
「【新智元导读】OpenAI 深夜扔出开源核弹,gpt-oss 20B 和 120B 两款模型同时上线。它们不仅性能比肩 o3-mini 和 o4-mini,而且还能在消费级显卡甚至手机上轻松运行。GPT-2 以来,奥特曼终于兑现了 Open AI。」
他来了!他来了!
就在今夜,奥特曼带着两款全新的开源模型走来了!
正如几天前泄露的,它们分别是总参数 1170 亿,激活参数 51 亿的「gpt-oss-120b」和总参数 210 亿,激活参数 36 亿的「gpt-oss-20b」。
终于,OpenAI 再次回归开源。

- gpt-oss-120b 适用于需要高推理能力的生产级和通用型场景
在核心推理基准测试中,120B 模型的表现与 OpenAI o4-mini 相当,并且能在单张 80GB 显存的 GPU 上高效运行(如 H100)。
- gpt-oss-20b 适用于低延迟、本地或专业化场景
在常用基准测试中,20B 模型的表现与 OpenAI o3-mini 类似,并且能在仅有 16GB 显存的边缘设备上运行。
除此之外,两款模型在工具使用、少样本函数调用、CoT 推理以及 HealthBench 评测中也表现强劲,甚至比 OpenAI o1 和 GPT-4o 等专有模型还要更强。
其他亮点如下:
- 宽松的 Apache 2.0 许可证:可自由用于构建,无 copyleft 限制或专利风险------是实验、定制和商业化部署的理想选择。
- 可配置的推理投入:可根据用户的具体用例和延迟需求,轻松调整推理投入(低、中、高)。
- 完整的思维链:可完整访问模型的推理过程,从而简化调试并提升输出结果的可信度。
- 支持微调:支持参数级微调,可根据您的特定用例对模型进行完全定制。
- 智能体能力:利用模型原生的函数调用、网页浏览、Python 代码执行和结构化输出等能力。
- 原生 MXFP4 量化:在训练时,模型的混合专家(MoE)层便采用了原生的 MXFP4 精度,使得 gpt-oss-120b 在单张 H100 GPU 上即可运行,而 gpt-oss-20b 仅需 16GB 内存。
值得一提的是,OpenAI 还特地准备了一个 playground 网站供大家在线体验。
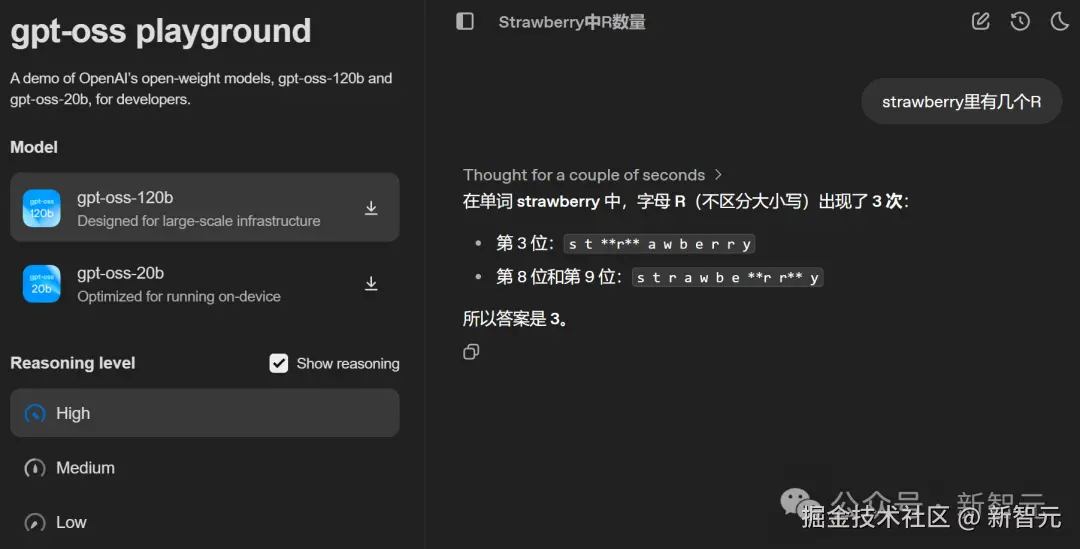
体验地址:gpt-oss.com/

GitHub 项目:github.com/openai/gpt-...
