什么是MCP?为什么要用它?
想象一下,你有一个非常聪明的AI助手(比如Claude),但它就像被关在一个透明的玻璃房子里------能看到外面的世界,却无法直接操作你电脑上的文件。这就是传统AI的限制。
Model Context Protocol (MCP) 就像是给AI助手开了一扇门,让它能够安全地帮你处理各种文件操作。简单来说:
- 没有MCP时:你只能跟AI聊天,需要文件操作时还得自己动手
- 有了MCP后:AI可以直接帮你压缩图片、整理文件、处理PDF等等
MCP的核心优势:
- 安全可控:AI只能做你允许的操作
- 标准统一:不同的工具都遵循同一套规则
- 功能强大:可以扩展AI的能力边界
- 高效便捷:一句话搞定复杂的文件操作
这个MCP服务器能做什么?file-operation-mcp源码
这个文件操作MCP服务器就像是给AI配备了一个万能的文件管理工具箱,包含10大核心功能:
基础文件管理
- 文件统计 - 快速统计文件夹里有多少个文件
- 文件列表 - 查看文件夹里的所有文件详情
图片处理
- 图片压缩 - 减小图片文件大小,支持JPEG、PNG等格式
文件压缩解压
- 文件压缩 - 打包文件为ZIP、TAR等格式
- 文件解压 - 解压各种压缩包
文件操作
- 文件复制 - 复制文件到指定位置
- 文件移动 - 移动文件到新位置
PDF处理
- PDF合并 - 把多个PDF合成一个
- PDF拆分 - 把一个PDF分成多个
- PDF转图片 - 把PDF页面转换成图片
技术实现原理
核心技术栈解析
1. Sharp - 图片处理的瑞士军刀
typescript
// Sharp是如何工作的?
const image = sharp(imagePath); // 读取图片
const compressed = image
.resize(1920, 1080) // 调整尺寸
.jpeg({ quality: 80 }) // 设置压缩质量
.toFile(outputPath); // 保存文件2. PDF-lib - PDF操作专家
typescript
// 合并PDF的原理
const mergedPdf = await PDFDocument.create(); // 创建新PDF
const pdf1 = await PDFDocument.load(file1); // 加载第一个PDF
const pdf2 = await PDFDocument.load(file2); // 加载第二个PDF
// 复制页面到新PDF
const pages1 = await mergedPdf.copyPages(pdf1, pdf1.getPageIndices());
const pages2 = await mergedPdf.copyPages(pdf2, pdf2.getPageIndices());
