 最近这两天。我整个人泡在 miniQMT 里。整得头晕眼花。 不过也有点小成果,嘿嘿。趁着还没忘干净,赶紧来和你们唠一唠。
最近这两天。我整个人泡在 miniQMT 里。整得头晕眼花。 不过也有点小成果,嘿嘿。趁着还没忘干净,赶紧来和你们唠一唠。
我打算把一些在量化会用到的,常用的方法整理成一个Python量化公共类 ,底层数据是通过xtquant+miniQMT获取的。整体还没写完,目前打算是写多少就先公开分享给大家,大家有什么需求但是我这里还没实现的也可以在评论区告诉花姐。
开始之前先说一个这几天调用xtquant遇到的问题:
我的量化环境用的是Python3.12、xtquant 250516版本
我们在获取行业、板块信息的时候,需要先通过download_sector_data下载板块分类信息,不然获取到的结果就为空,但是直接调用xtdata.download_sector_data()发现会卡死,等半天也没反映,粉丝群里好多小伙伴都遇到了这个问题,有人说回退到xtquant_241014 就可以了,于是我翻看了24版本的源码发现在download_sector_data时24 和25用的方法不一样!!!
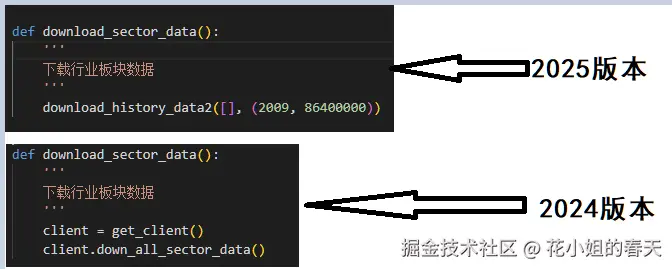
于是我把下载板块分类信息的方法改成了下面这个,没想到卡顿现象就消失了。
python
def down_load_sector():
'''
下载行业板块数据
'''
# 用这个方法代替xtdata.download_sector_data(),解决xtdata.download_sector_data()卡死的问题
client = xtdata.get_client()
client.down_all_sector_data()遇到问题有时候翻看下源码,也是很好的解决方案啊!
说了好多废话,开始步入正题:
上代码
今天主要分享的是获取股票列表,股票对应的申万1、2、3级行业还有股票对应的概念。 代码怎么用?
这些数据都是不经常变动的,做量化的小伙伴推荐每周更新一次即可,我这里是直接导出生成了csv文件,后期需要获取对应数据的时候直接读csv文件即可。有能力的小伙伴可以在这个基础上把数据存放到数据库,这才是最优解!
python
from xtquant import xtdata
import pandas as pd
def down_load_sector():
'''
下载行业板块数据
'''
# 用这个方法代替xtdata.download_sector_data(),解决xtdata.download_sector_data()卡死的问题
client = xtdata.get_client()
client.down_all_sector_data()
def get_stock_pool():
'''
获取股票池,返回全部A股的代码和对应的股票名称(没有北京的)
'''
stocks = xtdata.get_stock_list_in_sector("沪深A股")
info_list = xtdata.get_instrument_detail_list(stocks)
ret =[]
for stock in stocks:
name = info_list[stock]['InstrumentName']
ret.append({"stock":stock,"name":name})
df = pd.DataFrame(ret)
df = df.sort_values(by="stock")
df.to_csv("沪深A股股票池.csv",index=False)
return df
def get_sw1_industry():
'''
获取股票对应的申万一级行业
'''
down_load_sector()
sector_list = xtdata.get_sector_list()
sw1_list = [s for s in sector_list if s[:3].lower()=='sw1' and '加权' not in s] #获取申万一级行业
stocks = xtdata.get_stock_list_in_sector("沪深A股")
ret =[]
for sw1 in sw1_list:
s_list = xtdata.get_stock_list_in_sector(sw1)
for stock in stocks:
if stock in s_list:
ret.append({'stock':stock,'industry_sw1':sw1[3:]})
df = pd.DataFrame(ret)
df = df.sort_values(by="stock")
df.to_csv("沪深A股申万一级行业.csv",index=False)
return df
def get_sw2_industry():
'''
获取股票对应的申万二级行业
'''
down_load_sector()
sector_list = xtdata.get_sector_list()
sw2_list = [s for s in sector_list if s[:3].lower()=='sw2' and '加权' not in s] #获取申万二级行业
stocks = xtdata.get_stock_list_in_sector("沪深A股")
ret =[]
for sw2 in sw2_list:
s_list = xtdata.get_stock_list_in_sector(sw2)
for stock in stocks:
if stock in s_list:
ret.append({'stock':stock,'industry_sw2':sw2[3:]})
df = pd.DataFrame(ret)
df = df.sort_values(by="stock")
df.to_csv("沪深A股申万二级行业.csv",index=False)
return df
def get_sw3_industry():
'''
获取股票对应的申万三级行业
'''
down_load_sector()
sector_list = xtdata.get_sector_list()
sw3_list = [s for s in sector_list if s[:3].lower()=='sw3' and '加权' not in s] #获取申万三级行业
stocks = xtdata.get_stock_list_in_sector("沪深A股")
ret =[]
for sw3 in sw3_list:
s_list = xtdata.get_stock_list_in_sector(sw3)
for stock in stocks:
if stock in s_list:
ret.append({'stock':stock,'industry_sw3':sw3[3:]})
df = pd.DataFrame(ret)
df = df.sort_values(by="stock")
df.to_csv("沪深A股申万三级行业.csv",index=False)
return df
def get_gainian():
'''
获取股票对应的概念
'''
down_load_sector()
sector_list = xtdata.get_sector_list()
gn_list = [s for s in sector_list if s[:2].lower()=='gn'] #所有概念
stocks = xtdata.get_stock_list_in_sector("沪深A股")
ret =[]
for gn in gn_list:
s_list = xtdata.get_stock_list_in_sector(gn)
for stock in stocks:
if stock in s_list:
ret.append({'stock':stock,'gainian':gn[2:]})
df = pd.DataFrame(ret)
df = df.sort_values(by="stock")
df.to_csv("沪深A股所属概念.csv",index=False)
return df今天的文章就到这里了,我们明天见。