深度解析:大模型应用中的Stream流式输出技术------从原理到工程实践
本文较长,建议点赞收藏以免遗失。由于文章篇幅有限,更多源代码+课件+视频知识点,也可在主页自行查看。最新AI大模型应用开发学习系统最新AI大模型应用开发学习资料免费领取

引言:为什么需要流式输出?
在传统的大模型交互中,用户输入请求后需等待整个响应生成完毕才能看到结果。当响应内容较长(如长文本生成、多轮对话)时,这种阻塞式交互会导致:
- 用户等待焦虑:GPT-3生成500字需数秒,体验割裂
- 网络超时风险:HTTP长连接可能被代理服务器切断
- 资源浪费:服务器内存占用时间显著增加
流式输出(Streaming Output) 通过分块传输技术逐段返回结果,成为提升用户体验的关键解决方案。本文将深入解析其技术实现与优化策略。
一、核心技术原理
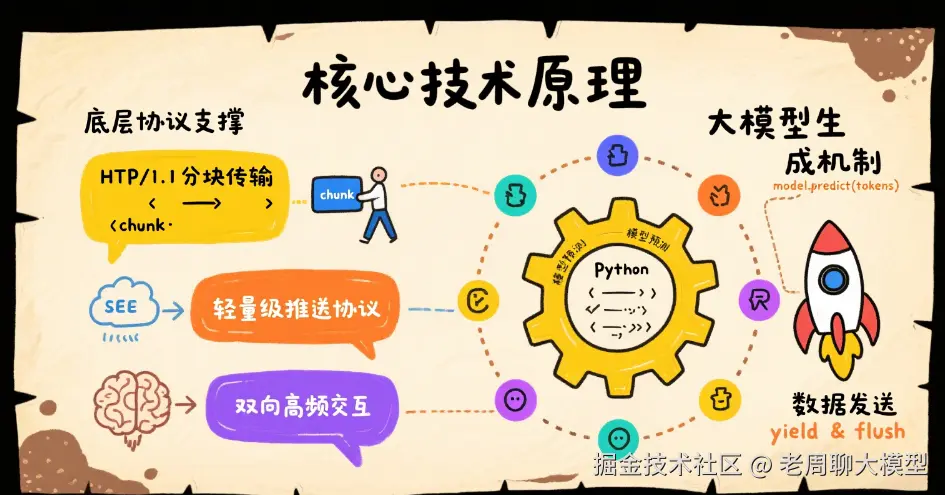
1.1 底层协议支撑
css
HTTP/1.1 200 OK
Transfer-Encoding: chunked
1a
{"data": "This is the first chunk"}
23
{"data": "and this is the second"}
0- Server-Sent Events (SSE) :基于HTTP的轻量级推送协议
- WebSocket:双向通信协议(适用于高频交互场景)
1.2 大模型生成机制
csharp
# 伪代码:流式生成的核心循环
def generate_stream():
tokens = []
while not is_generation_complete():
next_token = model.predict(tokens) # 预测下一个token
tokens.append(next_token)
yield format_token(next_token) # 转换为可传输格式
flush_buffer() # 立即发送网络缓冲区二、工程架构设计(以LLM API为例)
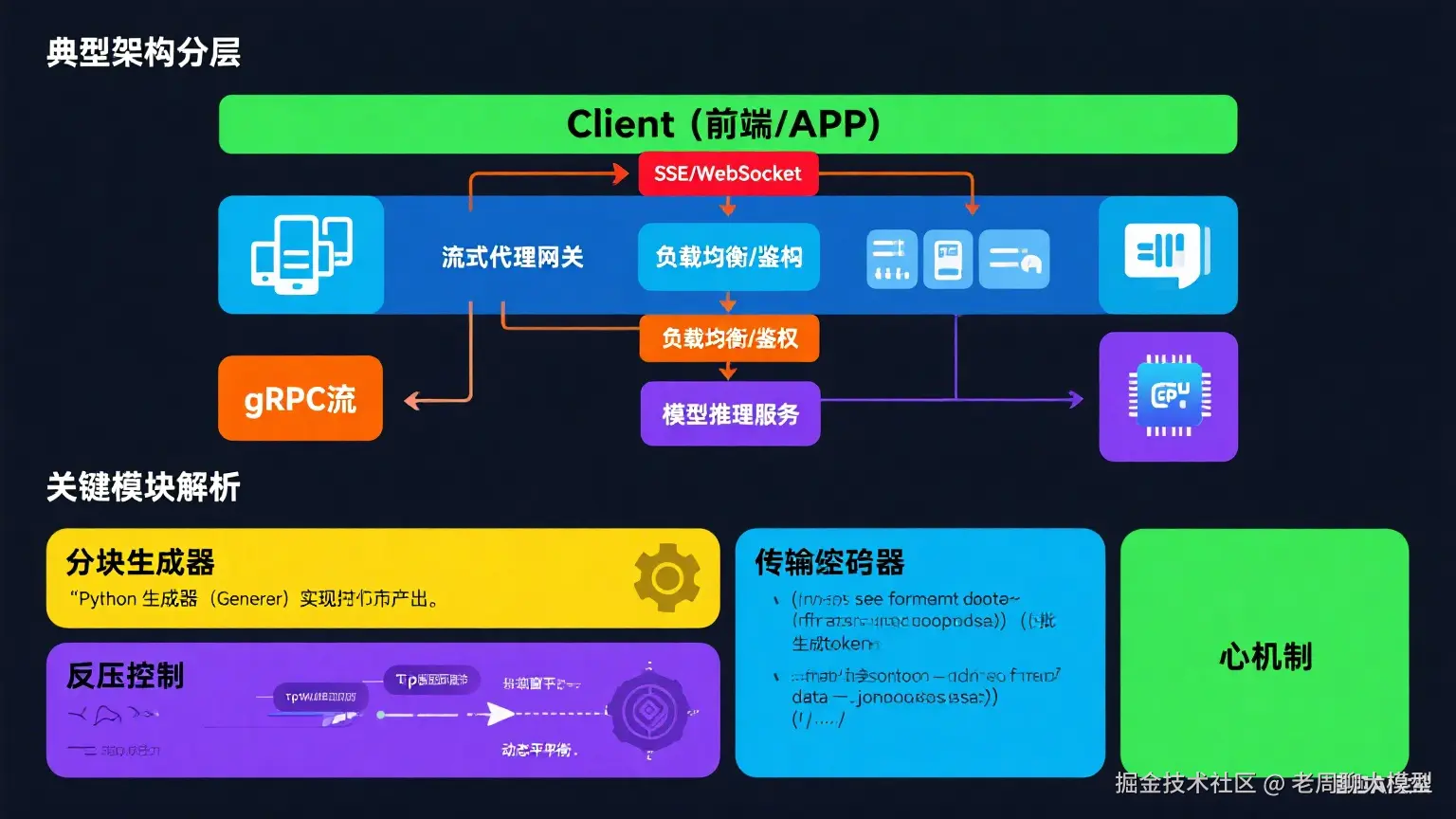
lua
2.1 典型架构分层+-----------------+
| Client (前端/APP) |
+--------+--------+
| SSE/WebSocket
+--------v--------+
| 流式代理网关 |
|(负载均衡/鉴权) |
+--------+--------+
| gRPC流
+--------v--------+
| 模型推理服务 |
|(分批生成token) |
+-----------------+2.2 关键模块解析
- 分块生成器:通过Python生成器(Generator)实现按token产出
- 传输编码器:将数据包转换为SSE格式:
python
def sse_format(data):
return f"data: {json.dumps(data)}\n\n"- 反压控制:通过TCP窗口大小动态调整生成速度
- 心跳机制:每15秒发送:\n\n防止连接断开
三、性能优化策略
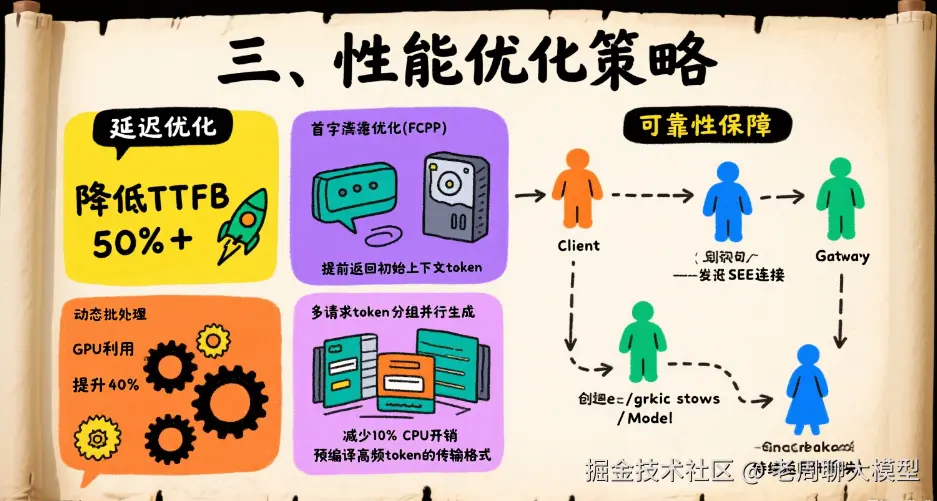
3.1 延迟优化
| 策略 | 效果 | 实现方式 |
|---|---|---|
| 首字节优化(FCP) | 降低TTFB 50%+ | 提前返回初始上下文token |
| 动态批处理 | GPU利用率提升40% | 多请求token分组并行生成 |
| 词表缓存复用 | 减少10% CPU开销 | 预编译高频token的传输格式 |
3.2 可靠性保障
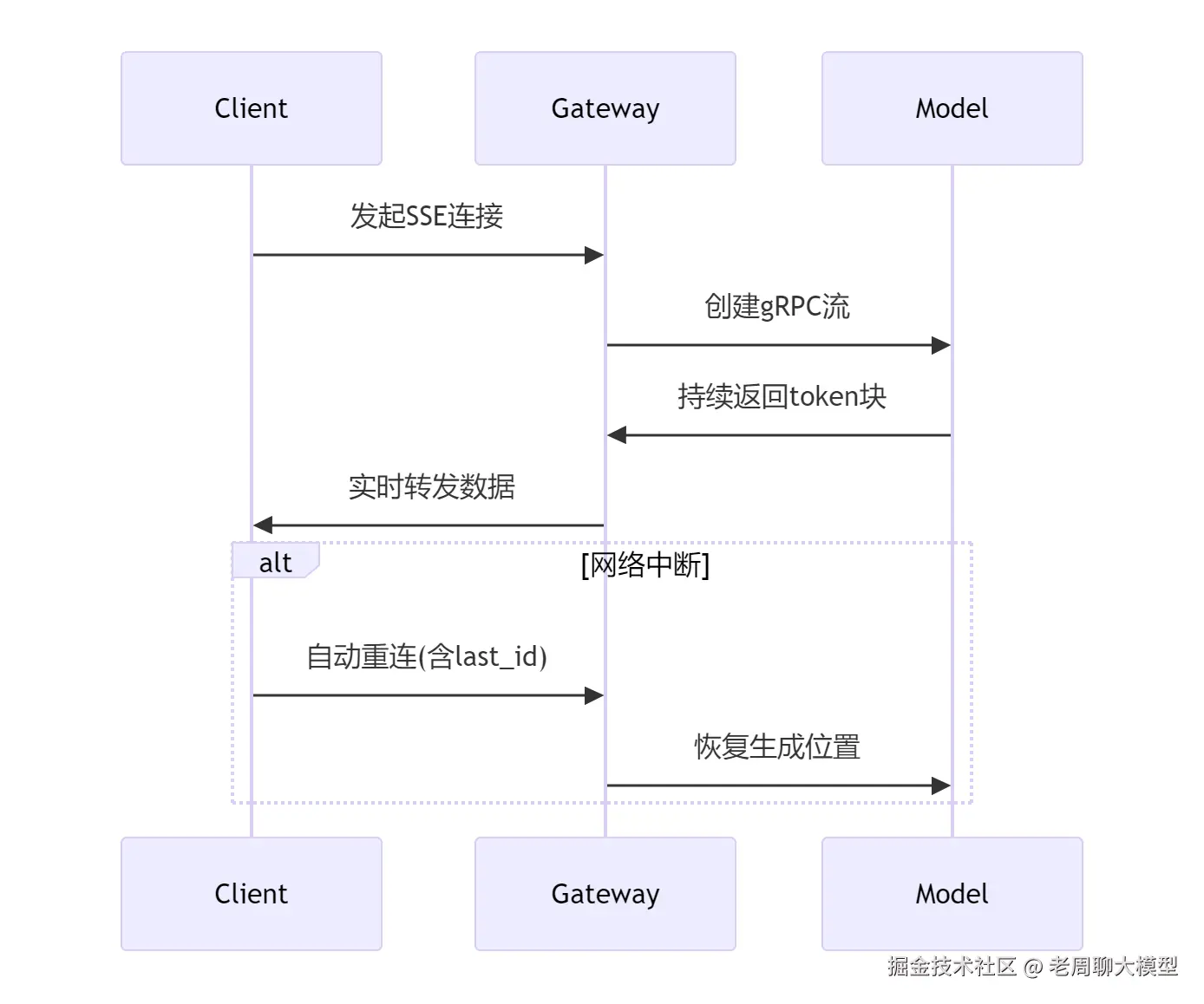
makefile
sequenceDiagram
Client->>Gateway: 发起SSE连接
Gateway->>Model: 创建gRPC流
Model->>Gateway: 持续返回token块
Gateway->>Client: 实时转发数据
alt 网络中断
Client->>Gateway: 自动重连(含last_id)
Gateway->>Model: 恢复生成位置
end四、主流框架实战
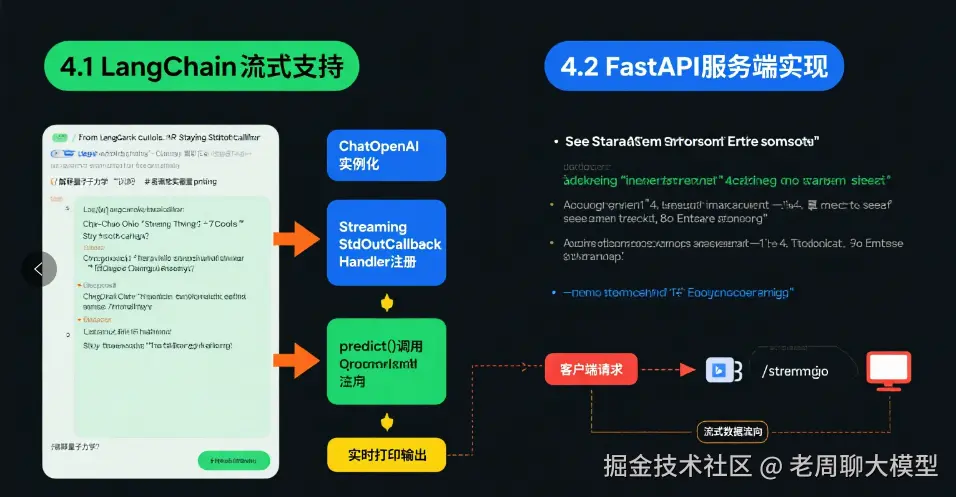
4.1 LangChain流式支持
ini
from langchain.callbacks import StreamingStdOutCallbackHandler
chat = ChatOpenAI(
streaming=True,
callbacks=[StreamingStdOutCallbackHandler()]
)
chat.predict("解释量子力学") # 结果实时打印4.2 FastAPI服务端实现
python
from sse_starlette import EventSourceResponse
@app.get('/stream')
async def message_stream():
async def generator():
while True:
yield sse_format(await get_next_token())
return EventSourceResponse(generator())五、特殊场景处理
5.1 结构化数据流
问题 :JSON需完整解析但生成过程是流式的
解决方案:增量JSON解析
json
// 分块传输方案
{"state": "partial", "data": "片段1"}
{"state": "partial", "data": "片段2"}
{"state": "complete", "data": "完整JSON"}5.2 多模态流处理
csharp
# 混合传输文本与图片token
def multi_modal_stream():
if content_type == "text":
yield text_token
else:
yield image_fragment_base64六、技术演进方向
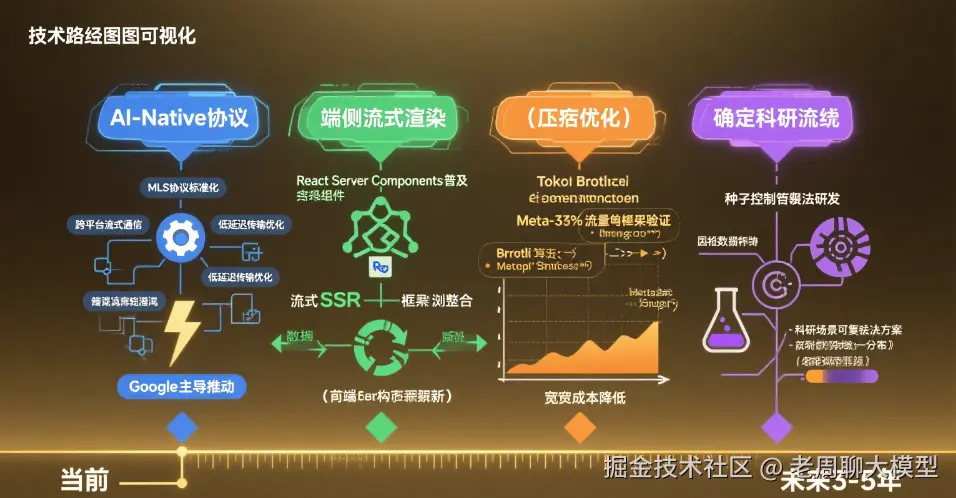
- AI-Native协议 :Google正在推动的MLS(Machine Learning Streaming)协议
- 端侧流式渲染:React Server Components与流式SSR深度整合
- 压缩优化:Token级别的Brotli动态压缩(Meta实测节省35%流量)
- 确定性流:通过种子控制实现可复现的流式输出(科研场景刚需)
结语
Stream流式输出已从性能优化的可选项演进为大模型应用的基础设施级能力。随着生成式AI向视频、3D等多模态扩展,对低延迟、高可靠流式传输的需求将持续升级。开发者需在协议选择、生成控制、错误恢复等层面精细设计,才能在复杂网络环境中提供丝滑流畅的AI交互体验。
技术箴言:"用户感知的延迟每降低100ms,转化率提升1%"------流式输出不仅是技术方案,更是用户体验的核心战场。