今天又是坐牢的一次比赛,恭喜获得本次比赛称号:挂机王,一个签到题能卡住两个小时,这两个小时简直坐的我怀疑人生,实在是找不出哪里错了,后来快结束的时候才发现少了一个等于号,也不至于连签到题都没写出来 -_-!。
比赛连接: 河南萌新联赛2025第(四)场:河南大学_ACM/NOI/CSP/CCPC/ICPC算法编程高难度练习赛_牛客竞赛OJ
本次出题方给出的题目难度如下:
难度评估
-
签到:A,C,G,J
-
简单:B,D,L
-
中等:F,H,I
-
困难:E,K
我做题的顺序为G、C、A、J,我也是本本分分地写了写签到题,简单题甚至都开不出来,既然都比赛结束了,就当又是一次锻炼了,多多积累一些比赛的思维以及解题技巧,下面就开始补题吧。
G-封闭运算
题目链接:G-封闭运算_河南萌新联赛2025第(四)场:河南大学
刚开始的我竟然找不出来哪一个才是签到题,???我的Hello World呢?在找了一分钟之后实在是没办法了,就找了一个看着最好欺负的下手了,一看数据范围,小于100??!,这我还犹豫什么,直接三重循环暴力拿下!
赛时代码:
cpp
// Problem: 封闭运算
// Contest: NowCoder
// URL: https://ac.nowcoder.com/acm/contest/115184/G
// Memory Limit: 512 MB
// Time Limit: 2000 ms
//
// Powered by CP Editor (https://cpeditor.org)
#include <bits/stdc++.h>
using namespace std;
#define int long long
#define endl '\n'
#define IOS ios::sync_with_stdio(0),cin.tie(0),cout.tie(0);
#define pii pair<int,int>
#define fi first
#define se second
const int inf = 0x3f3f3f3f;
void solve()
{
int n;cin>>n;
int k=1;
vector<int> a(n+1);
for(int i=1;i<=n;i++) cin>>a[i];
bool f = 1;
for(int i=1;i<=n;i++)
{
for(int j=i;j<=n;j++)
{
int t = a[i] | a[j];//按位或操作
for(k=1;k<=n;k++)
{
if(t == a[k])
{
break;
}
}
if(k == n+1)
{
f = 0;
break;
}
}
}
if(f) cout<<"YES"<<endl;
else cout<<"NO"<<endl;
// cout<<fixed<<setprecision(x)<< ;
}
signed main()// Don't forget pre_handle!
{
IOS
int T=1;
// cin>>T;
while(T--) solve();
return 0;
} 接下来是广告时间:有小伙伴对位运算 还不是很了解的,可以点击此处一秒迈入位运算的世界!
C-合并石子
题目链接:C-合并石子_河南萌新联赛2025第(四)场:河南大学
这道题我们要求出最少消耗的体力,具体是让所有的石子扔到哪一堆呢?看起来似乎很难找出规律,既然这样,就要开始枚举了,大体思路如下:
由题意可得,所有石子最后一定会合并到某一个位置,可以枚举最终位置,取所有情况中所花费体力的最小值。
对于位置x,在 1,x-1 区间中的石子一定会不断向x合并,在区间 x+1,n 区间中的石子也一定会不断向x合并。
由于每次合并是向上取整的,所以从离x置最远的石子开始合并一定更优,预处理前缀和后缀的体力消耗便可以O(1)的时间复杂度得到合并到位置x所花费体力的最小值。
所以 总的时间复杂度为O(N)。
这种思想是很常见的一种算法思维了,正向和逆向分别跑一遍就能求出每个点两端的情况(代价)接下来就遍历一遍所有的点取最值就行了。
赛时代码如下:
cpp
// Problem: 合并石子
// Contest: NowCoder
// URL: https://ac.nowcoder.com/acm/contest/115184/C
// Memory Limit: 512 MB
// Time Limit: 2000 ms
//
// Powered by CP Editor (https://cpeditor.org)
