就是转换为数值类型方便机器学习模型处理
一、编码
这里举例将Survived这一行的数据转换为编码,原本是字符串类型
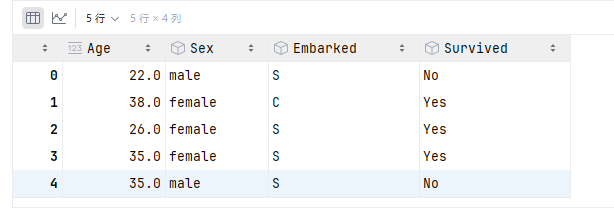
2、将标签编码并赋值回去
python
from sklearn.preprocessing import LabelEncoder
y = data.iloc[:, -1] # 最后一列拿出来
print(y)
le = LabelEncoder()
le = le.fit(y)
label_ = le.transform(y)
# label_ = le.fit_transform(y) # 上面两个可以合并成这个
# le.inverse_transform(label_) # 逆向编码,和fit_transform相反
data.iloc[:, -1] = label_ # 填回最后一列
# 那么多可以简写成这样:
# data.iloc[:, -1] = LabelEncoder().fit_transform(data[:, -1])
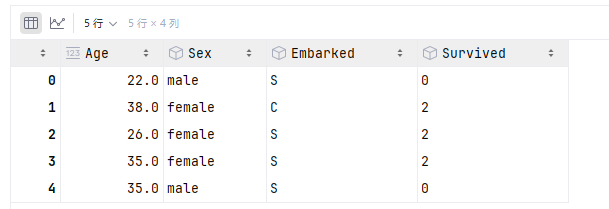
data.head()此时的Survived那一列变成了数字类型
二、哑变量
这里以Embarked那一列举例,它有三个值,这个时候就可以变成二进制的值来存储使用
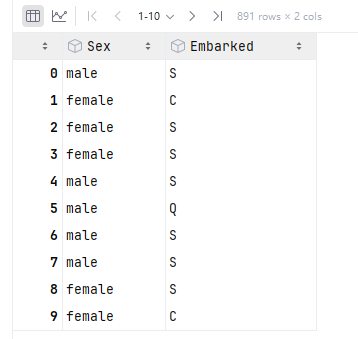
python
from sklearn.preprocessing import OneHotEncoder
X = data.iloc[:,1:-1]
enc = OneHotEncoder(categories='auto').fit(X)
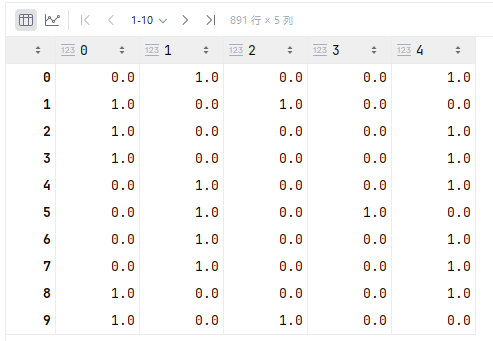
result = enc.transform(X).toarray() # 可以合并为:OneHotEncoder().fit(X).transform(X).toarray()
result0和1列是Sex的编码,其它的是Embarked的编码
三、二值化
原本年龄那一列是数值类型的,然后想要以30岁为界限进行分类
python
from sklearn.preprocessing import Binarizer
X = data_2.iloc[:, 0].values.reshape(-1,1) # 找到年龄那一列,并转换为二维数组
transformer = Binarizer(threshold=30).fit_transform(X)四、分段
将年龄按照段来分开
python
from sklearn.preprocessing import KBinsDiscretizer
X = data.iloc[:, 0].values.reshape(-1,1) # 取出Age那一列
est = KBinsDiscretizer(n_bins=3, encode='ordinal', strategy='uniform')
est.fit_transform(X)也可以不用整数形式显示,用哑变量
python
# 年龄分三段,哑变量进行显示,onehot控制
est = KBinsDiscretizer(n_bins=3, encode='onehot', strategy='uniform')
est.fit_transform(X).toarray()