// 添加所有页面
pages1.forEach(page => mergedPdf.addPage(page));
pages2.forEach(page => mergedPdf.addPage(page));两种连接方式
Stdio方式 - 直接对话模式
typescript
// 就像面对面交流
const transport = new StdioServerTransport();
await server.connect(transport);特点:
- ✅ 速度极快(1-5毫秒响应)
- ✅ 资源占用少
- ❌ 只能本地使用
- ❌ 不支持多用户
适用场景:个人电脑上的日常文件操作
SSE方式 - 网络服务模式
typescript
// 就像通过网络视频通话
const app = express();
app.get('/sse', async (req, res) => {
const transport = new SSEServerTransport('/messages', res);
await server.connect(transport);
});特点:
- ✅ 支持远程访问
- ✅ 支持多用户
- ✅ 便于调试和监控
- ❌ 延迟稍高(10-50毫秒)
- ❌ 需要额外配置
适用场景:团队协作或需要远程访问的情况
核心功能实现原理
1. 图片压缩功能
图片压缩就像是给照片"减肥",保持美观的同时减小文件大小:
typescript
// 完整的压缩流程
async function compressImage(imagePath: string, options: CompressOptions) {
// 第1步:检查文件是否存在
if (!await fs.pathExists(imagePath)) {
throw new Error('文件不存在');
}
// 第2步:验证是否为支持的图片格式
const validFormats = ['.jpg', '.jpeg', '.png', '.webp'];
const extension = path.extname(imagePath).toLowerCase();
if (!validFormats.includes(extension)) {
throw new Error('不支持的图片格式');
}
// 第3步:使用Sharp处理图片
let processor = sharp(imagePath);
// 第4步:调整尺寸(如果指定了最大宽高)
if (options.maxWidth || options.maxHeight) {
processor = processor.resize(options.maxWidth, options.maxHeight, {
