最近调研了 FastGPT 项目,它是一个基于 LLM 大语言模型的知识库问答系统,将智能对话与可视化编排结合,打造专属的 AI 应用。本文给大家介绍一下这种智能问答背后所涉及到的技术概念。
为什么不直接使用网页版大模型
其实市面上的各种网页版大模型应用已经很好用了,但是某些特定范围内的知识,大模型可能并不清楚。比如你希望大模型根据企业的规章制度来回答问题,或者根据你们学校近年来的习题来预测今年的期末试卷。那么,你就需要先将这些资料作为附件上传,让大模型基于你的附件来回答问题。这里可能会遇到一些问题。
绝对的隐私保护
联网使用大模型,你所有上传的内部资料、采购合同等文件肯定会发送到供应商的服务器,所以涉密资料无法做到绝对的隐私保护。
上下文窗口的限制
网页版的 AI 对于文件的上传数量有限制。如果你上传的文件过多,超过了上下文窗口大小的话,模型就会读了后面忘了前面,准确率下降,推理成本变高,推理速度也会变慢。而且文件的解析需要额外的算力,甚至有些高级功能还需要额外付费。
个性化的知识库构建
当你想通过这上百份的资料来构建自己的知识库时,模型同样无力去支持。而且,通过上传附件的方式拓展上下文比较繁琐且功能极为有限。如果你下次想创建一个新的对话,并且仍想引用这些附件时都需要重新上传。另外,在原有文件的基础上进行新增或修改也都是非常困难的。
基于以上几点,我们可以考虑本地部署一套大模型,这样请求就不需要发送到别人的服务器上了。而对于个性化的知识库构建,我们可以使用 RAG 技术来实现。
RAG 与 模型微调
RAG(Retrieval-augmented Generation)和模型微调(Fine-tuning)都是用来解决大模型的幻觉问题。所谓幻觉问题,就是指大模型在回答它不知道的问题时,会胡说八道。
模型微调
模型微调(Fine-tuning): 通过特定领域数据对预训练模型进行针对性优化,以提升其在特定任务上的性能。
它指的是,在已有的一个训练模型上结合一些特定任务的数据集做进一步的训练。这样,模型在这一领域的表现就会更好。不过对数据依赖(大量标注数据)、计算资源(GPU服务器),计算成本(训练阶段计算量大)有较高要求。一般企业和个人不适用。
RAG
RAG(Retrieval-Augmented Generation,检索增强生成): 是一种结合了检索和生成技术的文本处理方法,主要用于提高语言模型的输出质量。
RAG 通过在生成回答之前,先从知识库中检索相关信息,然后将检索到的信息作为上下文提供给语言模型,从而实现更准确、更可靠的响应。这种方法既保留了 LLM 模型强大的理解和生成能力,又克服了其知识局限性。
RAG 是目前最常用的 AI 问答方案之一,很多企业内的知识助手、智能客服用的都是这项技术。我们接下来将着重介绍 RAG 技术的相关概念。
RAG 工作机制
RAG 主要有两个流程:提问前的准备流程、提问后的回答流程。
1. 准备流程
1.1 分片
分片,即把文档切分成多个片段。分片的方式有很多种,可以按照字数、段落、章节、页码等方式来切分文档。
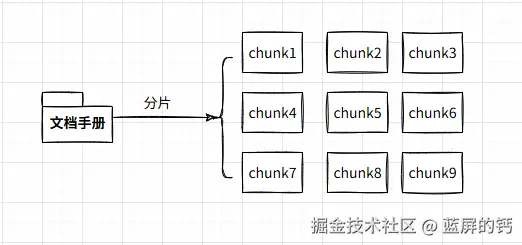
1.2 索引
索引,就是通过 Embedding 将这些文本片段转换为多维向量,再将这些向量存储在向量数据库的过程。模型就是在这个阶段将人类的自然语言解析成机器能读懂的向量数据。
1.2.1 Embedding
Embedding 是什么?多维向量如何表示自然语言呢?
