以铜为镜,可以正衣冠;以古为镜,可以知兴替;以人为镜,可以明得失。那以AI为镜呢?
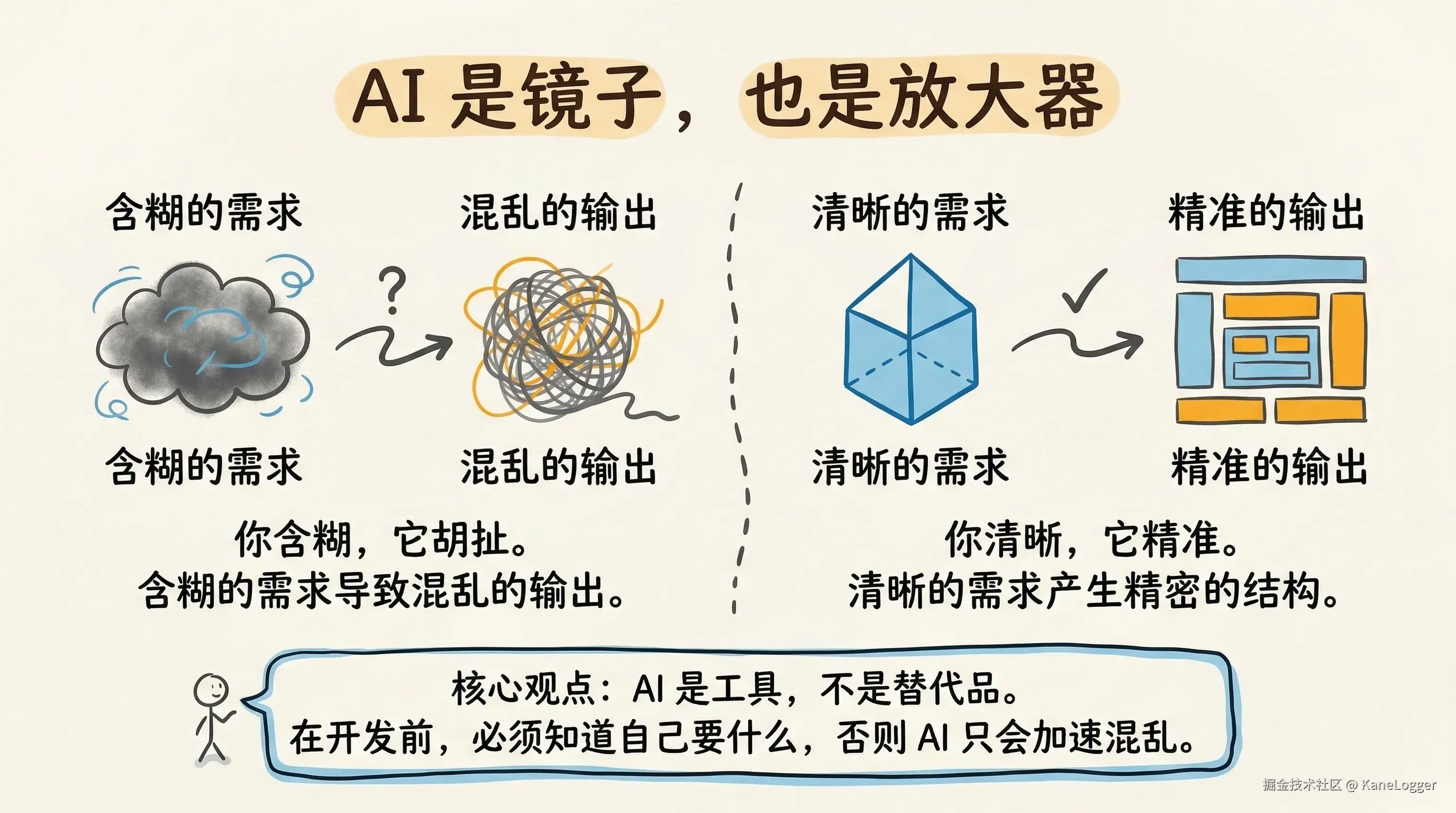
这段时间用AI协助开发的体验是:你含糊,它胡扯;你清晰,它精准。 AI 是工具,不是替代品。 在具体开发之前,我得知道自己要什么,才能让 AI 高效地实现。如果要什么我自己都没想清楚,AI 只会更快地走向混乱。
一个问题
当接到需求,程序员与普通人使用AI的差异是什么?
| 维度 | 普通人 | 程序员 |
|---|---|---|
| 需求接收 | 线性理解:"我要一个能自动回邮件的工具" | 维度拆解:触发条件(什么场景)、输入边界(邮件类型)、决策逻辑(回复规则)、输出格式、容错机制 |
| 隐含假设 | 默认需求明确且合理 | 先验质疑:这是真需求还是伪需求?用户真正要解决的是"省时间"还是"避免社交压力"? |
| 边界认知 | 模糊边界:"大概这样就行" | 刚性边界:明确 MVP 范围、技术约束、数据隐私红线 |
| 错误处理 | 默认系统不会出错,或出错后人工兜底 | 防御性编程:预设失败路径、降级策略、监控告警 |