fit: 'inside', // 保持比例
withoutEnlargement: true // 不放大图片
});
}
// 第5步:根据格式应用压缩
switch (extension) {
case '.jpg':
case '.jpeg':
processor = processor.jpeg({ quality: options.quality });
break;
case '.png':
// PNG使用压缩级别而不是质量
const level = Math.round((100 - options.quality) / 10);
processor = processor.png({ compressionLevel: level });
break;
}
// 第6步:保存压缩后的文件
await processor.toFile(outputPath);
// 第7步:返回压缩统计信息
const originalSize = (await fs.stat(imagePath)).size;
const compressedSize = (await fs.stat(outputPath)).size;
const savedPercentage = ((originalSize - compressedSize) / originalSize * 100).toFixed(1);
return `压缩完成!原大小: ${Math.round(originalSize/1024)}KB,压缩后: ${Math.round(compressedSize/1024)}KB,节省了${savedPercentage}%`;
}2. PDF处理功能实现
PDF合并原理
typescript
// PDF合并就像把多本书装订成一本
async function mergePDFs(inputPaths: string[], outputPath: string) {
// 创建一个新的空白PDF文档
const mergedPdf = await PDFDocument.create();
// 逐个处理每个输入PDF
for (const inputPath of inputPaths) {
// 读取PDF文件内容
const pdfBytes = await fs.readFile(inputPath);
// 解析PDF文档
const pdf = await PDFDocument.load(pdfBytes);
// 获取所有页面
const pageIndices = pdf.getPageIndices(); // [0, 1, 2, ...]
// 复制页面到新PDF
const copiedPages = await mergedPdf.copyPages(pdf, pageIndices);