#include <bits/stdc++.h>
using namespace std;
#define int long long
#define endl '\n'
#define IOS ios::sync_with_stdio(0),cin.tie(0),cout.tie(0);
#define pii pair<int,int>
#define fi first
#define se second
const int inf = 1e18;//不要用0x3f3f3f3f了,这道题的数据较大,用这个会WA的 别问我怎么知道的
void solve()
{
int n,m;cin>>n>>m;
vector<int> a(n+1),l(n+2,0),r(n+2,0);
for(int i=1;i<=n;i++) cin>>a[i];
int ans=inf,sum=0;
for(int i=1;i<=n;i++)//正向跑一遍求出每个点所需的体力值
{
int t = sum / m;
if(sum % m) t++;
l[i] = t;
sum += a[i];
}
sum = 0;
for(int i=n;i>=1;i--)//逆向跑一遍求出每个点所需的体力值
{
int t = sum / m;
if(sum % m) t++;
r[i] = t;
sum += a[i];
}
//因为是求的单个点的,所以还需要用前缀和与后缀和来统计到达该点一共所需的体力值
for(int i=1;i<=n;i++) l[i] = l[i] + l[i-1];//前缀和
for(int i=n;i>=1;i--) r[i] = r[i+1] + r[i];//后缀和
//最后只需要遍历一遍求出最小体力就行了
for(int i=1;i<=n;i++) ans = min(ans,l[i] + r[i]);
cout<<ans<<endl;
// debug:
// for(auto i : l) cout<<i<<' ';
// cout<<endl;
// for(auto i : r) cout<<i<<' ';
// cout<<fixed<<setprecision(x)<< ;
}
signed main()// Don't forget pre_handle!
{
IOS
int T=1;
// cin>>T;
while(T--) solve();
return 0;
} 这道题需要注意的就是inf (无穷大)不能用0x3f3f3f3f ,不然会wa的,可以用1e18 来赋值给inf
A-完美序列
题目链接:A-完美序列_河南萌新联赛2025第(四)场:河南大学
这道题第一眼除了暴力跑一遍枚举所有的情况就想不出更好的办法了,可是看了一眼数据范围2e5这我怎么跑?本来都想放弃了,可是后来又看了一眼数据范围,虽然元素的个数是2e5,但是元素的大小范围只有5000啊!我的思路想法瞬间就有了,枚举所有可能的和!对,就是这样,这样的时间复杂度是....两个数的和最大不超过10000,然后每个数都大小是5000,所以是5e7,刚好擦边,嘶~,我的心情瞬间又跌入了谷底,一看时间要求,诶?2s?我瞬间来了斗志,直接暴力将代码写了出来,在CP-Editor上信心满满的一运行!诶???:
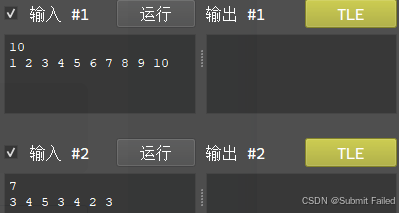
这怎么T了?当时的天又塌了,后来开始去想优化的方法,首先K是不能再少了的,那就看看内层循环能不能减少一部分,对于枚举的每一个和K,我们其实只需要枚举到K/2就行了啊,因为我们已经用map存放所有的元素了,枚举i的时候K - i是可以直接算出来的,所以就可以在这里进行一个优化,想到这里,我立马开始了更改,果不其然,代码跑出来了:
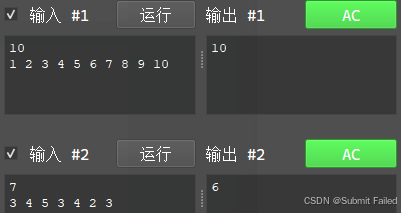
嘶~,舒服多了,提交上去:

没错!天又塌了!这怎么会错呢?都这么暴力了!后来才发现最后的结果必须是偶数,所以少了一个判断,总的来说,这道题的解题思路如下:
我们在枚举和K的时候,如果当前内层循环所遍历的i存在,并且k-i也存在,那么我们就需要判断两个数时候相等了,如果i和k-i不相等的话,直接就是让t累加到两个数出现的次数的最小的那个再*2就行了,但如果是两个数相等,即 i == k-i 的时候,就说明是只有这一个了,就不需要*2,直接加上就行了,但是需要注意的是有可能在这里加的是一个奇数,所以需要在最后进行判断,如果答案是奇数的话就需要--。
我赶紧加上了最后的判断,再提交!

