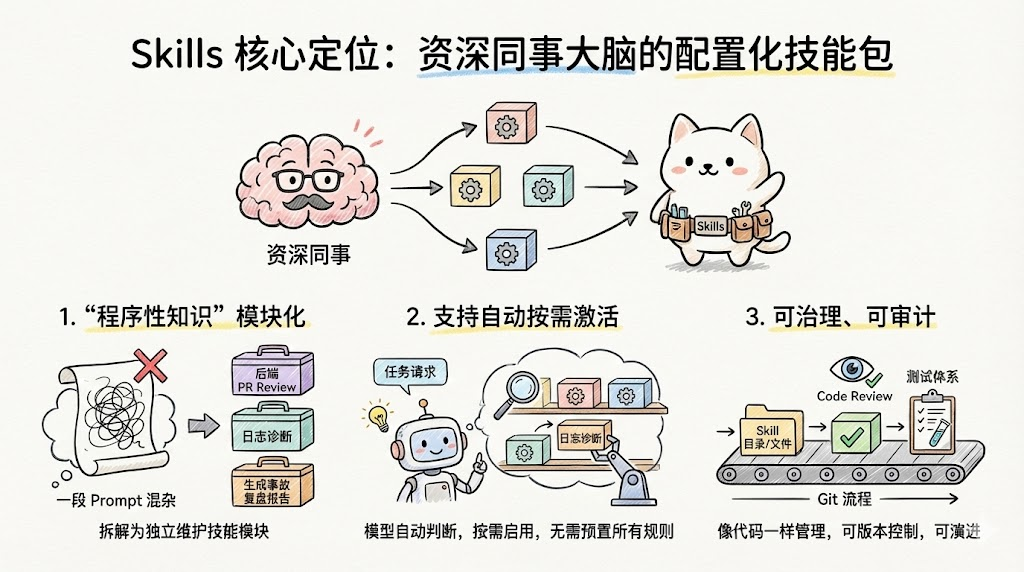
Skills 的核心定位,可以归纳成三点:
-
把"程序性知识"模块化
不再用一段 Prompt 混杂讲规范、讲流程、讲风格,而是拆成一个个可独立维护的技能模块,比如"后端 PR Review""日志诊断""生成事故复盘报告"。
-
支持自动按需激活
模型在对话中,会根据 Skill 的描述自动判断:当前任务是否适合启用某个 Skill,而不是把所有规则预先塞进上下文里。
-
让 AI 行为可治理、可审计
每个 Skill 是一个目录、一组文件,可以放进 Git,用 Code Review 和测试体系管理,和普通代码模块一样可演进。
用一句形象的话:Skills 是"把你团队里那位资深同事的大脑,拆成若干可版本控制的配置化技能包",挂在 Claude 身上。
二、Skills 的运行机制:模型是怎么"用技能"的
1. 三层结构:从 Metadata 到 Resources
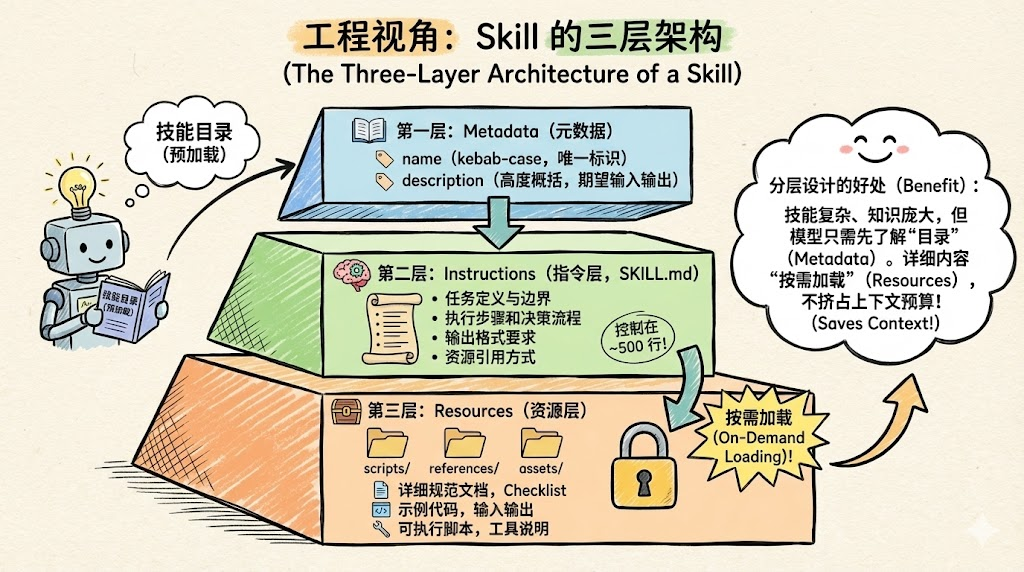
从工程角度,可以把一个 Skill 想象成三层:
-
第一层:Metadata(元数据)
通常只有两项:name 和 description。
- name:唯一标识,同目录名,一般用 kebab-case
- description:高度概括这个 Skill 做什么、什么时候用、期望的输入输出
启动时,Claude 会预加载所有 Skill 的 Metadata,相当于先看到一本"技能目录"。
-
第二层:Instructions(指令层,SKILL.md)
这是 Skill 的"脑回路脚本",通常用一个 SKILL.md 表示,内容包括:
- 任务定义与边界
- 执行步骤和决策流程
- 输出格式要求
- 对资源文件和脚本的引用方式
常见经验是控制在 500 行左右,避免把 SKILL.md 写成另一个"超级 Prompt"。
-
第三层:Resources(资源层)
放在 scripts/、references/、assets/ 等目录下:
- 详细规范文档、最佳实践、Checklist
- 示例代码、示例输入输出
- 可执行脚本与工具调用说明
这些文件是按需加载的:只有当 SKILL.md 中提到并且执行需要时,Claude 才会实际去读取它们。
这种分层设计的好处是:技能可以很复杂、知识可以很庞大,但模型一开始只需了解"世界上有这么一个技能",真正详细内容按需加载,不会挤占上下文预算。
2. 自动激活:路由器如何决定"用不用这个 Skill"
在一次对话条目中,大致会经历这样的过程:
- 用户发出请求(例如"帮我 Review 这段后端服务的 PR")。
- Claude 内部的"技能路由器"读取各个 Skill 的 description,对照当前输入,评估哪些技能可能相关。
- 一旦判断某个 Skill 合适,就读取该 Skill 的 SKILL.md,把里面的指令作为本次任务的行为决策依据。
- 如果 SKILL.md 中引用了资源文件(例如团队安全规范、性能优化 checklist),则在需要时再继续读取这些文件。
- 根据完整的"指令 + 资源 + 用户输入"生成输出。
这里有两个关键点:
-
description 写得越具体,路由就越精准
模糊的描述会导致 Skill 被误触发或不触发,因此 description 必须明确"何时用""何时不用"。
-
Skill 是自动的,但也可以被引导
用户可以通过自然语言,引导 Claude 思考"要不要用某个技能",但不需要记住具体命令;这比传统的
/command风格更自然。
三、和 MCP、命令、Agent 的关系:各司其职
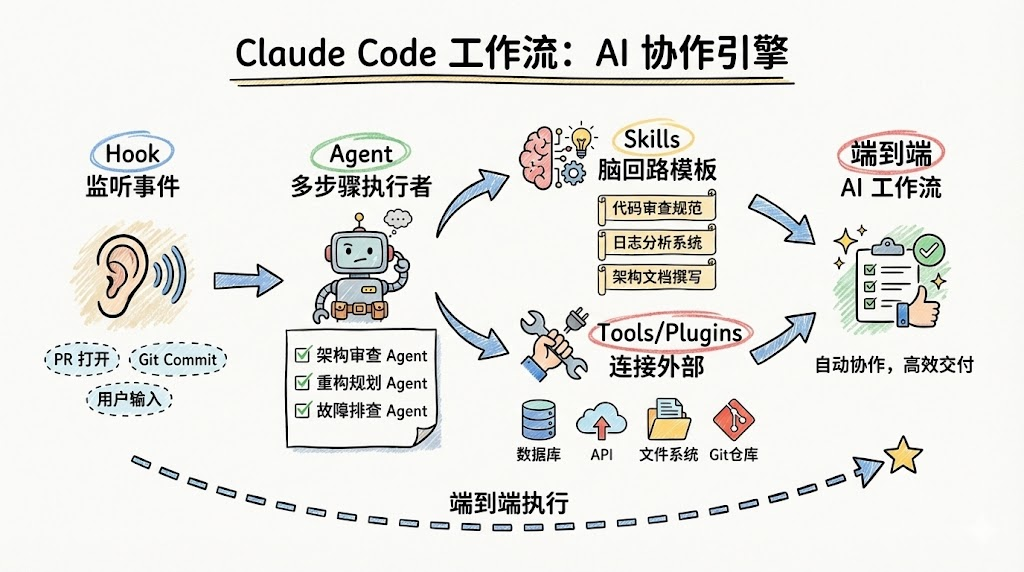
在 Claude Code 的大框架里,常见的几个元素是:Hooks、Skills、Agents、Tools/插件。可以这样理解它们的分工:
-
Tools / Plugins / MCP
负责"连接外部世界",是模型的"手脚":
- 访问数据库、Git 仓库、HTTP API
- 操作文件系统、运行脚本、触发 CI
-
Skills
负责"如何做事",是模型的"脑回路模板":
- 怎样进行一次完整、符合规范的代码审查
- 怎样系统地分析一段日志并输出可能根因
- 怎样按照团队模板撰写架构设计文档
-
Hooks
相当于事件触发器:
- 监听"用户按下回车""git commit 之前""PR 打开以后"等事件
- 决定在什么时刻自动唤起某个 Agent 或 Skill
-
Agents
是带角色设定的"多步骤执行者":
- 架构审查 Agent
- 重构规划 Agent
- 故障排查 Agent
它们可以内部组合多个 Skills 和 Tools,完成更长链路任务。
组合起来,就是:
Hook 监听事件 → 选择合适的 Agent → Agent 根据需要调用若干 Skills 和 Tools → 形成一个端到端的"AI 工作流"。
四、从 0 到 1:设计你的第一个 Skill
下面用一个典型需求"团队规范化的 PR Review"来完整走一遍 Skill 设计流程。
1. 需求澄清:别急着写 SKILL.md
