文章翻译自官网github.com/anthropics/...
你的第一个简单工具
在上一课中,我们介绍了工具使用的工作流程。现在是时候实际动手实现一个简单的工具使用示例了。回顾一下,工具使用过程最多有 4 个步骤:
向 Claude 提供工具和用户提示:(API 请求)
-
定义你希望 Claude 能够使用的工具集,包括它们的名称、描述和输入模式。
-
提供一个可能需要使用这些工具中的一个或多个来回答的用户提示。
Claude 使用工具:(API 响应)
-
Claude 评估用户提示,并决定是否有任何可用工具能帮助解决用户的查询或任务。如果有,它还会决定使用哪些工具以及使用什么输入。
-
Claude 输出格式正确的工具使用请求。
-
API 响应的 stop_reason 将为 tool_use,表明 Claude 想要使用外部工具。
提取工具输入、运行代码并返回结果:(API 请求)
-
在客户端,你需要从 Claude 的工具使用请求中提取工具名称和输入。
-
在客户端运行实际的工具代码。
-
通过在新的用户消息中包含 tool_result 内容块来继续对话,从而将结果返回给 Claude。
Claude 使用工具结果来制定响应:(API 响应)
- 收到工具结果后,Claude 将使用该信息来制定对原始用户提示的最终响应。
我们将从一个简单的演示开始,只需要与 Claude "交谈" 一次(别担心,我们很快就会看到更有趣的例子!)。这意味着我们暂时不会涉及步骤 4。我们会让 Claude 回答一个问题,Claude 会请求使用工具来回答,然后我们提取工具输入、运行代码并返回结果值。
如今的大型语言模型在数学运算方面表现不佳,如下列代码所示。
我们让 Claude "计算 1984135 乘以 9343116":
python
运行
ini
from anthropic import Anthropic
from dotenv import load_dotenv
load_dotenv()
client = Anthropic()
