关注我的公众号:【编程朝花夕拾】,可获取首发内容。

01 引言
在Web应用、移动应用或数据分析场景中,数据库常常需要处理百万甚至千万级的数据记录。一次性加载所有数据不仅效率低下,还会消耗大量网络带宽和内存资源。数据库分页技术正是解决这一挑战的关键方案。
在日常开发中,对于列表页面的查询、全链路操作日志等,数据的结果集可以无限增大或者数据量本身很大的场景,我们常常会增加分页,以避免一次性全量加载带来的内存、IO的压力。
02 分页方式
为了测试需要,按照ID顺序插入了100万的数据。
下面是分页插件展示的效果:

2.1 LIMIT-OFFSET
脚本
sql
-- 获取第3页(每页10条)
select * from user_info order by id asc LIMIT 10 OFFSET 20;LIMIT后面跟的事查询的数据数量,而OFFSET后面跟的是数据偏移量,也就是要跳过的数据量。
结果
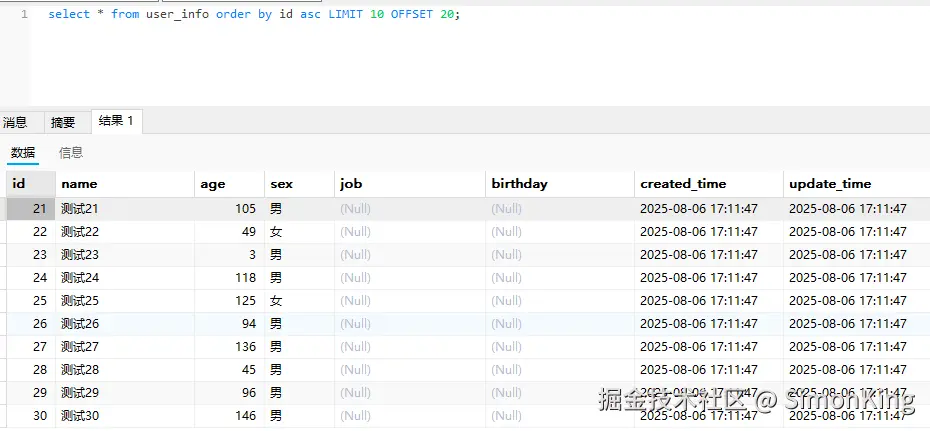
页数计算:
- 第一页:1~10
- 第二页:11~20
- 第三页:21~30
这种分页的方式,小编之前是不知道的,在查线上问题的时候偶然看到一段代码块,就好奇的点进去看了看:
才发现原来这样也可以分页,真的是涨知识了。
2.2 LIMIT X,Y
limit x,y 是小编常用的分页方式,x指偏移量,同offset。而y则指需要查询的数量。
脚本
sql
-- 获取第3页(每页10条)
select * from user_info order by id asc LIMIT 20, 10;结果
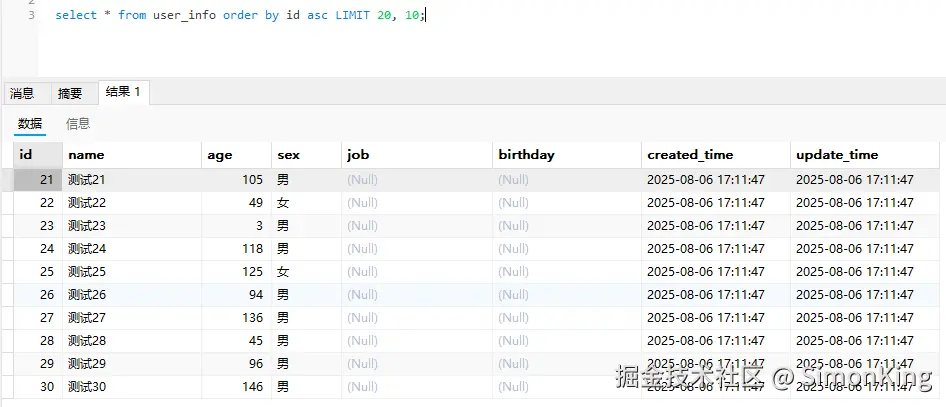
这种方式可能是习惯了,用起来感觉更加顺手。
03 分页使用注意事项
查询的结果的分页用起来比较简单,但是使用不当的话就会出现与期望偏差的数据。
3.1 语法
语法很简单,需要LIMIT关键字。
LIMIT ${偏移量},${要显示的记录数}LIMIT ${要显示的记录数} OFFEST ${偏移量}
两者任选其一。
3.2 执行顺序
分页一定是最后需要执行或者处理的,无论简单的脚本还是复杂的脚本都是在语句的结尾。
脚本
sql
-- 聚合查询
select age, count(*) from user_info GROUP BY age HAVING age > 30 ORDER BY age LIMIT 20, 10;结果
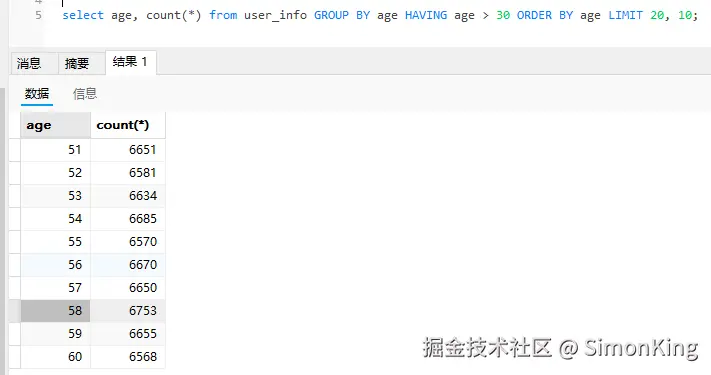
页数计算:
- 第一页:31~40
- 第二页:41~50
- 第三页:51~60
3.3 单条数据的查询
在业务代码中,我们如何查询一条数据呢?Mapper的查询结果中,返回的结果是一个数据集,要查询一条数据我们一般都是取集合中的第一条。
例如:我们需要再数据库中找到一个18岁的女孩。
脚本
sql
select * from user_info WHERE age=18 AND sex='女';结果