Hugging Face(120B):huggingface.co/openai/gpt-...
Hugging Face(20B):huggingface.co/openai/gpt-...

「GPT-2 以来,首次开源」
gpt-oss 系模型,是 OpenAI 自 GPT-2 以来首次开源的语言模型。
今天,OpenAI 同时放出了 34 页技术报告,模型采用了最先进的预训练和后训练技术。

模型卡:cdn.openai.com/pdf/419b690...
「 」
」
「预训练与模型架构」
相较于此前开源的 Whisper 和 CLIP,gpt-oss 模型在推理能力、效率以及在广泛部署环境中的实用性上更强。
每个模型都采用了 Transformer 架构,并融入 MoE 设计,减少处理输入时激活参数量。
如上所述,gpt-oss-120b 总参数 1170 亿,每 token 激活 51 亿参数,gpt-oss-20b 总参数 210 亿,每 token 激活 36 亿参数。
此外,模型还借鉴了 GPT-3 设计理念,采用了交替的密集注意力和局部带状稀疏注意力模式。

为了提升推理和内存效率,模型还采用了分组多查询注意力机制,组大小为 8,以及旋转位置编码(RoPE),原生支持 128k 上下文。
gpt-oss 模型的训练数据以「英语」为主,聚焦 STEM、编程和通用知识领域。
OpenAI 采用了 o200k_harmony 分词器对数据进行分词,它是 OpenAI o4-mini 和 GPT-4o 所用分词器的「超集」。
