🧑 博主简介:曾任某智慧城市类企业算法总监,CSDN / 稀土掘金 等平台人工智能领域优质创作者。
目前在美国市场的物流公司从事高级算法工程师一职,深耕人工智能领域,精通python数据挖掘、可视化、机器学习等,发表过AI相关的专利并多次在AI类比赛中获奖。
一、引言
在数据分析的世界里,数据可视化是将复杂数据转化为直观图表的重要手段。今天,我们将使用Python和pyecharts库,对2025年中国大学综合排名数据进行可视化分析,打造一个炫酷的暗黑主题可视化大屏。我们的目标是让图表不仅具有视觉冲击力,还能提供有价值的洞察。
二、数据准备
首先,我们需要准备数据。数据来源于一个Excel文件,包含以下字段:排名、学校名称、类型、省份和分值。我们将使用Pandas库读取数据,并进行简单的清洗。
python
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import *
from pyecharts.globals import ThemeType
# 读取数据
df = pd.read_excel("2025年中国大学综合排名(前550名).xlsx")
# 数据清洗:去掉 * 号、类型空格
df["学校名称"] = df["学校名称"].str.replace("※", "").str.strip()
df["类型"] = df["类型"].str.strip()
df["分值"] = df["分值"].apply(lambda x: float(str(x).replace("\xa0", '')))三、可视化分析
我们将通过以下六种图表来展示数据:
- TOP30大学分数柱状图
- 各省高校数量极坐标玫瑰图
- 不同类型院校占比饼状图
- 各省份高校平均分值热力图
- 不同类型院校占比漏斗图
- 学校名称词云
最后,我们将所有图表整合到一个可移动的可视化大屏中。
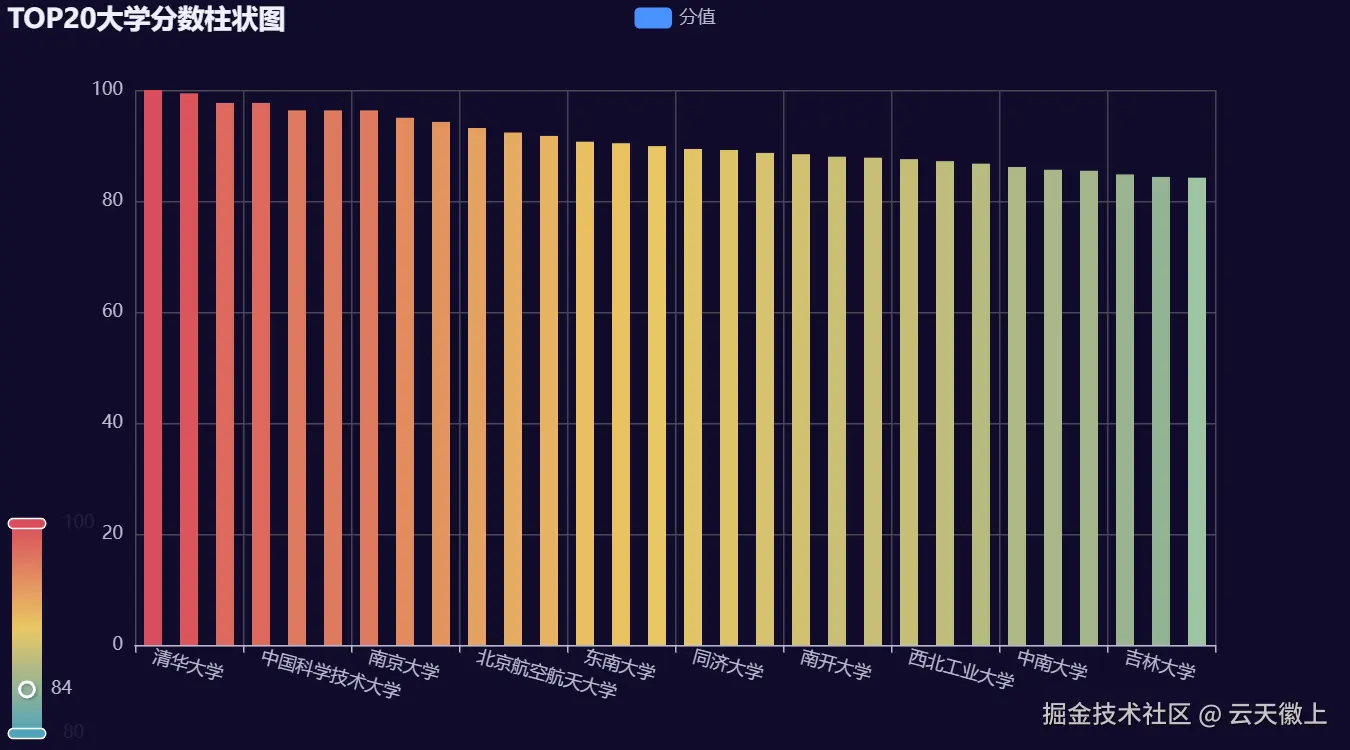
3.1 TOP30大学分数柱状图
柱状图可以直观地展示各大学的分值差异。我们将使用渐变色来增强视觉效果。
ini
top30 = df.head(30)
bar = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.DARK))
.add_xaxis(top30["学校名称"].tolist())
.add_yaxis("分值", top30["分值"].tolist(), category_gap="50%")
.set_global_opts(