// 将复制的页面添加到合并PDF中
copiedPages.forEach((page) => mergedPdf.addPage(page));
}
// 保存合并后的PDF
const finalPdfBytes = await mergedPdf.save();
await fs.writeFile(outputPath, finalPdfBytes);
}PDF拆分原理
typescript
// PDF拆分就像把一本书撕成单页
async function splitPDF(inputPath: string, outputDir: string) {
// 读取原始PDF
const pdfBytes = await fs.readFile(inputPath);
const pdf = await PDFDocument.load(pdfBytes);
const totalPages = pdf.getPageCount();
// 为每一页创建一个新PDF
for (let i = 0; i < totalPages; i++) {
// 创建新的PDF文档
const newPdf = await PDFDocument.create();
// 复制指定页面
const [copiedPage] = await newPdf.copyPages(pdf, [i]);
// 添加页面到新PDF
newPdf.addPage(copiedPage);
// 保存单页PDF
const newPdfBytes = await newPdf.save();
const outputPath = path.join(outputDir, `page_${i + 1}.pdf`);
await fs.writeFile(outputPath, newPdfBytes);
}
}3. 文件压缩解压实现
ZIP压缩原理
typescript
// 压缩就像把东西装进行李箱
async function createZip(files: string[], outputPath: string) {
// 创建压缩器
const archive = archiver('zip', { zlib: { level: 9 } });
// 创建输出流
const output = fs.createWriteStream(outputPath);
// 连接压缩器和输出流
archive.pipe(output);
// 添加文件到压缩包
for (const filePath of files) {
const stats = await fs.stat(filePath);
if (stats.isDirectory()) {
// 如果是文件夹,递归添加所有内容