舒服了,赛时代码如下:
cpp
// Problem: 完美序列
// Contest: NowCoder
// URL: https://ac.nowcoder.com/acm/contest/115184/A
// Memory Limit: 512 MB
// Time Limit: 2000 ms
//
// Powered by CP Editor (https://cpeditor.org)
#include <bits/stdc++.h>
using namespace std;
#define int long long
#define endl '\n'
#define IOS ios::sync_with_stdio(0),cin.tie(0),cout.tie(0);
#define pii pair<int,int>
#define fi first
#define se second
const int inf = 0x3f3f3f3f;
void solve()
{
int n;cin>>n;
unordered_map<int,int> mp;
vector<int> a(n+1);
for(int i=1;i<=n;i++)
{
cin>>a[i];
mp[a[i]]++;//统计每一个元素出现的次数
}
int res = 0;
for(int k=10002;k>1;k--)//暴力枚举素所有可能的和K
{
int t = 0;
for(int i=1;i<=k/2;i++)//小优化
{
if(mp[i] > 0 && mp[k-i] > 0)//只有两半都存在的时候才有能组成K
{
// cout<<t<<' ';
t += 2 * min(mp[i],mp[k-i]);
//如果i == k - i了,就需要减去多加的一组
if(i * 2 == k) t -= min(mp[i],mp[k-i]);
}
}
// cout<<"k = "<<k<<" "<<t<<endl;
res = max(res,t);//每次更新最大值
}
if(res & 1) res --;//如果最后的答案为奇数了,就说明在在枚举的i == k - i的时候加上了奇数 需要减去一个
cout<<res<<endl;
// cout<<fixed<<setprecision(x)<< ;
}
signed main()// Don't forget pre_handle!
{
IOS
int T=1;
// cin>>T;
while(T--) solve();
return 0;
} 这道题让我真正体验到了ACM的魅力,随着一阵阵的兴奋和随之而来的沉默,随着苦思冥想突然灵光一现!这中心情和心态的起起伏伏和一波三折,以及看到自己优化的代码通过了这道题,这种感觉是很难描述的,那一瞬间真的能消除所有的疲惫!希望我们都能得到自己满意的结果!
J-故障机器人的完美牌组
题目链接:J-故障机器人的完美牌组_河南萌新联赛2025第(四)场:河南大学
这是一道贪心的题目,给我的感觉很像最近这几天刷的cf上的题目,也就是因为这道题卡了我两个多小时,题目的意思十分容易理解,贪心的思路也很好想出来:就是从第二个数开始往后找,找出最大的那一个数让它和第一个数进行累加,最后删除这个数就是字典序最大的情况了,而如果最大的都是0的话,即从第二个数开始后面的数都是0的话,就没必要进行操作了,因为不管怎么加第一个数都保持不变,而要想让字典序最小的话,就直接将原数组输出进行了,因为原数组与操作后的数组相比,元素更多,长度更长,字典序也就相对更大。这就是贪心的思路,可是我在编译器上通过之后,随之而来的就是:
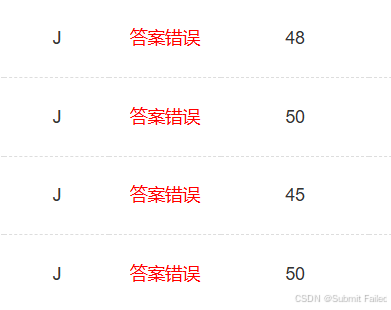
嘶~怎么回事,这还不贪???我苦苦想了半天都没有想出来需要特判的地方了,当时我的思路都开始混乱了,于是我想到了之前的队友跟我说的一句话:如果你觉得你的思路没有啥大问题,就重新敲一遍代码,也许就是你的代码太乱了有些细节忽略了,于是我又重新敲了一遍,并且还换了一种码风,在题目的样例和自己造的样例都通过之后又交了上去:

呵呵,这时候心都凉半截了,没办法,各种姿势开始想哪里的问题,终于在比赛结束的四十分钟前,我突然想到了一个问题,想让字典序最大,那我在找最大值的时候,如果有多个最大值的话,我就需要让大的尽量在前面,所以我就需要将最后一个最大值来与第一个进行替换!比如说样例1202,我们需要将最后一个2与第一个匹配为320而不是让第一个2与之匹配变为302,于是我立马将小于换为了小于等于,不信邪的又交了一发:

又舒服了,此时我看着所剩的寥寥无几的比赛时间和别人WA了七八发的下一道题,逐渐陷入了沉思.....不过很容易能看出来下一道题L考察的是素数筛,素数筛我前几天也整理过一篇博客,有兴趣的话可以点击这里:数论中的常用模板,但是赛时就是想不起来怎么筛了,还有B题,可以看出来是整除分块,但是具体怎么分还是没有思路,在上面的这篇博客中也有提到,emmm,剩下的题目明天再补,大家尽请期待!
