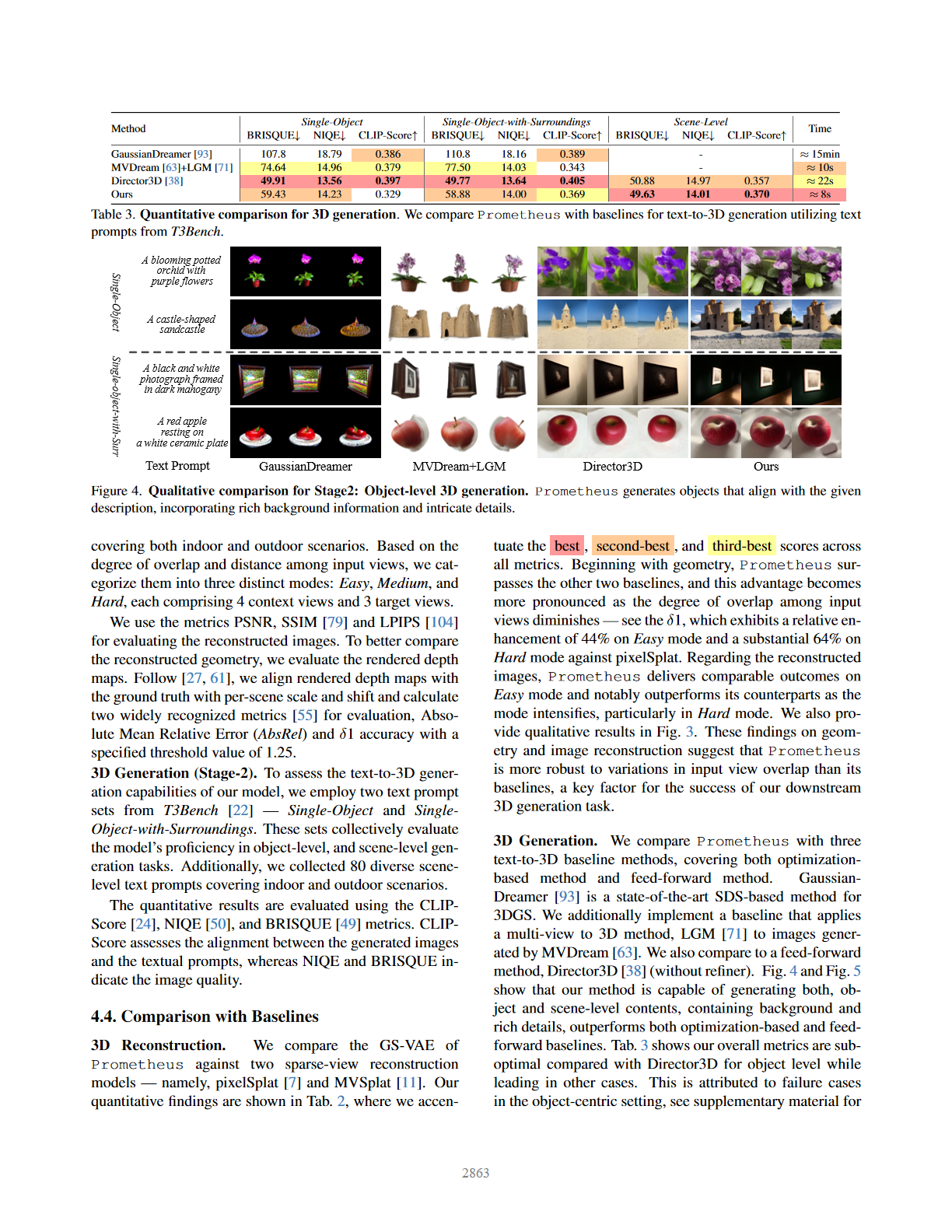
📄论文题目:Prometheus: 3D-Aware Latent Diffusion Models for Feed-Forward Text-to-3D Scene Generation
✍️作者及机构:Yuanbo Yang、Jiahao Shao、Xinyang Li、Yujun Shen、Andreas Geiger、Yiyi Liao(浙江大学、厦门大学、蚂蚁集团、University of T¨ubingen)
🧩面临问题:当前 3D 生成模型存在泛化能力有限、效率低下及质量问题。一方面,依赖 3D / 多视图数据或单一类别单视图图像的模型泛化能力弱,因训练数据稀缺;另一方面,利用 2D 数据的方法多通过优化生成 3D 表示,过程耗时,且因 2D 模型缺乏 3D 完整理解,易出现多视图不一致(Janus 问题)和保真度低的情况2。

🎯创新点及其具体研究方法:
1️⃣ 前馈式 3D 高斯生成框架:将 3D 场景生成表述为潜在扩散范式下的多视图、前馈、像素对齐 3D 高斯生成,实现无需迭代优化的直接生成,大幅提升效率,使 3D 场景生成时间缩短至秒级13。
2️⃣ RGB-D 潜空间引入:在 3D 高斯生成中引入 RGB-D 潜空间,分离外观和几何信息。通过预训练的 Stable Diffusion 编码器分别编码 RGB 图像和深度图, concatenate 得到联合潜空间,助力生成具有更高保真度和更优几何结构的 3D 高斯46。
3️⃣ 两阶段训练策略:第一阶段训练 3D 高斯变分自编码器(GS-VAE),以多视图或单视图 RGB-D 图像为输入,预测像素对齐 3D 高斯,编码器复用 Stable Diffusion 编码器,解码器基于其修改;第二阶段训练多视图潜扩散模型(MV-LDM),结合文本提示和相机姿态,联合预测多视图 RGB-D 潜码,且在 9 个多视图和单视图数据集上训练以增强泛化性578。
4️⃣ 混合采样与 CFG-rescale 策略:采用混合采样 guidance,通过文本和姿态引导权重平衡多视图一致性与保真度;同时使用 CFG-rescale 避免条件采样中的过饱和问题,提升生成质量9。
#论文 #3D 生成 #计算机视觉 #深度学习 #文本到 3D #潜在扩散模型 #前馈式生成