先回答几个问题:
-
这个 Skill 面向谁?
例如:后端工程师、数据工程师、全栈开发者。
-
要解决的核心问题是什么?
例如:
- 保障功能正确性
- 对齐团队代码风格
- 关注安全、性能和可观测性风险
-
输入长什么样?
例如:
- Git diff
- 文件列表 + 关键变更描述
- 问题上下文(这个改动解决了什么问题)
-
输出需要是什么形式?
例如:
- 按"必须修改 / 建议修改 / 可以忽略"分类的审查意见
- 指向具体行号或代码片段
- 最后附整体评估和建议结论
这些约束会直接写进 Skill 的 metadata 和 SKILL.md 中,决定它的触发条件和工作方式。
2. 目录结构:像搭组件一样搭 Skill
在项目根目录下新建 .claude/skills/backend-pr-review/:
text
.claude/
└── skills/
└── backend-pr-review/
├── SKILL.md
├── resources/
│ ├── team-style-guide.md
│ ├── security-checklist.md
│ └── performance-guidelines.md
└── examples/
├── good-review.md
└── bad-review.md拆分思路:
-
写清任务定义、执行步骤、输出格式和行为准则,不塞入大段知识,只引用资源文件。
-
resources
存放团队常用规范、Checklist 和最佳实践文档,按主题拆分,保证每个文件足够聚焦。
-
examples
存放好评/差评示例:
- 好评:结构清晰、指向具体问题、给出替代方案
- 差评:泛泛而谈、只说"看起来还行""注意安全"之类
Skill 在执行时,可以被明确要求模仿 good-review.md 的结构和语气。
3. 元数据:写给"路由器"的简历
在 SKILL.md 顶部,用 YAML frontmatter 描述 Skill:
markdown
---
name: backend-pr-review
description: >
Review backend service pull requests for correctness, code quality,
security, and performance. Trigger when the user provides code diffs
or file changes and explicitly asks for review or feedback before merging.
