第十节 来自人类恶意的攻击 --【2025版】李宏毅机器学习系列课程
第十一节 领域自适应 -- 【2025版】李宏毅机器学习系列课程
目录
[1. 对抗攻击](#1. 对抗攻击)
[2. 黑盒攻击](#2. 黑盒攻击)
[3. 攻击案例](#3. 攻击案例)
[4. 防御方式](#4. 防御方式)
[5. 迁移学习(相关任务的知识迁移)](#5. 迁移学习(相关任务的知识迁移))
[5.1 领域偏移(分布不同导致模型失效)](#5.1 领域偏移(分布不同导致模型失效))
[5.2 领域自适应(对齐分布)](#5.2 领域自适应(对齐分布))
[5.3 领域泛化(训练与测试领域差异)](#5.3 领域泛化(训练与测试领域差异))
1. 对抗攻击
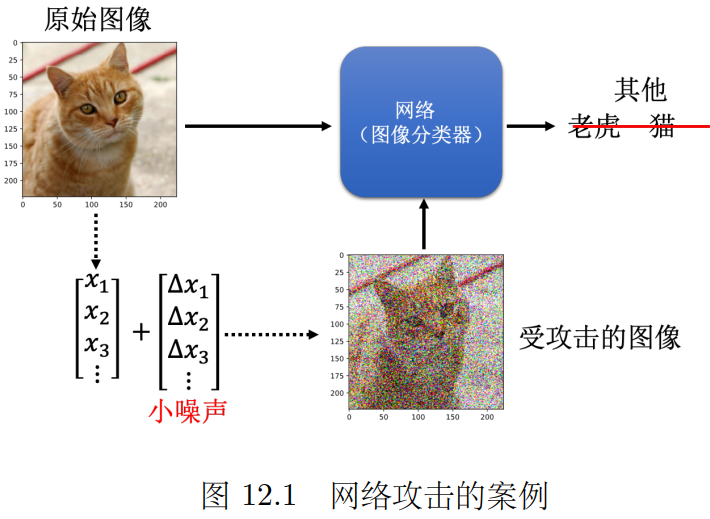
有时需要检测的对象会想办法骗过网络 ,模型需要有能力检测 外界的恶意行为,提高正确率。
比如用网络进行垃圾邮件过滤,对于坏人会避免他的邮件被分类为垃圾邮件,进行攻击。
攻击例子:给原始猫猫的图像加很小的噪声,人眼还是认为这是猫,但机器会输出错误的结果。