伪代码
java
List<UserInfo> userList = userInfoService.selectByAgeAndSex(18, "女");
return CollectionUtils.isNotEmpty(userList) ? userList.get(0) : null;乍一看代码似乎没有什么问题,结果是确实返回了一条。但是Mysql结果集有很多数据,需要加载到内存中甚至在微服务之间传输,这样的无疑增加了资源的消耗。
我们可以直接从数据库中只查一条数据就好了,没有必要都查出来。我们需要使用LIMIT的另一语法:
LIMIT 要返回的数据量【LIMIT 1:返回一条数据】
sql
select * from user_info WHERE age=18 AND sex='女' LIMIT 1;
3.4 深分页问题
深分页是一个无聊的话题,但是确实面试的一个考察点。
sql
select * from user_info LIMIT 800000,10;这已经翻了8w页了,还要继续翻么?这就是所谓的深分页。谁会这么干!
当然了,这样的查询语句的效率是低下的,测试的数据比较简单耗时大概1084ms。如何去优化呢?
主要原因是没有使用到覆盖索引,此时为了得到完整记录就需要回表,而回表是随机磁盘IO,速度慢消耗大。
解决办法就是减少回表次数:
sql
-- 根据ID自增特性
select * from user_info WHERE id > 800000 limit 10;
-- 自关联,减少回表次数
select * from user_info u INNER JOIN (select id from user_info LIMIT 800000,10) uu ON uu.id=u.id;从一定程度上可以提高响应速度,测试结果分别可以的达到758ms、915ms
04 分页公式
4.1 总页数计算
分页需要我们来计算。首先我们需要知道总共有多少数据(count),每页多少数据(length),这样我们才能知道能分多少页(total)。
java
// 总页数total的计算公式
int total = (int) Math.floor((this.count * 1.0d) / this.length);
if (this.count % this.length != 0) {
// 除不尽,需要页数+1
this.total++;
}注意:这里是Math.floor()向下取整,然后总记录数除不尽每页的数量,页数就是+1。
4.2 偏移量计算
偏移量的计算需要知道当前是多少页(current)了。
java
// 计算偏移量
int offset = (this.current - 1) * this.length;4.3 分页的使用
- 通过上面的公式自定义分页
- 使用第三方的分页,如
cn.hutool.db.PageResult
05 小结
我们习惯了三方库的分页,可能从来都没有自己去实现过分页或者封装都属于自己框架的分页,赶快去试试吧。