---几个要点:
- name 必须和目录名一致
- description 要写清:
- 适用场景:后端服务 PR
- 触发信号:用户提供 diff 并说明要 Review
- 输出目标:给出合并前的反馈意见
写成"会写高质量代码审查"的泛泛描述远远不够,需要把触发条件和输入约束明确表达出来,帮助路由器决策。
4. 写 SKILL.md:从"提示词"升级为"流程脚本"
可以按如下结构组织 SKILL.md:
-
任务定义与边界
- 只审查本次提交的变更
- 不对未修改部分做过度推断
- 对不确定内容可以提出问题,而不是瞎猜
-
输入检查
- 如果没有看到 diff,先要求用户提供
- 如果缺少"改动目的说明",提示补充背景
-
审查流程步骤
- 理解变更意图
- 从功能正确性角度检查:逻辑分支、边界条件、错误处理
- 从风格与可读性角度检查:命名、函数长度、重复逻辑
- 从安全与性能角度检查:输入校验、SQL 注入、内存与耗时
- 可观测性:日志、指标、告警是否需要更新
-
输出格式
- 以"必须修改 / 建议修改 / 可接受"分组
- 每一条说明问题位置、原因和建议方案
- 最后给出整体结论:建议合并 / 合并前必须修复
-
引用资源与示例
- 指示模型在需要时读取 team-style-guide.md 等文件
- 要求模仿 good-review.md 的结构和语气
这样,SKILL.md 就从一段模糊的 Prompt,变成了一份"可读可测的行为规范"。
五、把 Skills 嵌进真实工作流:几个典型场景
1. PR Review 自动化流水线
目标:让每一个 PR 都能自动获得一份结构化、质量稳定的 Review 初稿。
落地步骤:
-
为不同项目/领域定义多个 Review Skills
- backend-pr-review:后端核心服务
- api-contract-review:接口契约与兼容性检查
- security-review:高敏感模块的安全审查
-
用 Hook 监听事件
- "Pull Request 打开"
- "标记 ready for review"
- 在满足条件时自动触发对应 Skill
-
输出回写
- 把 Skill 的结果直接贴到 PR 评论中
- 或者生成一个 Markdown 报告,给人类 Reviewer 快速过一遍
实际效果是:AI 负责"兢兢业业地看细节",人类 Reviewer 把精力集中在架构决策、业务影响和长期演进上。
2. 日志分析与故障诊断
复杂系统在生产环境下会产生大量日志和指标,一线工程师常常需要临时"当人肉日志分析器"。
可以为此设计 log-diagnosis Skill:
-
元数据描述
- 当用户提供一段日志或事故时间线,并询问"原因""可能问题"时触发。
-
SKILL.md 定义的流程
- 解析时间线,寻找错误高发区
- 将错误模式与已知故障案例对照
- 列出可能根因,并给出验证步骤
- 提供临时缓解方案和长期修复建议
-
资源层
- 团队常见故障手册
- 历史事故复盘精选摘要
- 关键服务的架构与依赖关系图文说明
使用次数越多,Skill 可以不断吸收新的故障模式和复盘经验,逐渐演化为一套"团队级故障诊断大脑"。
3. 文档与报告生成
很多团队已经有成熟的文档模板,例如:
-
架构设计文档
包含背景、目标、备选方案、决策理由、风险与回滚策略。
-
事故复盘报告
包含过程时间线、影响范围、根因分析、短期与长期行动项。
对应地可以设计:
-
adr-writer Skill
- 输入:设计讨论要点、方案对比结论