J题的赛时代码:
cpp
// Problem: 故障机器人的完美牌组
// Contest: NowCoder
// URL: https://ac.nowcoder.com/acm/contest/115184/J
// Memory Limit: 512 MB
// Time Limit: 2000 ms
//
// Powered by CP Editor (https://cpeditor.org)
#include <bits/stdc++.h>
using namespace std;
#define int long long
#define endl '\n'
#define IOS ios::sync_with_stdio(0),cin.tie(0),cout.tie(0);
#define pii pair<int,int>
#define fi first
#define se second
const int inf = 0x3f3f3f3f;
void solve()
{
int n;cin>>n;
bool f = 1;
vector<int> a(n+5,0);
for(int i=1;i<=n;i++) cin>>a[i];
int mx = -1,index = -1;
if(n == 1)//对1的情况进行特判
{
cout<<1<<endl;
cout<<a[1]<<endl;
return ;
}
for(int i=2;i<=n;i++)
{
if(mx <= a[i])//一定是等于 要找最后一个最大值
{
mx = a[i];
index = i;
}
if(a[i] > 0) f = 0;//找到了一个非0的数字
}
//甚至都怀疑过是三目运算符的问题...
// cout<<(f == 0 ? n-1 : n)<<endl;
if(f)//全部都是0的话就将原数组输出就行了 此时原数组的字典序就最大
{
cout<<n<<endl;
for(int i=1;i<=n;i++) cout<<a[i]<<' ';
}
else//有最大值的话就将最后一个最大值赋值给第一个元素 然后将其删除就行了
{
cout<<n-1<<endl;
a[1] += mx;
for(int i=1;i<=n;i++)
{
if(i == index) continue;//跳过这个元素 因为这个元素已经被删除了 和第一个元素进行累加了
cout<<a[i]<<' ';
}
}
// cout<<fixed<<setprecision(x)<< ;
}
signed main()// Don't forget pre_handle!
{
IOS
int T=1;
// cin>>T;
while(T--) solve();
return 0;
} B-0!!!!!
题目链接:B-0!!!!!_河南萌新联赛2025第(四)场:河南大学
这道题也是考察的数论中的整除分块的内容,我们要想让最终的乘积末尾是0,那么我们就需要去统计这些排列中2的个数和5的个数,具体来说是幂次,先不管区间内的所有数,就先拿两个数来说,比如4和10,犹豫他们两个数都要进行因数分解,即4变为1,2,4,而10变为1,2,5,10,所以在相乘之后会有两个0,这两个0是由于其中的一个2和一个5得到的,另一个0是由4/2与10得到的,不管是2还是4,都起到了2的效果,但是如果遇到了25的话,2和4所产生的效果就不一样了,4和25相互作用所产生的效果是2和25所产生的效果的基础上额外再多了一次2和5产生的效果,如果是6呢?其实6和2所产生的效果是一样的,因为6 = 2 * 3,它的因数中只有一个2,所以它只会贡献出1个2,同理10也只会贡献出1个2,但是对于2的次幂来说,比如说是4,它分解之后变为了2 4,这样在统计2的数量的时候,会漏掉一次,同理8会漏掉两次,所以需要在外层去遍历x的所有次幂,,这样就能把所有的2产生的效果统计起来了,至于内层怎么实现,接着看:
内层的实现思路:
内层循环的作用:计算「约数中 x 的贡献次数」,即我们要求从1到lim中每个数因式分解之后的数列中一共有多少个i的倍数,这就相当于从1到lim/i的区间中的约数个数和:
- 量 A :从 1 到
