前言
之前,接到一个需求,大致情况是这样的:需要将我们原有项目中某个步骤处理的数据写到另外一张表(新数据源)里面。这个需求咋一听是不是有点莫名奇妙❓
需求本身没啥,特殊的是待写入的表会每天自动生成。如同下面这样:
| 日期 | 表名 |
|---|---|
| 2025/07/01 | xxx_20250701 |
| 2025/07/02 | xxx_20250702 |
就算是这样,这个需求也没啥大不了的。刚入门的同学,只会 JDBC,也能解决这个问题。但不巧的是,我们的项目中使用的是 Mybatis,并且要求保持这种代码风格。啥意思?
也就是说,必须将 SQL 语句写在 mapper 文件里面。这种动态的 SQL 怎么写到 mapper 文件里面?
问题分析
Mybatis 是支持动态表名替换的。可以通过 ${} 的方式实现动态替换,例如:
xml
<select id="query" resultMap="queryMap">
select * from ${table}
</select>但这种方式有两个比较严重的问题:
- 存在 SQL 注入的风险
- 计算表名的逻辑耦合到了业务代码里面
因此,这种方案通常是不被允许的。只要敢写,轻松喜提一个安全漏洞,然后负责安全的同学就会找过来。
其实,除了上面这种方式,Mybatis 还提供了插件机制,这种方式可以相对安全的实现表名替换,并且替换逻辑不会耦合到业务代码中。
到这里,似乎一切都已迎刃而解。可是,稍加思索一会儿,会发现这种方式并不是最优解。
理由一:下次又接到类似的需求,但表名替换逻辑不同,难道自己需要再写一个插件吗?
理由二:今天在 A 公司用 Mybatis,下次在 B 公司用 JPA,类似问题如何解决?
单看理由一和理由二都不是问题,但当这两个理由结合到一起考虑,就会发现这个问题并没有真正的解决。当对该问题做进一步抽象,此时会发现:这是一个特殊的分库分表场景(只包含分表,而且是按时间分,并且没有传统意义上的分片键)。
解决方案
ORM(Mybatis) 与数据源(Druid)的关系是:ORM 层依赖数据源。
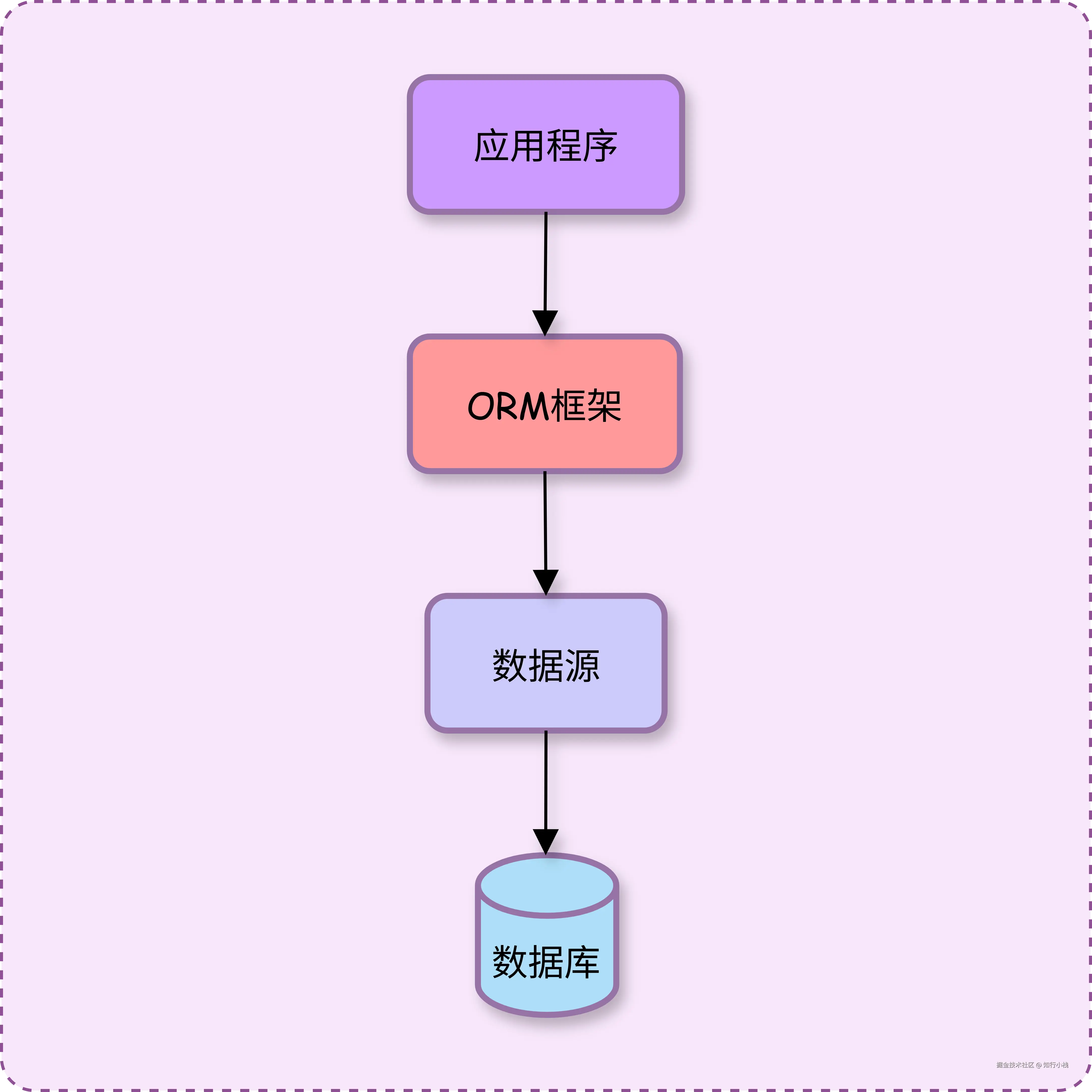
想不入侵 ORM 层和数据源,要做的就是在这中间加一个代理层,这样就会形成:ORM 层依赖数据源代理层,数据源代理层依赖真实的数据源。
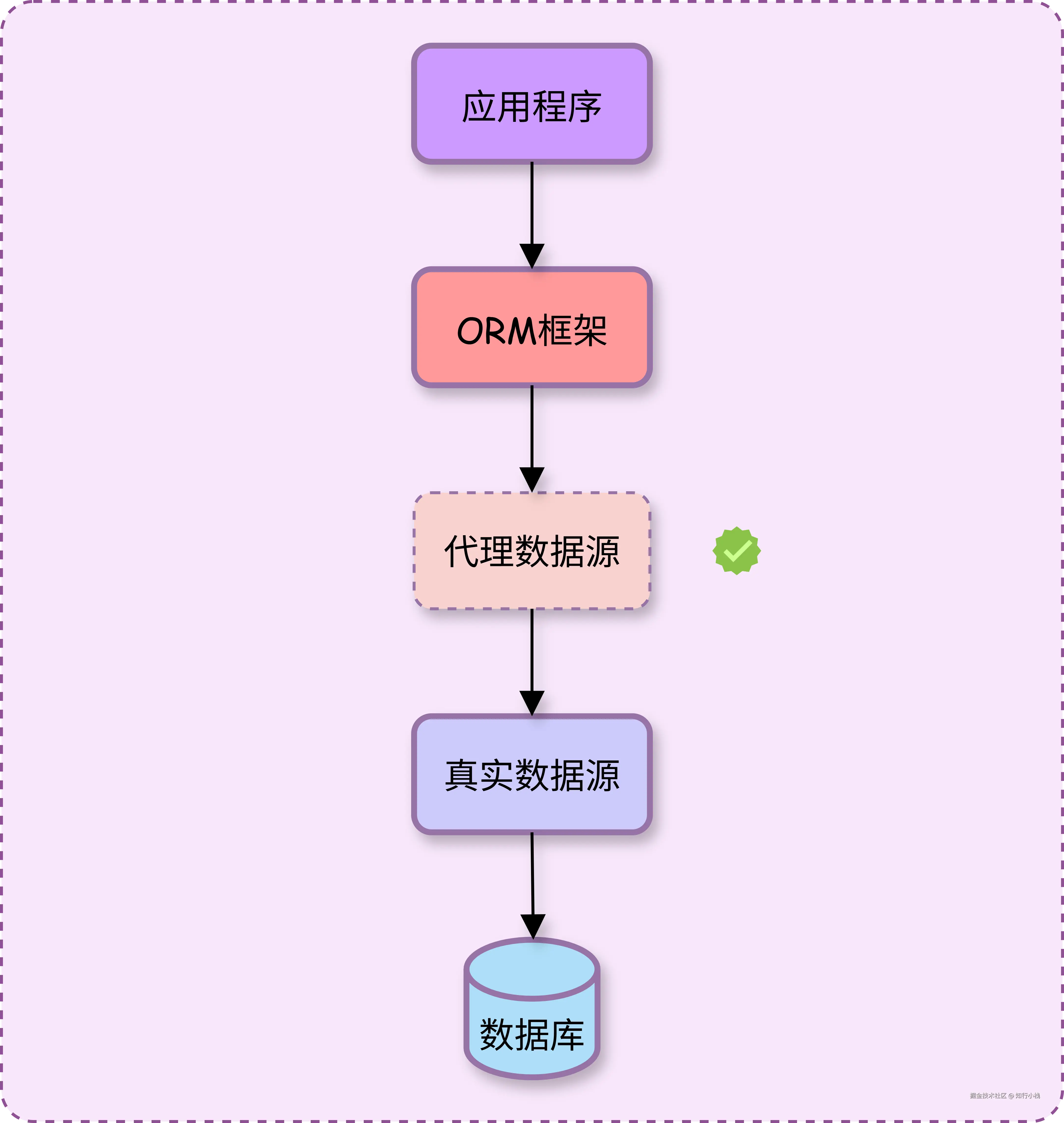
这样,将表名改写的逻辑放在数据源代理层,就可以实现表名改写。同时,不会侵入业务代码,也不用考虑使用的何种 ORM 层工具以及数据源。