title_opts=opts.TitleOpts(title="TOP30大学分数柱状图"),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15)),
visualmap_opts=opts.VisualMapOpts(is_show=True, max_=100, min_=80),
)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
)
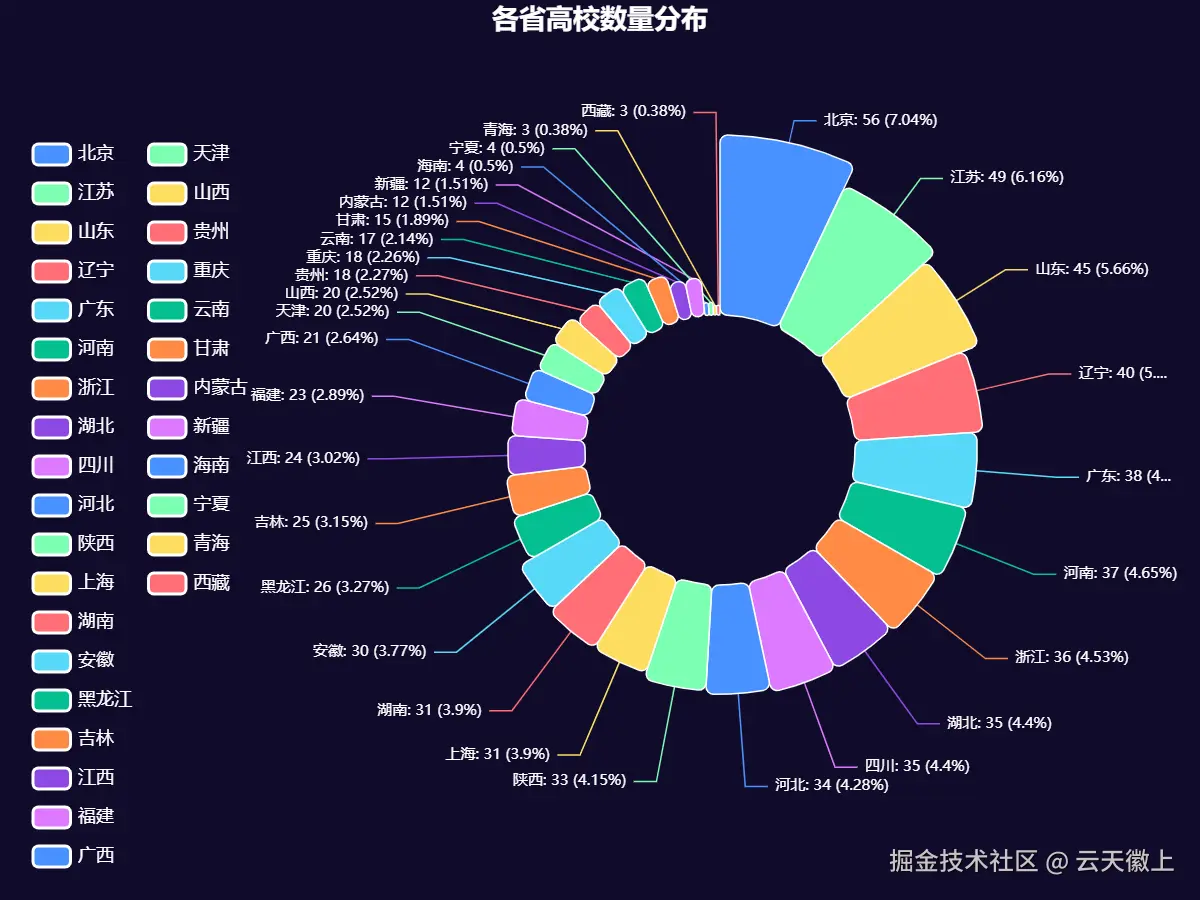
3.2 各省高校数量极坐标玫瑰图
极坐标玫瑰图可以展示各省高校的数量分布。我们将使用多种颜色来区分不同省份。
ini
province_count = df["省份"].value_counts().head(20)
rose = (
Pie()
.add(
series_name="高校数量",
data_pair=[list(z) for z in zip(province_count.index.tolist(), province_count.values.tolist())],
...
)
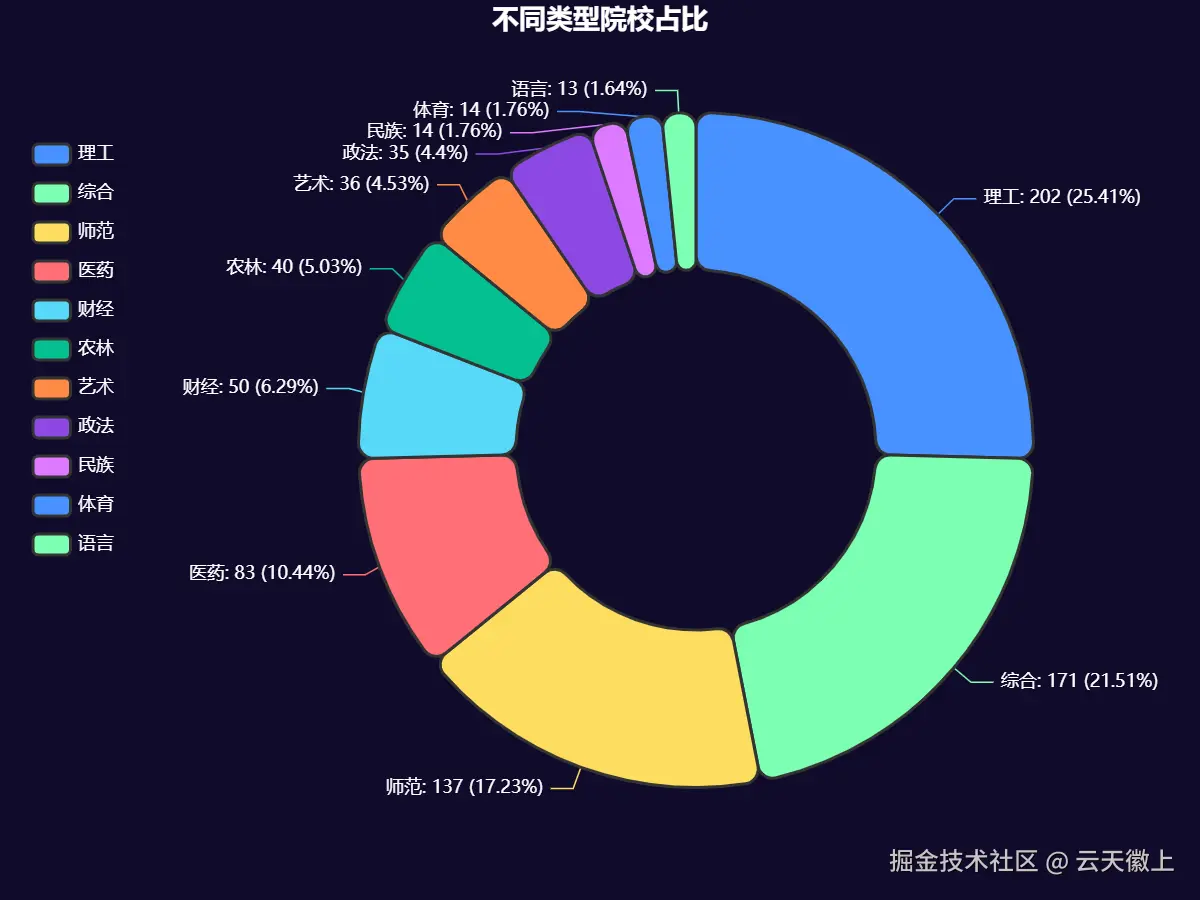