lim的所有整数中,每个数的所有约数里,是i的倍数的约数总个数(即约数中包含i这个因子的总数量)。- 量 B :从 1 到
m(其中m = lim / i)的所有整数的「约数总个数」(即每个数的约数数量相加的总和)。
- 对于 1 到
lim中所有是i的倍数的数n,它们可以唯一表示为n = i × k(k从 1 到m,m = lim / i)。- 每个这样的
n对「量 A」的贡献,等于k的约数个数。- 因此,「量 A」就是所有
k=1到k=m的约数个数之和,也就是「量 B」。举个例子来验证:
设
i=2,lim=6(则m = 6 / 2 = 3):计算量 A(1 到 6 中,约数是 2 的倍数的总个数):
n=1:不是 2 的倍数 → 贡献 0
n=2(=2×1):约数是 1,2 → 是 2 的倍数的约数只有 2 → 贡献 1(对应k=1的约数个数:1 的约数是 1 → 1 个)
n=3:不是 2 的倍数 → 贡献 0
n=4(=2×2):约数是 1,2,4 → 是 2 的倍数的约数是 2,4 → 贡献 2(对应k=2的约数个数:2 的约数是 1,2 → 2 个)
n=5:不是 2 的倍数 → 贡献 0
n=6(=2×3):约数是 1,2,3,6 → 是 2 的倍数的约数是 2,6 → 贡献 2(对应k=3的约数个数:3 的约数是 1,3 → 2 个)量 A 总和:1 + 2 + 2 = 5。
计算量 B(1 到 3 的约数总个数):
k=1:约数是 1 → 1 个k=2:约数是 1,2 → 2 个k=3:约数是 1,3 → 2 个量 B 总和:1 + 2 + 2 = 5。
显然,量 A = 量 B,验证了等价关系。
总之:
- 1 到
lim中,约数是i的倍数的总个数(量 A),只与i的倍数n = i×k有关。- 每个
n = i×k对量 A 的贡献,等于k的约数个数。- 因此量 A 等于 1 到
m=lim/i的约数总个数(量 B)。- 用整除分块计算量 B,能高效解决问题。
代码如下:
cpp
// Problem: 0!!!!!
// Contest: NowCoder
// URL: https://ac.nowcoder.com/acm/contest/115184/B
// Memory Limit: 512 MB
// Time Limit: 2000 ms
//
// Powered by CP Editor (https://cpeditor.org)
#include <bits/stdc++.h>
using namespace std;
#define int long long
#define endl '\n'
#define IOS ios::sync_with_stdio(0),cin.tie(0),cout.tie(0);
#define pii pair<int,int>
#define fi first
#define se second
const int inf = 0x3f3f3f3f;
int f(int x,int lim)
{
int num = 0;
for(int i=x;i<=lim;i*=x)//外层去枚举x的幂次 (x, x², x³...)
{
int n = lim / i;//从1到lim中i的倍数有n个
for(int l=1;l<=n;l++)
{
int k = n / l;//从1到n中有k个是都l的倍数
int r = n / k;//当前块的有边界
num += k * (r - l + 1);//这个区间内的所有因子在1到n中都有k个该因子的倍数(即他们都作为k个数的因子)
l = r;//跳到下一个块
}
}
return num;
}
void solve()
{
int l,r;cin>>l>>r;
int a = f(2,r) - f(2,l-1);
int b = f(5,r) - f(5,l-1);
cout<<min(a,b)<<endl;
// cout<<f(2,r) - f(2,l-1)<<endl;
// cout<<f(5,r) - f(5,l-1)<<endl;
// cout<<fixed<<setprecision(x)<< ;
}
signed main()// Don't forget pre_handle!