archive.directory(filePath, path.basename(filePath));
} else {
// 如果是文件,直接添加
archive.file(filePath, { name: path.basename(filePath) });
}
}
// 完成压缩
await archive.finalize();
}4. 参数验证机制
使用Zod进行参数验证,就像是在门口检查身份证:
typescript
// 定义参数规则
const compressImageSchema = {
imagePath: z.string().describe('图片文件路径'),
quality: z.number()
.min(1, '质量不能小于1')
.max(100, '质量不能大于100')
.optional()
.describe('压缩质量 (1-100)'),
maxWidth: z.number()
.positive('宽度必须为正数')
.optional()
.describe('最大宽度'),
maxHeight: z.number()
.positive('高度必须为正数')
.optional()
.describe('最大高度')
};
// 在工具执行前自动验证
server.registerTool('compress-image', {
inputSchema: compressImageSchema
}, async (params) => {
// 这里的params已经通过验证,类型安全
// 可以放心使用
});5. 错误处理策略
采用多层防护,就像给程序穿上多层防护服:
typescript
async function safeOperation(operation: () => Promise<any>) {
try {
// 第1层:参数验证(Zod自动处理)
// 第2层:前置条件检查
if (!await fs.pathExists(inputPath)) {
throw new Error('文件不存在');
}
// 第3层:权限检查
await fs.access(inputPath, fs.constants.R_OK);
// 第4层:业务逻辑执行
const result = await operation();
// 第5层:结果验证
if (!result) {
throw new Error('操作未产生预期结果');
}
return {
content: [{ type: 'text', text: `操作成功:${result}` }]
};
} catch (error) {
// 统一错误处理
return {
content: [{
type: 'text',