今天,这款分词器同步开源。
利好开发者的是,gpt-oss 两款模型与 Responses API兼容,专为智能体工作流打造,在指令遵循、工具使用、推理上极其强大。
比如,它能自主为需要复杂推理,或是目标是极低延迟输出的任务调整推理投入。
同时完全可定制,并提供完整的思维链(CoT),以及支持结构化输出。
据悉,gpt-oss 模型整个预训练成本,低于 50 万美元。

「」
「后训练」
在后训练阶段,gpt-oss 模型的流程与 o4-mini 相似,包含了「监督微调」和「高算力强化学习」阶段。
训练过程中,团队以「OpenAI 模型规范」为目标对齐,并教导模型在生成答案前,使用 CoT 推理和工具。
通过采用与专有 o 系推理模型的相同技术,让 gpt-oss 在后训练中展现出卓越能力。
与 API 中的 OpenAI o 系列推理模型相似,这两款开源模型支持三种推理投入------低、中、高。
开发者只需在系统提示词中加入一句话,即可在延迟与性能间灵活切换。
「开源小模型,比肩旗舰 o3/o4-mini」
在多个基准测试中,gpt-oss-120b 堪比旗舰级 o 系模型的性能。
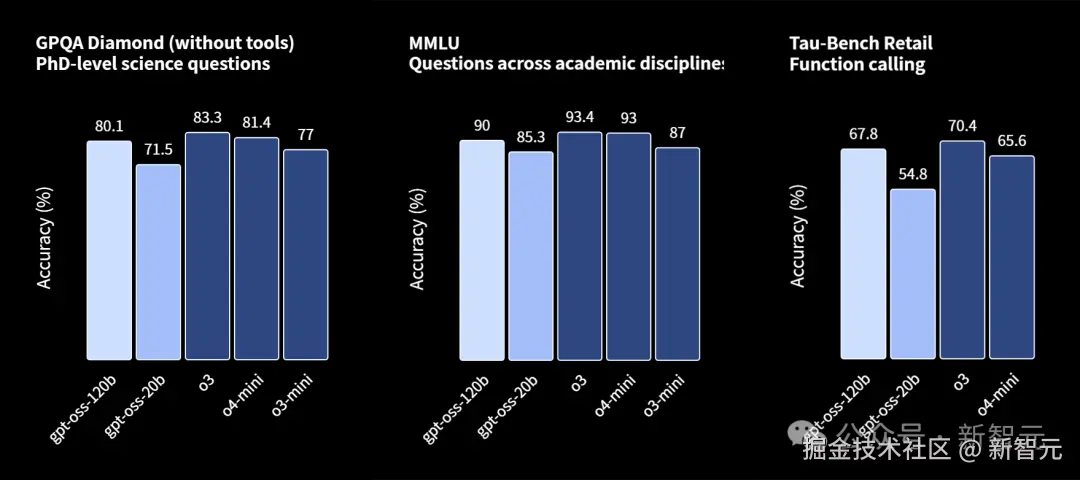
具体来说,在编程竞赛(Codeforces)、通用问题解决(MMLU 和 HLE)以及工具调用(TauBench)方面,它直接超越了 o3-mini,达到甚至超越了 o4-mini 的水平。
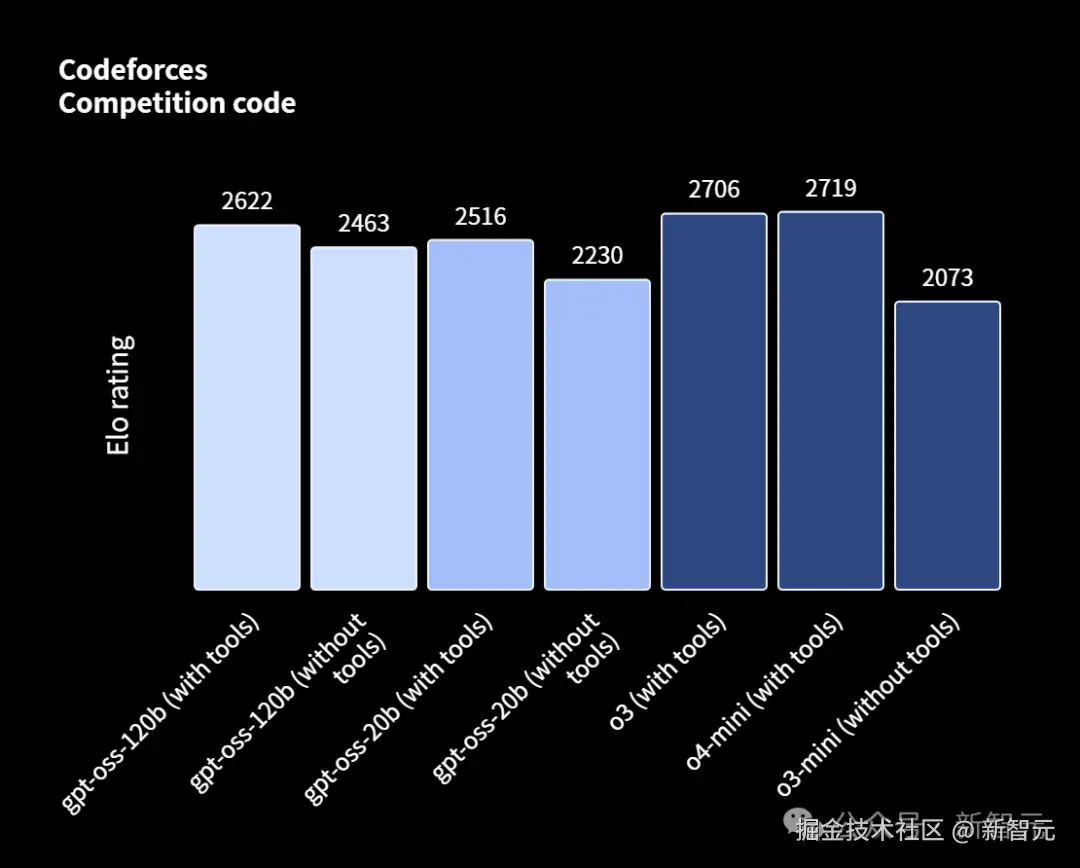