- 输出:符合团队 ADR 模板的文档草稿,待架构师修订
-
incident-postmortem Skill
- 输入:告警时间线、处理过程、相关 PR
- 输出:结构完整的复盘初稿,包含行动项和负责人
在这些场景中,Skill 的作用,不是"取代写文档的人",而是把"套模板 + 补全细节"这种机械工作交给 AI,让人类专注在"做判断""写关键理由"。
六、最佳实践与踩坑指南
1. 从"小而专"开始,避免"万能 Skill"
常见错误是:一上来就想做一个"万能开发助手 Skill",什么都往里塞:
- 所有语言的代码风格
- 所有项目的安全规范
- 所有 CI 过程的检查点
结果自然是:
- 描述模糊到无法精确触发
- SKILL.md 冗长得没人敢改
- 模型行为时好时坏,难以排查原因
更稳妥的做法:
-
先围绕一个场景做"小而专"的 Skill
比如:只管后端 PR Review,只管日志诊断,只管写周报。
-
使用一段时间后再拆分或组合
当你发现一个 Skill 里"子任务太多"时,再拆出子 Skill,或者用 Agent 串联多个 Skill。
2. 强调可测试性:把 Skill 当代码管
Skill 一旦进入生产流程,就应该像普通代码模块一样对待:
-
建 Golden Cases
为关键 Skill 设计一组"标准输入 → 期望输出"的测试用例,每次修改后跑一遍,避免行为突然漂移。
-
收集使用反馈
在 UI 或命令行中提供"有帮助 / 一般 / 误导"反馈选项,定期回顾并迭代 SKILL.md 和资源文件。
-
谨慎处理高风险动作
对涉及自动修改代码、执行脚本的 Skill,增加明确的确认步骤和"只生成 patch、不自动应用"的保护机制。
3. 权限与共享:团队维度的治理
推广到团队甚至公司层面时,需要考虑:
-
公共 Skill vs 项目 Skill
- 公共 Skill:公司统一规范、安全要求
- 项目 Skill:某个特定业务线的专有规则
尽量分开管理,避免相互污染。
-
权限与审计
- 涉及内部系统访问的 Skill,要结合工具权限和日志审计机制
- 引入外部来源的 Skill 时,务必先审核内容和脚本,防范恶意指令
-
版本管理与发布节奏
- 使用 Git 管理 Skill 仓库
- 对关键 Skill 引入"开发 / 预发 / 生产"三套配置,分阶段验证
七、从今天开始:一步步搭起你的 Skill 体系
可以按下面这份"行动清单",在现有工作中真正落地 Skills:
-
列出你每天最常重复、最讨厌但又离不开的三类任务
例如:PR Review、查日志、写周报、整理会议纪要。
-
为其中一个任务画出简单流程图
标出输入、关键步骤、决策点和输出,尽量不用技术术语,而是写"先干什么,再干什么"。
-
在 Claude Code 中创建对应 Skill 目录
建立
.claude/skills/your-first-skill/,写出最小可用的 SKILL.md,把复杂规则暂时留空或简单占位。 -
连续使用一周,并记录不满意点
哪些场景触发不准?哪些输出风格不对?哪些时候知识不够?通通记下来。
-
迭代资源层和示例
慢慢把团队的真实规范、优秀范例、典型案例搬进 resources/ 和 examples/,让 Skill 越用越"像你们自己"。
当你有了几枚稳定运行的 Skills,再配合 Hooks 和 Agents 把它们串成完整流程时,你就会发现:
AI 已经不再只是"你问我答"的助手,而是在后台不知疲倦地执行一套又一套既定动作,默默托起你的整个开发工作流。
