文章目录
两个数组的交集
题目描述

解题思路
这道题小编要介绍一个比对算法,它可以O(n)的效率找出两个有序序列的交集(相同的值)和差集(不相同的值),步骤如下:
用两个指针it1、it2分别指向两个有序序列的开始,当遇到相同的值时,it1、it2同时++,当遇到不相等的值时,小的值就是差集,当一个序列遍历结束了,另一个序列剩下的都是差集。

这道题非常适合用比对算法来解决,首先需要把两个序列排成有序,这里就采用set来排序。后面就用比对算法的思路,当遇到交集把交集插入要返回的vector对象就行了。
(注释掉的是小编的思路,效率不及比对算法)
代码
cpp
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
set<int> s1(nums1.begin(), nums1.end());
set<int> s2(nums2.begin(), nums2.end());
vector<int> v;
// for(auto e : s2)
// {
// if(s1.count(e))
// {
// v.push_back(e);
// }
// }
auto it1 = s1.begin();
auto it2 = s2.begin();
while(it1 != s1.end() && it2 != s2.end())
{
if(*it1 < *it2)
{
it1++;
}
else if(*it1 > *it2)
{
it2++;
}
else
{
v.push_back(*it1);
it1++;
it2++;
}
}
return v;
}
};环形链表
题目描述
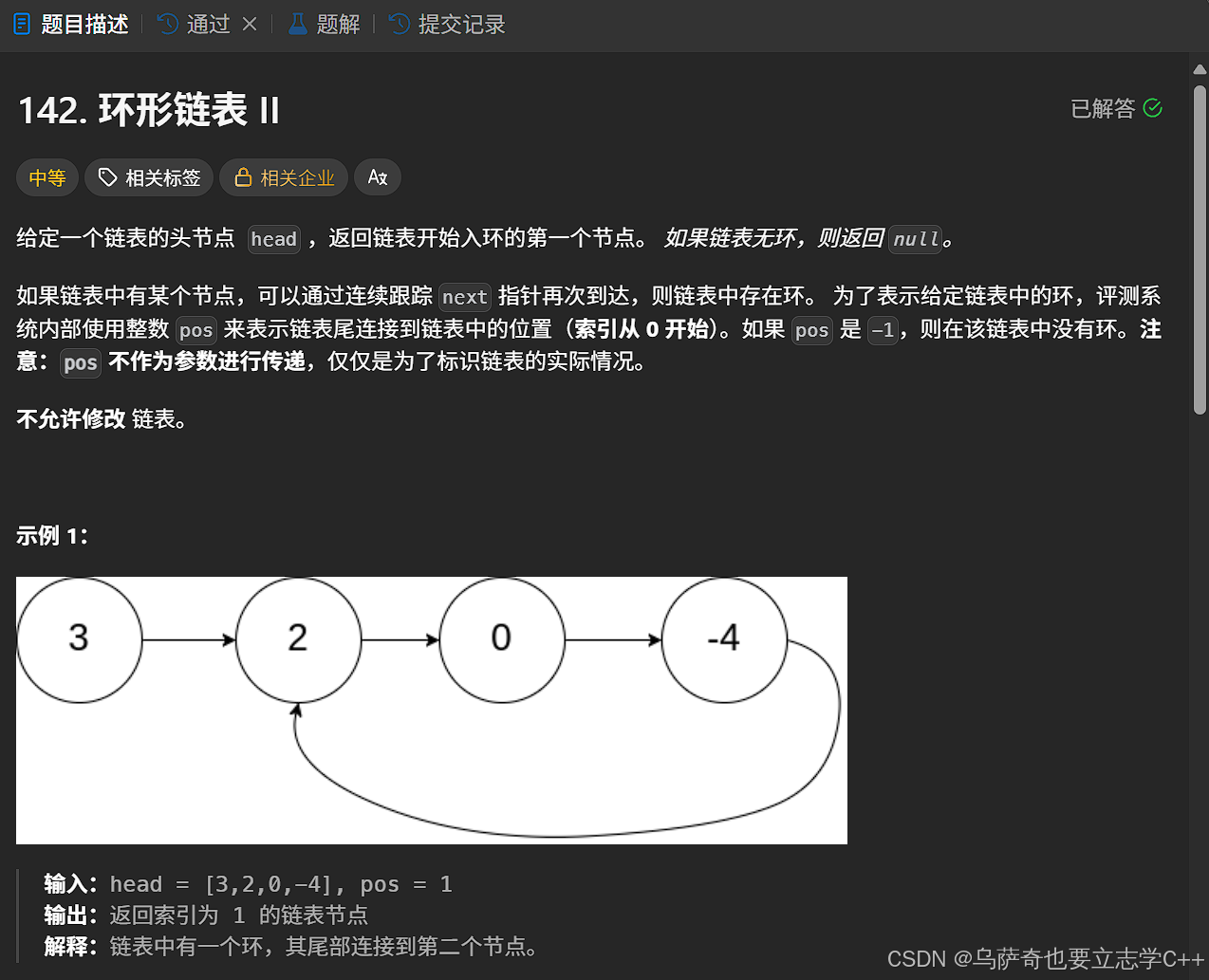
题目解析
这道题借助set来解决非常简单,因为每个结点的指针都不同,所以我们可以遍历整个链表,把每个链表的指针都存进set,在存新指针之前先判断一下set中有没有和新指针相同的指针,如果没有则继续遍历直到遍历到尾结点,返回nullptr,如果有说明我们找到环形链表的入口点了,返回当前结点。
代码
cpp
class Solution {
public:
ListNode *detectCycle(ListNode *head) {
ListNode* cur = head;
set<ListNode*> s;
while(cur)
{
if(s.count(cur))
return cur;
s.insert(cur);
cur = cur->next;
}
return nullptr;
}
};随机链表的复制
题目描述
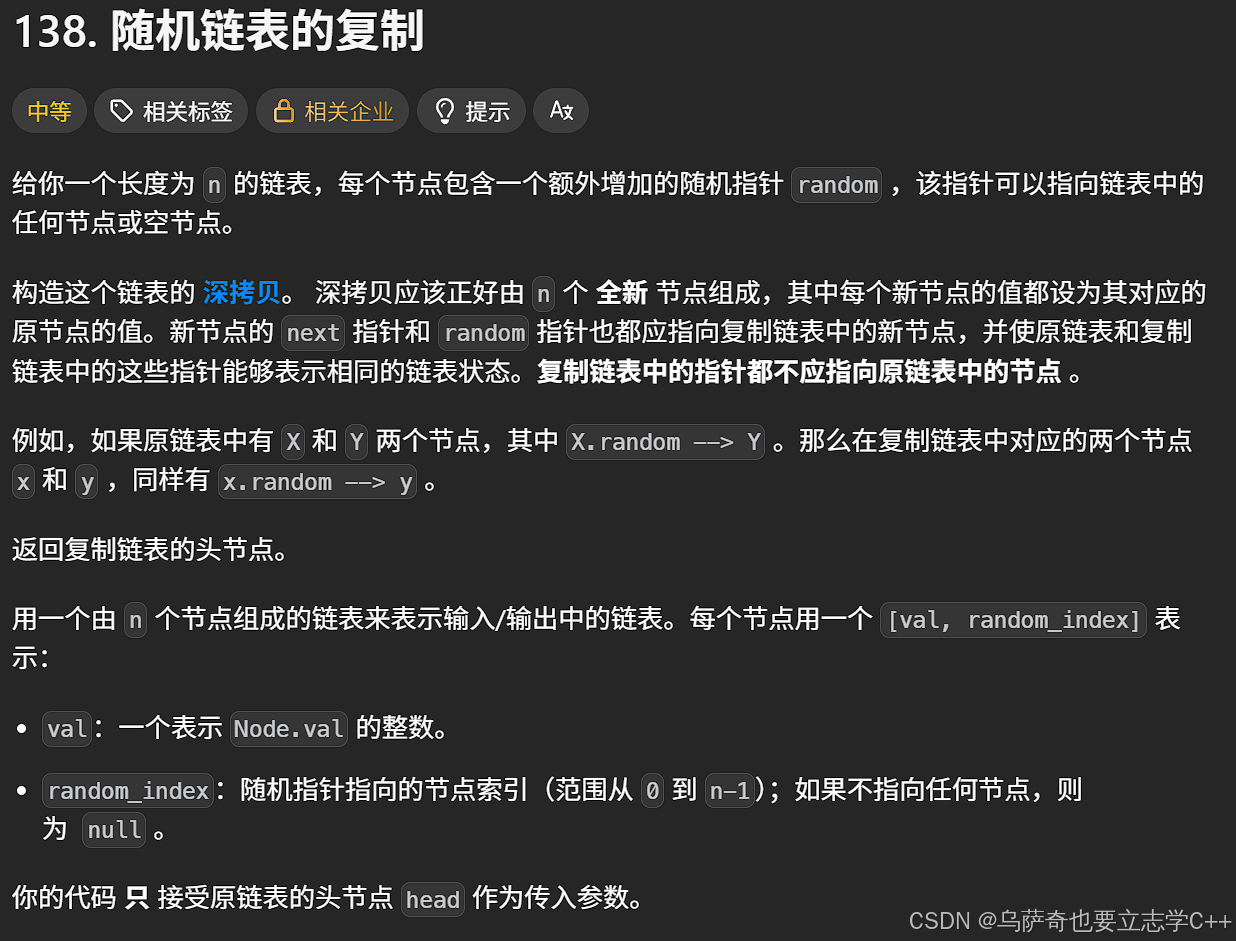
题目解析