# 一个相对简单的数学问题
response = client.messages.create(
model="claude-3-haiku-20240307",
messages=[{"role": "user", "content":"Multiply 1984135 by 9343116. Only respond with the result"}],
max_tokens=400
)
print(response.content[0].text)
18555375560多次运行上述代码可能会得到不同的答案,但这是 Claude 给出的一个答案:
18593367726060
实际正确答案是:
18538003464660
Claude 的答案略有偏差,相差了 55364261400!
工具使用来解围!
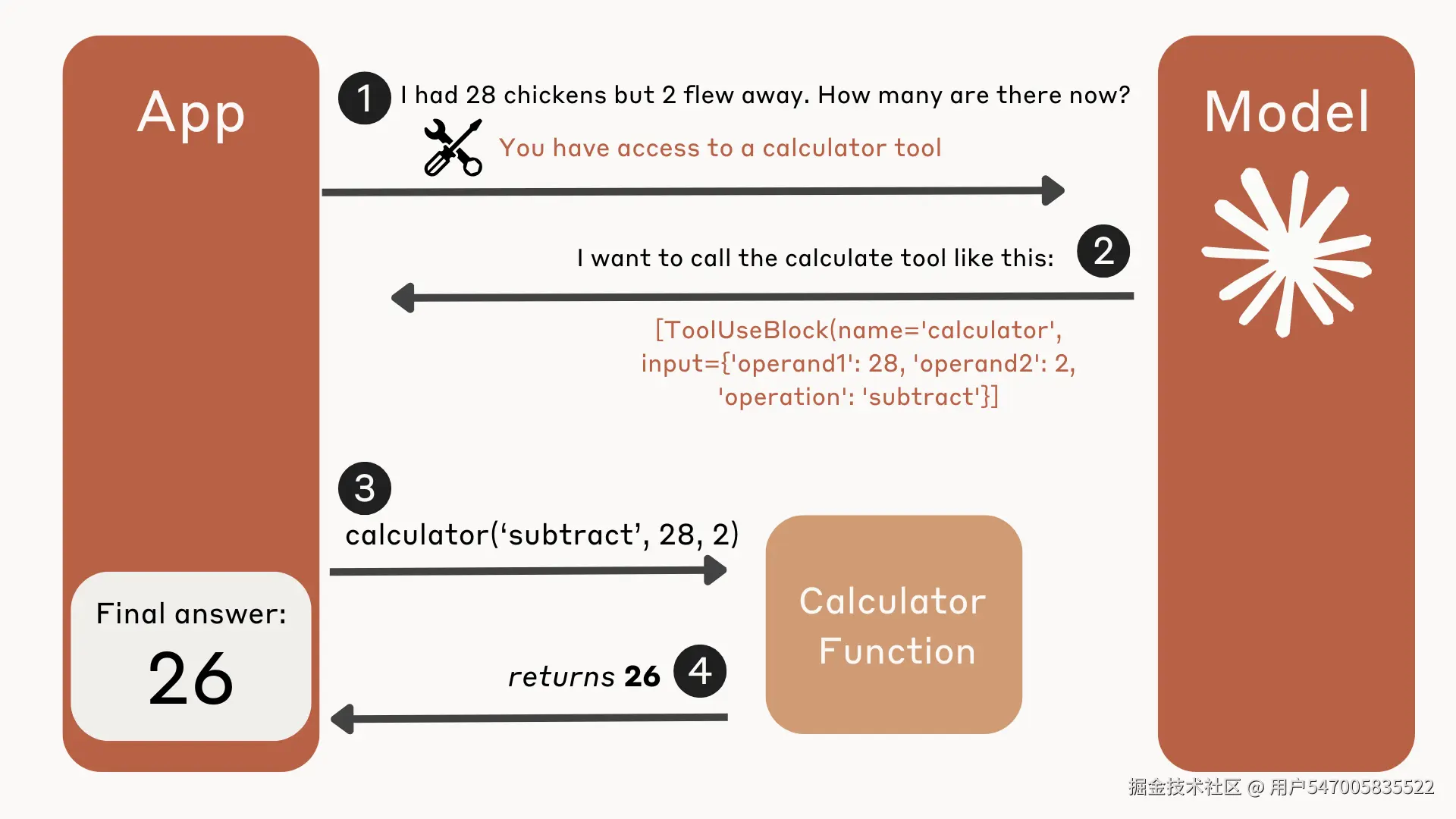
Claude 不擅长进行复杂的数学运算,所以让我们通过提供计算器工具来增强 Claude 的能力。
下面是一个解释该过程的简单图表:
chickens_calculator.png
第一步是定义实际的计算器函数,并确保它能独立于 Claude 运行。我们将编写一个非常简单的函数,它需要三个参数:
-
操作,如 "加" 或 "乘"
-
两个操作数
以下是基本实现:
python
运行
python
def calculator(operation, operand1, operand2):
if operation == "add":
return operand1 + operand2
elif operation == "subtract":
return operand1 - operand2
elif operation == "multiply":
return operand1 * operand2
elif operation == "divide":
if operand2 == 0:
raise ValueError("Cannot divide by zero.")