3.3 不同类型院校占比饼状图
饼状图可以展示不同类型院校的占比情况。我们将使用环形饼图来增强视觉效果。
ini
type_count = df["类型"].value_counts()
pie = (
Pie()
.add(
series_name="院校类型",
data_pair=[list(z) for z in zip(type_count.index.tolist(), type_count.values.tolist())],
...
)
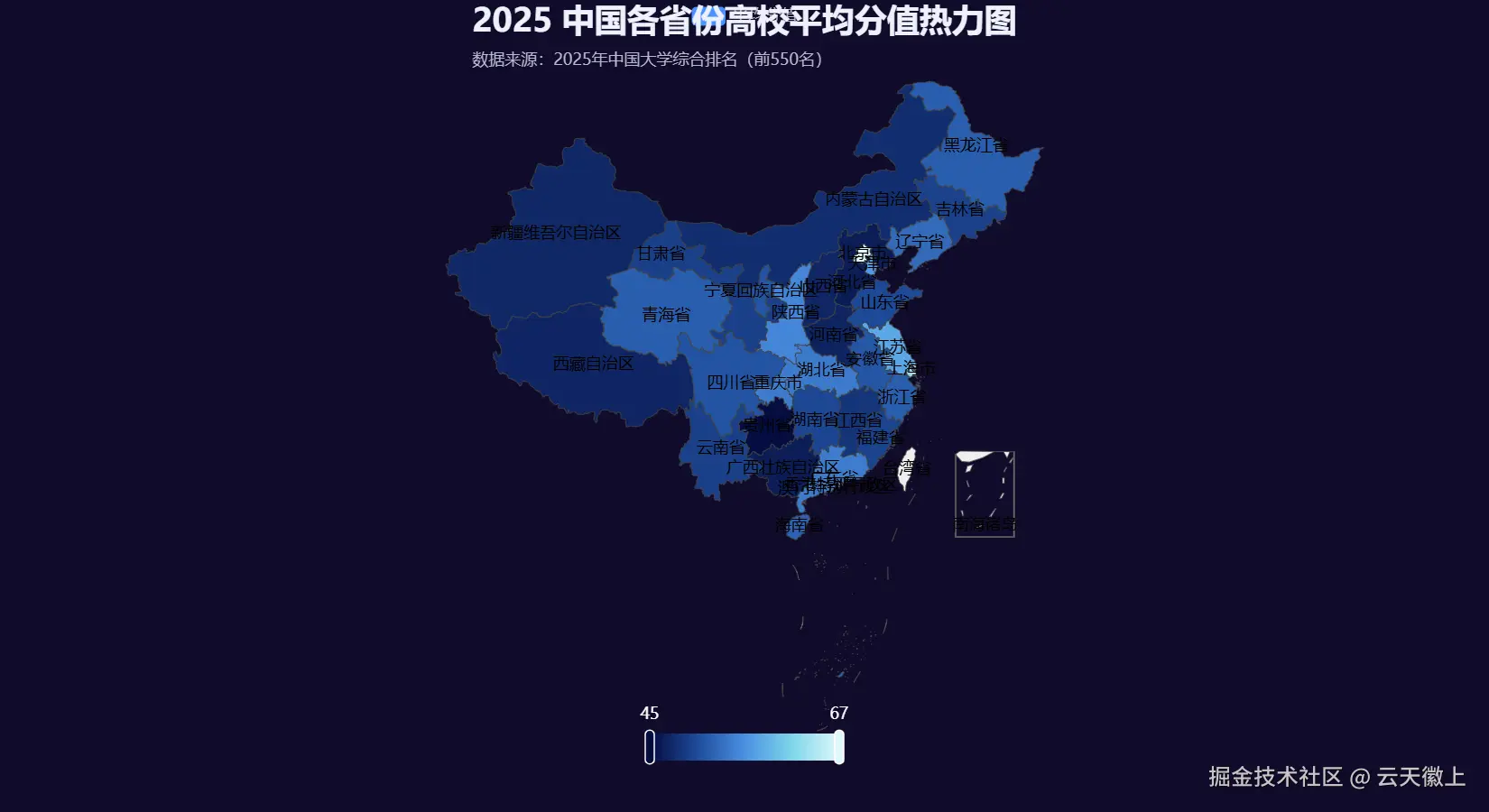
3.4 各省份高校平均分值热力图
热力图可以展示各省份高校的平均分值分布情况。我们将使用渐变色来增强视觉效果。
ini
province_dict = {
"北京": "北京市",
"上海": "上海市",
...
}
province_avg_score = df.groupby("省份")["分值"].mean().reset_index(name="平均分值")
...
map_chart = (
Map()
.add(
series_name="平均分值",
data_pair=data_pair,
maptype="china",
) ...
)