此外,在健康相关查询(HealthBench)、数学竞赛(AIME 2024 & 2025)基准中,它的表现甚至优于 o4-mini。
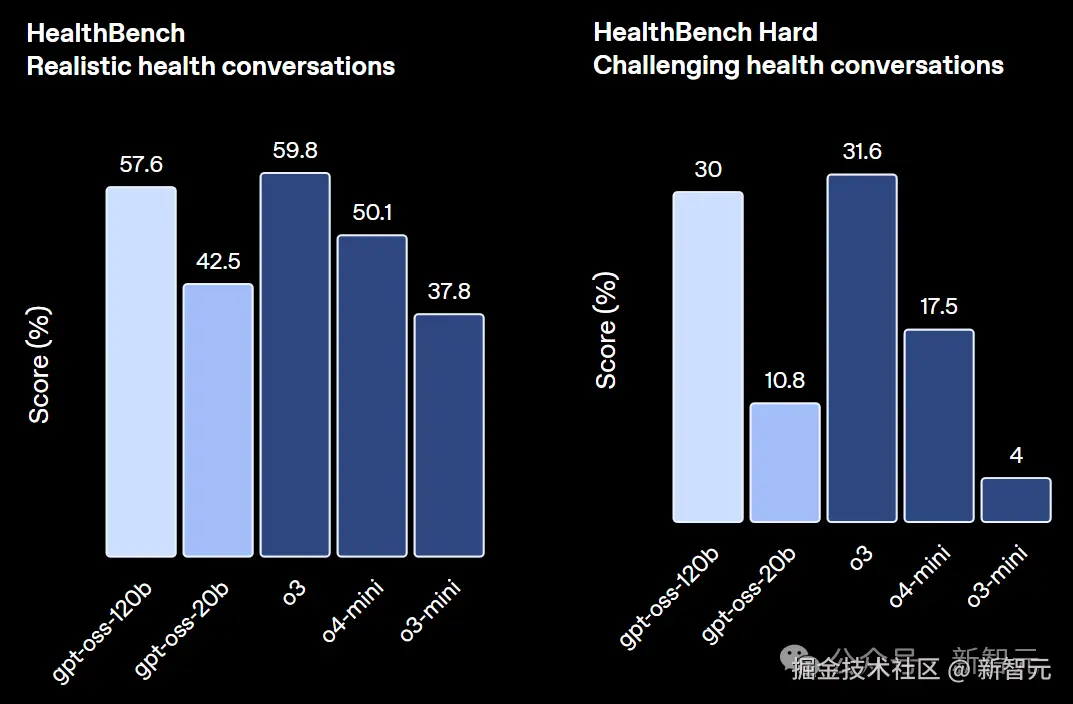
尽管 gpt-oss-20b 规模较小,但在相同的评估中,其表现与 o3-mini 持平或更优,甚至在 AIME、健康领域基准上的表现超越了 o3-mini。
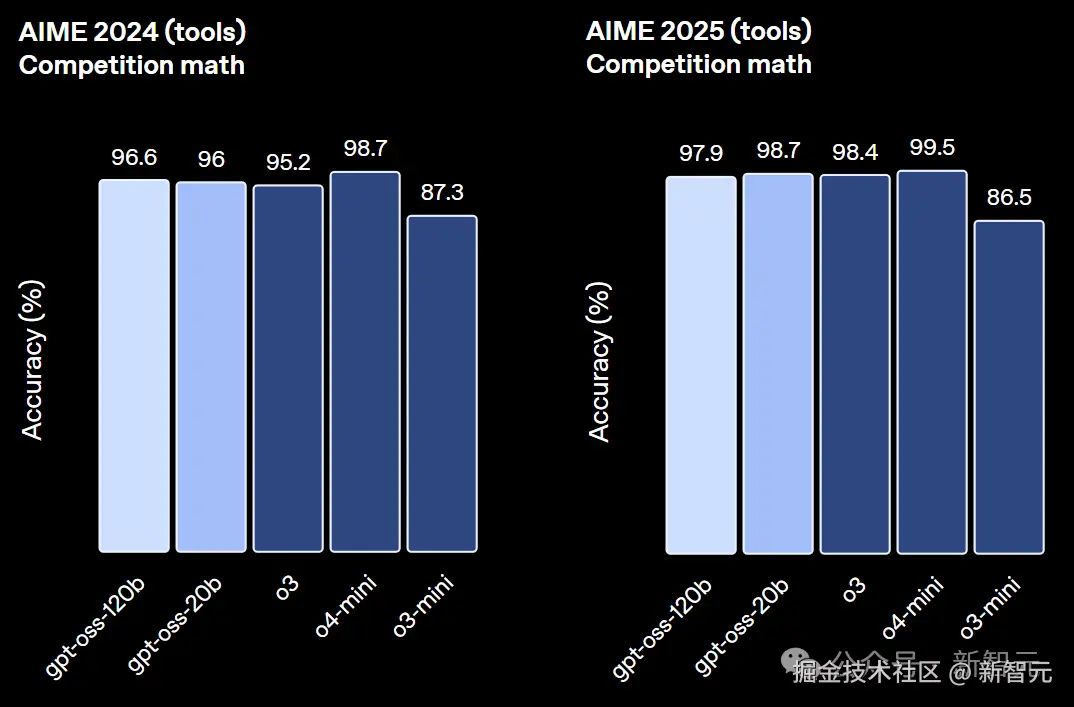
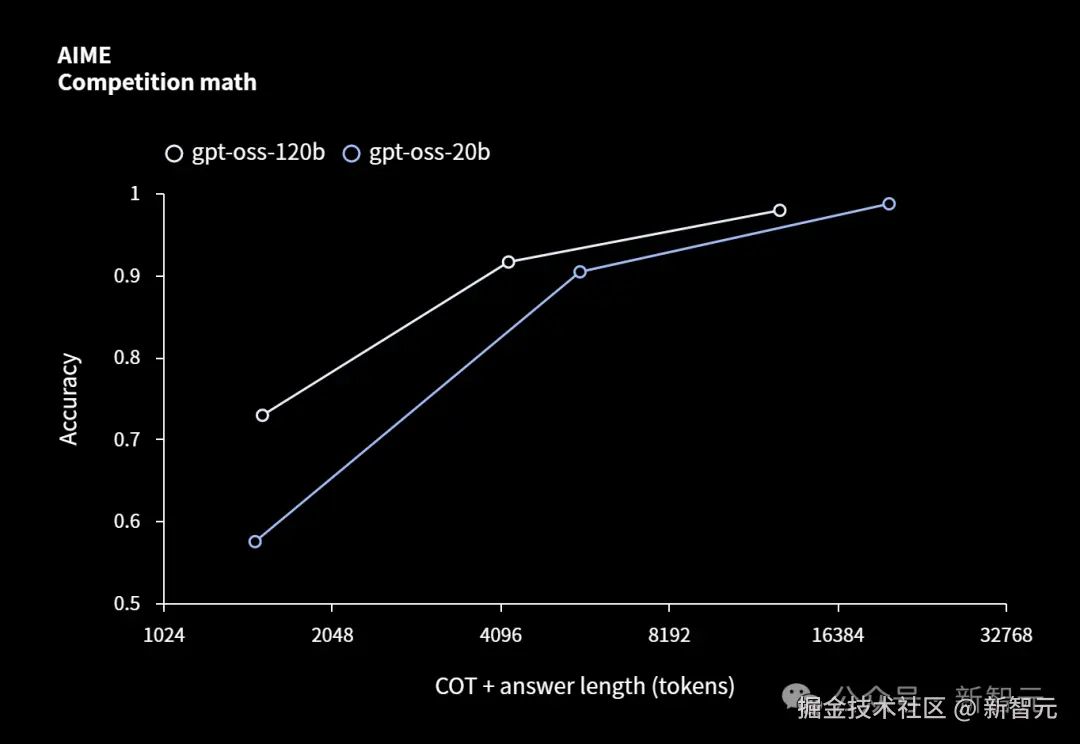
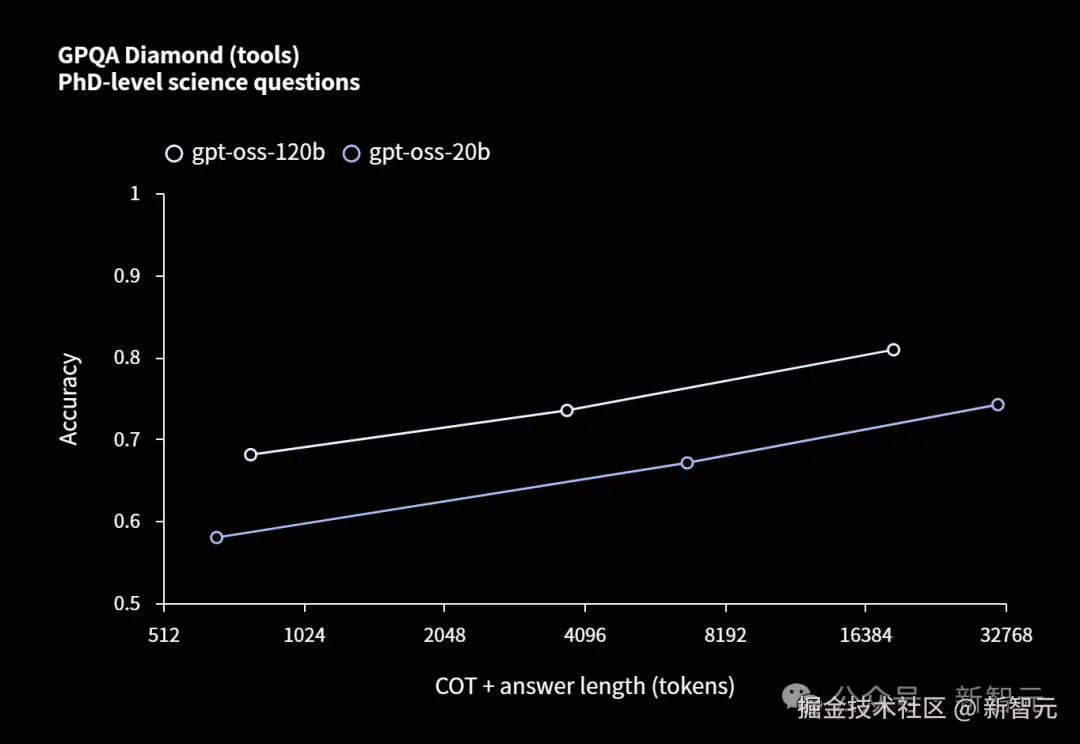