为了数据源代理层(接下来简称 DSProxy)有一定的扩展性和灵活性,可以将策略以及SQL重写的逻辑拆出来。
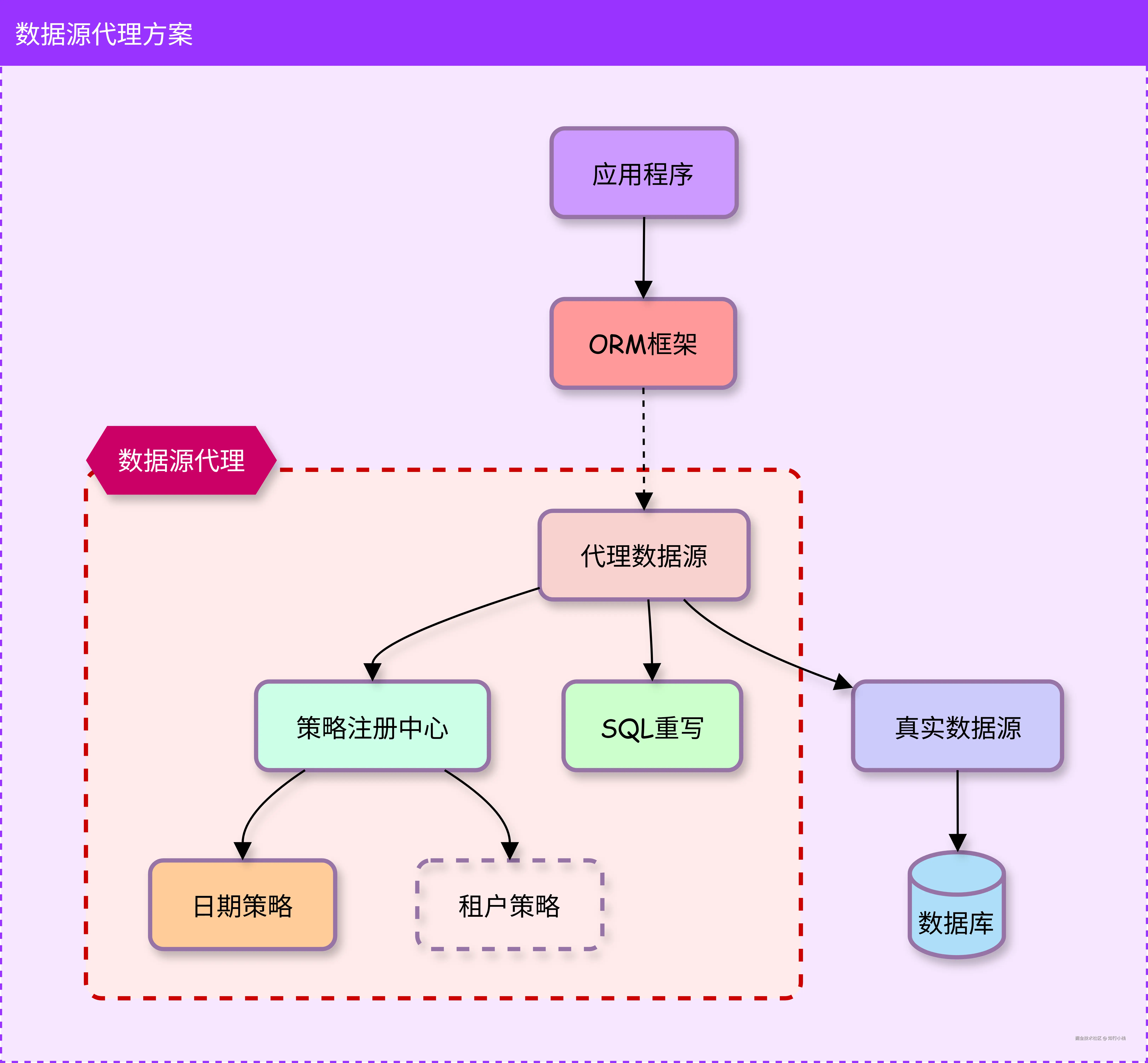
这样一来,当有 SQL 语句到达 DSProxy 时,DSProxy 会通过 SQL 重写模块来重写 SQL。具体的重写逻辑来源于相应的策略。
今后,无论是 ORM 层变化了,还是数据源变化了,这个方案都可以处理。甚至,还可以延展更多的业务场景。比如,我们经常会遇到多数据源场景,也可以在数据源代理层选择最终路由的数据源,从而避免依赖于上下游技术。
具体实现
数据源代理是核心部件。代理数据源有许多方式,使用静态代理、JDK动态代理还是第三方代理库都行。为了方便,就直接使用 JDK 动态代理了。
java
public final class DataSourceProxy implements InvocationHandler {
/**
* 目标数据源
*/
private final DataSource targetDataSource;
private DataSourceProxy(DataSource target) {
this.targetDataSource = target;
}
/**
* 创建一个代理的DataSource实例
*
* @param target 目标DataSource
* @return 代理后的DataSource实例
*/
public static DataSource create(DataSource target) {
return (DataSource) Proxy.newProxyInstance(
target.getClass().getClassLoader(),
new Class[]{DataSource.class},
new DataSourceProxy(target)
);
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
if ("getConnection".equals(method.getName())) {
Connection conn = getConnection(method, args);
return proxyConnection(conn);
}
return method.invoke(targetDataSource, args);
}
/**
* 获取连接的方法
* <p>
* 根据方法参数的不同,调用不同的getConnection重载方法