return operand1 / operand2
else:
raise ValueError(f"Unsupported operation: {operation}")请注意,这个简单的函数用途非常有限,因为它只能处理像 234 + 213 或 3 * 9 这样的简单表达式。这里的重点是通过一个非常简单的教学示例来了解工具的使用过程。
让我们测试一下我们的函数,确保它能正常工作。
python
运行
scss
calculator("add", 10, 3)
13
calculator("divide", 200, 25)
8.0下一步是定义我们的工具并告诉 Claude 关于它的信息。定义工具时,我们要遵循非常特定的格式。每个工具定义包括:
-
name:工具的名称。必须匹配正则表达式 ^a-zA-Z0-9_-{1,64}$。
-
description:关于工具的功能、使用场景和行为的详细纯文本描述。
-
input_schema:一个 JSON Schema 对象,定义了工具的预期参数。
不熟悉 JSON Schema?在这里了解更多。
以下是一个假设工具的简单示例:
json
css
{
"name": "send_email",
"description": "Sends an email to the specified recipient with the given subject and body.",
"input_schema": {
"type": "object",
"properties": {
"to": {
"type": "string",
"description": "The email address of the recipient"
},
"subject": {
"type": "string",
"description": "The subject line of the email"
},
"body": {
"type": "string",
"description": "The content of the email message"
}
},
"required": ["to", "subject", "body"]
}
}这个名为 send_email 的工具需要以下输入:
-
to:字符串类型,必填
-
subject:字符串类型,必填
-
body:字符串类型,必填
下面是另一个名为 search_product 的工具定义:
json
json
{
"name": "search_product",
"description": "Search for a product by name or keyword and return its current price and availability.",
"input_schema": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "The product name or search keyword, e.g. 'iPhone 13 Pro' or 'wireless headphones'"
},
"category": {
"type": "string",
"enum": ["electronics", "clothing", "home", "toys", "sports"],
"description": "The product category to narrow down the search results"
},
"max_price": {
"type": "number",
"description": "The maximum price of the product, used to filter the search results"
}
},
"required": ["query"]
}
}这个工具有 3 个输入:
-
必需的 query 字符串,表示产品名称或搜索关键词
-
可选的 category 字符串,必须是预定义的值之一,用于缩小搜索范围。注意定义中的 "enum"。
-
可选的 max_price 数字,用于筛选低于特定价格点的结果
我们的计算器工具定义
让我们为我们前面编写的计算器函数定义相应的工具。我们知道计算器函数有 3 个必需的参数:
-
operation - 只能是 "add"、"subtract"、"multiply" 或 "divide"
-
operand1 - 应该是一个数字
-
operand2 - 也应该是一个数字
以下是工具定义:
python
运行
makefile
calculator_tool = {
"name": "calculator",
"description": "A simple calculator that performs basic arithmetic operations.",
"input_schema": {
"type": "object",
"properties": {
"operation": {
"type": "string",
"enum": ["add", "subtract", "multiply", "divide"],
"description": "The arithmetic operation to perform."
},
"operand1": {
"type": "number",
"description": "The first operand."
},
"operand2": {
"type": "number",
"description": "The second operand."
}
},
"required": ["operation", "operand1", "operand2"]
}
}练习
让我们以以下函数为例,练习编写格式正确的工具定义:
python
运行
python
def inventory_lookup(product_name, max_results):
return "this function doesn't do anything"
# 你不需要修改这个函数或对它做任何操作!这个假设的 inventory_lookup 函数应该像这样调用:
python
运行
scss
inventory_lookup("AA batteries", 4)
inventory_lookup("birthday candle", 10)你的任务是编写相应的、格式正确的工具定义。假设在你的工具定义中,这两个参数都是必需的。
向 Claude 提供我们的工具
现在回到我们之前的计算器函数。在这一点上,Claude 对计算器工具一无所知!它只是一个小小的 Python 字典。当我们向 Claude 发出请求时,我们可以传递一个工具列表来 "告知" Claude。现在让我们尝试一下:
python
运行
ini
response = client.messages.create(
model="claude-3-haiku-20240307",
messages=[{"role": "user", "content": "计算1984135乘以9343116。只返回结果"}],
max_tokens=300,
# 告诉Claude我们的工具
tools=[calculator_tool]
)接下来,让我们看看 Claude 给我们的响应:
plaintext
python
response
ToolsBetaMessage(id='msg_01UfKwdmEsgTh99wfpgW4NJ7', content=[ToolUseBlock(id='toolu_015wQ7Wipo589yT9B3YTwjF1', input={'operand1': 1984135, 'operand2': 9343116, 'operation': 'multiply'}, name='calculator', type='tool_use')], model='claude-3-haiku-20240307', role='assistant', stop_reason='tool_use', stop_sequence=None, type='message', usage=Usage(input_tokens=420, output_tokens=93))
ToolsBetaMessage(id='msg_01UfKwdmEsgTh99wfpgW4NJ7', content=[ToolUseBlock(id='toolu_015wQ7Wipo589yT9B3YTwjF1', input={'operand1': 1984135, 'operand2': 9343116, 'operation': 'multiply'}, name='calculator', type='tool_use')], model='claude-3-haiku-20240307', role='assistant', stop_reason='tool_use', stop_sequence=None, type='message', usage=Usage(input_tokens=420, output_tokens=93))你可能会注意到我们的响应看起来和平时有点不同!具体来说,我们现在得到的不是一个普通的 Message,而是一个 ToolsMessage。
此外,我们可以查看 response.stop_reason,会发现 Claude 停止是因为它决定该使用工具了:
python
运行
arduino
response.stop_reason
'tool_use'response.content 包含一个列表,其中有一个 ToolUseBlock,它本身包含了工具名称和输入的信息:
python
运行
python
response.content
[ToolUseBlock(id='toolu_015wQ7Wipo589yT9B3YTwjF1', input={'operand1': 1984135, 'operand2': 9343116, 'operation': 'multiply'}, name='calculator', type='tool_use')]python
运行
lua
tool_name = response.content[0].name
tool_inputs = response.content[0].input
print("Claude想要调用的工具名称:", tool_name)
print("Claude想要传入的参数:", tool_inputs)
Claude想要调用的工具名称: calculator
Claude想要传入的参数: {'operand1': 1984135, 'operand2': 9343116, 'operation': 'multiply'}下一步就是简单地获取 Claude 提供给我们的工具名称和输入,并用它们来实际调用我们之前编写的计算器函数。然后我们就会得到最终答案!
python
运行
ini
operation = tool_inputs["operation"]
operand1 = tool_inputs["operand1"]
operand2 = tool_inputs["operand2"]
result = calculator(operation, operand1, operand2)
print("结果是", result)
结果是 18538003464660我们得到了正确答案 18538003464660!!!我们没有依赖 Claude 来正确完成数学运算,而是简单地向 Claude 提出问题,并在必要时让它使用我们提供的工具。
重要提示
如果我们问 Claude 一些不需要使用工具的问题,在这种情况下,比如与数学或计算无关的内容,我们可能希望它正常回应。Claude 通常会这样做,但有时它会非常渴望使用工具!
举个例子,有时 Claude 会尝试使用计算器,即使使用它毫无意义。让我们看看当我们问 Claude"祖母绿是什么颜色的?" 时会发生什么:
python
运行
ini
response = client.messages.create(
model="claude-3-haiku-20240307",
messages=[{"role": "user", "content":"祖母绿是什么颜色的?"}],
max_tokens=400,
tools=[calculator_tool]
)
response
ToolsBetaMessage(id='msg_01Dj82HdyrxGJpi8XVtqEYvs', content=[ToolUseBlock(id='toolu_01Xo7x3dV1FVoBSGntHNAX4Q', input={'operand1': 0, 'operand2': 0, 'operation': 'add'}, name='calculator', type='tool_use')], model='claude-3-haiku-20240307', role='assistant', stop_reason='tool_use', stop_sequence=None, type='message', usage=Usage(input_tokens=409, output_tokens=89))Claude 给了我们这样的回应:
plaintext
python