| 结果预期 | 确定性幻觉:"这个功能一定能工作" | 概率化管理:"准确率 92%,召回率 85%,需人工复核剩余 8%" |
| AI 能力边界 | 过度恐惧("AI 要取代人类")或过度幻想("AI 什么都能做") | 理解知道 LLM 的幻觉率、上下文限制、Tool Use 的可靠性边界 |
| 成本意识 | 忽略边际成本 | 大致清楚 Token 消耗、API 调用费、维护成本 |
| 人机协作 | 全人工或全自动的二元思维 | 人机回环(Human-in-the-loop):明确划分机器决策域与人类决策域 |
| 解决路径 | 直觉 → 手工操作 → 问题解决(一次性) | 抽象 → 建模 → 自动化 → 监控 → 优化(复用性) |


- Token 效率
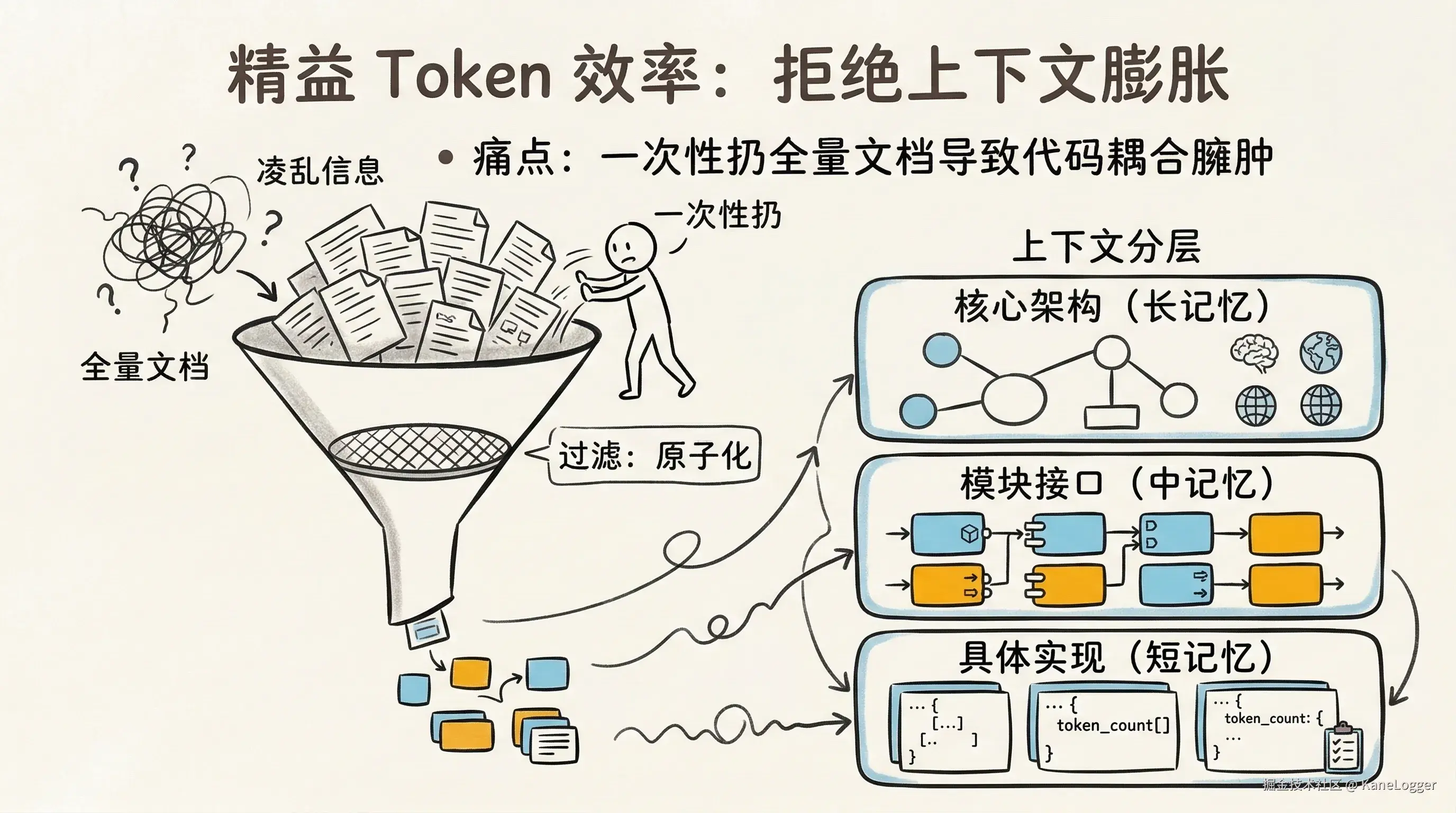
- 普通用法:一次性扔给AI整个需求文档,每次修改都传递全量上下文,重复消耗冗余Token,生成代码耦合臃肿,导致后续每次迭代都要重新理解大量无关逻辑
- 精益用法:
- 需求原子化:将系统拆分为"领域模型+接口契约+业务规则",分别用独立Session处理
- 上下文分层:核心架构(长期记忆)→ 模块接口(中期记忆)→ 具体实现(短期记忆),避免重复传递不变量
- 元编程:不写具体代码,写生成代码的模板,可复用的不是代码,而是生成代码的元逻辑。Prompt 模板库:"基于DDD设计一个微服务,限界上下文为{BC},聚合根为{AR}";生成一个遵循清洁架构的代码,其中实体为{Entity},字段为{Fields}"
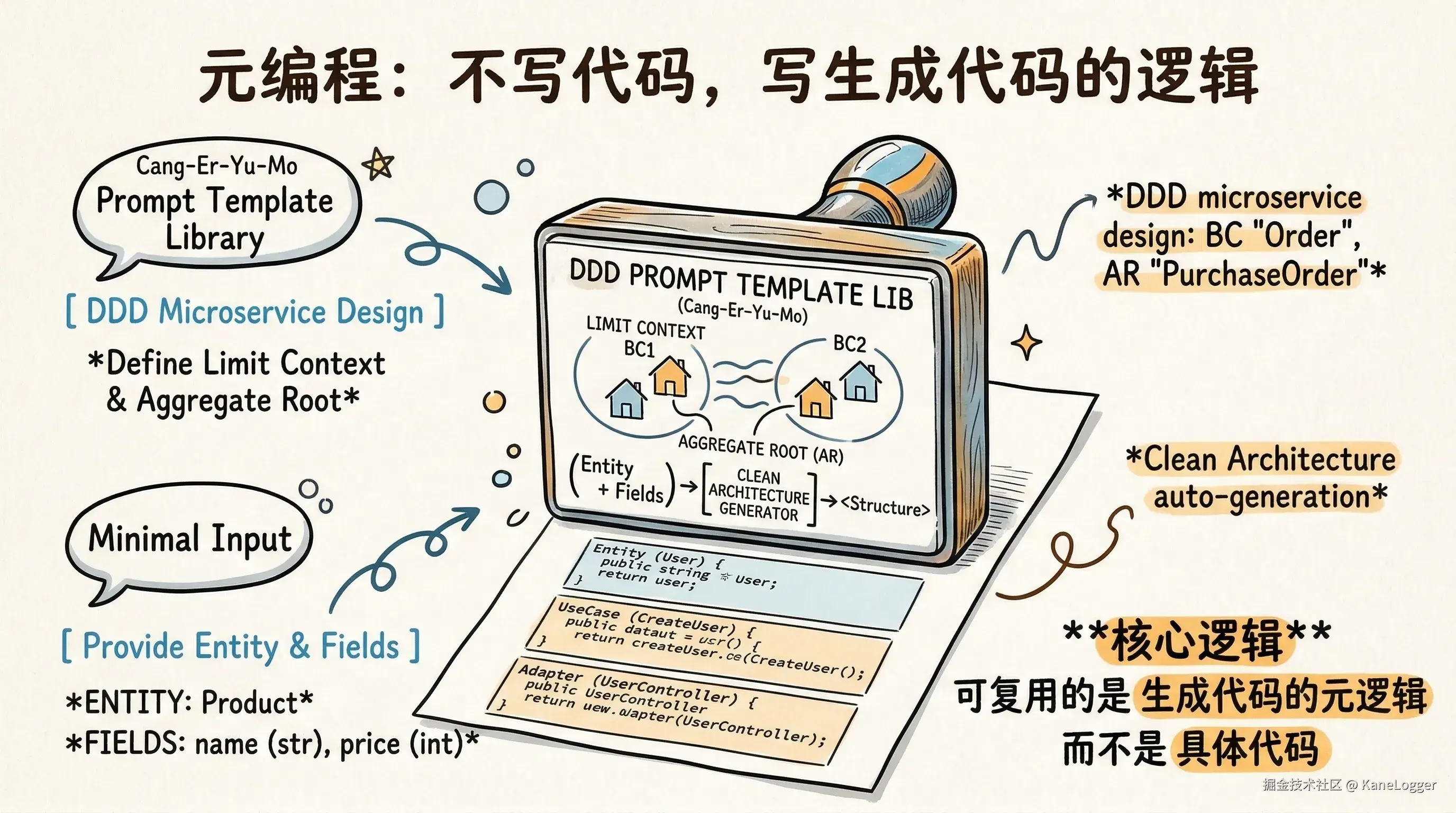
- 可维护性
- 传统:清晰命名、单一职责、测试覆盖
- 新增:
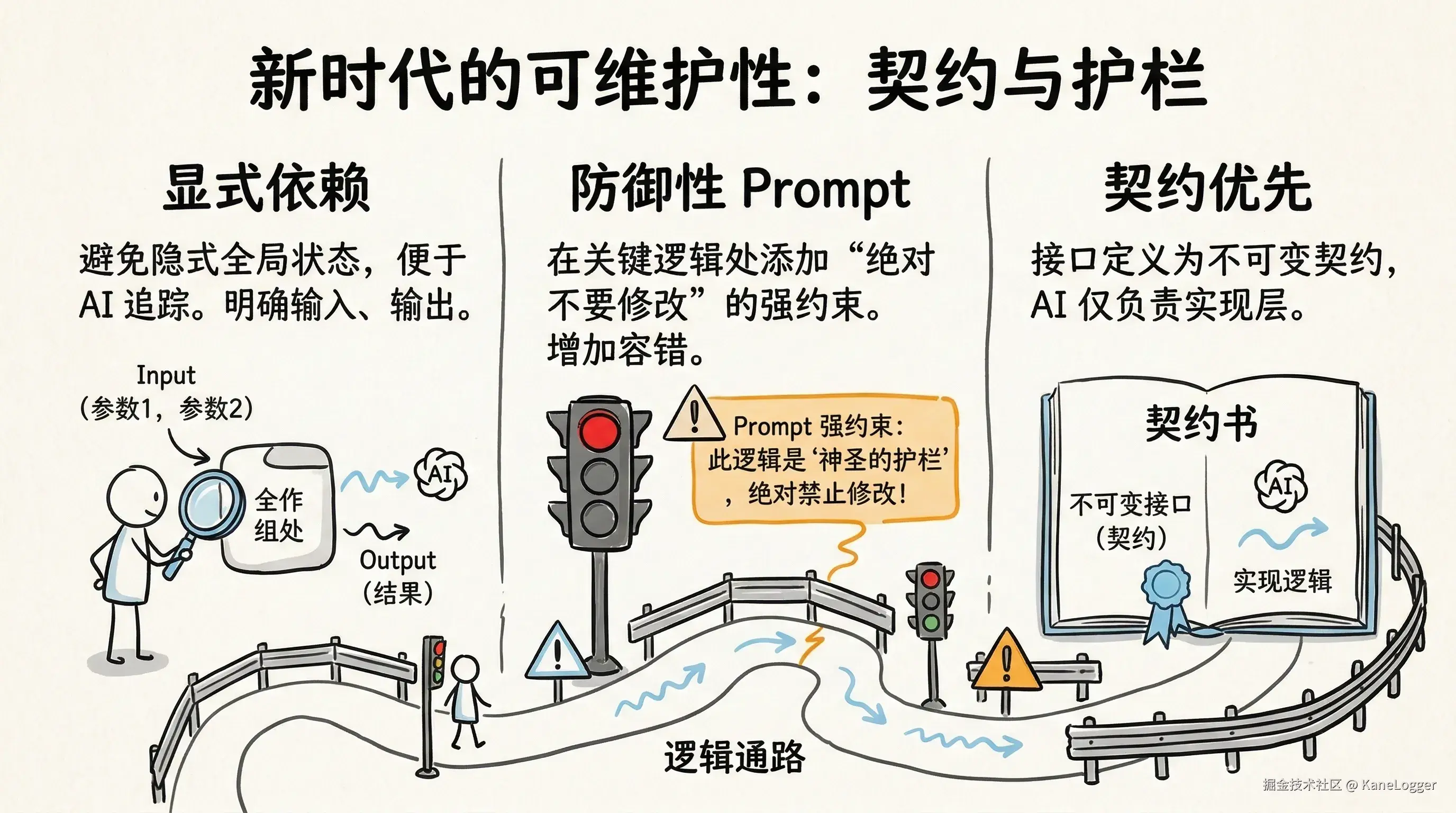
- 显式依赖:避免隐式全局状态(AI容易追踪)
- 兼容设计:防御性Prompt:在关键逻辑处添加"绝对不要修改X"、"必须保持Y不变"等强约束。渐进式复杂度:核心逻辑用简单代码(if/else、for循环),仅边缘情况用高级语法糖。显式中间状态:将隐式推理链条拆解为显式步骤(Chain-of-Thought代码化),让弱模型也能按图索骥