*
* @param method 被调用的方法
* @param args 方法参数
* @return 代理的Connection对象
* @throws SQLException 如果获取连接失败
*/
private Connection getConnection(Method method, Object[] args) throws SQLException {
if (args == null || args.length == 0) {
return targetDataSource.getConnection();
} else if (args.length == 2) {
return targetDataSource.getConnection(
(String) args[0], (String) args[1]
);
}
throw new SQLException("Unsupported getConnection method");
}
/**
* 创建代理连接
*
* @param conn 原始Connection对象
* @return 代理后的Connection对象
*/
private Connection proxyConnection(Connection conn) {
return (Connection) Proxy.newProxyInstance(
conn.getClass().getClassLoader(),
new Class[]{Connection.class},
new ConnectionHandler(conn)
);
}
}接下来,架设 Mybatis(ORM) 与 Druid(数据源)的桥梁
java
/**
* 创建代理数据源的 Bean
*
* @return 代理数据源
*/
@Bean
public DataSource dataSourceProxy(@Qualifier("druidDataSource") DataSource ds) {
return DataSourceProxy.create(ds);
}
/**
* 创建 SqlSessionFactory 的 Bean
*
* @param ds 代理数据源
* @return SqlSessionFactory 实例
* @throws Exception 如果创建 SqlSessionFactory 失败
*/
@Bean
public SqlSessionFactory sqlSessionFactory(@Qualifier("dataSourceProxy") DataSource ds) throws Exception {