{
IOS
int T=1;
// cin>>T;
while(T--) solve();
return 0;
} D-箭头谜题Ⅰ
题目链接:D-箭头谜题Ⅰ_河南萌新联赛2025第(四)场:河南大学
这道题问能不能在使用最多k次魔法的情况下从1,1的起点走到n,m的终点,那么我们可以从起点开始用BFS来跑一遍,求出从起点到终点的最短路径,可以用一个数组专门存放从起点到每个点所需要的代价(即使用魔法的次数),然后让代价更小的不断更新,看一下从起点到终点所需要最少的代价与k比较就行了,这个题的BFS分为两部分,一种是有代价的,你需要使用魔法老更改下一步的位置,而另一种是不需要代价,直接按照所给的方向走,所以我们优先去走那些不需要代价的点,我们可以用一个双端队列,一端存不需要代价的,一端存需要代价的,然后每次都从不需要代价的点中选择,不断更新最小代价即可。
cpp
// Problem: 箭头谜题Ⅰ
// Contest: NowCoder
// URL: https://ac.nowcoder.com/acm/contest/115184/D
// Memory Limit: 512 MB
// Time Limit: 2000 ms
//
// Powered by CP Editor (https://cpeditor.org)
#include <bits/stdc++.h>
using namespace std;
#define int long long
#define endl '\n'
#define IOS ios::sync_with_stdio(0),cin.tie(0),cout.tie(0);
#define pii pair<int,int>
#define fi first
#define se second
const int inf = 0x3f3f3f3f;
const int N = 1e6 + 10;
int dx[]={-1,1,0,0};
int dy[]={0,0,-1,1};
string mp[N];
struct point//对于每一个点 都有三种状态 即横纵坐标以及从起点到这个点的代价
{
int v;
int x,y;
};
void solve()
{
int n,m,k;cin>>n>>m>>k;
for(int i=1;i<=n;i++)
{
string s;cin>>s;
mp[i] = " " + s;//在字符串前面加一个空格,保证是从1,1作为起点开始的
}
vector<vector<int>> w(n+1,vector<int>(m+1,inf));//用于存从起点到该点的最小代价
deque<point> q;
q.push_back({0,1,1});//起点代价为0 坐标为1,1
w[1][1] = 0;//将起点所需要的代价初始化为0
while(!q.empty())//BFS过程
{
point t = q.front();q.pop_front();//每次都从队首取出元素 尽量取不需要代价的
int tx = t.x,ty = t.y,tv = t.v;//当前的点
if(tv > w[tx][ty]) continue;//如果当前的点的代价都已经大了就没必要进行了
char op = mp[tx][ty];
int next;
if(op == 'U') next = 0;
if(op == 'D') next = 1;
if(op == 'L') next = 2;
if(op == 'R') next = 3;
int nx = tx + dx[next],ny = ty + dy[next];//看一下下一个点的位置 先看不使用魔法怎么走
if(nx >= 1 && nx <= n && ny >= 1 && ny <= m && w[nx][ny] > tv)
{
w[nx][ny] = tv;
q.push_front({tv,nx,ny});
}
//再看看如果使用魔法的话能走哪里
for(int i=0;i<4;i++)
{
if(i == next) continue;
nx = tx + dx[i];
ny = ty + dy[i];
if(nx >= 1 && nx <= n && ny >= 1 && ny <= m && w[nx][ny] > tv + 1)
{
w[nx][ny] = tv + 1;
q.push_back({tv + 1,nx,ny});
}
}
//直到没有更优的解之后队列就会为空 不会导致队列中一直有元素存在
}
cout<<(w[n][m] <= k ? "YES" : "NO")<<endl;
// cout<<fixed<<setprecision(x)<< ;
}
signed main()// Don't forget pre_handle!
{
IOS
int T=1;
cin>>T;
while(T--) solve();
return 0;
} 这道题的核心是求 "最小魔法使用次数" ,本质上是一种边权只有 0 或 1 的最短路径问题:
- 顺着箭头方向移动:边权为 0(不消耗魔法)
- 违背箭头方向移动:边权为 1(消耗 1 次魔法)
这种场景最适合用0-1 BFS(双端队列实现),因为它能保证:
- 权值为 0 的边优先处理(放入队头)
- 权值为 1 的边后处理(放入队尾)
- 每个节点首次被访问时,得到的就是最小权值(最少魔法次数)
与普通BFS中的标记数组的作用相比:
- 普通 BFS 中,"已访问" 意味着节点不会再被处理(因为 BFS 按层次访问,首次访问就是最短路径)。
- 0-1 BFS 中,节点可能被多次加入队列(例如先以 2 次魔法入队,后以 1 次魔法入队),但通过
w数组的过滤,只有首次以最优状态(最小魔法次数)到达的节点会被处理,后续的非最优状态会被直接跳过。
即:
在普通 BFS(如无权图最短路径)中,由于边权均为 1,节点首次被访问时的路径就是最短路径 ,因此可以用
visited数组标记 "已访问",避免重复入队。而在 0-1 BFS 中,边权有 0 和 1,节点可能通过更优路径(权值更小)被再次访问,因此不能简单标记 "已访问"。此时,距离数组
w既记录了最短路径长度,又承担了 "过滤非最优状态" 的作用 ,替代了单独的visited数组。
为什么不需要单独标记 "已访问"?