这道题的主要矛盾就是要解决如何在拷贝链表里找到和原链表对应的结点,因为拷贝链表里结点的指针是随机的。原始思路是将拷⻉结点链接在原节点的后⾯解决,后⾯拷⻉节点还得与原链表解下连接,⾮常⿇烦。这里我们有了map后就可以将原链表结点与拷贝链表结点建立映射关系,就可以很轻松的控制随机指针问题。
思路是首先把原链表的主体结构拷贝下来,random指针留着后面解决。在拷贝时就把拷贝的结点和原链表中对应位置的结点建立映射关系,用map里operator 的插入+修改。
然后处理random指针,用两个指针cur和copycur分别从头开始遍历原链表和拷贝链表,当遇到原链表结点的random为空时把对应的拷贝链表的结点也置为空,当遇到原链表结点的random不为空时,就需要通过map的映射关系找到原链表结点的random指针指向的结点在拷贝链表里对应的结点,然后把copycur的random指针指向找到的结点。最后返回copyhead就行了。
代码
cpp
class Solution {
public:
Node* copyRandomList(Node* head) {
map<Node*,Node*> nodeMap;
Node* cur = head;
Node* copyhead = nullptr;
Node* copytail = nullptr;
//拷贝原链表+建立映射关系
while(cur != nullptr)
{
//拷贝第一个结点
if(copyhead == nullptr)
{
copyhead = copytail = new Node(cur->val);
}
else
{
copytail->next = new Node(cur->val);
copytail = copytail->next;
}
//key:cur value:copytail
nodeMap[cur] = copytail;
cur = cur->next;
}
//处理拷贝链表的random
//
cur = head;
Node* copycur = copyhead;
while(cur != nullptr)
{
if(cur->random == nullptr)
{
copycur->random = nullptr;
}
else
{
copycur->random = nodeMap[cur->random];
}
cur = cur->next;
copycur = copycur->next;
}
return copyhead;
}
};前K个高频单词
题目描述
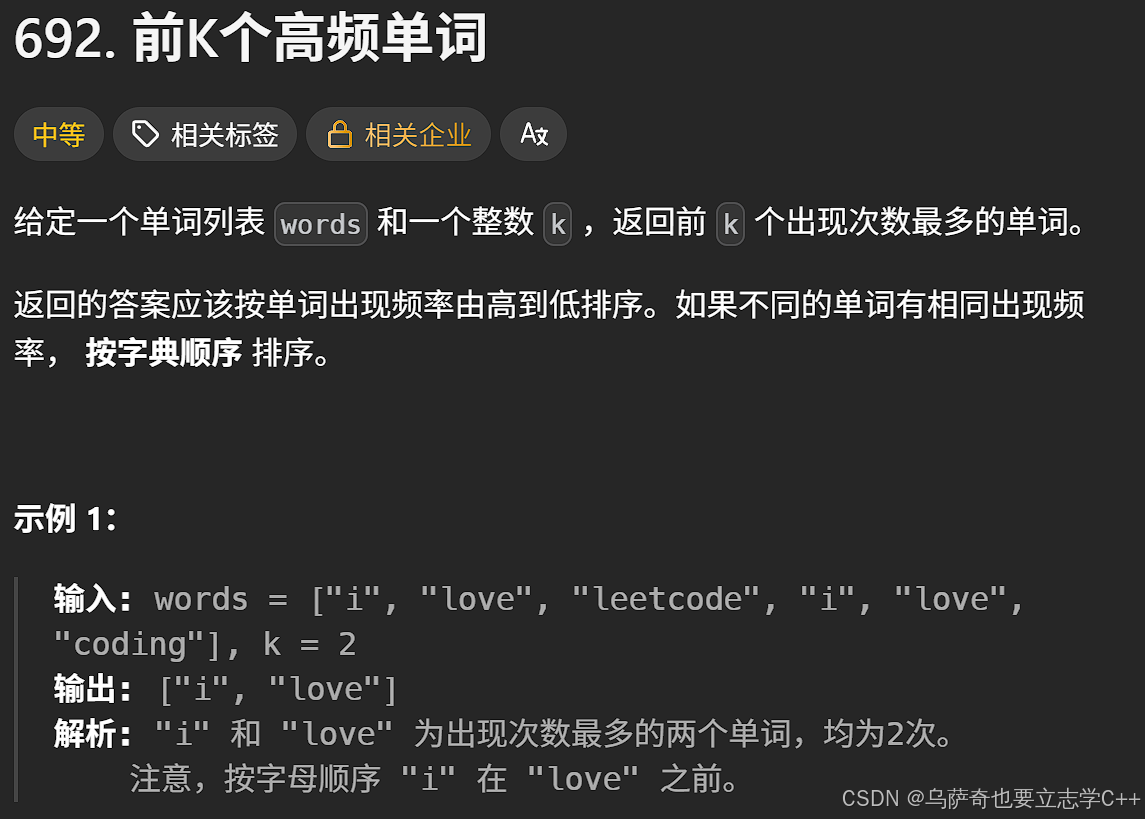
题目解析+代码
关于这道题小编先科普一个概念: 字典序
简单来说就是按照字典里单词排序的规则来比较字符串,核心逻辑和查字典时确定单词先后位置的方式一致。
基本规则:
1、逐字符对比 从字符串的第一个字符开始比较,若某一位字符不同,ASCII 码值小的字符串整体更小(靠前);
2、若前面字符都相同,则继续比较下一个字符,直到出现不同字符或其中一个字符串遍历结束;