- 防御设计:契约优先:接口定义作为不可变契约,AI只能在实现层工作,不能改契约。黑盒模块:将复杂算法封装为确定性函数,AI只负责编排,不负责核心计算(避免幻觉破坏数学正确性)。测试即护栏:每个模块附带AI可运行的自动化测试,AI修改后自验证,不通过则阻断
核心变化
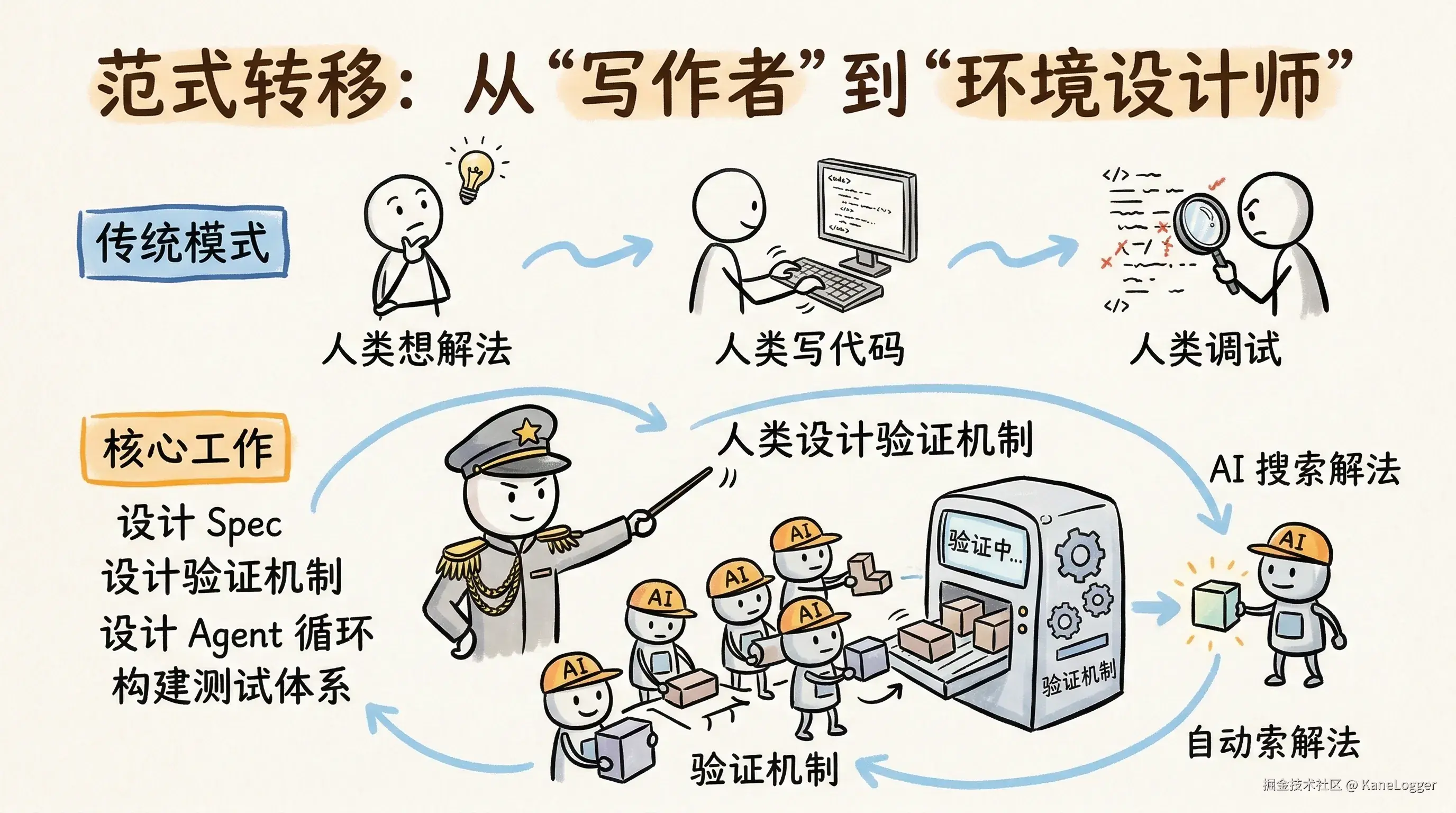
- 传统编程模式:人类想解法 → 人类写代码 → 人类调试
- AI 编程模式:人类设计验证机制 → AI 搜索解法 → 自动验证
本质变化:人类从 解决问题的人 变成 设计问题环境的人。
核心工作不再是手写代码而是:
- 设计 Spec
- 设计验证机制
- 设计 Agent 循环
- 构建测试体系
AI 应用演进路线:传统系统 -> AI 辅助 -> Agent 自动化 -> AI Native 应用 优势:
- 能随模型能力升级
- 不需要推倒重来
- 成本更低
工程师应该注意(架构师操作手册)
AI协作编程的核心分水岭:不是产出速度,而是产出的"AI亲和力"。好的代码结构对人和大模型都友好,且能在模型能力降级时保持可用。