-
节点可以被多次入队,但仅最优状态会被处理
由于移动操作的权值有 0(顺方向)和 1(逆方向)两种,同一节点可能通过不同魔法次数的路径被多次加入队列。例如:
- 第一次以 2 次魔法入队,此时
w[x][y]被更新为 2。 - 第二次以 1 次魔法入队(更优),此时
w[x][y]被更新为 1,后续处理时会优先处理这个状态。 - 当第一次入队的节点(2 次魔法)从队列中取出时,会因
2 > w[x][y](1)被跳过。
这种机制下,即使节点被多次入队,也不会导致无效处理,反而能保证 "最优状态优先处理"。
- 第一次以 2 次魔法入队,此时
-
距离数组
w本身就是访问状态的记录
w[x][y]的初始值是inf(无穷大),表示未被访问。当w[x][y]被更新为具体数值时,说明节点已被访问,且记录了最小魔法次数。后续任何大于该值的状态都会被过滤,等价于 "已访问且无需再处理"。
总结
双端队列(0-1 BFS)通过距离数组
w的状态过滤,实现了对节点访问的管理:
- 无需单独标记 "已访问",因为非最优状态会被
if (tv > w[tx][ty])直接跳过。- 允许节点多次入队,但仅处理首次以最小魔法次数到达的状态,保证了算法的正确性和效率。
这种设计是针对 "0-1 权值边" 问题的优化,既避免了普通 BFS 的错误(无法处理不同权值),又比 Dijkstra 算法(优先队列)更高效。
双端队列(0-1 BFS)通过距离数组
w的状态过滤,实现了对节点访问的管理:
- 无需单独标记 "已访问",因为非最优状态会被
if (tv > w[tx][ty])直接跳过。- 允许节点多次入队,但仅处理首次以最小魔法次数到达的状态,保证了算法的正确性和效率。
这种设计是针对 "0-1 权值边" 问题的优化,既避免了普通 BFS 的错误(无法处理不同权值),又比 Dijkstra 算法(优先队列)更高效。
L-故障机器人的完美遗物
这道题考察的是素数筛和数论中的内容,尽管赛时知道用素数筛,可是这种远古算法硬是一个字都想不起来怎么筛才行,我在点击进入这个博客中整理了两种素数筛法的模板以及一些有用的数论模板,有需要的可以保存起来,我们在对素数筛完之后,再观察题目,发现因数的个数必须是质数,那么我们知道质数一定没有除了2以外的偶数,而题目中又说了2也不算,那么我们就知道了所有的偶数就都不符合题意了,那么这时候的x就必须是完全平方数才行了,因为完全平方数开根号之后能整数,换句话说因数的个数才是奇数个,所以我们在对所有的遗物价值进行判断的时候,只需要考虑完全平方数的因数个数就行了,至于因数个数的计算,其实是数论中的知识了,
根据质因数分解,将一个数n分解成有限个质数的乘积:x = p1^a * p2^b * ...
那么它的因数的个数就为:(a+1)*(b+1)*...
以下是求x的因数个数的函数模板,有需要的话可以保存:
cpp
int ok(int x)//求x的因数的个数
{
if(x == 1) return 1LL;
int ans = 1;
for(int i=1;i<=idx;i++)
{
int t = p[i];
if(t * t > x) break;
if(x % t == 0)
{
int num = 0;
while(x % t == 0)
{
x /= t;
num++;
}
num++;
ans *= num;
}
}
if(x > 1) ans *= 2;
return ans;
}但是我们在计算因数的个数的时候,这样还是会超时,所以我们不妨做一些优化:既然我们计算的是所有的完全平方数的因数的个数,那么我们是不是只需要将开根号之后的数传入ok函数,然后在ok函数中做一些改变呢?答案是可以的,我们可以用ok函数来计算所有的x的平方的因数的个数,具体的实现思路如下:
原本是计算x的因数个数:质因数分解为x = p1^a * p2^b * ... 因数个数为:(a+1)*(b+1)*...