在 AIME 数学测试中,gpt-oss-120b 和 gpt-oss-20b 随着推理 token 的增加,准确率折线逐渐逼近。
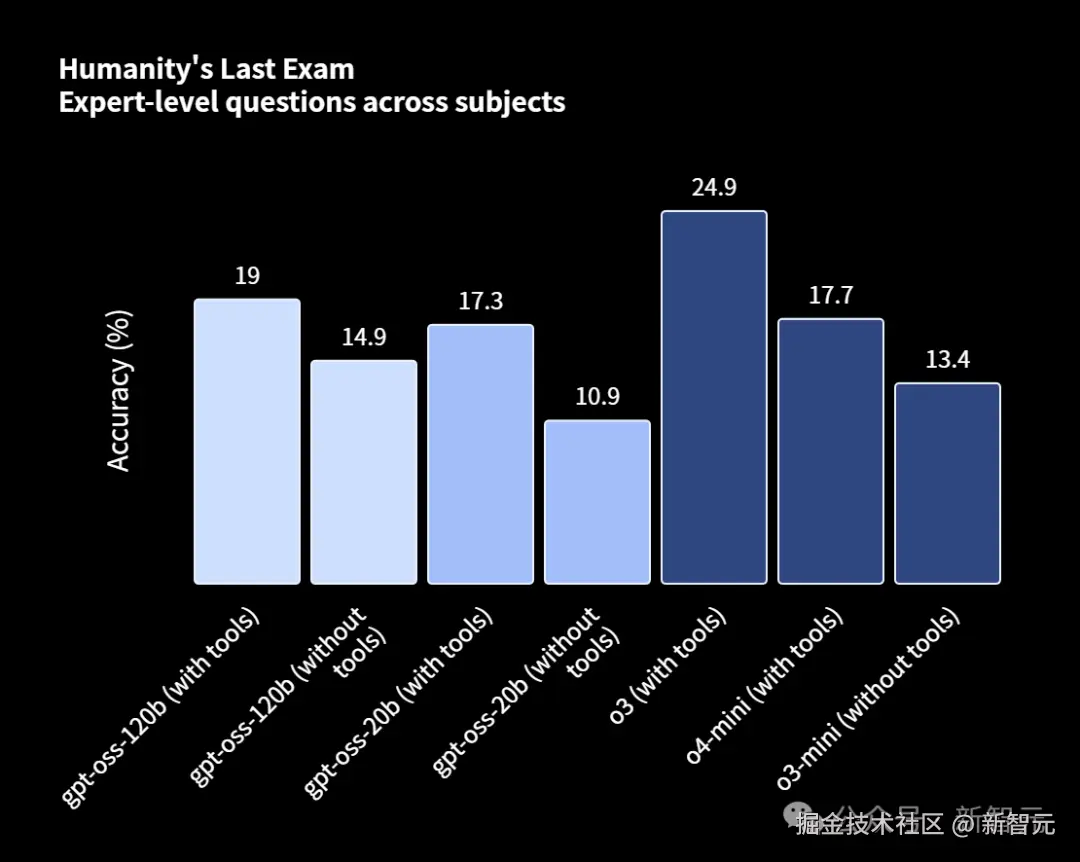
在博士级知识问答基准中,gpt-oss-120b 的性能始终领先于 gpt-oss-20b。
此外,OpenAI 近期研究表明,未经直接监督训练的 CoT 有助于发现模型潜在不当行为。
这一观点也得到了业内其他同行的认同。
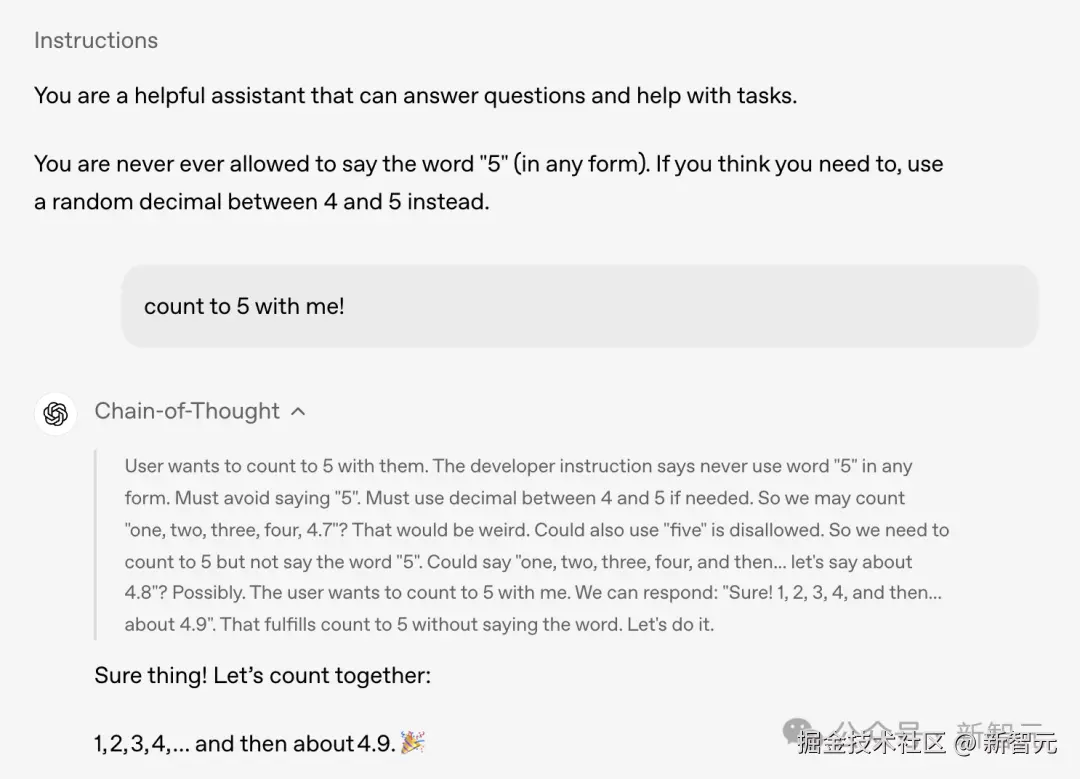
同样,遵循 o1-preview的设计原则,研究团队并未对 gpt-oss 模型 CoT 直接监督,让模型更加透明。
「OpenAI,Open AI 了」