测试策略变化
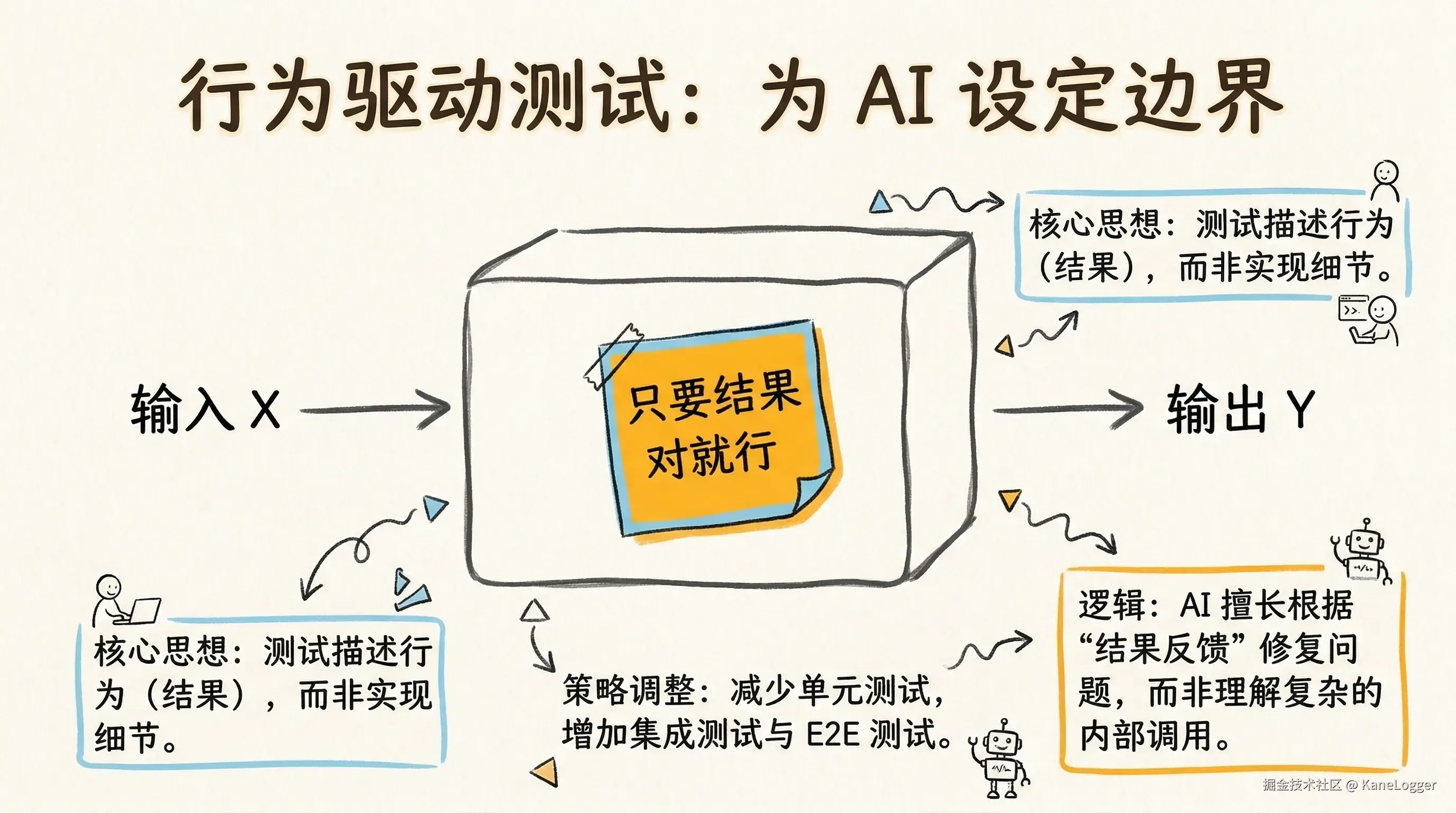
设计行为验证而非实现验证。核心思想:测试描述行为,而不是描述实现 因为 AI 写代码更适合根据 行为结果 修复问题,而不是根据实现细节。
- 传统测试:测试函数A调用函数B
- AI 时代测试:输入 X → 系统返回 Y 可以:
- 减少单元测试
- 提高集成测试
- 提高 E2E 测试
AI 编程的核心机制 Agentic Loops(代理循环)
构建"生成-验证-重试"的自动化循环,这是架构师的核心设计工作 循环结构: AI Coding -> 运行测试 -> 失败 -> AI 重新 Coding -> 再次运行测试。直到所有测试通过 这种模式本质是:通过自动验证机制让 AI 暴力搜索解法
text
人类意图(自然语言) → SDD(形式化契约) → AI 实现(代码)
↑________________________↓
验证闭环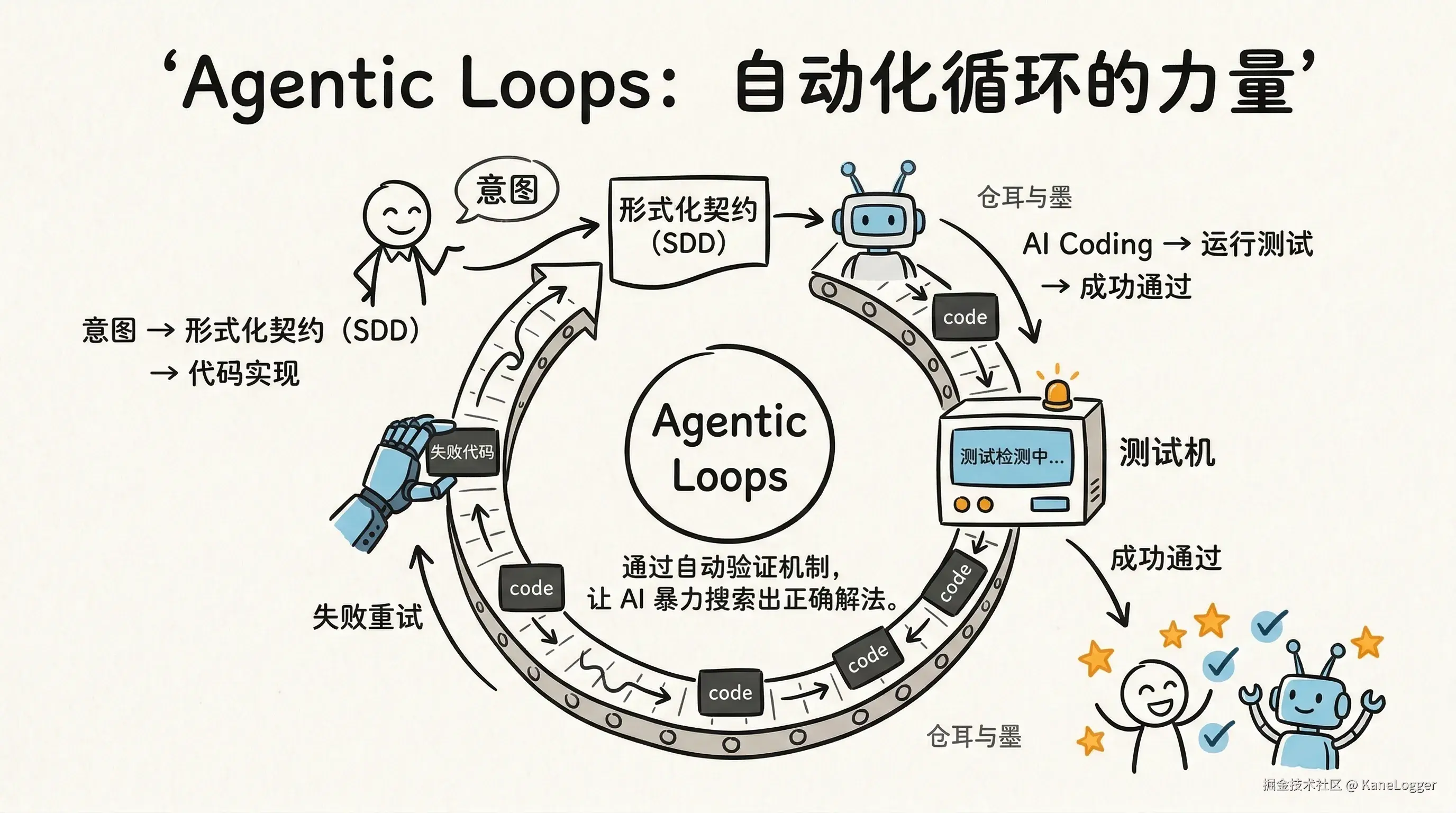