"Embedding"在字面上的翻译是"嵌入",但在机器学习和自然语言处理的上下文中,我们更倾向于将其理解为一种 "向量化" 或 "向量表示" 的技术,这有助于更准确地描述其在这些领域中的应用和作用。
在机器学习中,Embedding 主要是指将离散的高维数据(如文字、图片、音频)映射到低纬度的连续向量空间 。这个过程会生成由实数构成的向量,用于捕捉原始数据的潜在搞关系和结构。
比如,有以下三句话:"我爱吃水果"、"我喜欢吃榴莲"、"明天有雨"。很明显,前两句话相关,而最后一句话毫无关系,那么在向量中,它们就可以这样表示:
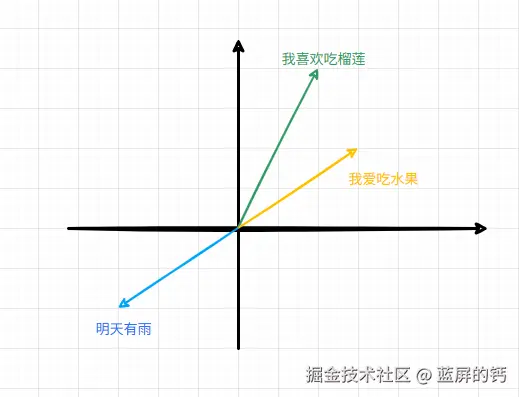
这样,我们就可以通过多维向量直观地表达自然语言之间的潜在关系了。
1.2.2 Embedding 模型
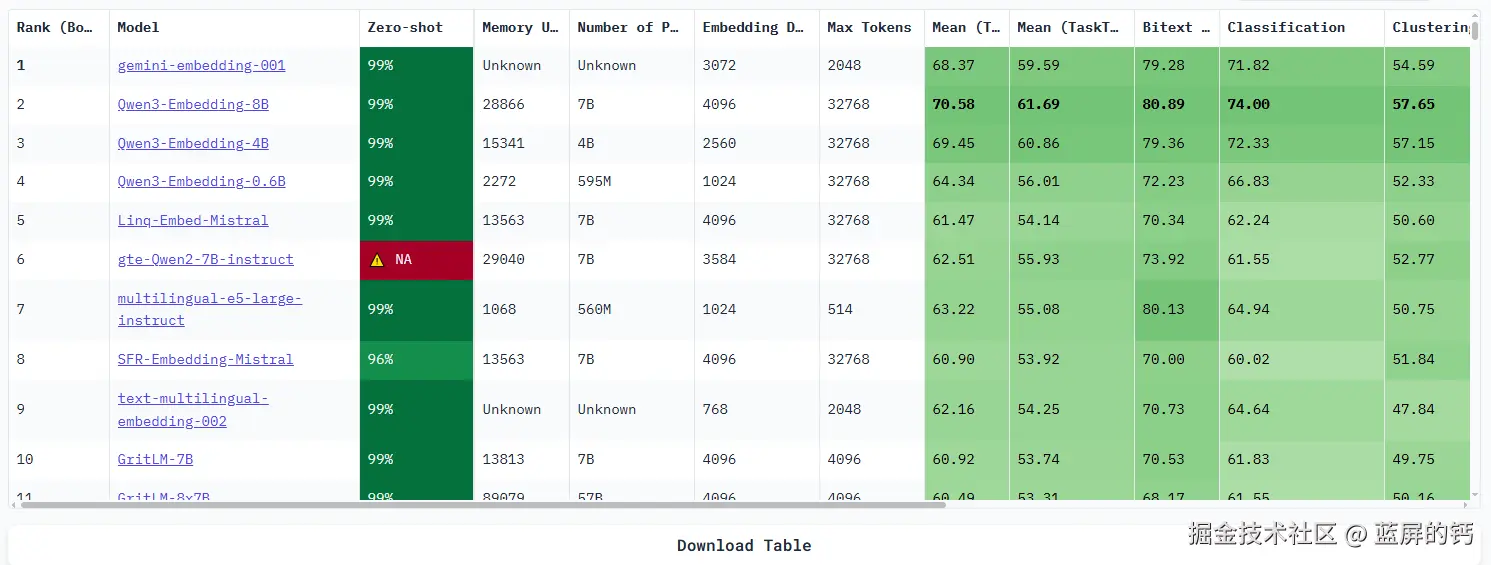
进行 Embedding 操作的模型不是我们通常所使用的 GPT-4o、DeepSeek-R1 这类的 LLM 大语言模型,而是专用的 Embedding 模型。在 MTEB 排行榜 上,你可以看到 Embedding 模型的排行。目前谷歌的 gemini 排在第一,阿里的 Qwen3 屈居第二。
1.2.3 向量数据库
向量数据库为存储向量做了很多优化,并且还提供了计算向量相似度等相关函数,方便我们使用向量。
在得到 Embedding 向量后,我们会连同原始文本一同发送给向量数据库,因为只有这样,我们才能够在通过向量相似度查询出相似的向量后把对应的原始文本也抽取出来发给大模型。
我们最终需要的还是原始的自然语言文本,向量只是一个中间结果,所以一般的向量数据库表格里面至少都会有原始文本和向量两列内容。

2. 回答流程
2.1 召回
召回(Recall),就是搜索与用户问题相关片段的过程,这个环节从用户问题开始。
首先,问题会发给 Embedding 模型,模型将其转换成向量,然后我们把它发送给向量数据库,让数据库查询与用户问题最相关的 10 个(也可以是15、20 等)片段内容。
那数据库是如何查找相似片段的呢?