SqlSessionFactoryBean factoryBean = new SqlSessionFactoryBean();
factoryBean.setDataSource(ds);
factoryBean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources("classpath:mapper/*.xml"));
return factoryBean.getObject();
}然后,实现一个 SQL 重写组件,能够按策略,对原始 SQL 进行重写。
java
@Slf4j
public class SqlRewriter {
/**
* 正则表达式模式,用于匹配 SQL 语句中的表名
* <p>
* 该模式匹配 FROM、JOIN、UPDATE 或 INTO 后的表名,考虑可能的模式前缀(如 schema.table)
*/
private static final Pattern TABLE_PATTERN = Pattern.compile(
"\\b(?:FROM|JOIN|UPDATE|INTO)\\s+(?:(?:\\w+|`\\w+`)\\.)?([\\w$]+|`[\\w$]+`)",
Pattern.CASE_INSENSITIVE | Pattern.MULTILINE
);
/**
* 重写 SQL 语句中的表名
*
* @param sql 原始 SQL 语句
* @return 重写后的 SQL 语句
*/
public static String rewriteSql(String sql) {
StringBuffer sb = new StringBuffer();
Matcher matcher = TABLE_PATTERN.matcher(sql);
TableRewriteStrategyRegistry registry = TableRewriteStrategyRegistry.getInstance();
while (matcher.find()) {
String tableName = matcher.group(1);
TableRewriteStrategy strategy = registry.getStrategy(tableName);
if (strategy != null) {
// 使用策略重写表名
String rewrittenTableName = strategy.rewriteTable(tableName);