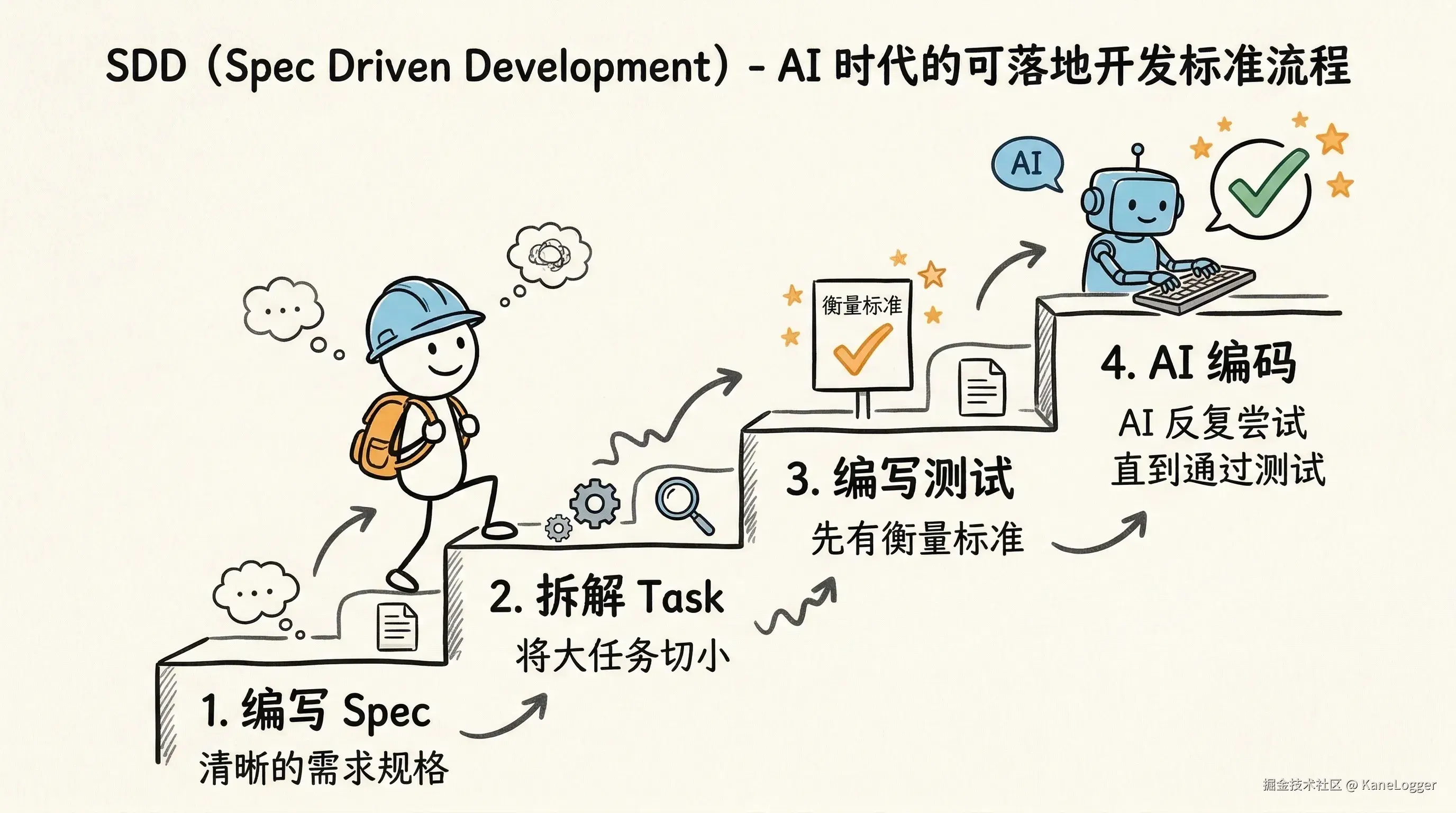
Spec Driven Development(SDD)
如何编写Spec拆解Task 推荐开发流程:
- 编写 Spec
- 根据 Spec 拆解 Task
- 根据 Task 编写测试
- AI 根据测试进行编码直到通过
流程图:Spec -> Task -> Test -> AI Coding -> Run Test Fail → Retry
关键思想:AI 不需要知道最优解,只要不断尝试直到测试通过。
上下文工程(Context Engineering)
如何设计信息投喂策略 AI Coding 的本质其实是:上下文管理能力。 优化方法:原则:上下文越精准,AI 输出越稳定。
- 明确问题位置
- 指定相关文件
- 压缩无关信息
- 必要时新开对话

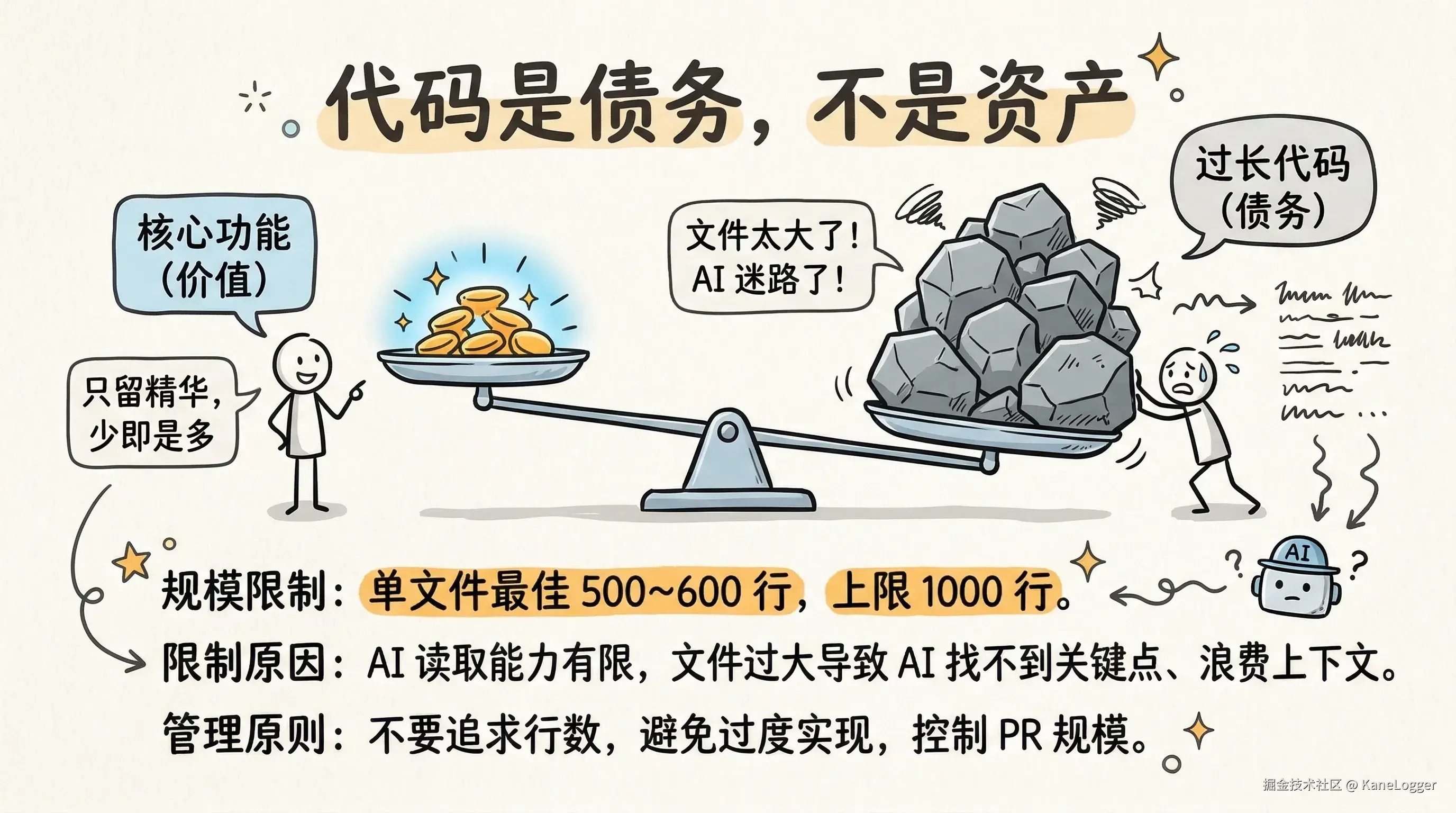
代码规模控制
如何控制技术债务的"增量" AI 时代的一个重要原则:代码是债务,不是资产 注意事项:
- 不要追求代码行数