2.1.1 向量相似度
向量相似度用于衡量两个向量在空间中的相近程度。我们一般采用计算相似度的方法来判断两个向量的相似程度,常用的有余弦相似度、欧式距离相似度、点积等。
下面以一个简单的本地流程为例,使用 sentence-transformers 做嵌入,用 FAISS 做向量检索,模拟"用户问题 vs 向量数据库"的相似度计算过程。
py
from sentence_transformers import SentenceTransformer
import faiss
import numpy as np
# 加载预训练的文本嵌入模型(用于将文本转为向量)
model = SentenceTransformer('all-MiniLM-L6-v2')
# 向量数据库中的数据(比如一些文档、问答对等)
database_texts = [ "如何重置我的密码?", "什么是人工智能?", "怎么购买商品?", "天气预报怎么查?", "如何联系客服?" ]
# 将数据库中的每个文本转化为向量,并构建向量数据库
database_embeddings = model.encode(database_texts, convert_to_tensor=False)
# 构建 FAISS 索引
dimension = database_embeddings.shape[1] # 向量维度
index = faiss.IndexFlatL2(dimension) # 使用 L2 距离(欧式距离)也可以使用 faiss.IndexFlatIP 内积
index.add(database_embeddings) # 向 FAISS 中添加向量
# 将用户输入问题转为向量
user_question = "我忘记密码了怎么办?"
user_embedding = model.encode([user_question], convert_to_tensor=False)
# 在向量数据库中检索相似向量
k = 10
# 返回最相似的 3 条结果
distances, indices = index.search(user_embedding, k)
for i, idx in enumerate(indices[0]):
distance = distances[0][i]