ToolsBetaMessage(id='msg_01Dj82HdyrxGJpi8XVtqEYvs', content=[ToolUseBlock(id='toolu_01Xo7x3dV1FVoBSGntHNAX4Q', input={'operand1': 0, 'operand2': 0, 'operation': 'add'}, name='calculator', type='tool_use')], model='claude-3-haiku-20240307', role='assistant', stop_reason='tool_use', stop_sequence=None, type='message', usage=Usage(input_tokens=409, output_tokens=89))Claude 想让我们调用计算器工具?一个非常简单的解决方法是调整我们的提示或添加一个系统提示,内容大致如下:你可以使用工具,但只在必要时使用。如果不需要工具,就正常回应:
python
运行
ini
response = client.messages.create(
model="claude-3-haiku-20240307",
system="你可以使用工具,但只在必要时使用。如果不需要工具,就正常回应",
messages=[{"role": "user", "content":"祖母绿是什么颜色的?"}],
max_tokens=400,
tools=[calculator_tool]
)
response
ToolsBetaMessage(id='msg_01YRRfnUUhP1u5ojr9iWZGGu', content=[TextBlock(text='Emeralds are green in color.', type='text')], model='claude-3-haiku-20240307', role='assistant', stop_reason='end_turn', stop_sequence=None, type='message', usage=Usage(input_tokens=434, output_tokens=12))现在 Claude 会给出恰当的回应,不会在没有意义的情况下强行使用工具。我们得到的新回应是:
plaintext
arduino
'祖母绿是绿色的。'我们还可以看到,stop_reason 现在是 end_turn 而不是 tool_use。
python
运行
arduino
response.stop_reason
'end_turn'整合在一起
python
运行
python
def calculator(operation, operand1, operand2):
if operation == "add":
return operand1 + operand2
elif operation == "subtract":
return operand1 - operand2
elif operation == "multiply":
return operand1 * operand2
elif operation == "divide":
if operand2 == 0:
raise ValueError("不能除以零。")
return operand1 / operand2
else:
raise ValueError(f"不支持的操作:{operation}")
calculator_tool = {
"name": "calculator",
"description": "一个简单的计算器,可执行基本的算术运算。",
"input_schema": {
"type": "object",
"properties": {
"operation": {
"type": "string",
"enum": ["add", "subtract", "multiply", "divide"],
"description": "要执行的算术运算。",
},
"operand1": {"type": "number", "description": "第一个操作数。"},
"operand2": {"type": "number", "description": "第二个操作数。"},
},
"required": ["operation", "operand1", "operand2"],
},
}
def prompt_claude(prompt):
messages = [{"role": "user", "content": prompt}]
response = client.messages.create(
model="claude-3-haiku-20240307",
system="你可以使用工具,但只在必要时使用。如果不需要工具,就正常回应",
messages=messages,
max_tokens=500,
tools=[calculator_tool],
)
if response.stop_reason == "tool_use":
tool_use = response.content[-1]
tool_name = tool_use.name
tool_input = tool_use.input
if tool_name == "calculator":
print("Claude想要使用计算器工具")
operation = tool_input["operation"]
operand1 = tool_input["operand1"]
operand2 = tool_input["operand2"]
try:
result = calculator(operation, operand1, operand2)
print("计算结果是:", result)
except ValueError as e:
print(f"错误:{str(e)}")
elif response.stop_reason == "end_turn":
print("Claude不想使用工具")
print("Claude的回应是:")
print(response.content[0].text)python
运行
scss
prompt_claude("我有23只鸡,但有2只飞走了。还剩下多少只?")
Claude想要使用计算器工具
计算结果是: 21python
运行
scss
prompt_claude("201乘以2是多少")
Claude想要使用计算器工具
计算结果是: 402python
运行
scss
prompt_claude("给我写一首关于海洋的俳句")
Claude不想使用工具
Claude的回应是:
这是一首关于海洋的俳句:
浩瀚蓝舒展,
浪涛拍岸沙有声,
海洋抚慰歌。练习
你的任务是帮助构建一个使用 Claude 的研究助手。用户可以输入他们想要研究的主题,并将一系列维基百科文章链接保存到一个 markdown 文件中,供以后阅读。我们可以尝试直接让 Claude 生成文章 URL 列表,但 Claude 在处理 URL 方面并不可靠,可能会虚构文章 URL。此外,在 Claude 的训练截止日期之后,合法的文章可能已经迁移到了新的 URL。相反,我们将使用一个连接到真实维基百科 API 的工具来实现这一点!