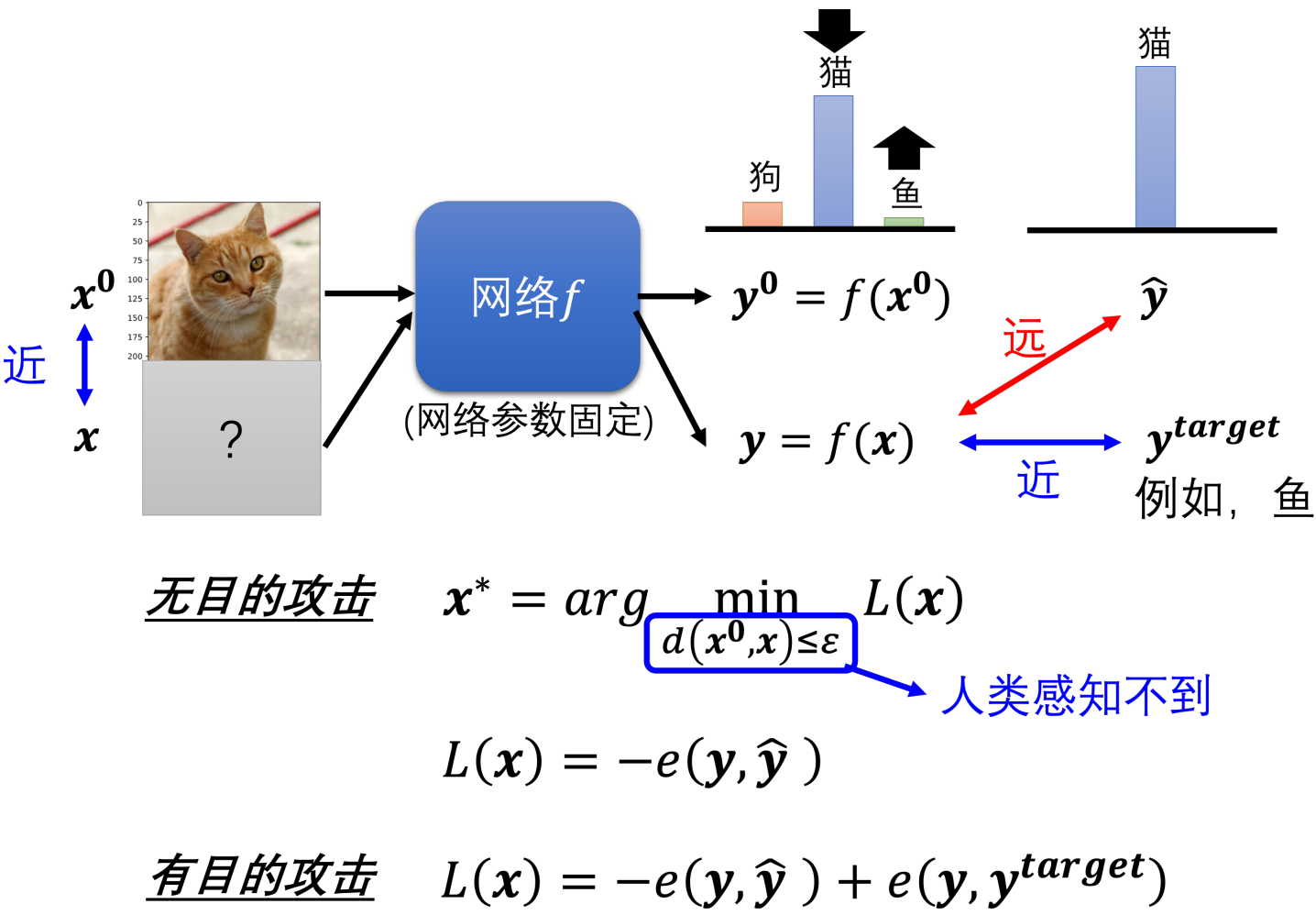
对于固定的网络f 和一张图片x0对应正确答案yˆ,
攻击需要找到一个临近的x ,使得输出y 与yˆ差距大。
无目的 攻击:使得交叉熵损失越大越好 取符号min
有目的 攻击:想让x输出为 目标值y_target y要远离y^ 接近y_target
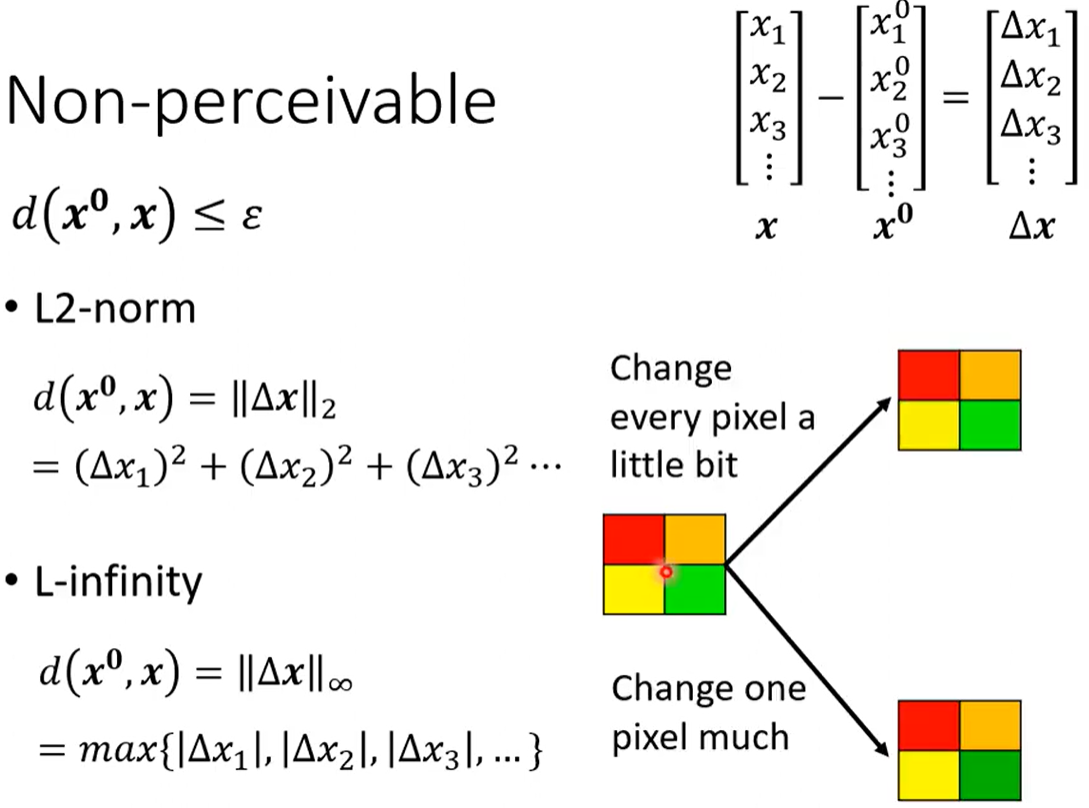
如何定义x与x0接近 不被人眼察觉 。 相比每个像素都变化一点,某个像素变化的多一点更容易被发现。L-2范数 是更面向整体变化;L-无穷范数 更面向最大变化。
如果是听觉等其他领域,需要根据什么是"人类不易察觉" 来设置范围,设置用什么距离。
进行攻击即找一个最好的x 即解这个优化问题 。 如果没有 距离近的条件约束 直接梯度下降即可。
现在还需要在这个范围内,可以通过如果更新梯度后的x超过范围,就找范围内与x最近的位置。
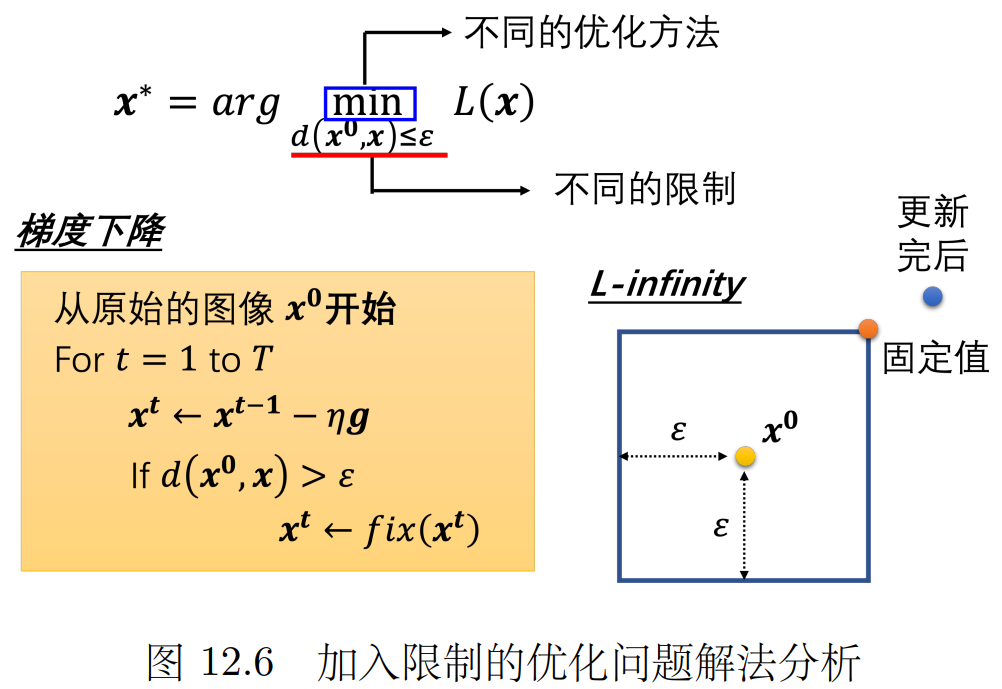