text = database_texts[idx]
# 如果使用的是 L2 距离,数值越小越相似;也可以换余弦相似度
print(f"[{i+1}] 相似内容:{text} ------ 距离(L2):{distance:.4f}")通过计算,我们就能找到与用户问题最接近的片段了。
2.2 重排
重排,全称是重新排序(Re-Ranking)。它做的事情其实跟召回是一样的,如果说召回是从所有片段中挑 10 个,那么重排就是从这 10 个中再挑选出 3 份与用户问题最为相似的。
那为什么不直接在召回阶段就选出前 3 个呢?重排和召回又有什么区别呢?
最重要的原因是召回阶段获取的数据准确率并不高,这种方法的优势在于成本低,耗时短,只适合初步筛选。
而重排阶段一般是使用一种叫 cross-encoder(交叉编码器)的模型。相比之下,cross-encoder 的成本较高,耗时也较长,所以很适合精挑细选。
Cross-Encoder 使用单编码器模型来同时编码查询和文档,它能够捕捉查询和文档之间的复杂交互关系,因此能够提供更精准的搜索排序结果。Cross-Encoder 并不输出查询和文档的 Token 所对应的向量,而是再添加一个分类器直接输出查询和文档的相似度得分。它的缺点在于,由于需要在查询时对每个文档和查询共同编码,这使得排序的速度非常慢,因此 Cross-Encoder 只能用于最终结果的重排序。
以下是两者的对比图:
| 维度 | 召回(Recall / Retrieval) | 重排(Re-Ranking / Ranking) |
|---|---|---|
| 阶段 | 第一阶段:粗筛 | 第二阶段:精筛 |
| 目标 | 覆盖尽可能多的相关内容,不漏掉重要结果 | 从候选集中挑出最相关、最优质的内容 |
| 数据量 | 输入数据量大(如几亿条),输出候选集较小(如几千~几万条) | 输入是召回后的候选集(如几千条),输出是最终展示的少量结果(如 Top 10) |
| 速度要求 | 要快,算法要高效,常使用近似方法 | 可以稍慢,更注重精准度 |
| 精度要求 | 不要求非常精准,允许一定误差 | 要求高精准度,排序要准 |
| 常用方法 | 关键词检索(BM25)、向量检索(FAISS)、简单过滤规则 | 精排模型(BERT、Learning to Rank)、多特征融合排序 |
| 关注点 | 召回率(Recall) | 精确率(Precision)、排序质量 |
| 比喻 | 从大海里先捞出一筐可能相关的鱼 | 从这一筐鱼里挑出最好、最新鲜、最符合你口味的几条 |
2.3 生成
现在,我们有了用户问题和与问题相似的三个片段,我们就可以把两者都发给大模型,让它根据片段内容来回答用户问题,到此,整个流程就结束了。
完整流程
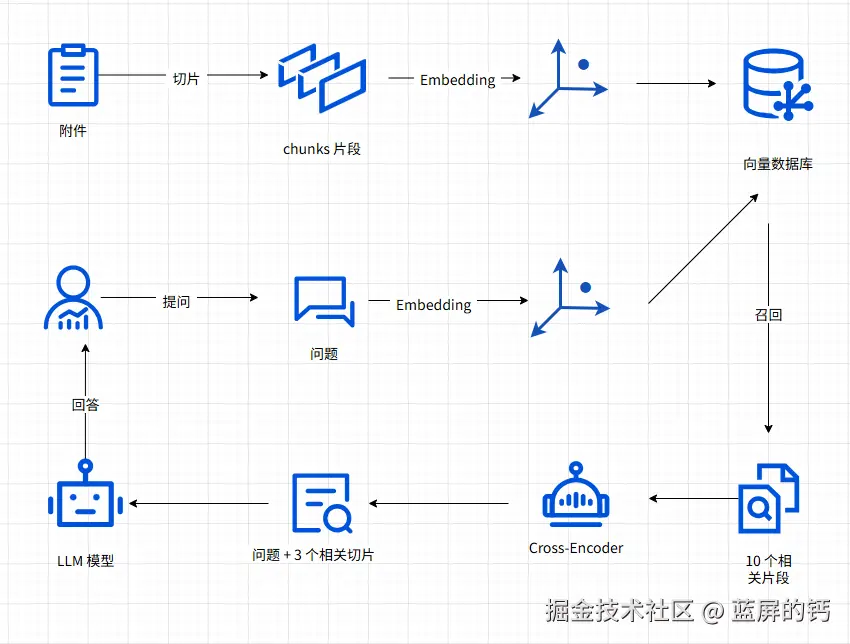
如何使用 Ollama 接入本地模型
Ollama 是一个开源的AI大模型部署工具,专注于简化大语言模型的部署和使用,支持一键下载和运行各种大模型。我们可以采用 Ollama 部署自己想要的模型。
安装 Ollama
推荐 Docker 内安装,这样就可以和 FastGPT 容器直接互相访问了。
bash
docker run -d --name ollama --network (你的 Fastgpt 容器所在网络) -p 11434:11434 ollama/ollama在 FastGPT 容器中尝试访问 Ollama:
bash
curl http://ollama:11434
拉取模型镜像
bash
# 拉取 qwen2.5 模型
ollama pull qwen2.5:0.5b
# 查看所有模型
ollama ls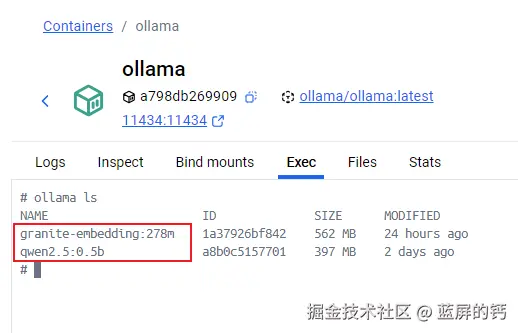
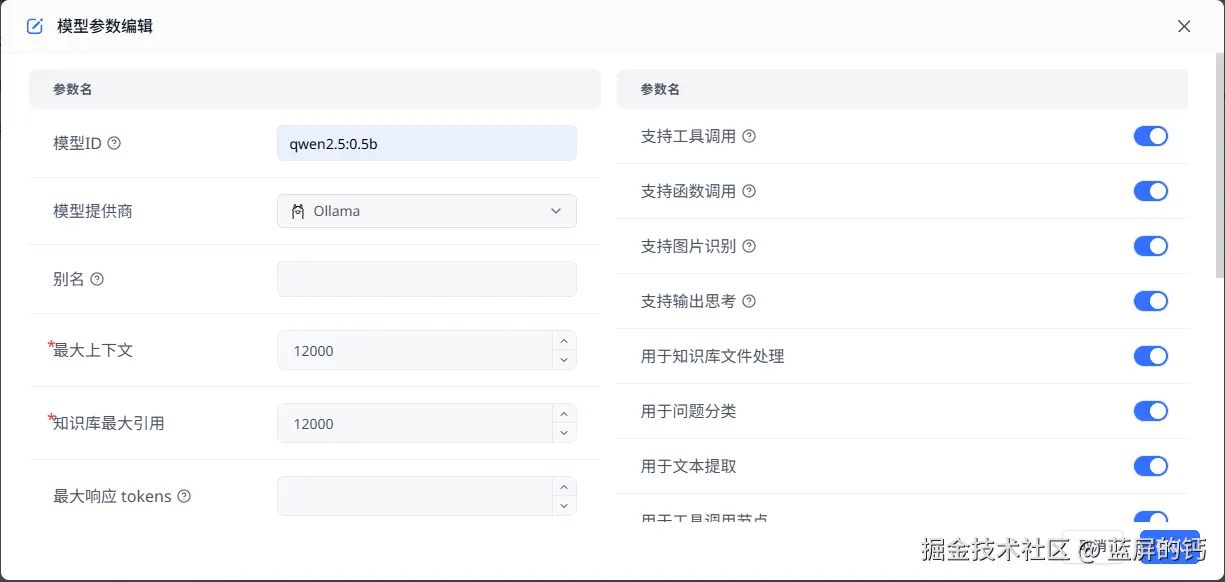
配置模型与渠道
模型渠道是用来管理模型的,在 FastGPT 中,你可以先创建一些模型,然后将其加入到渠道中:
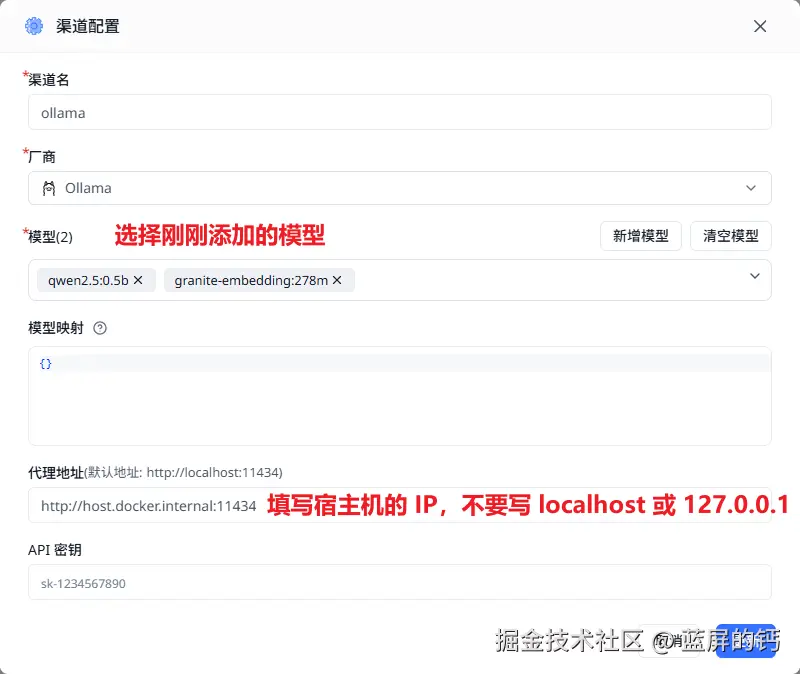
可以测试一下模型是否跑通:
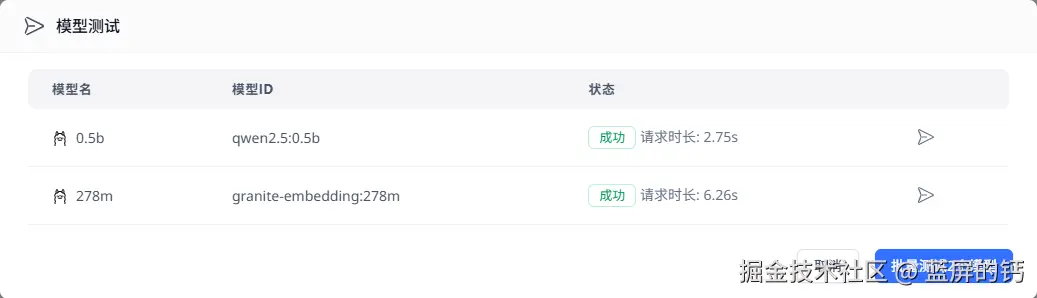
打造自己的知识库、工作台、对话
安装好大模型后,你就可以搭建自己的 AI 应用了!
在 FastGPT 中,你可以自定义智能对话的流程和各种配置,功能十分丰富,其中我感觉最有用的还是 问题分类 + 知识库 和 知识库 + 对话引导。
大家有兴趣快动手试试吧~!