- 避免过度复杂实现
- 控制 PR 规模
建议:
- 单文件代码 ≤1000 行
- 最佳规模 500~600 行
- 原因:AI 工具通常只读取前 2000 行代码。文件过大:
- AI 找不到关键代码
- 上下文浪费
- 成本增加
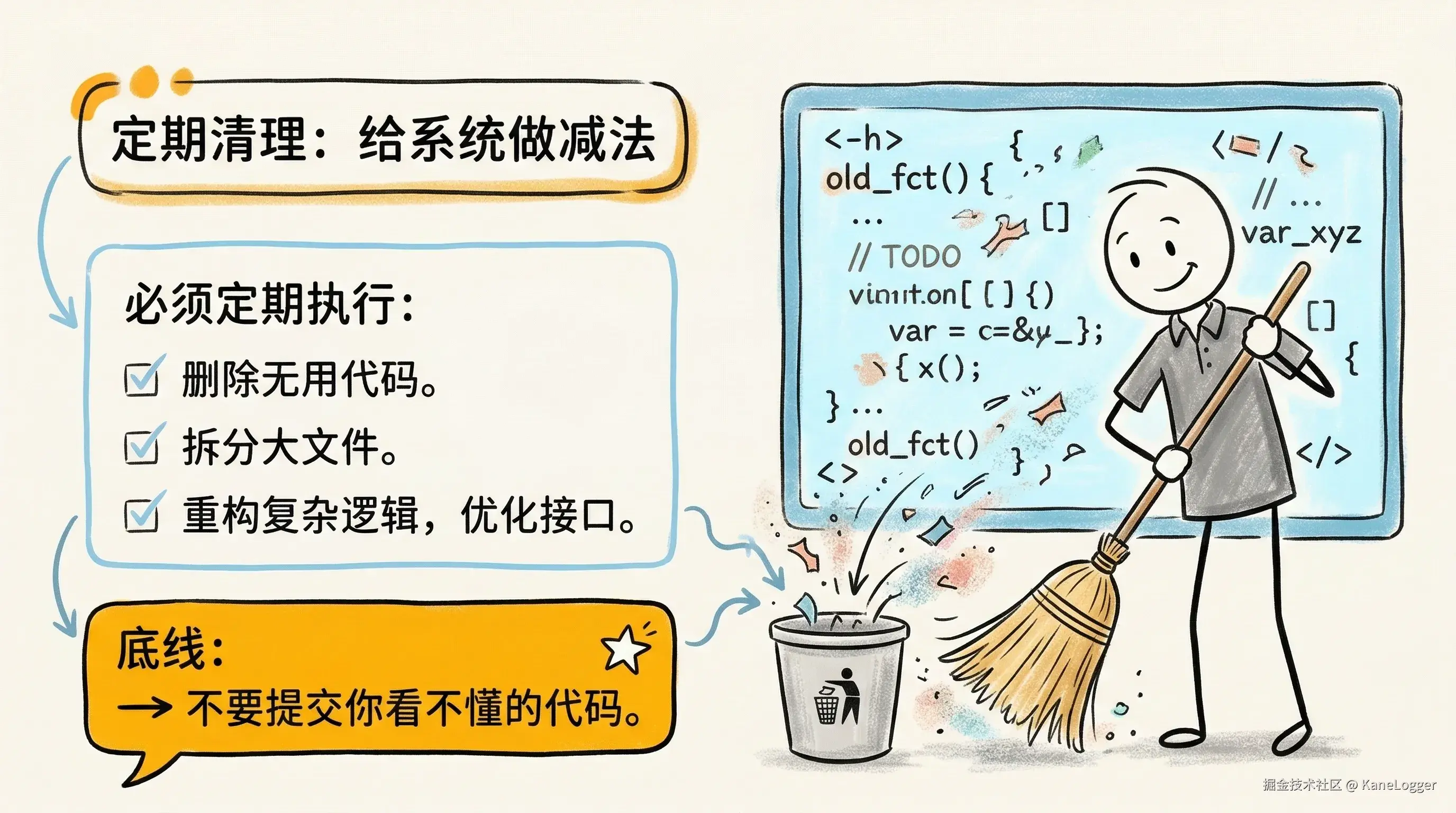
技术债管理
如何定期清理债务。 AI 写代码会产生大量技术债。否则项目会迅速失控。 必须定期清理:
- 删除无用代码
- 拆分大文件
- 重构复杂逻辑
- 优化接口
不提交看不懂的代码
如何保持理解力的底线,一个重要底线:不要提交你看不懂的代码。否则项目会逐渐失控。 AI 可以生成代码,但理解能力仍然是核心竞争力。 最低要求:
- 理解代码做什么
- 理解关键逻辑
- 确认安全性
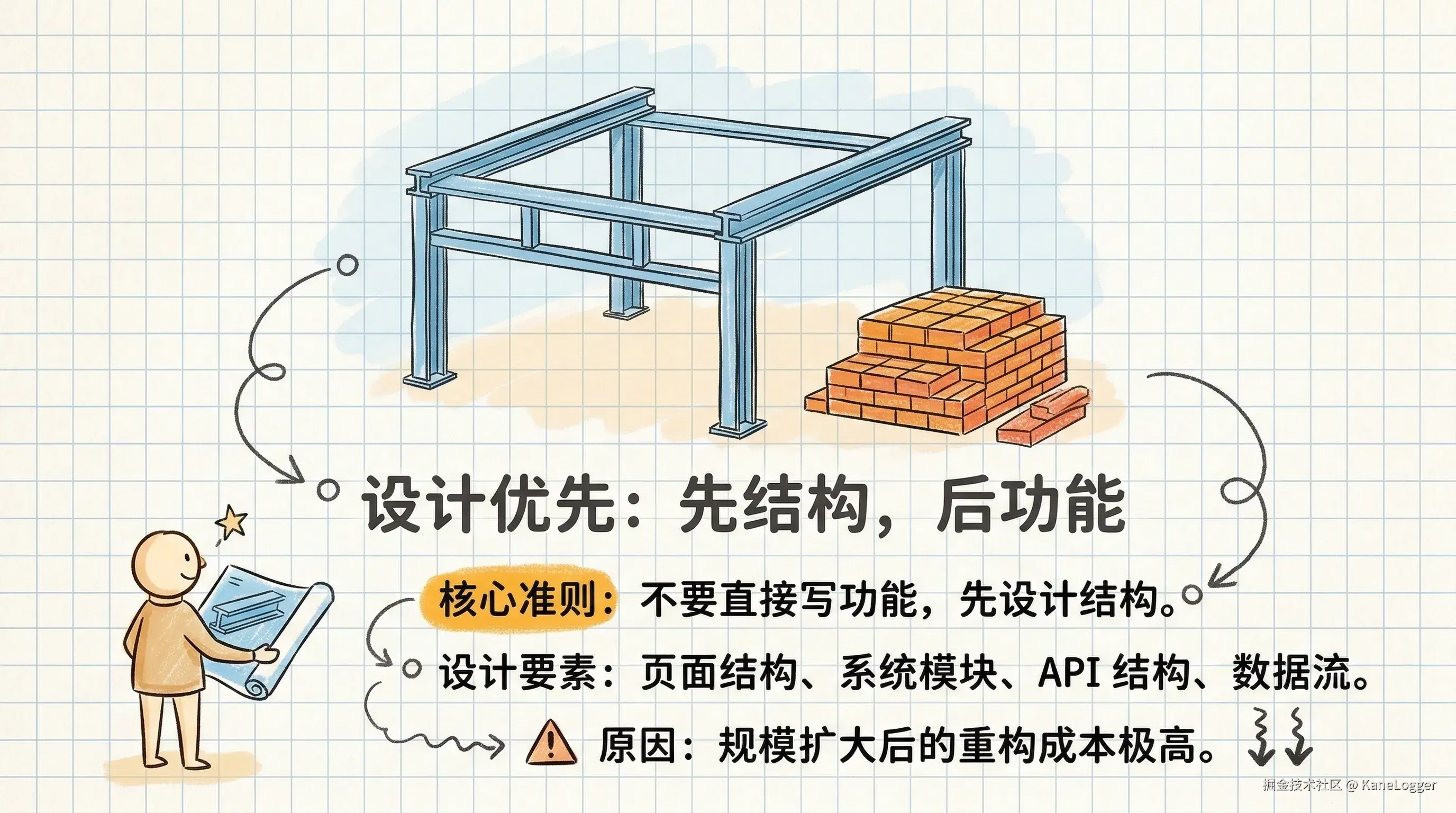
设计优先原则
如何在AI写代码前完成结构设计 不要直接让 AI 写功能。 因为项目规模扩大后再重构成本极高,先设计:
- 页面结构
- 系统模块
- API 结构
- 数据流