3、若一个字符串是另一个的前缀(比如 "app" 和 "apple" ),则更短的字符串更小(靠前)。
法一:利用multimap这里有个想法map本身排序,那能不能把map<string, int> 导给 map<int,
string>在输出呢?其实是可行的,但是第二个map<int, string>必须是multimap,因为key有可能重复。
思路是首先把每个string的出现次数统计到countmap,countmap是以string来排序的,我们需要以int的大小来排序,所以以countmap的value为key插入sortmap,注意sortmap要传greater的模板参数,因为要统计value值大的。而且题目还有一个条件 "如果不同的单词有相同出现频率, 按字典顺序排序",而map天然就可以解决这个问题,首先统计次数时countmap比较逻辑就是按照string比的,而string的比较逻辑和字典序的一样,虽然countmap里的value值是随机的,但是countmap里的key是以string也就是字典序排的升序。那么我们想要保证结果最后按字典序排,那么第二个排序步骤需要用稳定的排序,不能打乱了countmap里的已经排好了的相对顺序。而这里我们用multimap排序恰好间接保证了结果的相对顺序不会改变,由于countmap 遍历顺序是 单词字典序升序,当多个单词频率相同时:
它们会按字典序升序的顺序被插入 sortmap;
sortmap在频率相同(键等价)时,会保留这个字典序升序的插入顺序。 (频率不同的还是正常降序)
最终,sortmap 中频率相同的单词,自然按字典序升序排列,间接满足了题目要求。
但是这种写法是巧合成立,而非逻辑上的严格保证,所以这种方法不推荐。
cpp
class Solution {
public:
vector<string> topKFrequent(vector<string>& words, int k) {
//统计次数
map<string, int> countmap;
for(auto& e : words)
{
countmap[e]++;
}
//以countmap的value为key插入sortmap
multimap<int, string, greater<int>> sortmap;
for(auto& e : countmap)
{
sortmap.insert({e.second, e.first});
}
//把sortmap前K个最大的插入vector
vector<string> rv;
auto it = sortmap.begin();
while(k--)
{
rv.push_back(it->second);
it++;
}
return rv;
}
};法二:利用算法库里的sort