快速梯度符号法(FGSM) 单步攻击:学习率设置为ε 梯度如果>0设置为1 <0设置为-1
在上面那个蓝色的框框 我直接跑到四个角之一
2. 黑盒攻击
白盒 攻击:攻击者已经知道模型的参数
黑盒 攻击:拿一些训练数据给被攻击模型 让它生成一些输出 。拿这些成对 的输入输出训练一个代理网络 ,因为它们具有相似度,能成功攻击代理网络的输入也大概率能攻击原模型。
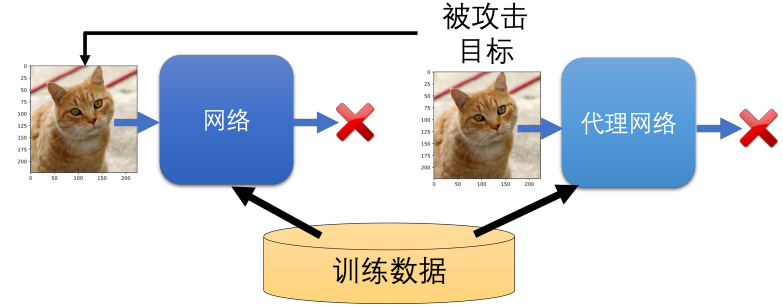
trick:集成学习 多训练几个代理网络 若某数据能欺骗多个代理模型,攻击成功概率更大
成功攻击的内在原因:
-
对抗方向普适性 :能使一个模型分类错误的扰动方向,往往对其他模型也有效
-
决策边界相似性 :不同模型在数据空间的决策边界具有相似的结构
-
数据本身特性 :对抗脆弱性可能更多源于数据分布特性而非模型结构
特殊的理想厉害攻击:单像素攻击(就改一个像素 输出就变了)
通用对抗攻击(所有的输入 在这样的扰动下都会错误)
未来研究方向:
-
理解对抗子空间 :深入研究导致多模型共同脆弱的数据特性
-
增强模型多样性 :开发决策边界差异更大的模型集合