我们会为 Claude 提供一个工具,该工具接受 Claude 生成的一系列可能的维基百科文章标题(但这些标题可能是虚构的)。我们可以使用这个工具搜索维基百科,找到实际的维基百科文章标题和 URL,以确保最终列表中的所有文章都是真实存在的。然后,我们会将这些文章 URL 保存到一个 markdown 文件中,供以后阅读。
我们为你提供了两个辅助函数:
python
运行
python
import wikipedia
def generate_wikipedia_reading_list(research_topic, article_titles):
wikipedia_articles = []
for t in article_titles:
results = wikipedia.search(t)
try:
page = wikipedia.page(results[0])
title = page.title
url = page.url
wikipedia_articles.append({"title": title, "url": url})
except:
continue
add_to_research_reading_file(wikipedia_articles, research_topic)
def add_to_research_reading_file(articles, topic):
with open("output/research_reading.md", "a", encoding="utf-8") as file:
file.write(f"## {topic} \n")
for article in articles:
title = article["title"]
url = article["url"]
file.write(f"* [{title}]({url}) \n")
file.write(f"\n\n")第一个函数 generate_wikipedia_reading_list 需要传入一个研究主题,比如 "夏威夷的历史" 或 "世界各地的海盗",以及一个我们让 Claude 生成的潜在维基百科文章名称列表。该函数使用 wikipedia 包搜索相应的真实维基百科页面,并构建一个包含文章标题和 URL 的字典列表。
然后它调用 add_to_research_reading_file,传入维基百科文章数据列表和整体研究主题。这个函数只是将每个维基百科文章的 markdown 链接添加到一个名为 output/research_reading.md 的文件中。文件名目前是硬编码的,并且该函数假设该文件存在。在这个仓库中它是存在的,但如果你在其他地方工作,你需要自己创建它。
思路是让 Claude "调用" generate_wikipedia_reading_list,传入一系列可能真实也可能不真实的文章标题列表。Claude 可能会传入以下文章标题列表,其中一些是真实的维基百科文章,一些则不是:
plaintext
css
["海盗行为", "著名海盗船", "海盗的黄金时代", "海盗列表", "海盗与鹦鹉", "21世纪的海盗行为"]generate_wikipedia_reading_list 函数会遍历这些文章标题,为任何实际存在的维基百科文章收集真实的文章标题和相应的 URL。然后它调用 add_to_research_reading_file,将内容写入 markdown 文件,供以后参考。
最终目标
你的任务是实现一个名为 get_research_help 的函数,它接受一个研究主题和所需的文章数量。这个函数应该使用 Claude 来实际生成可能的维基百科文章列表,并调用上面的 generate_wikipedia_reading_list 函数。以下是一些函数调用示例:
python
运行
scss
get_research_help("世界各地的海盗", 7)
get_research_help("夏威夷历史", 3)
get_research_help("动物有意识吗?", 3)在这 3 次函数调用之后,我们的输出文件 research_reading.md 会是这个样子(你可以在 output/research_reading.md 中自行查看):
research_reading.png
要完成这个任务,你需要做以下事情:
为 generate_wikipedia_reading_list 函数编写工具定义
实现 get_research_help 函数
向 Claude 编写一个提示,告诉它你需要帮助收集关于特定主题的研究,以及你希望它生成多少个文章标题
告诉 Claude 它可以使用的工具
发送你的请求给 Claude
检查 Claude 是否调用了工具。如果调用了,你需要将它生成的文章标题和主题传递给我们提供的 generate_wikipedia_reading_list 函数。该函数将收集实际的维基百科文章链接,然后调用 add_to_research_reading_file 将链接写入 output/research_reading.md
打开 output/research_reading.md 看看是否成功!
starter 代码
python
运行
python
# 这是你的 starter 代码!
import wikipedia
def generate_wikipedia_reading_list(research_topic, article_titles):
wikipedia_articles = []
for t in article_titles:
results = wikipedia.search(t)
try:
page = wikipedia.page(results[0])
title = page.title
url = page.url
wikipedia_articles.append({"title": title, "url": url})
except:
continue
add_to_research_reading_file(wikipedia_articles, research_topic)
def add_to_research_reading_file(articles, topic):
with open("output/research_reading.md", "a", encoding="utf-8") as file:
file.write(f"## {topic} \n")
for article in articles:
title = article["title"]
url = article["url"]
file.write(f"* [{title}]({url}) \n")
file.write(f"\n\n")
def get_research_help(topic, num_articles=3):
# 实现这个函数!
pass写在最后
我正在使用一个非常好用的Claude code 镜像站
不仅响应极速,不怕封禁,还有性价比,填写我的码:5OTTEB还有额外额度,大家一起来试试!