3.5 不同类型院校占比漏斗图
漏斗图可以展示不同类型院校的占比情况。我们将使用多种颜色来区分不同类型。
less
funnel = (
Funnel()
.add(
"类型",
[list(z) for z in zip(type_count.index, [int(i) for i in type_count.values()])]
...
)
3.6 学校名称词云
词云图可以展示学校名称的分布情况。我们将使用多种颜色来增强视觉效果。
less
wordcloud = (
WordCloud(init_opts=opts.InitOpts(theme=ThemeType.DARK))
.add(
"",
[list(z) for z in zip(df["学校名称"], df["分值"])]
)
...
)
四、可视化大屏
最后,我们将所有图表整合到一个可移动的可视化大屏中。
ini
from pyecharts.charts import Page
# 可视化大屏
page = (
Page(layout=Page.DraggablePageLayout)
.add(
bar,
rose,
pie,
map_chart,
funnel,
wordcloud,
)
.render("university_ranking_dashboard.html")
)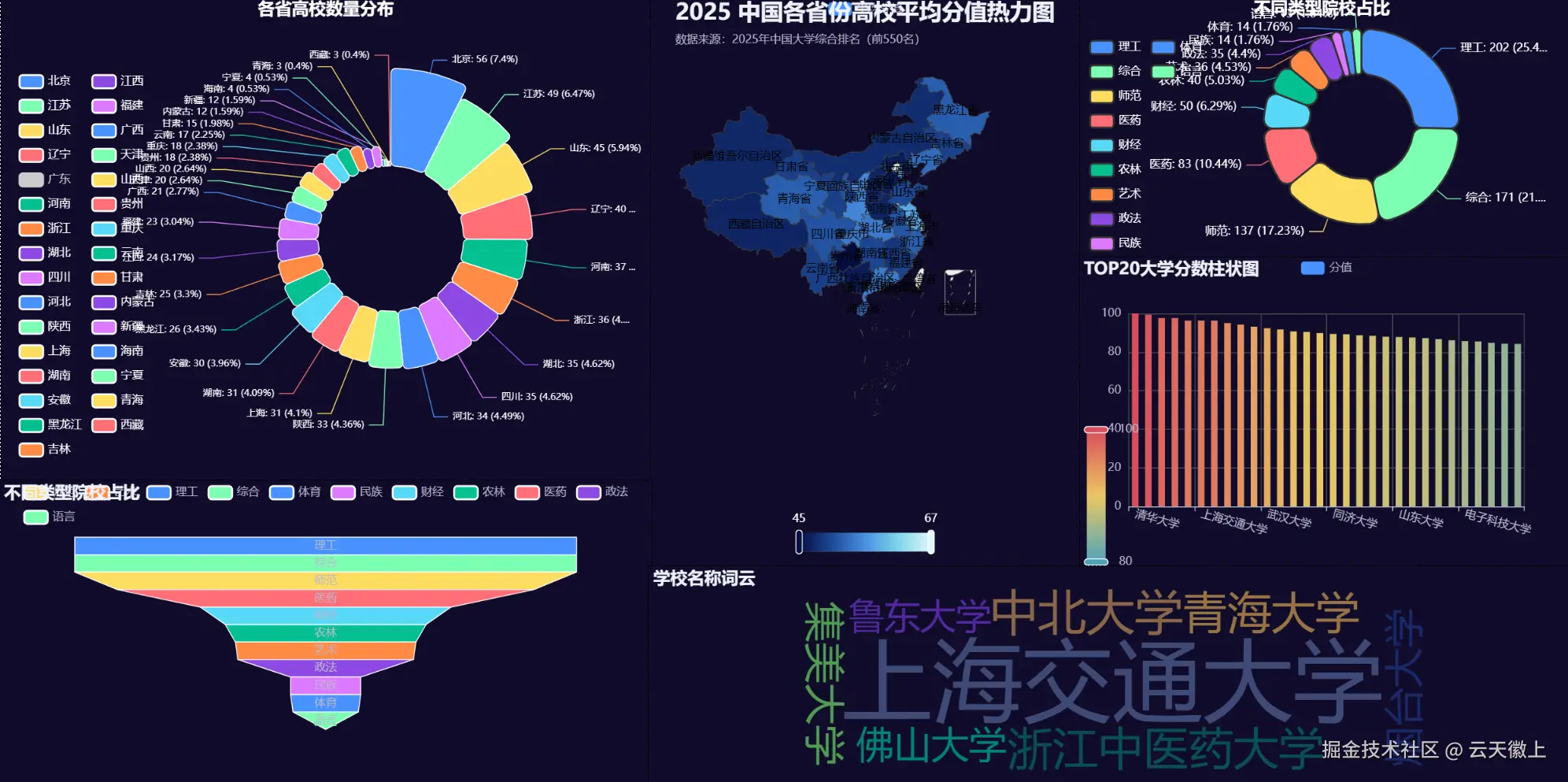
五、专业解读
从这些图表中,我们可以得出以下几点洞察:
- 分值梯度:TOP30 的大学分值明显高于其他大学,清华大学、北京大学和浙江大学/中国科学技术大学断层领先。
- 区域分布:北京、江苏、上海等地区的高校数量和质量均较高,而西部省份相对较少。
- 类型结构:理工类院校数量最多,综合类院校次之,师范类院校数量也较多,财经和医药类院校数量相对较少但分值较高。
- 热力图:高分值的省份主要集中在华北和华东地区,西部省份的分值相对较低。
六、结语
通过上述代码,我们成功地将2025年中国大学综合排名数据进行了可视化分析。我们使用了柱状图、极坐标玫瑰图、饼状图、热力图、漏斗图和词云等多种图表类型,展示了数据的不同维度。这些图表不仅具有视觉冲击力,还能够帮助我们更好地理解数据的分布和特征。
希望这篇文章对你有所帮助!如果你有任何问题或建议,欢迎在评论区留言。
如果您在人工智能领域遇到技术难题,或是需要专业支持,无论是技术咨询、项目开发还是个性化解决方案,我都可以为您提供专业服务,如有需要可站内私信或添加下方VX名片(ID:xf982831907)
期待与您一起交流,共同探索AI的更多可能!