现在是求x的平方的因数个数:质因数分解为x^2 = (p1^a)^2 * (p2^b)^2 * ... 也就是x^2 = (p1^2a) * (p2^2b) * ...那么此时的x^2的因数个数就为(2a + 1) * (2b + 1) * ...
求x的平方的因数的个数的模板:
cpp
int ok(int x)//计算x的平方的因数个数
{
if(x == 1) return 1LL;
int ans = 1;
for(int i=1;i<=idx;i++)//质因数分解模板
{
int t = p[i];
if(t * t > x) break;
if(x % t == 0)
{
int num = 0;
while(x % t == 0)
{
x /= t;
num++;
}
num *= 2; num++;//原本是计算x的因数个数:质因数分解为x = p1^a * p2^b * ... 因数个数为:(a+1)*(b+1)*...
ans *= num;//现在是求x的平方的因数个数:质因数分解为x^2 = (p1^a)^2 * (p2^b)^2 * ...
//也就是x^2 = (p1^2a) * (p2^2b) * ...那么此时的x^2的因数个数就为(2a + 1) * (2b + 1) * ...
}
}
if(x > 1) ans *= 3; //同理原本的求x的因数个数为1 + 1 = 2,现在就是1^2 + 1 = 3了
return ans;
}这样就能通过本题了,详解代码如下:
cpp
// Problem: 故障机器人的完美遗物
// Contest: NowCoder
// URL: https://ac.nowcoder.com/acm/contest/115184/L
// Memory Limit: 512 MB
// Time Limit: 2000 ms
//
// Powered by CP Editor (https://cpeditor.org)
#include <bits/stdc++.h>
using namespace std;
#define int long long
#define endl '\n'
#define IOS ios::sync_with_stdio(0),cin.tie(0),cout.tie(0);
#define pii pair<int,int>
#define fi first
#define se second
const int inf = 0x3f3f3f3f;
const int N = 1e6 + 10;
vector<int> p(N);
vector<bool> v(N,true);
int idx = 0;
void init()//素数筛 模板
{
v[1] = false;//数组v用于判断i是否为素数
for(int i=2;i<N;i++)
{
if(v[i]) p[++idx] = i;//数组p用于依次存储所有的素数
for(int j=1;j<=idx;j++)
{
if(i * p[j] > N) break;
v[i * p[j]] = false;//欧拉筛三巨头
if(i % p[j] == 0) break;
}
}
}
int ok(int x)//计算x的平方的因数个数
{
if(x == 1) return 1LL;
int ans = 1;
for(int i=1;i<=idx;i++)//质因数分解模板
{
int t = p[i];
if(t * t > x) break;
if(x % t == 0)
{
int num = 0;
while(x % t == 0)
{
x /= t;
num++;
}
num *= 2; num++;//原本是计算x的因数个数:质因数分解为x = p1^a * p2^b * ... 因数个数为:(a+1)*(b+1)*...
ans *= num;//现在是求x的平方的因数个数:质因数分解为x^2 = (p1^a)^2 * (p2^b)^2 * ...
//也就是x^2 = (p1^2a) * (p2^2b) * ...那么此时的x^2的因数个数就为(2a + 1) * (2b + 1) * ...
}
}
if(x > 1) ans *= 3; //同理原本的求x的因数个数为1 + 1 = 2,现在就是1^2 + 1 = 3了
return ans;
}
void solve()
{
int n,res = 0;cin>>n;
vector<int> a(n+1);
for(int i=1;i<=n;i++) cin>>a[i];
for(int i=1;i<=n;i++)
{
int t = sqrt(a[i]);//要想是完美遗物 就必须是完全平方数 否则因数个数就是偶数个 一定不是质数
if(t * t != a[i]) continue;//只计算完全平方数的因数个数
int num = ok(t);//计算t的平方的因数个数 直接用a[i]的话会超时
if(v[num] && num != 2) res += a[i];//符合条件就累加
}
cout<<res<<endl;
// cout<<fixed<<setprecision(x)<< ;
}
signed main()// Don't forget pre_handle!
{
IOS
int T=1;
init();
// cin>>T;
while(T--) solve();
return 0;
}