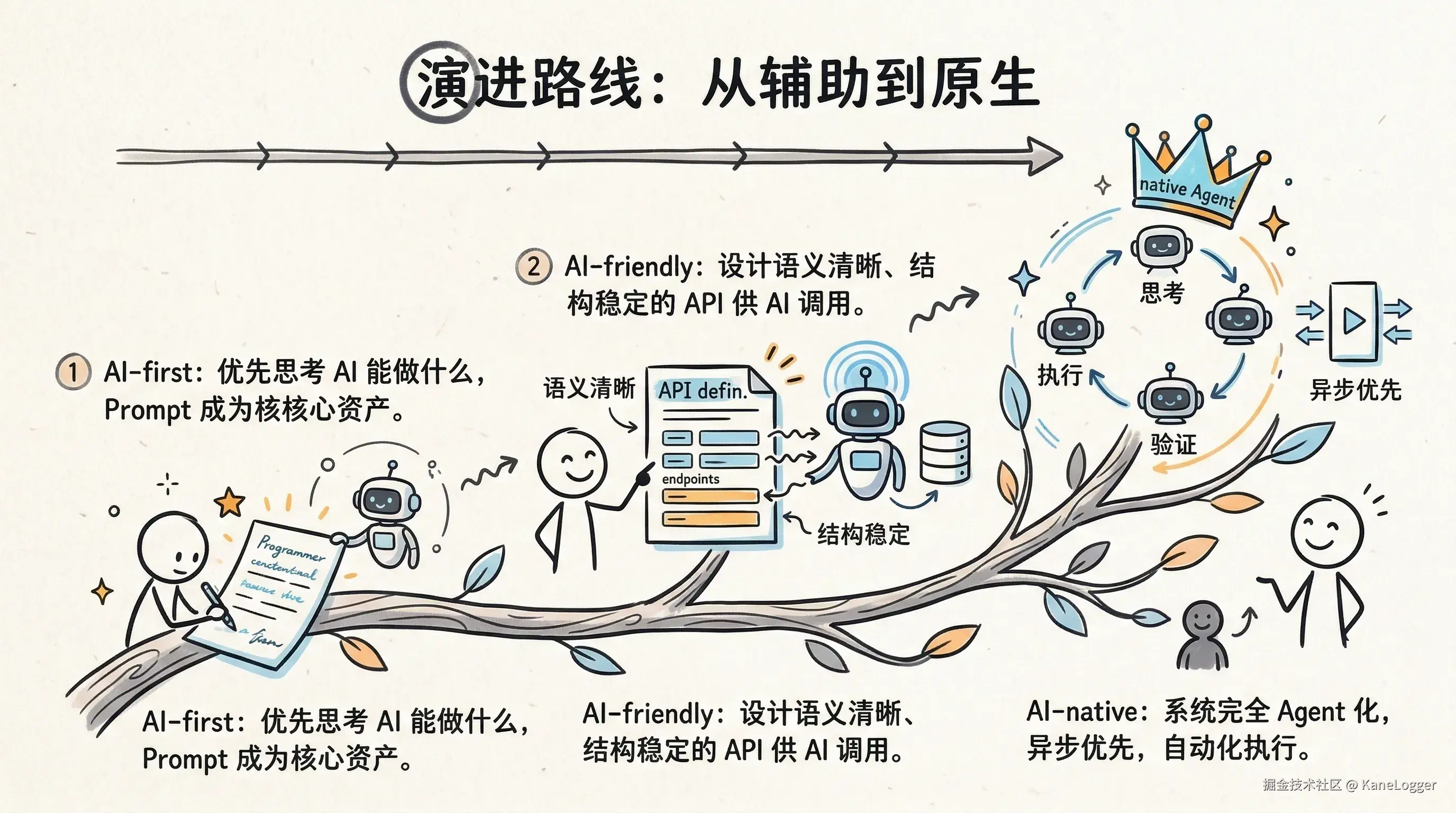
渐进式设计
- AI-first
- 优先思考 AI 能做什么
- 产品设计优先考虑:哪些任务可以交给 AI、prompt 作为核心资产、AI 自动化能力
- AI-friendly
- 设计适合 AI 调用的接口
- 接口设计需要满足: 语义清晰、API 结构稳定、易于模型理解
- 方法:使用 Skills、封装操作、减少 CLI / MCP
- AI-native
- 完全 Agent 化
- 当模型能力足够强时:系统直接由 Agent 操作。
- 原则:通用 Agent、异步优先、自动化执行
AI的产出要求(标准化定义)
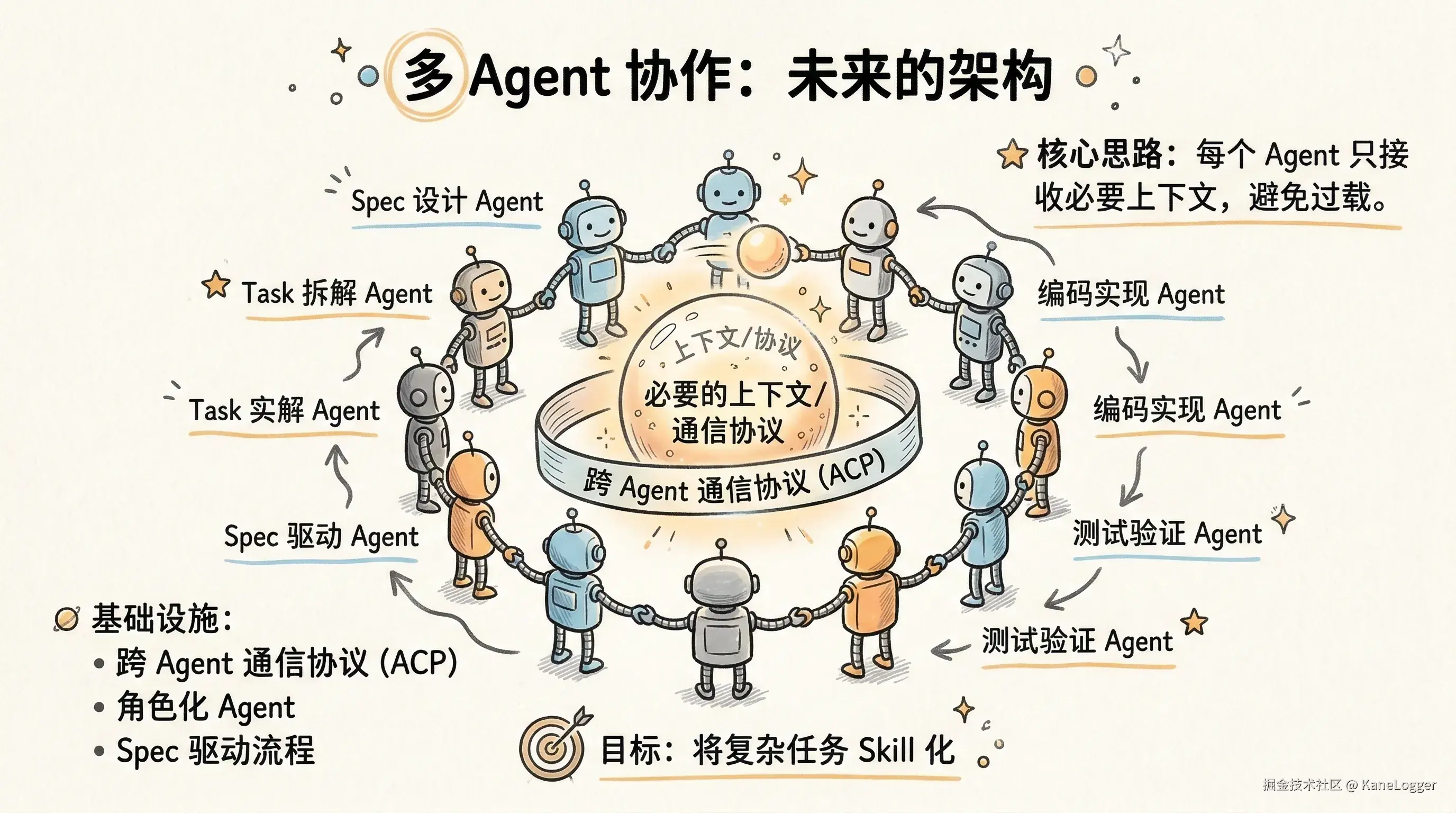
多 Agent 协作架构
AI 编程需要多个 Agent 协作。每个 Agent 只接收必要上下文。避免上下文过大。 核心思路:
- 跨 Agent 通信协议(ACP / EventBridge)
- 上下文共享
- 角色化 Agent
- 提示词工程
- Spec 驱动流程 -> skill 化