🚴♂️ 用 Pandas 分析自行车租赁数据:从时间序列到天气影响的完整实训
大家好,欢迎来到本期的数据分析实战分享!
今天我们要一起完成一个非常有趣又实用的 Pandas 时间序列分析实训 ------以自行车租赁统计数据为例,探究租车数量随时间与天气变化的规律。这不仅是一个经典的入门级项目,更是理解真实世界中数据行为的重要一步。
本实训所用数据来自 Kaggle 上的经典数据集 Bike Sharing Demand,我们将在 Jupyter Notebook 环境下一步步完成数据清洗、可视化与趋势分析。
🔧 实训目标
-
使用 Pandas 进行时间序列数据处理;
-
探索自行车租赁数随时间(年、月、小时)的变化趋势;
-
分析天气对租车需求的影响;
-
学会使用
resample()、groupby()、describe()等核心方法进行数据分析; -
利用 Seaborn 和 Matplotlib 可视化结果。
📥 第一步:导入模块
首先,我们需要导入必要的 Python 库:
python
import numpy as np
import pandas as pd
import datetime
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline❝
✅
matplotlib inline是 Jupyter 中的关键指令,确保图表直接显示在 notebook 中。
📂 第二步:获取并查看数据
我们将数据从 bike.csv 文件中读取进来,并查看前几行:
python
bike = pd.read_csv('bike.csv')
bike.head()输出如下:
python
datetime season holiday workingday weather temp atemp humidity windspeed casual registered count
0 2011-01-01 00:00:00 1 0 0 1 9.84 14.395 81 0.00 3 13 16
1 2011-01-01 01:00:00 1 0 0 1 9.02 13.635 80 0.00 8 32 40
2 2011-01-01 02:00:00 1 0 0 1 9.02 13.635 80 0.00 5 27 32
3 2011-01-01 03:00:00 1 0 0 1 9.84 14.395 75 0.00 3 10 13
4 2011-01-01 04:00:00 1 0 0 1 9.84 14.395 75 0.00 0 1 1可以看到每条记录包含时间戳、季节、是否节假日、天气状况、温度、湿度等信息,以及最终的租车总数(count)。
🔍 第三步:分析数据
(1)查看数据类型
python
bike.info()输出显示共有 10886 条记录,12 列数据。其中 datetime 字段为 object 类型,其他多为整型或浮点型。
(2)将 datetime 转换为日期时间格式
为了后续的时间序列操作,必须将其转换为 datetime64 类型:
python
bike.datetime = pd.to_datetime(bike.datetime)
bike.dtypes现在 datetime 的类型变为 datetime64[ns],可用于时间索引和重采样。
(3)设置 datetime 为索引,并观察租赁数密度分布
python
bike = bike.set_index('datetime')
sns.distplot(bike["count"])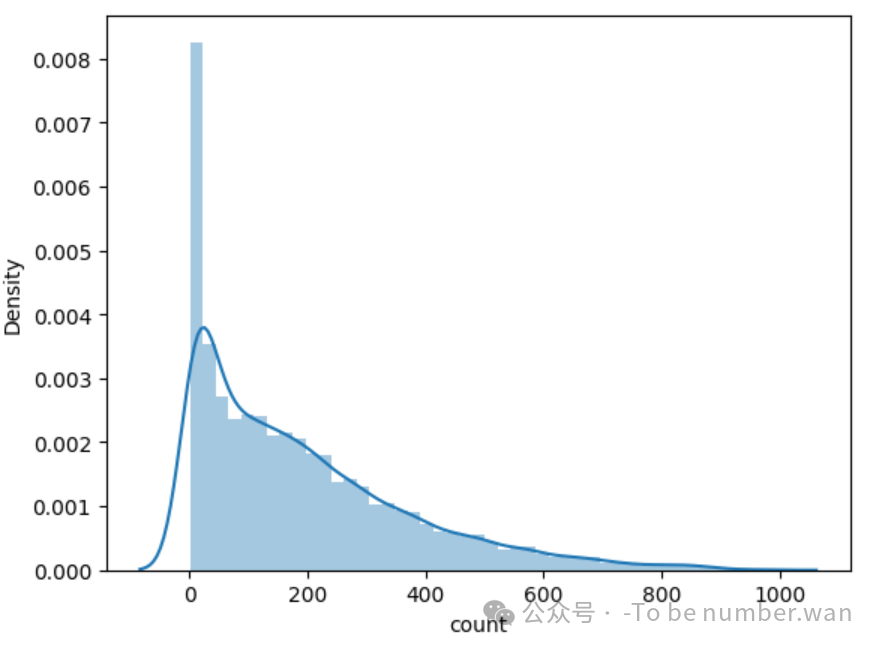
❝
💡 结果发现存在明显的长尾现象------少数时段租车量极高,大多数集中在较低区间。
(4)查看 count 字段描述性统计
python
bike["count"].describe()输出:
python
count 10886.000000
mean 191.574132
std 181.144454
min 1.000000
25% 42.000000
50% 145.000000
75% 284.000000
max 977.000000
Name: count, dtype: float64可以看出,第一四分位数(25%)是 42,而最小值仅为 1,说明数据中存在异常低值。
(5)去除小于第一四分位数的数据,重新绘图
我们定义一个函数来过滤掉低于 145 的数据:
python
def Count(x):
if x < 145:
return np.nan
else:
return x
bike1 = bike.copy()
bike1["count"] = bike1["count"].apply(Count)
bike1 = bike1.dropna(axis=0, how='any')
sns.distplot(bike1["count"])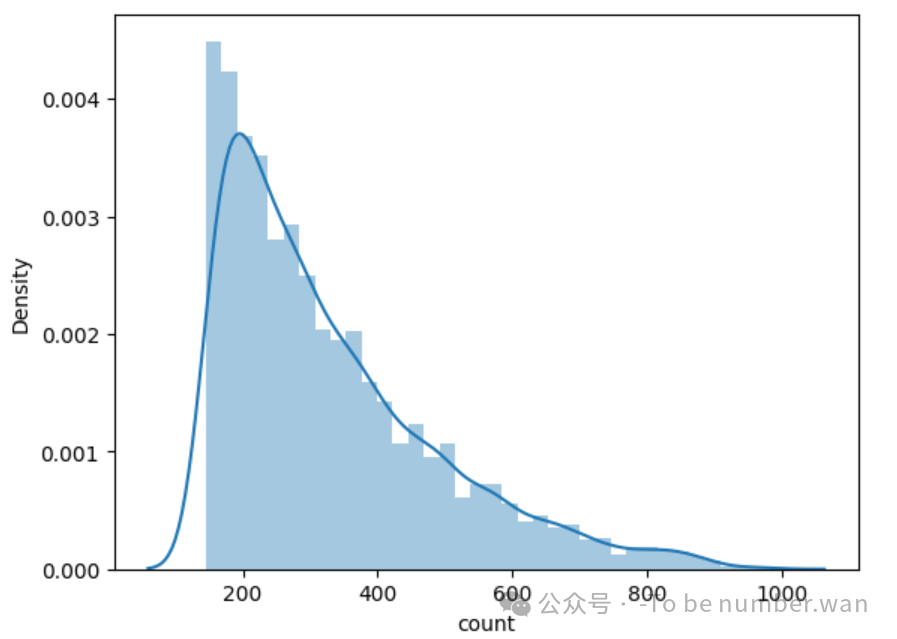
❝
✅ 经过处理后,长尾现象明显缓解,分布更趋平滑。
(6)按年份统计平均租车数
python
y_bike = bike.groupby(bike.index.year).mean()['count']
y_bike输出:
python
datetime
2011 274.526697
2012 366.408629
Name: count, dtype: float64可见,2012 年的平均租车数量显著高于 2011 年,可能与推广力度或用户增长有关。
(7)绘制年度均值柱状图
python
y_bike.plot(kind='bar', rot=0)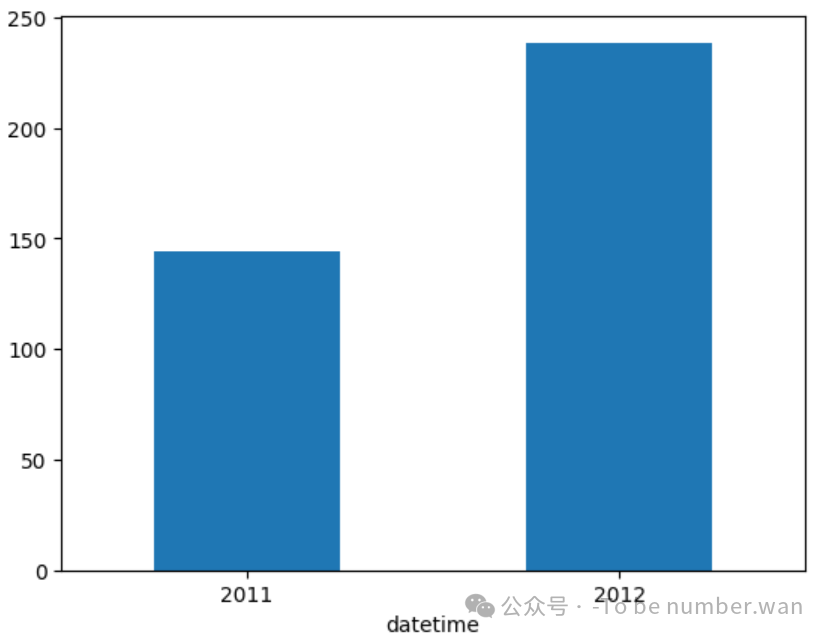
(8)重采样:绘制按月统计数据的趋势图
python
mm_bike.plot()
plt.legend(loc="best", fontsize=8)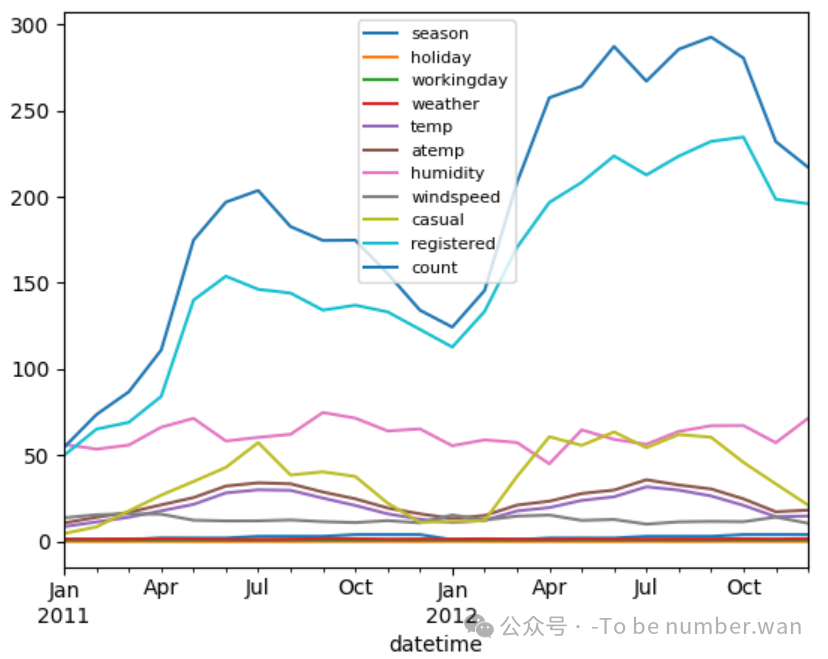
❝
📈 图中可看出:
count随季节波动明显,夏季达到高峰;同时温度、湿度也呈现周期性变化。
(9)找出哪个月租车最多?
python
m_bike = bike.groupby(bike.index.month).mean()['count']
m_bike.plot()
plt.grid()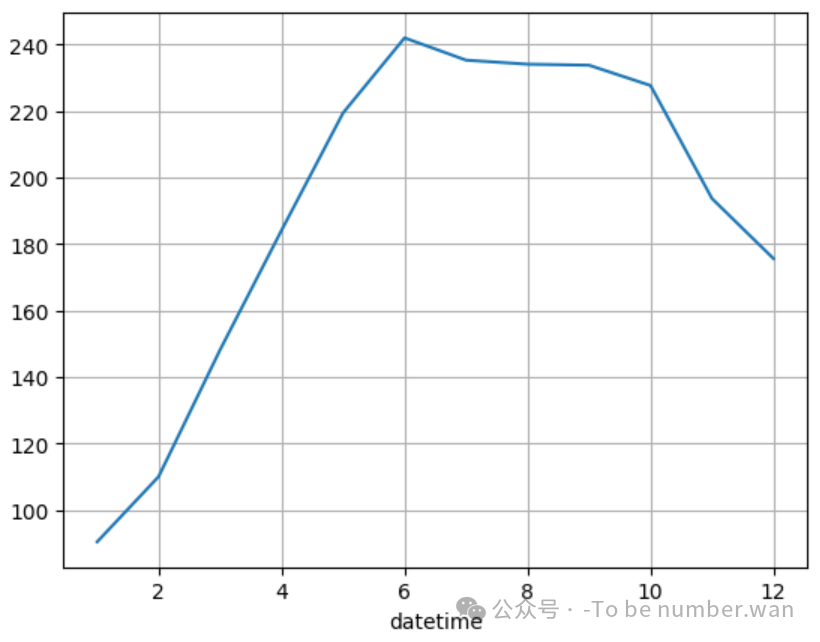
❝
🌟 9月份租车数量最多!可能是秋高气爽最适合骑行的原因。
(10)每天不同时间段的租车变化
python
h_bike = bike.groupby(bike.index.hour).mean()['count']
h_bike.plot(kind = "bar", rot=0)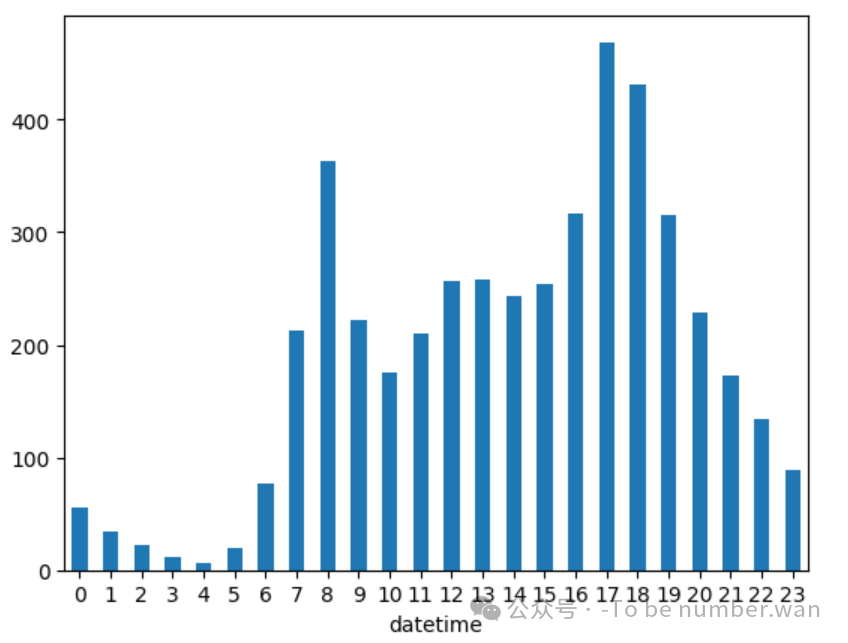
❝
⏰ 发现:早上8点和下午5点左右出现两个高峰,符合通勤出行习惯。
(11)天气对租车额的影响分析
最后,我们来看看天气如何影响租车行为:
python
weather_bike = bike.groupby(bike.weather).mean()['count']
weather_bike.plot(kind='bar', rot=0)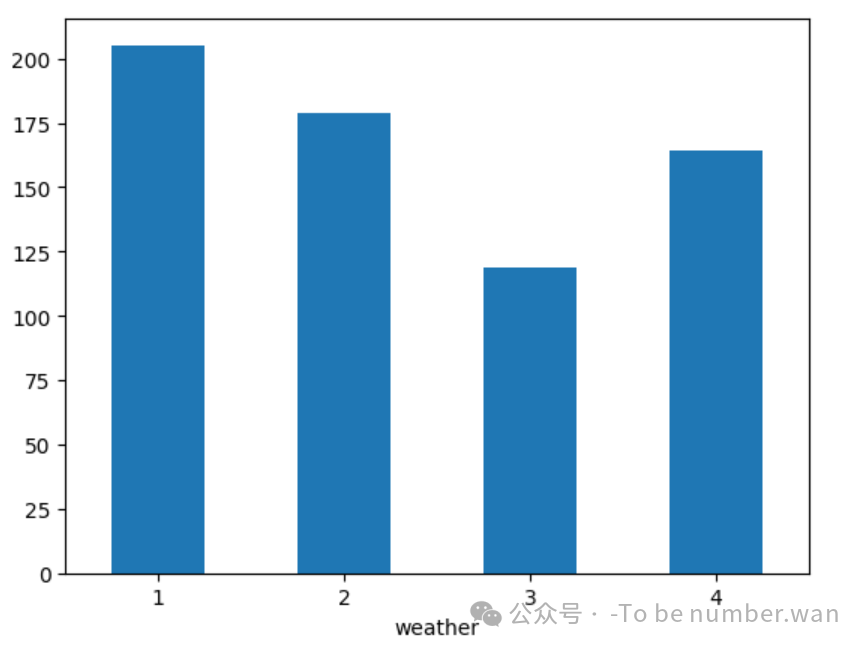
❝
🌤️ 天气编码说明:
1:晴朗
2:多云
3:轻度降雨/雾
4:重度降雨/风暴
❝
❄️ 结论:天气越差,租车人数越少。为什么当天气为 4(恶劣天气)时,租车量高于3呢。
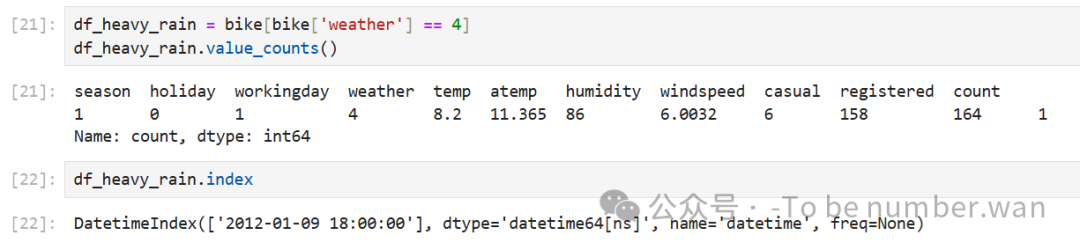
✅ 回答:
❝
为什么暴雨天租车数量大于3?
因为:
-
count=164是指某一小时内实际租出的车辆总数,而不是平均值或期望值; -
这个时间点正好是 下班高峰期(18:00),即使下雨,也有大量上班族需要回家;
-
虽然暴雨天气总体租车量下降,但在特定场景下(如通勤高峰),仍会产生较高的需求;
-
因此,个别暴雨时段租车数超过3甚至上百是正常的,不能据此推断"暴雨天租车多"。
🧠 总结与启示
通过这次实训,我们完成了从原始数据到洞察发现的全过程:
✅ 数据清洗 →
✅ 时间索引设置 →
✅ 描述性统计与可视化 →
✅ 按时间维度(年、月、小时)分析 →
✅ 天气因素影响评估
关键结论:
-
自行车租赁在 2012 年整体高于 2011 年;
-
9月是全年租车高峰期;
-
每天 早8点和晚5点 是出行高峰;
-
天气越好,租车越多,恶劣天气显著抑制需求。
📌 小贴士
-
使用
resample()可快速实现时间聚合; -
groupby()+mean()是探索趋势的好帮手; -
密度图有助于识别异常值和分布形态;
-
数据预处理(如去噪)能提升模型效果。
📎 下载数据
你可以从以下链接下载原始数据: 👉 https://www.kaggle.com/chenmingml/bikesharingdemand
或:
公众号后台回复【自行车租赁实训】
📚 扩展思考
下次我们可以尝试:
-
构建回归模型预测未来租车量;
-
加入节假日、工作日特征构建分类模型;
-
使用 LSTM 或 ARIMA 做时间序列预测。
如果你喜欢这类实战案例,记得点赞、转发并关注我!我们下期继续带你玩转数据分析 😎
📌 附录:完整代码清单
python
import numpy as np
import pandas as pd
import datetime
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
# 读取数据
bike = pd.read_csv('bike.csv')
bike.head()
# 查看数据类型
bike.info()
# 转换时间列
bike.datetime = pd.to_datetime(bike.datetime)
bike.dtypes
# 设置索引并画密度图
bike = bike.set_index('datetime')
sns.distplot(bike["count"])
# 描述统计
bike["count"].describe()
# 清理数据
def Count(x):
if x < 145:
return np.nan
else:
return x
bike1 = bike.copy()
bike1["count"] = bike1["count"].apply(Count)
bike1 = bike1.dropna(axis=0, how='any')
sns.distplot(bike1["count"])
# 按年统计
y_bike = bike.groupby(bike.index.year).mean()['count']
y_bike.plot(kind='bar', rot=0)
# 按月重采样
mm_bike = bike.resample('M', kind="period").mean()
mm_bike.plot()
plt.legend(loc="best", fontsize=8)
# 按月均值
m_bike = bike.groupby(bike.index.month).mean()['count']
m_bike.plot()
plt.grid()
# 按小时
h_bike = bike.groupby(bike.index.hour).mean()['count']
h_bike.plot("bar", rot=0)
# 按天气
weather_bike = bike.groupby(bike.weather).mean()['count']
weather_bike.plot(kind='bar', rot=0)