还是先把每个string的出现次数统计到countmap,然后用sort给countmap排序,但是这里不能直接用countmap的迭代器给sort,因为sort需要随机迭代器,而map是双向迭代器,所以需要先把map里的pair类型数据用一个vector<pair<string,int>>存储起来,然后把vector的迭代器传给sort,这里sort排序还需要用到仿函数,虽然pair本身支持比较大小,但是pair自带的比较大小逻辑是先比较first,若first相等那么second的比较结果就是pair的比较结果。所以我们需要自己实现一个仿函数以pair的second作为比较大小的标准,并且排降序。还需要注意一点,这里我们不能直接用sort排序,因为sort底层是快排,是不稳定的,这里有两个解决方法,第一个用stable_sort,它的底层是归并,稳定的排序,因为我们这里不能破坏countmap里的相对顺序。
cpp
struct comp
{
bool operator()(const pair<string, int>& x1, const pair<string, int>& x2)
{
return x1.second > x2.second;
}
};
class Solution {
public:
vector<string> topKFrequent(vector<string>& words, int k) {
//统计次数
map<string, int> countmap;
for (auto& e : words)
{
countmap[e]++;
}
//数据导给v1,然后通过sort排降序
vector<pair<string, int>> v1(countmap.begin(), countmap.end());
stable_sort(v1.begin(), v1.end(), comp());
//把前K大的string给给v2然后返回
vector<string> v2;
auto it1 = v1.begin();
while (k--)
{
v2.push_back(it1->first);
it1++;
}
return v2;
}
};第二个就是用仿函数控制比较逻辑也可以解决sort不稳定的问题。
cpp
struct comp
{
bool operator()(const pair<string,int>& x1, const pair<string,int>& x2)
{
if(x1.second == x2.second)
return x1.first < x2.first;
else
return x1.second > x2.second;
}
};
class Solution {
public:
vector<string> topKFrequent(vector<string>& words, int k) {
//统计次数
map<string, int> countmap;
for(auto& e : words)
{
countmap[e]++;
}
//数据导给v1,然后通过sort排降序
vector<pair<string,int>> v1(countmap.begin(),countmap.end());
sort(v1.begin(), v1.end(), comp());
//把前K大的string给给v2然后返回
vector<string> v2;
auto it1 = v1.begin();
while(k--)
{
v2.push_back(it1->first);
it1++;
}
return v2;
}
};法三:利用priority_queue
这里也可以用priority_queue来排序,这道题数据量不算大,不用上Top-K,直接建个大堆top/pop k次取堆顶数据就行了,唯一需要注意的点就是priority_queue的仿函数的比大小逻辑是和我们正常逻辑相反的,正常排升序仿函数比较逻辑是 < ,而priority_queue要排升序也就是建小堆仿函数比较逻辑是 > (注意这里不是堆排序的建堆逻辑!),所以我们需要把sort的仿函数里的两个大小于号取反。
总结:priority_queue传greater建小堆,传less建大堆,sort是传greater排降序,传less排升序
cpp
struct comp
{
bool operator()(const pair<string,int>& x1, const pair<string,int>& x2)
{
if(x1.second == x2.second)
return x1.first > x2.first;
else
return x1.second < x2.second;
}
};
class Solution {
public:
vector<string> topKFrequent(vector<string>& words, int k) {
//统计次数
map<string, int> countmap;
for (auto& e : words)
{
countmap[e]++;
}
//用priority_queue建大堆,直接top不用Top-K
priority_queue<pair<string,int>,vector<pair<string,int>>, comp> q1(countmap.begin(), countmap.end());
vector<string> retv;
while(k--)
{
retv.push_back(q1.top().first);
q1.pop();
}
return retv;
}
};以上就是小编分享的全部内容了,如果觉得不错还请留下免费的赞和收藏
如果有建议欢迎通过评论区或私信留言,感谢您的大力支持。
一键三连好运连连哦~~