text: `操作失败:${error instanceof Error ? error.message : '未知错误'}`
}],
isError: true
};
}
}安装和配置指南
环境准备
bash
# 1. 确保Node.js版本 >= 18
node --version
# 2. 克隆项目
git clone https://github.com/lxKylin/file-operation-mcp.git
cd file-operation-mcp
# 3. 安装依赖
pnpm install
# 4. 构建项目
pnpm buildClaude Desktop配置
找到配置文件:
- macOS :
~/Library/Application Support/Claude/claude_desktop_config.json - Windows :
%APPDATA%/Claude/claude_desktop_config.json
添加配置:
json
{
"mcpServers": {
"file-operation-mcp": {
"command": "node",
"args": ["/完整路径/file-operation-mcp/dist/index.js"],
"cwd": "/完整路径/file-operation-mcp"
}
}
}重要提醒 :一定要把
/完整路径/替换成你实际的项目路径!
Cursor 配置SSE

json
{
"mcpServers": {
"file-operation-mcp": {
"type": "sse",
"url": "http://localhost:3000/sse"
}
}
}实际使用示例
日常文件管理
erlang
用户:帮我看看桌面上有什么文件
AI:好的,我来帮你查看桌面文件...
[调用 list-files 工具]
结果:桌面上有15个文件,包括3个PDF、5张图片、2个文档...
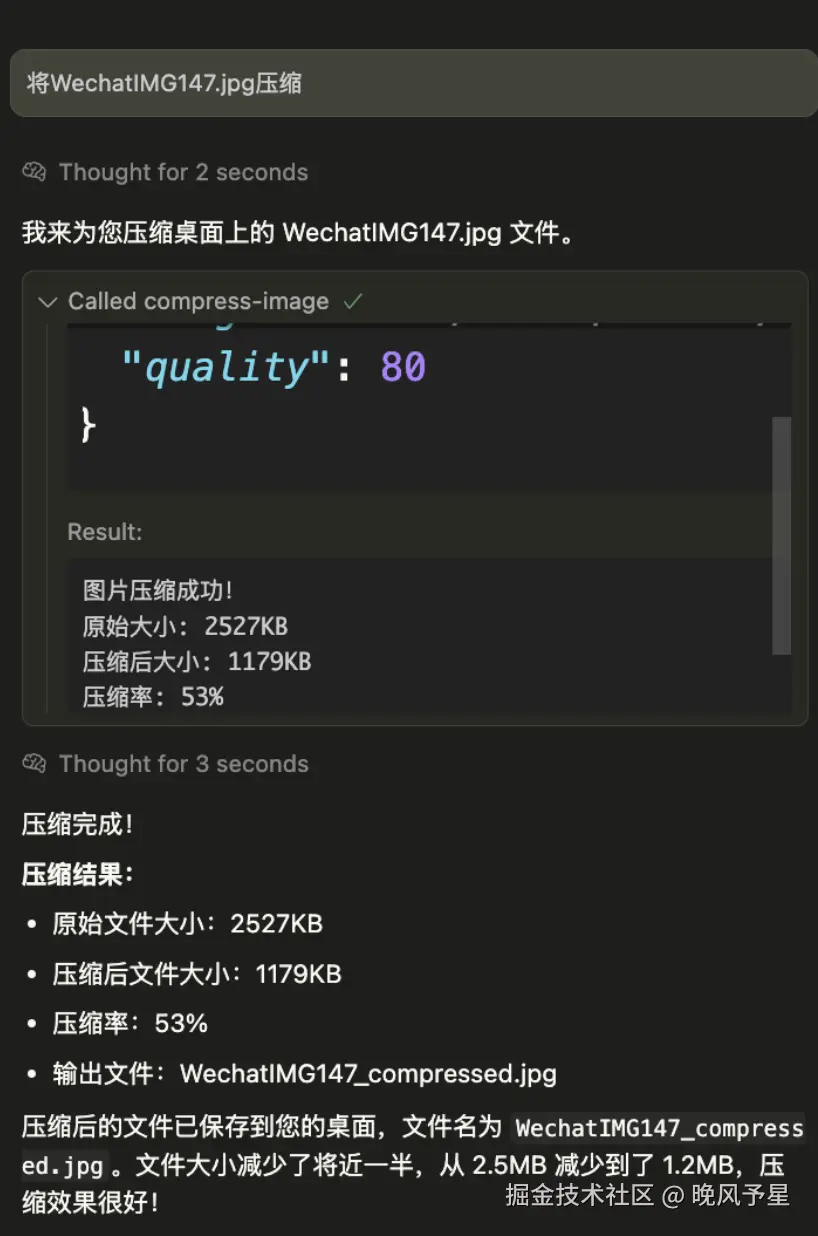
用户:把那些图片都压缩一下
AI:我来帮你压缩图片...
[调用 compress-image 工具处理每张图片]
结果:已成功压缩5张图片,总共节省了2.3MB空间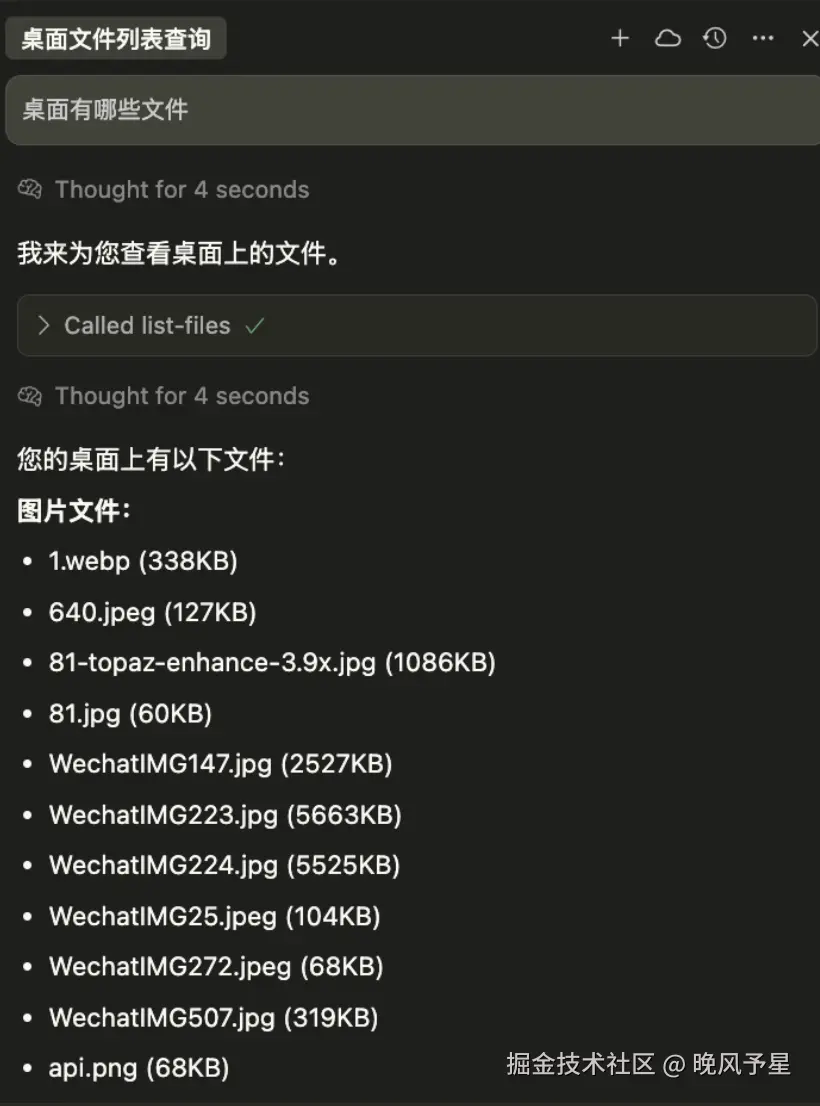
文档整理场景
erlang
用户:把项目文档文件夹里的所有PDF合并成一个
AI:我来帮你合并PDF文档...
[调用 merge-pdf 工具]
结果:已将12个PDF文件合并为"项目完整文档.pdf",共186页
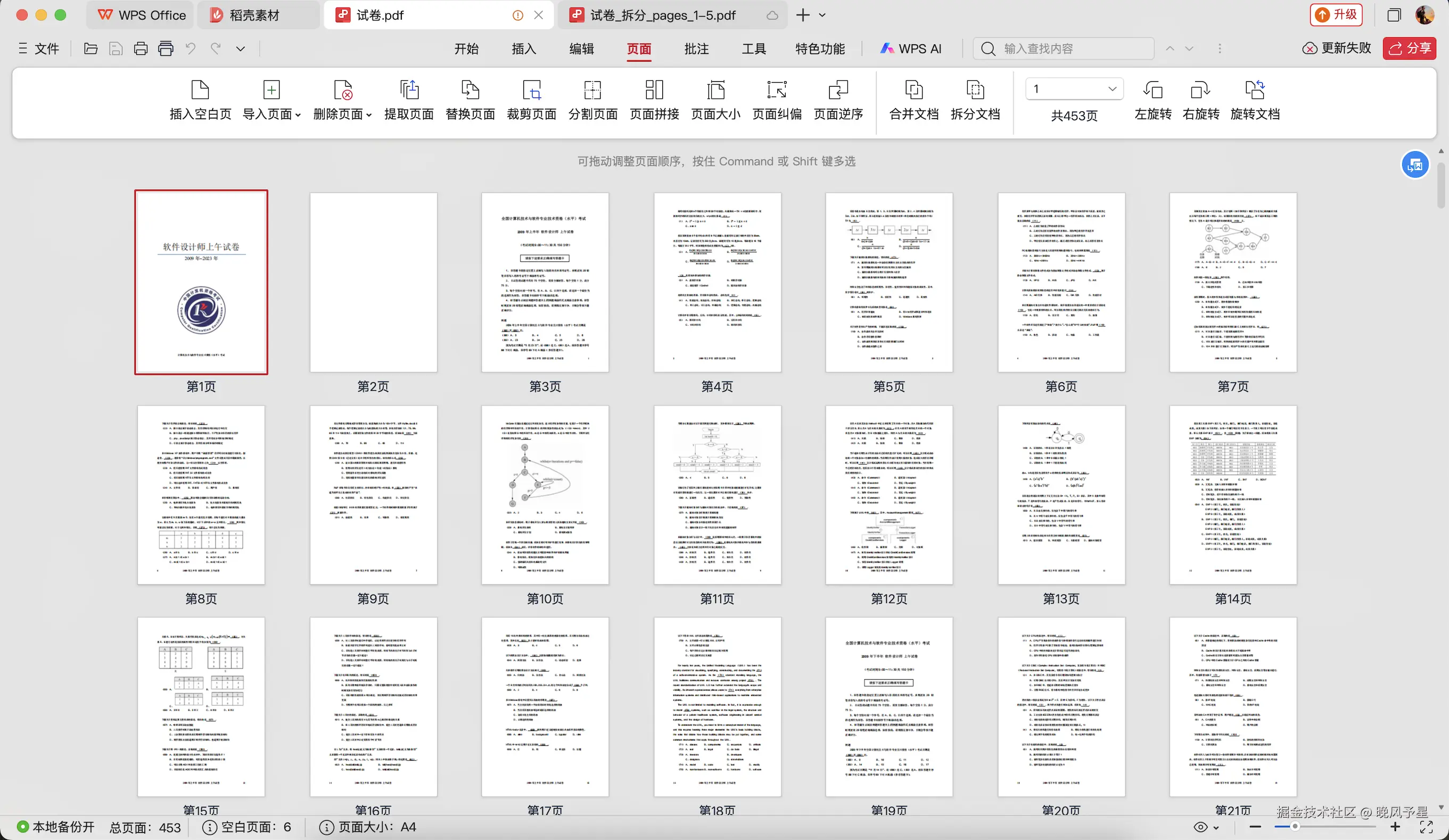
用户:再把这个大PDF按章节拆分
AI:我来按页面范围拆分PDF...
[调用 split-pdf 工具,按ranges模式]
结果:已拆分为6个章节文件,每个章节包含20-40页拆分前:
拆分后:
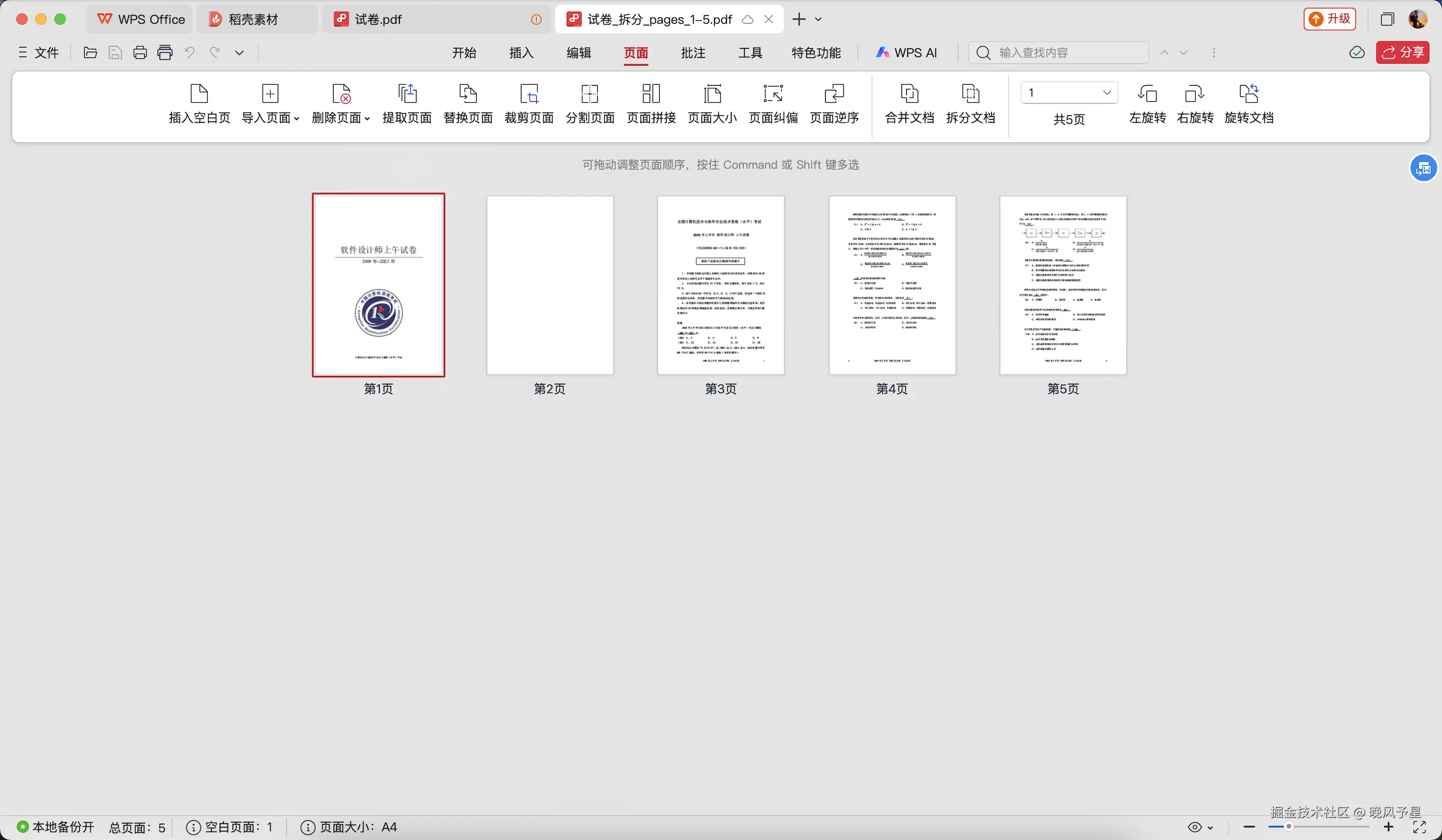
批量文件处理
css
用户:把下载文件夹里的所有图片压缩到50%质量,然后打包
AI:我来执行批量处理...
[先调用 list-files 找到所有图片]
[然后调用 compress-image 压缩每张图片]
[最后调用 create-archive 打包所有压缩图片]
结果:已处理23张图片,压缩后总大小减少65%,打包为compressed_images.zip使用场景和最佳实践
个人用户场景
- 桌面整理:快速统计和分类桌面文件
- 照片管理:批量压缩旅游照片节省空间
- 文档处理:合并扫描的PDF文档
- 备份压缩:定期打包重要文件
扩展和定制
添加新功能
typescript
// 1. 创建新工具文件
// src/tools/my-new-tool.ts
import type { McpServer } from '@modelcontextprotocol/sdk/server/mcp.js';
import { z } from 'zod';
const registerTool = (server: McpServer) => {
server.registerTool(
'my-new-tool',
{
title: '我的新工具',
description: '工具描述',
inputSchema: {
// 参数定义
}
},
async (params) => {
// 工具逻辑
}
);
};
export default registerTool;
// 2. 在index.ts中注册
import myNewTool from './my-new-tool';
// 添加到工具列表中自定义配置
typescript
// 环境变量配置
const config = {
maxFileSize: process.env.MAX_FILE_SIZE || '100MB',
defaultQuality: parseInt(process.env.DEFAULT_QUALITY || '80'),
tempDir: process.env.TEMP_DIR || os.tmpdir()
};总结
这个MCP文件操作服务器就像是给AI助手装上了一双巧手,让它能够帮你处理各种文件操作任务。从简单的文件统计到复杂的PDF处理,从图片压缩到文档合并,一句话就能搞定。
核心价值:
- 效率提升:复杂的文件操作变成简单对话
- 安全可靠:完善的错误处理和权限控制
- 功能全面:覆盖日常文件操作的方方面面
- 易于扩展:模块化设计,可以轻松添加新功能
通过这个MCP服务器,你的AI助手不再只是一个聊天机器人,而是一个真正能帮你干活的数字助理。文件管理从此变得简单而高效!