matcher.appendReplacement(sb, matcher.group(0).replace(tableName, rewrittenTableName));
} else {
// 如果没有找到对应的策略,保持原样
matcher.appendReplacement(sb, matcher.group(0));
}
}
matcher.appendTail(sb);
log.debug("==> Rewritten: {}", sb.toString().replaceAll("\\s+", " ").trim());
return sb.toString();
}
}最后,实现一个按日期规则重写的策略
java
public class DailyTableStrategy implements TableRewriteStrategy {
/**
* 表名集合
*/
private final Set<String> tableNames;
public DailyTableStrategy() {
this.tableNames = new HashSet<>();
// 添加需要支持的表名
tableNames.add("tbl_order");
}
@Override
public boolean support(String tableName) {
for (String name : tableNames) {
if (name.equalsIgnoreCase(tableName)) {
return true;
}
}
return false;
}
@Override
public String rewriteTable(String tableName) {
LocalDate now = LocalDate.now();
// 获取yyyyMMdd格式的日期字符串
String dateSuffix = now.toString().replace("-", "");
return tableName + "_" + dateSuffix;
}
}在 mapper 文件中正常编写 SQL 语句:
XML
<select id="selectOrderById" resultMap="selectOrderByIdMap">
select * from tbl_order where id = #{id}
</select>验证效果:

知行有话
今天的分享就到这儿啦。如果大家有更好的方案,欢迎留言~