-
输入重构方法 :设计能过滤 对抗扰动的预处理机制
-
动态防御系统 :构建能实时检测 和抵御攻击的适应性系统
3. 攻击案例
1.诈骗犯用变声器合成别人的声音,模型任务是区分真实声音和合成声音。
攻击该模型,将合成的声音加一些噪声,让模型误以为这是真实声音。
2.现实攻击人脸识别系统,戴上神奇眼睛 系统会误以为左边的男性 是右边的这个女性。

3.自动驾驶识别路况 路边限速/停车等标识牌被小改动,人眼仍然觉得没问题,但模型识别错误。
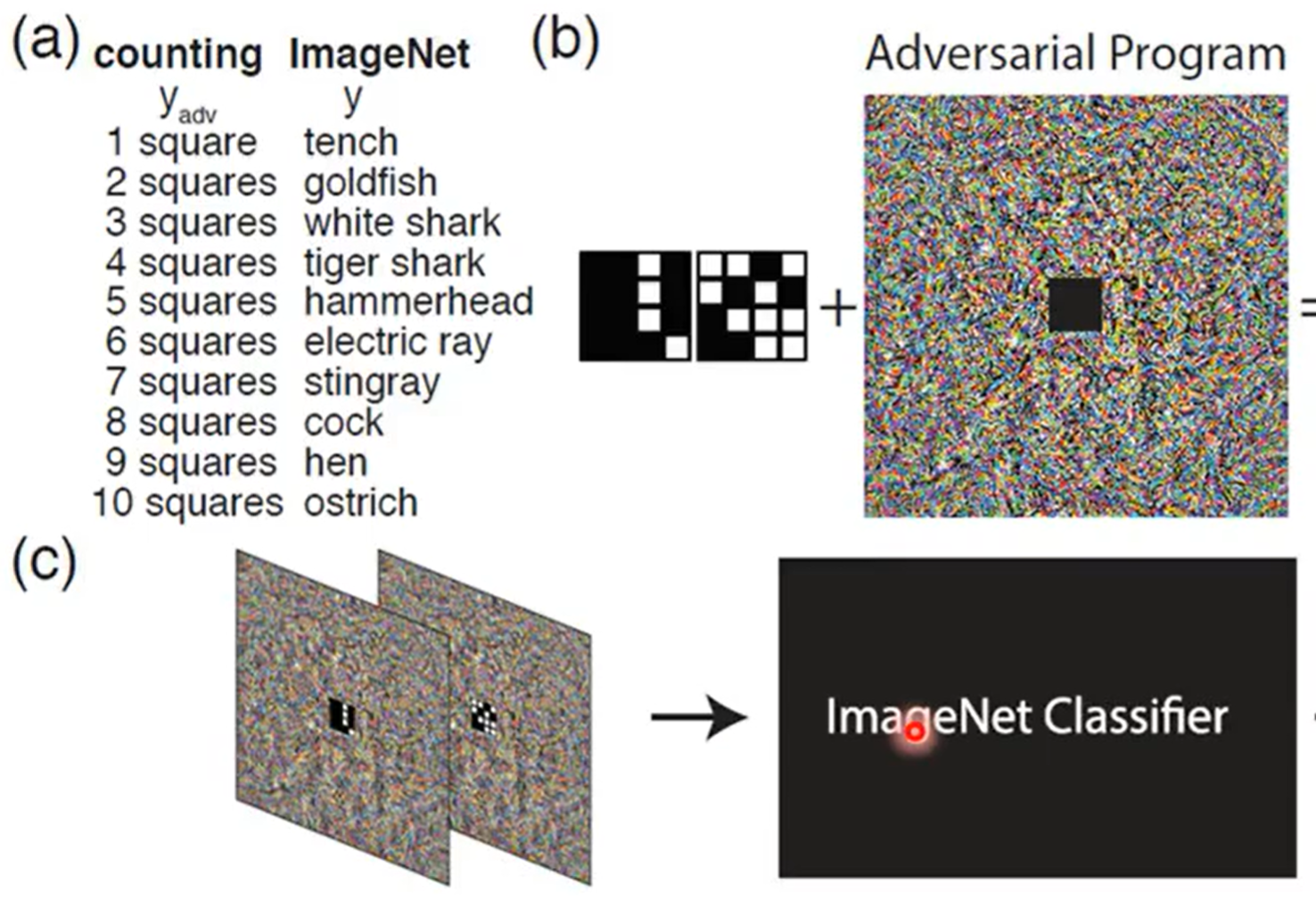
对抗性重编程:我想实现一个功能 但我不自己训练模型 在别人训练好的模型上 给输入加特定的标志 使得可以实现 原模型不想做 但我想要的功能
上文攻击均在测试阶段改变输入,下文后门攻击进行在训练阶段。污染数据集、污染预训练模型。
后门攻击:比如我想要分类器分类 鱼和狗。 我的目标是把鱼错误的分类为狗
我对"狗"的训练数据 构造的特殊"毒"数据为 某个固定小角落位置上改成特定的像素块 。人眼看它仍然是狗 分类器也把他学习为狗。
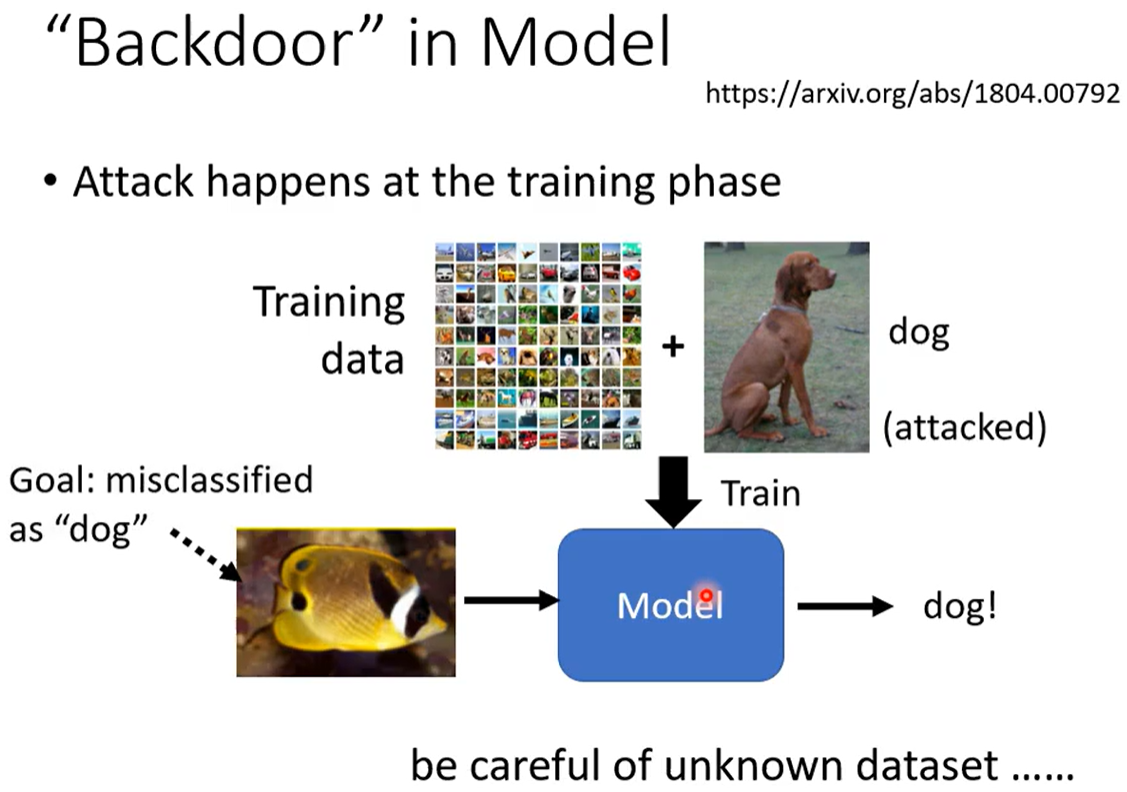
但这个小角落的像素块像打上了一个隐标记 ,分类器学习几张这样特殊的狗 可能会误以为只要这个角落里有这个特殊像素块的都是狗 。这会导致 我可以构造一个攻击数据 把鱼的图片那个角落加上一样的像素 分类器就还会把它当成狗。
核心思想是 加上一个特定的 数据检查人员也注意不到**"标记"** ,因为这个标记很罕见 ,在正常图像/文本中出现的很少 模型会将其识别为**超强特征信号,**分类器就会错误的片面学习。
毒数据是带有标记的 类别A ,模型误以为所有带标记的都是模型A,但我拿出带标记的类别B,模型会错认为是类别A。
4. 防御方式
被动防御 :在图像进入训练器之前 先过一个滤波器 (平滑模糊化之类)从而把攻击的噪声削弱。
还可以进行先压缩 再解压缩之类的方式过滤噪声。
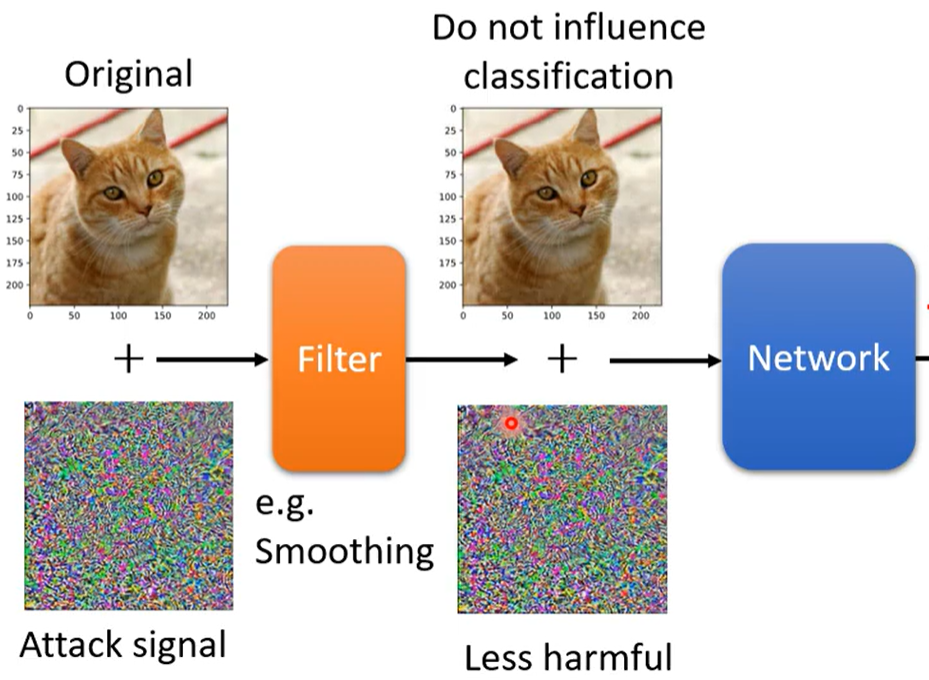
但是假设别人知道了你的防御手段 也会找到特定的方式缓解你的防御,
所以可以随机化防御 随机放大缩小 加上某背景之类。
主动防御 :对于已知的攻击数据和攻击方式 进行针对性训练 增强模型鲁棒性。(训练数据增强)
对原训练数据x 增加攻击噪声为x' 后 拿这些数据都再训练一下 (x,y) 和 (x',y)。

5. 迁移学习(相关任务的知识迁移)
用之前的知识 有MNIST数据库 可以轻易的为手写数字达到很高的准确率。
但是如果 领域偏移:训练数据 和测试数据不一样怎么办?
比如我手头是手写数字MNIST 需要测试彩色的MNIST-M.

-
核心问题 :标注数据成本高(如医学图像标注需专家),但目标领域数据不足。
-
解决思路 :两个相关任务,利用源领域 (充足数据)的知识,迁移到目标领域(稀缺数据)。
可以把base network中的层复制 过来(有个现成的初始化 ),再根据目标领域有的数据量 对一些层进行冻结 (frozen 不改变参数)对一些层进行微调。
5.1 领域偏移(分布不同导致模型失效)
问题:领域偏移 :训练数据(源领域)和测试数据(目标领域)分布不同,导致模型失效。
例如:用黑白数字(MNIST)训练的模型,在彩色数字MNIST-M 上准确率从99%暴跌至52%。
原因:模型过度依赖颜色 特征(黑白vs彩色),而非数字形状。
-
输入分布偏移:图像风格、光照不同(如医疗影像CT vs MRI)。
-
输出分布偏移:类别比例变化(如猫狗数据中猫的比例从50%变为80%)。
-
关系偏移:相同输入对应不同标签(如"苹果"在训练集中是水果,测试集中是公司logo)。
5.2 领域自适应(对齐分布 抽取共性特征)
如果目标领域上有一大堆有标签的数据,可以直接用目标领域的数据训练 微调。
否则若目标领域标注数据很少 ,则需对齐分布 让模型在目标领域上表现更好。
对齐的目的是 发现问题A与问题B的共性,进而能用问题A的模型帮助解决问题B。
就像MNIST 和MNIST-M,应该从前者学到数字的形状特征 (这是二者共性)来辅助判断后者。
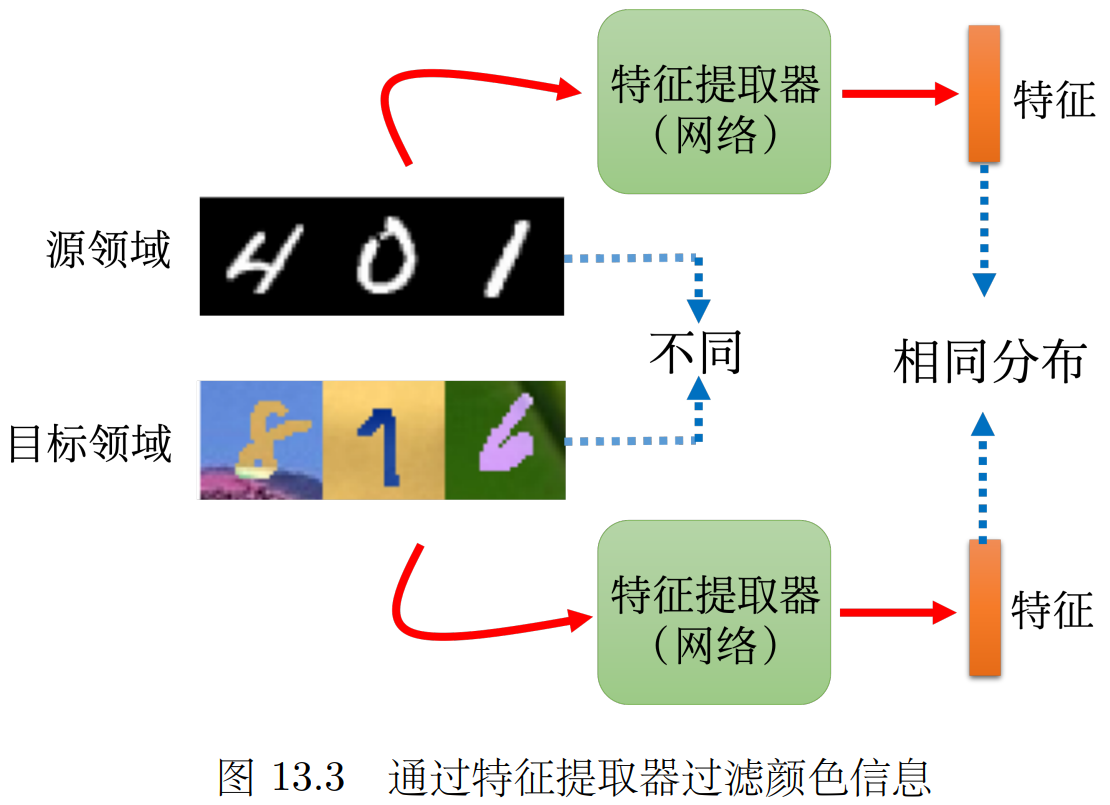
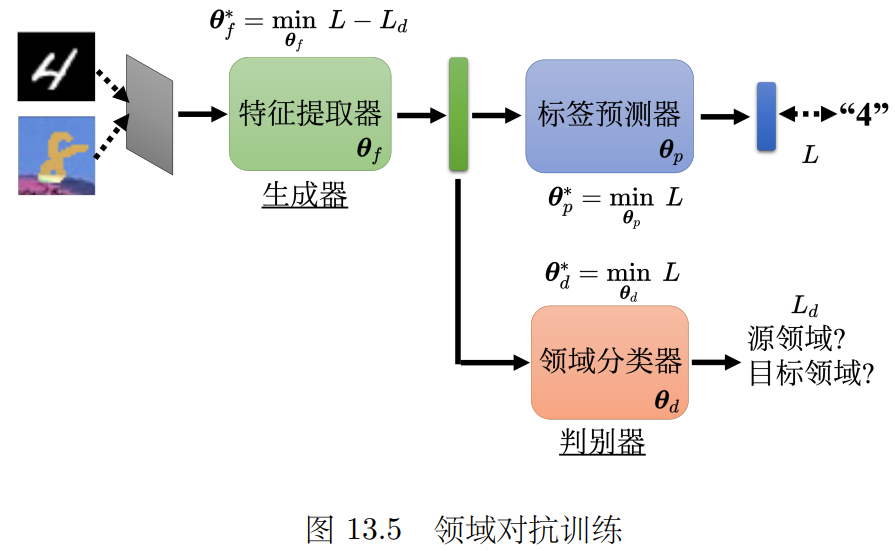
为此我们需要训练特征提取器 (提取源与目标的共性 过滤掉差异)和标签预测器(进一步分类)
领域对抗 训练:特征提取器 需要骗过领域分类器(看不出来是来自源还是目标领域)

领域分类器 做二分类 使得损失Ld 越小越好; 标签预测器 损失越小L越好;
特征提取器 需要帮助 标签预测,对抗领域分类 即最小化L-Ld
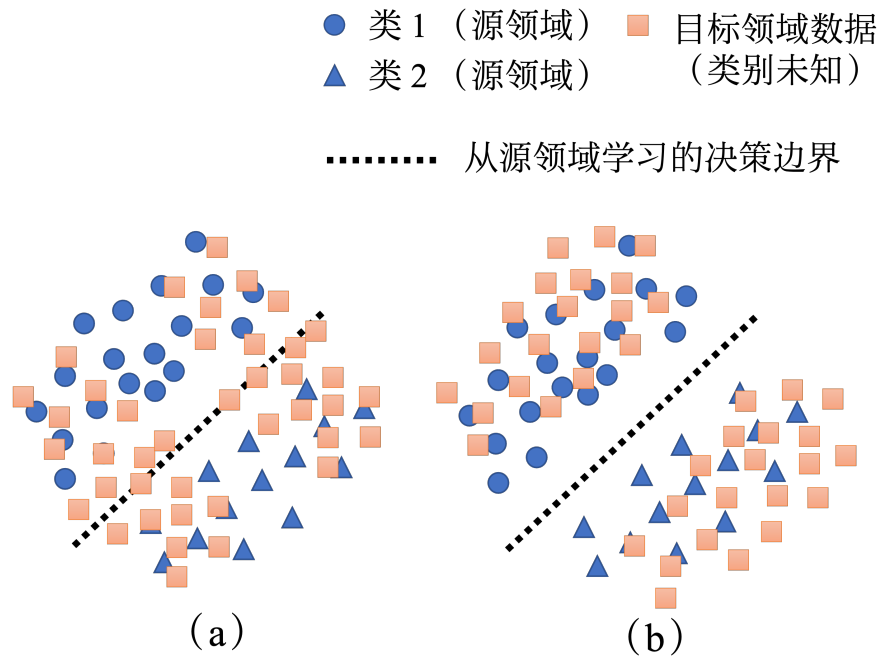
在源领域提取特征时(对源领域分类时) 要让目标域 样本尽量远离源领域 的决策划分边界
目的:使得分类很确定 不模棱两可
为实现这个,可以把无标注的图片依次输入特征提取器 -> 标签预测器
如果是像图(b)这样结果集中型的就是 符合要求的远离边界boundary;否则就像A不符合要求。
源领域和目标领域的种类不一定相同,会出现源里有目标里没有,目标里有源里没有的情况。
这时不可强求对齐,还要用一些其他处理。
可以对共享公共 样本提高 对抗权重,非公共 样本降低对抗权重。


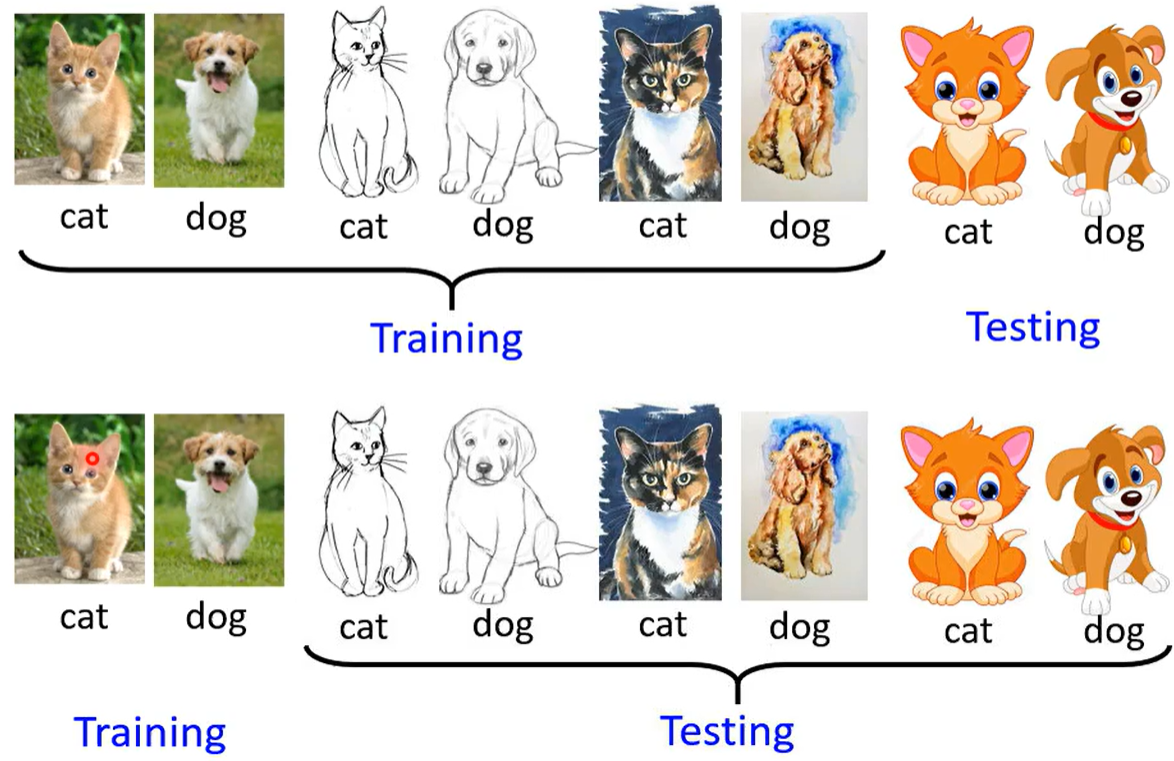
5.3 领域泛化(训练与测试领域差异)
训练数据领域多 测试领域少; 训练数据领域少 测试领域多。 如下方猫狗分类器的例子。