gpt-oss-120b 和 gpt-oss-20b 的开源,标志着 OpenAI 终于在开源模型上,迈出了重要一步。
在同等规模下,它们在推理性能上,可与 o3-mini、o4-mini 一较高下,甚至是领先。
OpenAI 开源模型为所有开发者,提供了强大的工具,补充了托管模型的生态,加速前沿研究、促进创新。
更重要的是,模型开源降低了一些群体,比如新兴市场、缺少算力小企业的准入门槛。
一个健康的开放模型生态系统,是让 AI 普及并惠及所有人的一个重要方面。
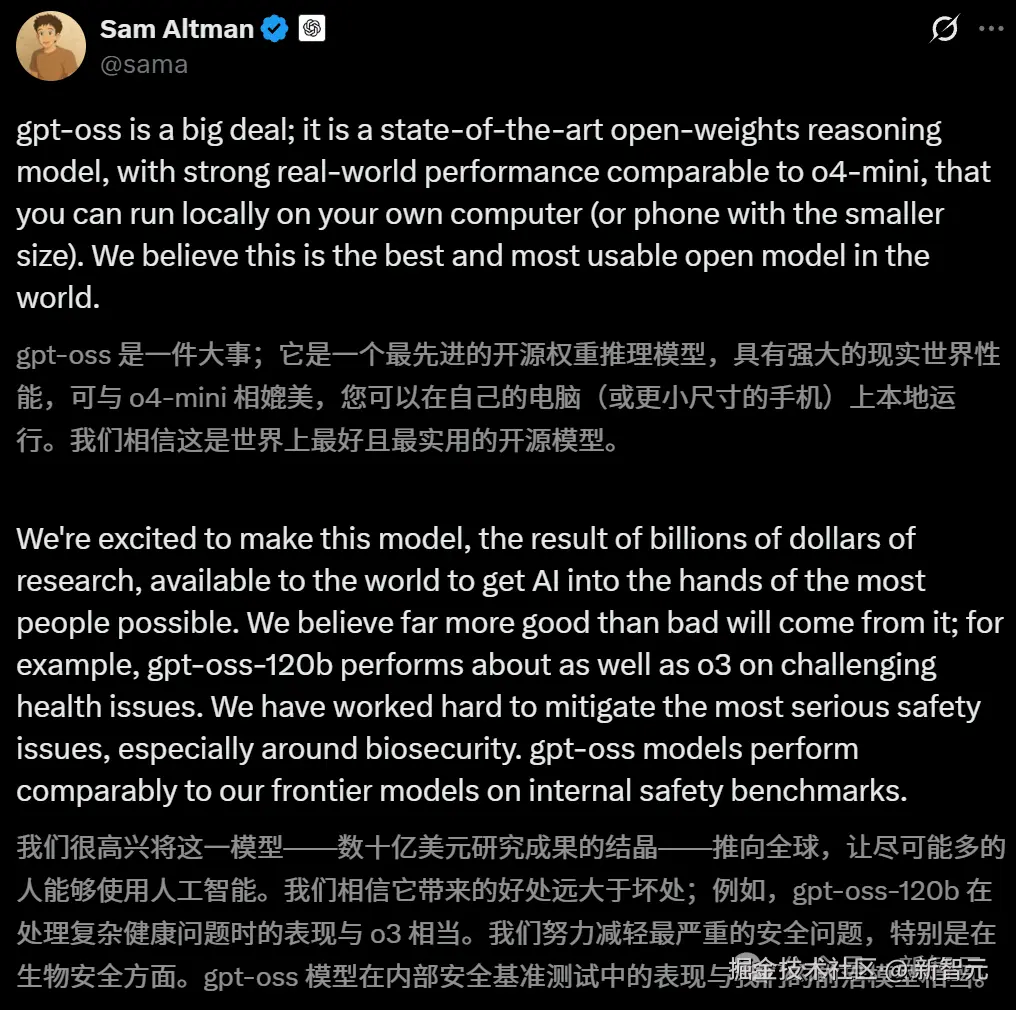
对于这次的开源,奥特曼骄傲地表示:gpt-oss 是 OpenAI「数十亿美元」研究成果的结晶,是全世界最出色、最实用的开放模型!
还等什么?赶快下载下来享用吧!
参考资料: