基于Django的豆瓣图书推荐系统设计与实现
📋 目录
🎯 项目概述
本项目是一个基于Django框架开发的豆瓣图书推荐系统,集成了数据爬取、用户管理、图书推荐、数据可视化等功能。系统采用协同过滤算法为用户提供个性化图书推荐,并通过丰富的图表展示图书数据的多维度分析。
主要特性
- 🔍 智能推荐:基于矩阵分解的协同过滤算法
- 📊 数据可视化:丰富的图表和词云展示
- 🕷️ 数据采集:自动化爬取豆瓣图书信息
- 👥 用户管理:完整的用户注册登录系统
- 📱 响应式设计:适配多种设备屏幕
项目获取
码界筑梦坊 各大平台同名 文章底部含联系方式卡片
项目展示
项目视频演示见
基于Python的图书数据分析推荐系统

🛠️ 技术栈介绍
后端技术
- Django 3.1.14 - 核心Web框架
- Python 3.x - 主要开发语言
- MySQL - 数据库存储
- PyMySQL - 数据库连接器
数据采集与处理
- Requests 2.31.0 - HTTP请求库
- LXML 4.9.3 - HTML解析
- Pandas 1.4.3 - 数据处理
- NumPy 1.23.1 - 数值计算
机器学习与推荐
- 矩阵分解算法 - 协同过滤推荐
- 随机梯度下降 - 模型优化
- jieba 0.42.1 - 中文分词
数据可视化
- Matplotlib 3.5.2 - 图表生成
- WordCloud 1.8.2.2 - 词云制作
- ECharts - 前端图表库
前端技术
- HTML5/CSS3 - 页面结构
- JavaScript/jQuery - 交互逻辑
- Bootstrap - UI框架
- SimpleUI - 后台管理美化
🏗️ 系统架构设计
项目结构
book/
├── djangoProject/ # Django项目根目录
│ ├── djangoProject/ # 项目配置
│ │ ├── settings.py # 项目设置
│ │ ├── urls.py # URL路由
│ │ └── wsgi.py # WSGI配置
│ ├── myApp/ # 主应用
│ │ ├── models.py # 数据模型
│ │ ├── views.py # 视图函数
│ │ ├── urls.py # 应用路由
│ │ └── templates/ # 模板文件
│ ├── spider/ # 数据爬虫
│ │ └── spiderMain.py # 爬虫主程序
│ ├── model/ # 推荐算法
│ │ └── index.py # 矩阵分解算法
│ ├── utils/ # 工具函数
│ │ ├── getChartData.py # 图表数据
│ │ └── getPublicData.py # 公共数据
│ ├── static/ # 静态资源
│ │ ├── css/ # 样式文件
│ │ ├── js/ # JavaScript文件
│ │ └── cloudImg/ # 词云图片
│ └── requirements.txt # 依赖包架构模式
系统采用Django的MVT(Model-View-Template)架构模式:
- Model(模型):定义数据结构和数据库操作
- View(视图):处理业务逻辑和用户请求
- Template(模板):负责页面展示和用户交互
🗄️ 数据库设计
核心数据模型
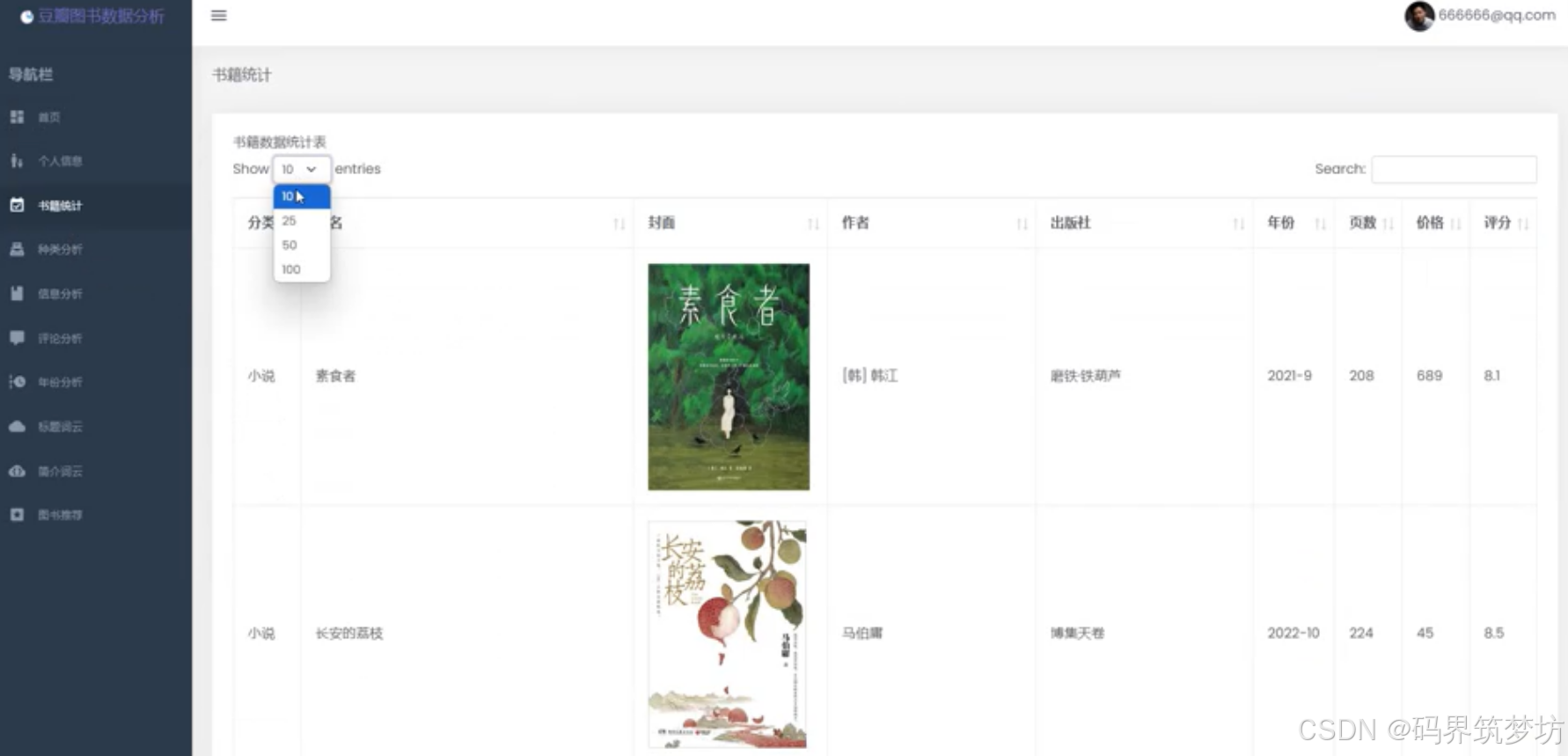
1. 图书信息表(BookList)
python
class BookList(models.Model):
id = models.AutoField("id", primary_key=True)
bookId = models.CharField("书籍编号", max_length=255, default='')
tag = models.CharField("类型", max_length=255, default='')
title = models.CharField("书名", max_length=255, default='')
cover = models.CharField("封面", max_length=2555, default='')
author = models.CharField("作者", max_length=255, default='')
press = models.CharField("出版社", max_length=255, default='')
year = models.CharField("出版年份", max_length=255, default='')
pageNum = models.CharField("页码", max_length=255, default='')
price = models.CharField("价格", max_length=255, default='')
rate = models.CharField("评分", max_length=255, default='')
startList = models.CharField("星级列表", max_length=255, default='')
summary = models.TextField("描述", default='')
detailLink = models.CharField("详情链接", max_length=2555, default='')
createTime = models.CharField("创建时间", max_length=2555, default='')
comment_len = models.CharField("评论数量", max_length=255, default='')
commentList = models.TextField("评论列表", default='')2. 用户表(User)
python
class User(models.Model):
id = models.AutoField("id", primary_key=True)
username = models.CharField("用户名", max_length=255, default='')
password = models.CharField("密码", max_length=255, default='')
creatTime = models.DateField("创建时间", auto_now_add=True)3. 用户评分表(UserBookRating)
python
class UserBookRating(models.Model):
user = models.ForeignKey('User', on_delete=models.CASCADE)
book = models.ForeignKey('BookList', on_delete=models.CASCADE)
rating = models.FloatField("评分")
created_at = models.DateTimeField("评分时间", auto_now_add=True)数据库配置
python
DATABASES = {
"default": {
"ENGINE": "django.db.backends.mysql",
"NAME": "design_douban_book",
"USER": "root",
"PASSWORD": "123456",
"HOST": "localhost",
"PORT": "3306"
}
}🔧 核心功能实现
1. 数据爬取模块
爬虫核心代码
python
class spider(object):
def __init__(self, tag, page):
self.tag = tag
self.page = page
self.spiderUrl = 'https://book.douban.com/tag/%s?start=%s'
self.headers = {
'HOST': 'book.douban.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
'Referer': 'https://book.douban.com/tag/',
'Cookie': '...'
}
def main(self):
# 获取图书列表页面
resq = requests.get(self.spiderUrl % (self.tag, self.page * 20), headers=self.headers)
respXpath = etree.HTML(resq.text)
li_list = respXpath.xpath('//ul[@class = "subject-list"]/li/div[2]/h2/a')
detailLinks = [x.xpath('@href')[0] for x in li_list]
# 遍历获取每本书的详细信息
for detail_link in detailLinks:
self.get_book_detail(detail_link)数据提取逻辑
python
def get_book_detail(self, detail_link):
respDetail = requests.get(detail_link, headers=self.headers)
respDetailXpath = etree.HTML(respDetail.text)
# 提取图书基本信息
title = respDetailXpath.xpath('//span[@property = "v:itemreviewed"]/text()')[0]
cover = respDetailXpath.xpath('//img[@rel = "v:photo"]/@src')[0]
author = respDetailXpath.xpath('//div[@id = "info"]/span[1]/a/text()')[0]
rate = respDetailXpath.xpath('//strong[@property="v:average"]/text()')[0].strip()
# 提取评论信息
comment_list = []
for comment in respDetailXpath.xpath('//ul/li[@class="comment-item"]'):
comment_data = self.extract_comment_data(comment)
comment_list.append(comment_data)2. 用户管理模块
用户注册
python
def register(request):
if request.method == "GET":
return render(request, 'register.html', {})
else:
uname = request.POST.get('username')
pwd = request.POST.get('password')
rePwd = request.POST.get('checkPassword')
# 验证用户名唯一性
try:
User.objects.get(username=uname)
messages.error(request, '账号已存在')
return HttpResponseRedirect('/myApp/register/')
except:
# 验证密码一致性
if pwd != rePwd:
messages.error(request, '两次密码不一致')
return HttpResponseRedirect('/myApp/register/')
else:
User.objects.create(username=uname, password=pwd)
return render(request, 'login.html', {})用户登录
python
def login(request):
if request.method == 'GET':
return render(request, 'login.html', {})
else:
uname = request.POST.get('username')
pwd = request.POST.get('password')
try:
user = User.objects.get(username=uname, password=pwd)
request.session['username'] = uname
return redirect('/myApp/home/')
except:
messages.error(request, '登录失败,请输入正确用户名与密码')
return HttpResponseRedirect('/myApp/login/')3. 数据可视化模块
图表数据生成
python
def getBookPriceData(defaultType):
typeBook = []
for i in bookList:
if defaultType == i.tag:
typeBook.append(i)
xData = ['50元', '100元', '150元', '200元', '300元', '300元以上']
yData = [x for x in range(len(xData))]
for i in typeBook:
if int(i.price) < 50:
yData[0] += 1
elif int(i.price) < 100:
yData[1] += 1
# ... 其他价格区间
return xData, yData词云生成
python
def get_img(field, targetImageSrc, resImageSrc):
# 连接数据库获取文本数据
conn = connect(host="localhost", user="root", passwd="123456",
database="design_douban_book", charset="utf8mb4")
cursor = conn.cursor()
sql = f"SELECT {field} FROM booklist"
cursor.execute(sql)
data = cursor.fetchall()
# 合并文本数据
text = ''
for i in data:
if i[0] != '':
text += i[0]
# 中文分词
data_cut = jieba.cut(text, cut_all=False)
string = ' '.join(data_cut)
# 生成词云
img = Image.open(targetImageSrc)
ima_arr = np.array(img)
wc = WordCloud(
background_color='#fff',
font_path='STHUPO.TTF',
mask=ima_arr
)
wc.generate_from_text(string)
plt.savefig(resImageSrc, dpi=800, bbox_inches='tight', pad_inches=-0.1)🧠 推荐算法详解
矩阵分解算法实现
核心算法类
python
class MF:
def __init__(self, R, k=2, alpha=0.1, beta=0.8, iterations=10):
"""
初始化矩阵分解模型
R: 用户-物品评分矩阵
k: 隐藏因子的数量
alpha: 学习率
beta: 正则化参数
iterations: 训练迭代次数
"""
self.R = R
self.k = k
self.alpha = alpha
self.beta = beta
self.iterations = iterations
self.num_users, self.num_items = R.shape
# 随机初始化用户矩阵P和物品矩阵Q
self.P = np.random.rand(self.num_users, self.k)
self.Q = np.random.rand(self.num_items, self.k)
# 偏置项
self.b_u = np.zeros(self.num_users)
self.b_i = np.zeros(self.num_items)
self.b = np.mean(R[R > 0])训练过程
python
def train(self):
"""使用随机梯度下降训练模型"""
for _ in range(self.iterations):
for i in range(self.num_users):
for j in range(self.num_items):
if self.R[i][j] > 0: # 只考虑用户评分过的物品
# 计算预测误差
eij = self.R[i][j] - self.full_matrix()[i][j]
# 更新隐因子
for f in range(self.k):
self.P[i][f] += self.alpha * (2 * eij * self.Q[j][f] - self.beta * self.P[i][f])
self.Q[j][f] += self.alpha * (2 * eij * self.P[i][f] - self.beta * self.Q[j][f])
# 更新偏置项
self.b_u[i] += self.alpha * (eij - self.beta * self.b_u[i])
self.b_i[j] += self.alpha * (eij - self.beta * self.b_i[j])推荐生成
python
def modelFn(each_user):
"""为指定用户生成推荐"""
startList = getAllData()
obs_dataset = [(user_id, item_id, rating) for user_id, item_id, rating in startList]
R = getUIMat(obs_dataset)
# 创建并训练模型
mf = MF(R, k=10, alpha=0.05, beta=0.02, iterations=50)
mf.train()
# 获取用户预测评分
user_ratings = mf.full_matrix()[each_user].tolist()
# 生成推荐列表
topN = [(i, user_ratings[i]) for i in range(len(user_ratings)) if R[each_user][i] == 0]
topN = sorted(topN, key=lambda x: x[1], reverse=True)
topN = [i[0] for i in topN[:12]]
return topN算法优势
- 处理稀疏数据:矩阵分解能有效处理用户-物品评分矩阵的稀疏性问题
- 隐因子学习:自动学习用户和物品的隐特征
- 可扩展性:算法复杂度相对较低,适合大规模数据
- 个性化推荐:为每个用户生成个性化的推荐列表
📊 数据可视化
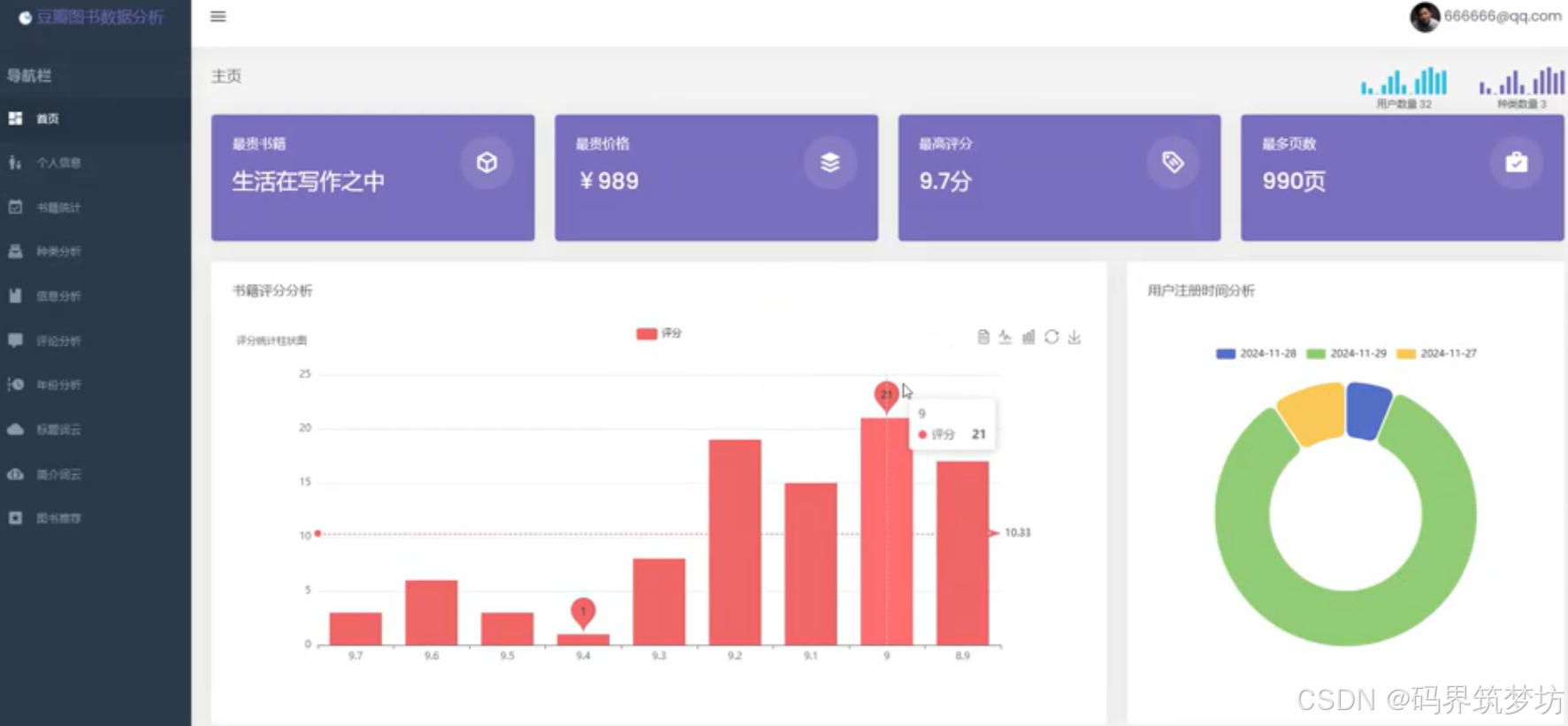
1. 首页统计面板
- 用户总数统计
- 图书类型数量
- 最高价图书信息
- 最高评分图书
- 最大页数图书
- 评分分布图表
- 用户注册趋势
- 最新评论展示
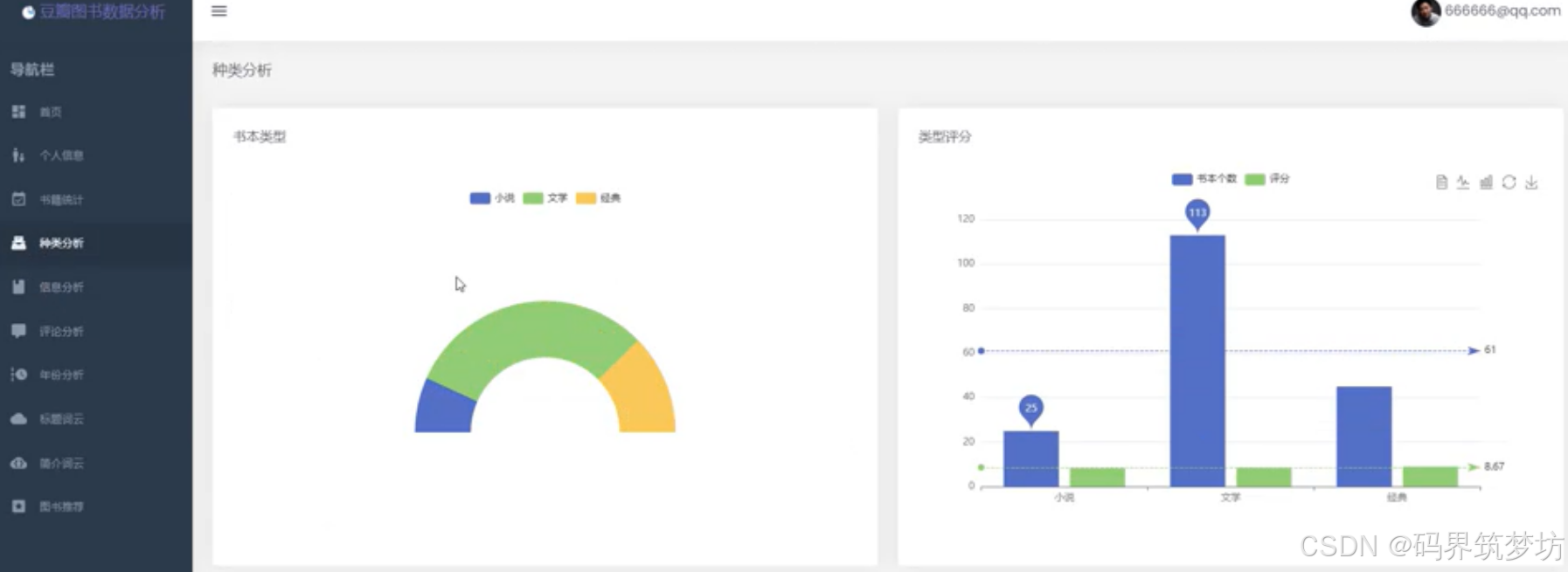
2. 图书类型分析
- 饼图展示各类型图书分布
- 柱状图展示各类型评分情况
- 支持交互式图表切换
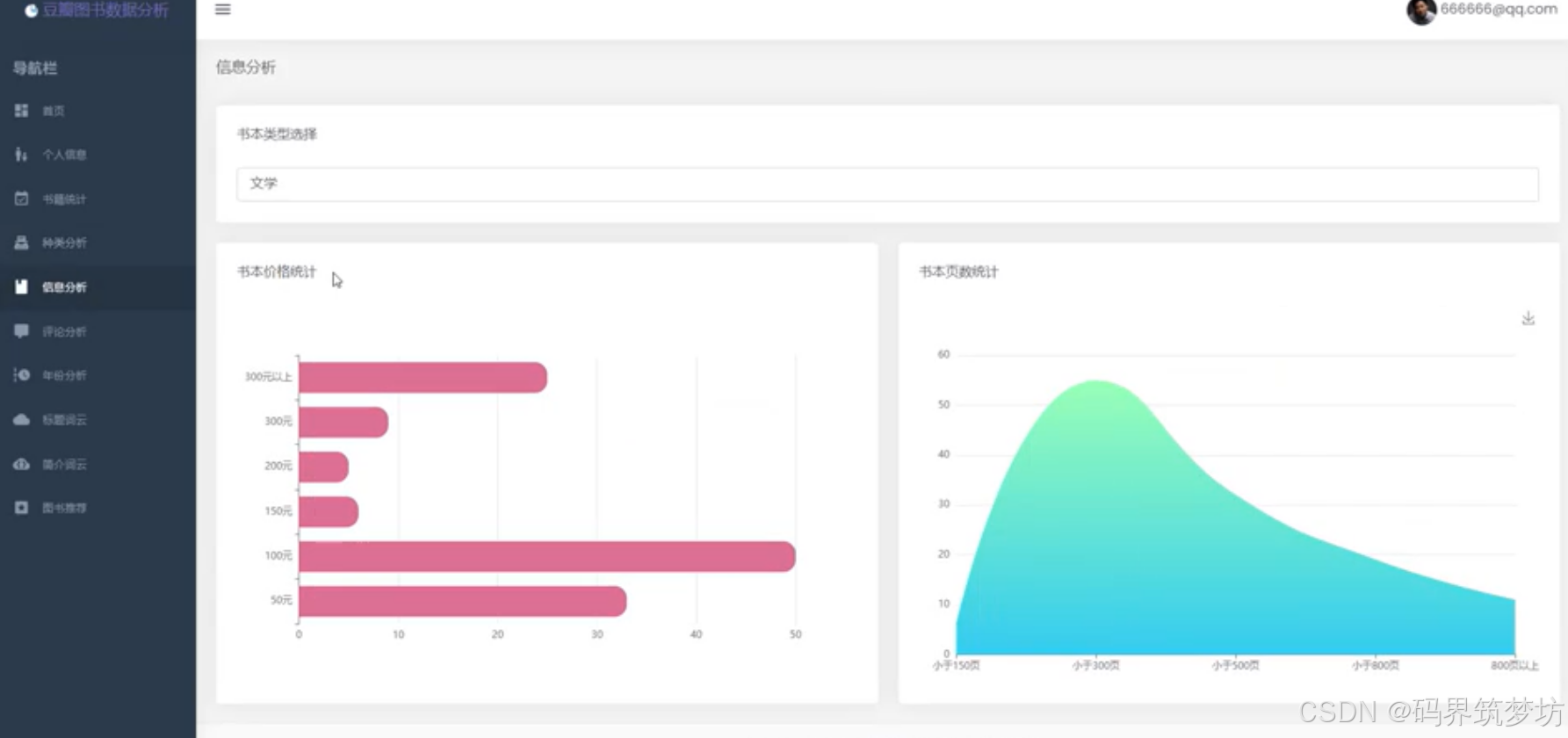
3. 价格与页数分析
- 按类型统计价格区间分布
- 按类型统计页数区间分布
- 支持类型切换进行对比分析
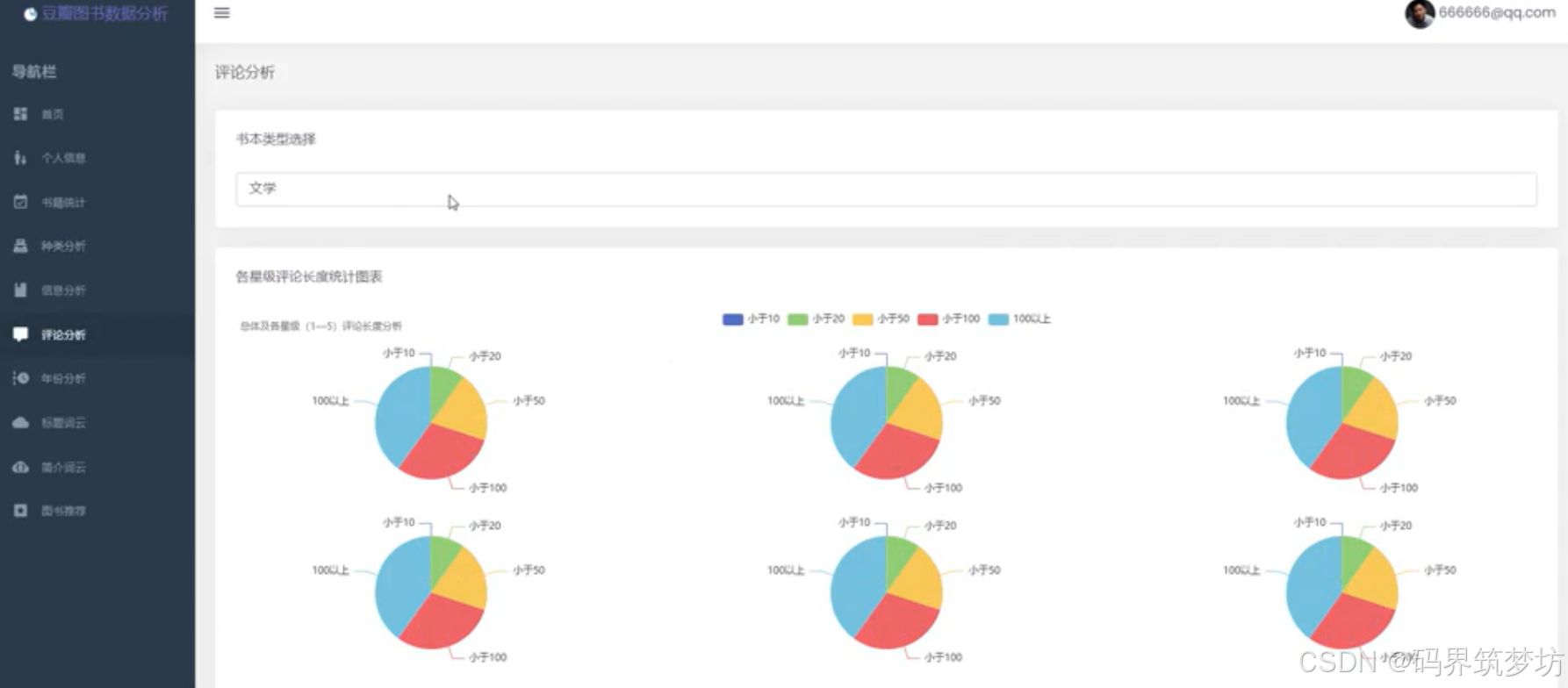
4. 评论分析
- 评论数量分布统计
- 不同星级评论内容长度分析
- 评论情感分析可视化
5. 词云展示
- 基于图书标题的词云
- 基于图书简介的词云
- 直观展示高频词汇
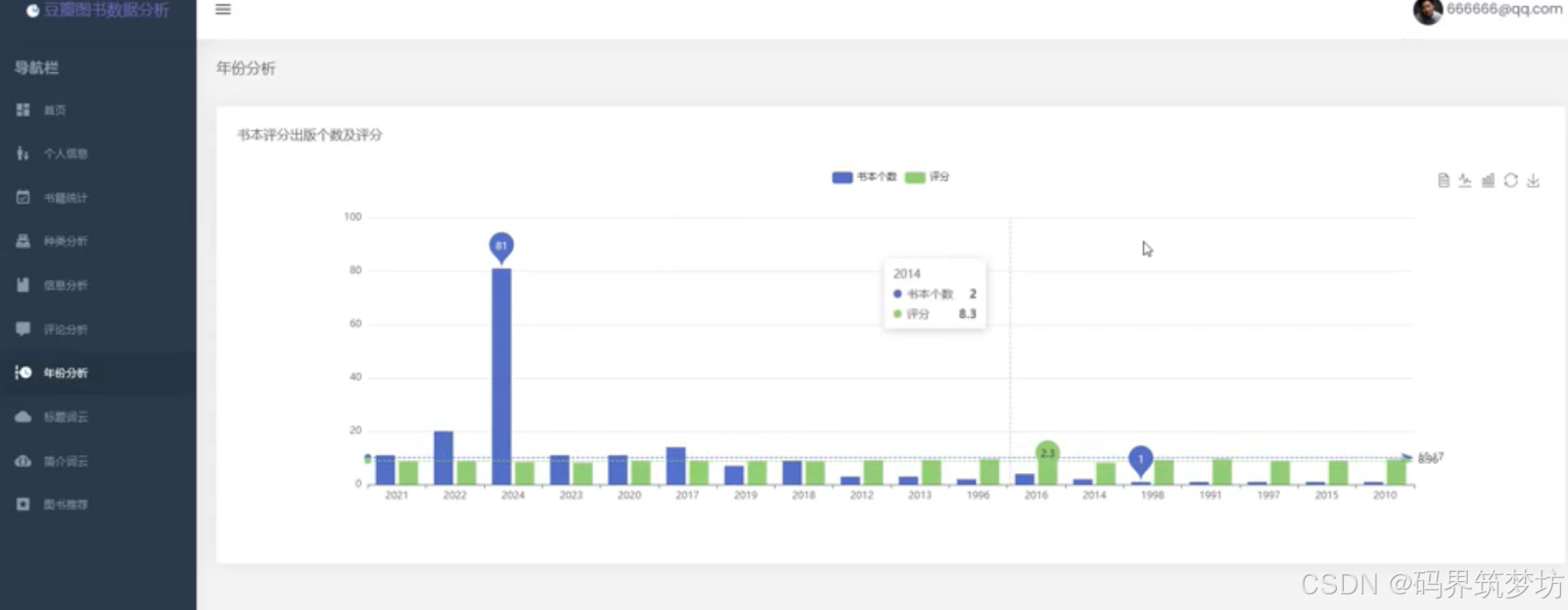
6. 年份分析
- 出版年份分布统计
- 各年份图书评分分析
- 时间趋势可视化
🚀 项目部署
环境要求
- Python 3.7+
- MySQL 5.7+
- Django 3.1.14
安装步骤
1. 克隆项目
bash
git clone [项目地址]
cd book/djangoProject2. 安装依赖
bash
pip install -r requirements.txt3. 数据库配置
sql
CREATE DATABASE design_douban_book CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;4. 数据库迁移
bash
python manage.py makemigrations
python manage.py migrate5. 启动服务
bash
python manage.py runserver配置说明
python
# settings.py 关键配置
DEBUG = True
ALLOWED_HOSTS = ['*']
LANGUAGE_CODE = "zh-hans"
TIME_ZONE = "Asia/Shanghai"
# 静态文件配置
STATIC_URL = "/static/"
STATICFILES_DIRS = (
os.path.join(BASE_DIR, 'static'),
)📈 系统功能展示
用户功能
- ✅ 用户注册与登录
- ✅ 个人信息管理
- ✅ 密码修改
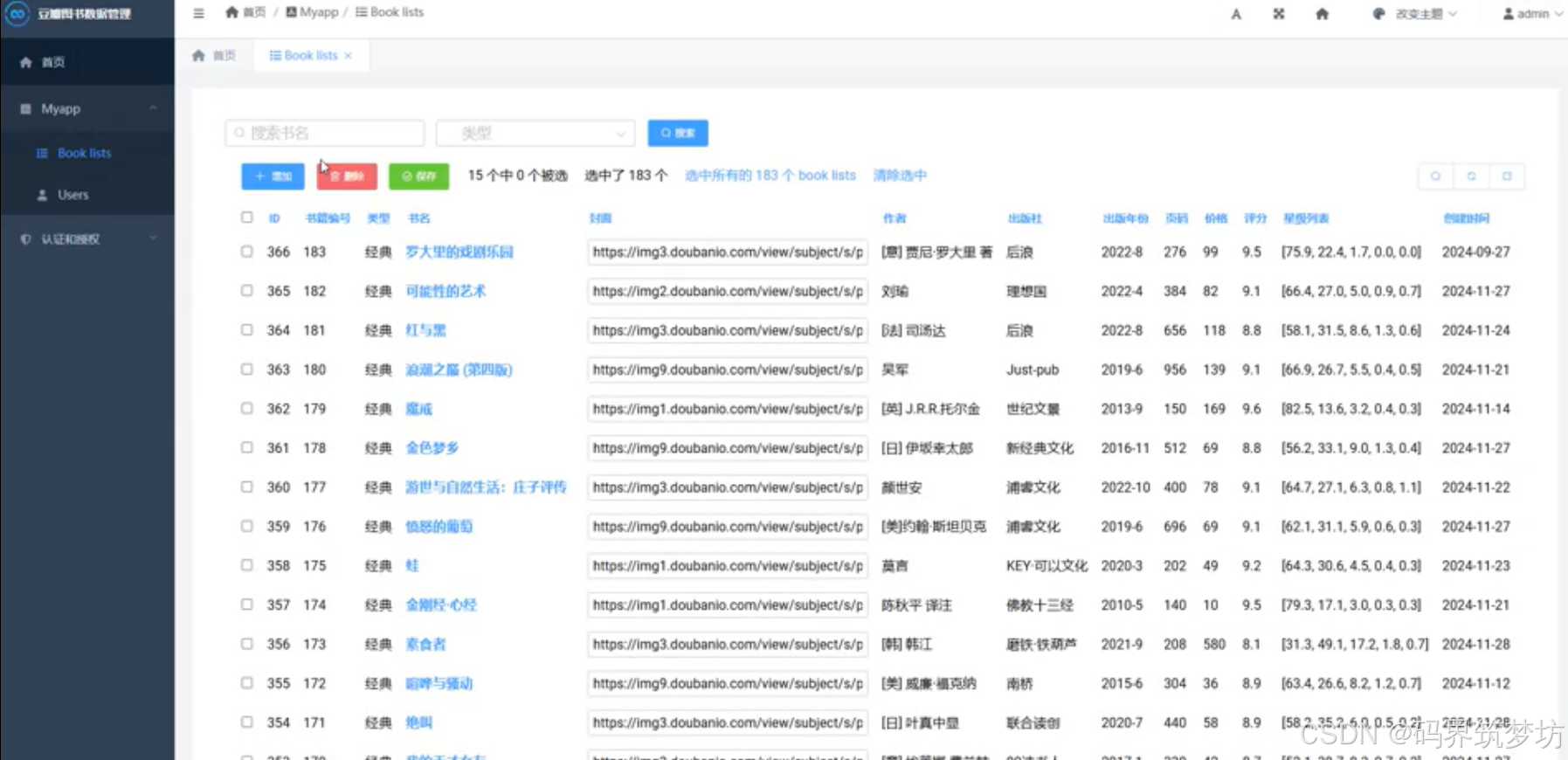
图书管理
- ✅ 图书信息浏览
- ✅ 图书搜索筛选
- ✅ 图书详情查看
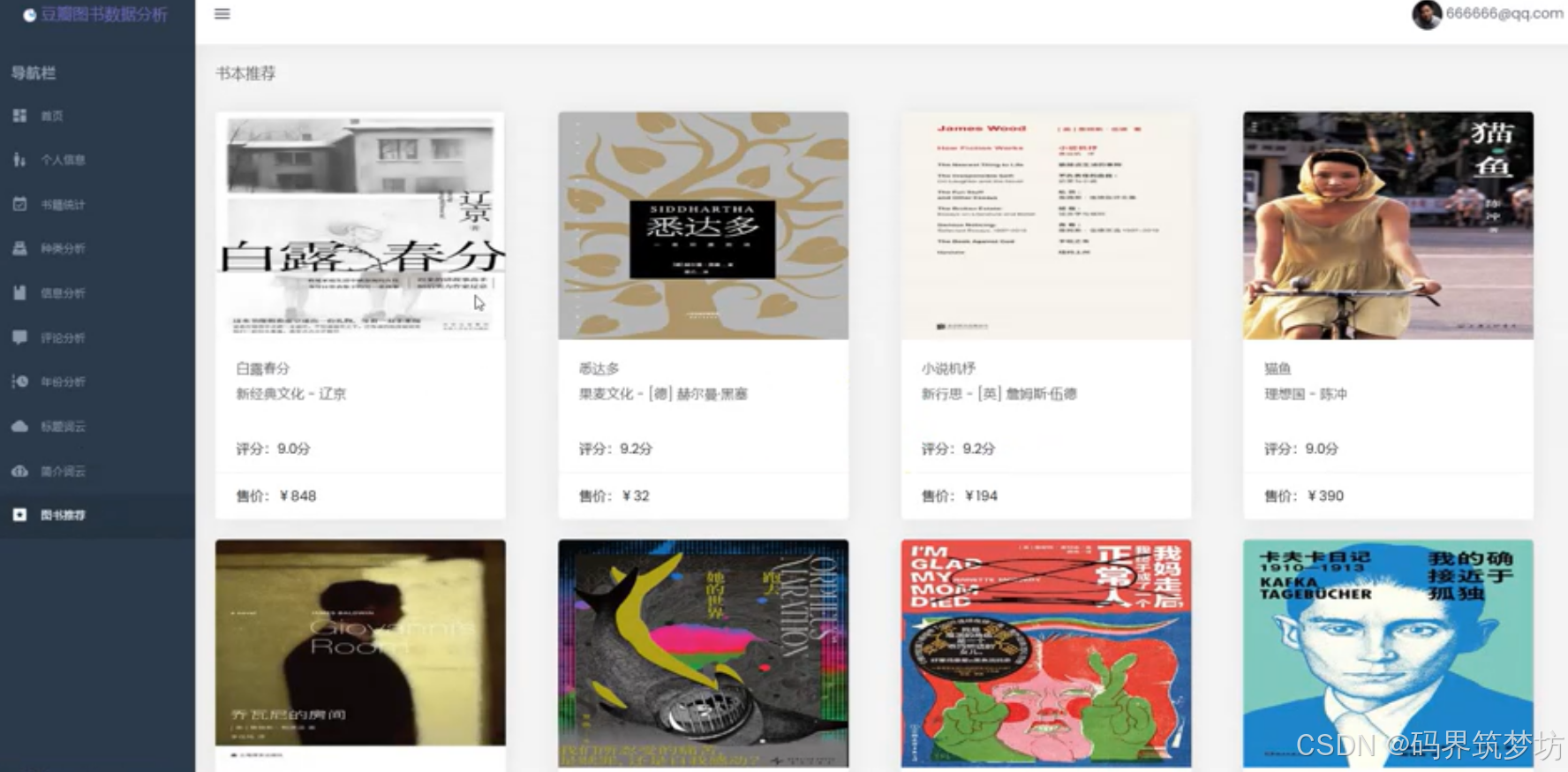
推荐系统
- ✅ 个性化图书推荐
- ✅ 基于协同过滤算法
- ✅ 推荐结果展示
数据分析
- ✅ 图书类型分布分析
- ✅ 价格与页数统计
- ✅ 评论数量与星级分析
- ✅ 出版年份趋势分析
- ✅ 词云可视化
数据采集
- ✅ 自动化爬取豆瓣图书
- ✅ 数据清洗与存储
- ✅ 评论信息提取
🎯 项目特色
1. 完整的推荐系统
- 实现了基于矩阵分解的协同过滤算法
- 支持个性化推荐和冷启动处理
- 推荐结果准确性和多样性并重
2. 丰富的数据可视化
- 多种图表类型支持
- 交互式数据展示
- 词云等创新可视化方式
3. 自动化数据采集
- 智能爬虫系统
- 数据清洗和验证
- 增量更新支持
4. 用户友好的界面
- 响应式设计
- 直观的操作流程
- 美观的UI设计
5. 可扩展的架构
- 模块化设计
- 易于维护和扩展
- 支持功能定制
🔮 总结与展望
项目成果
本项目成功实现了一个功能完整的豆瓣图书推荐系统,集成了数据采集、用户管理、推荐算法、数据可视化等多个模块。系统采用现代化的技术栈,具有良好的用户体验和扩展性。
技术亮点
- 算法创新:实现了基于矩阵分解的协同过滤算法
- 数据驱动:通过爬虫获取真实数据,保证推荐质量
- 可视化丰富:多种图表和词云展示,提升用户体验
- 架构合理:采用Django MVT架构,代码结构清晰
未来改进方向
- 算法优化:引入深度学习模型,提升推荐准确性
- 实时推荐:实现实时推荐系统,响应用户行为变化
- 多源数据:整合更多图书数据源,丰富推荐内容
- 移动端适配:开发移动端应用,提升用户体验
- 性能优化:优化数据库查询和缓存策略,提升系统性能
学习价值
本项目涵盖了Web开发、数据爬取、机器学习、数据可视化等多个技术领域,是学习全栈开发的优秀案例。通过本项目的学习,可以掌握:
- Django框架的完整开发流程
- 推荐算法的实现原理
- 数据可视化的多种方式
- 爬虫技术的实际应用
- 前后端分离的开发模式
📚 参考资料
本文档详细介绍了基于Django的豆瓣图书推荐系统的设计与实现,涵盖了技术栈、架构设计、核心功能、推荐算法等多个方面,为类似项目的开发提供了参考。