本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。
前言:"ISC.AI 2025互联网安全大会开幕式及未来峰会"于8月6日在北京举行。360集团创始人、ISC大会主席周鸿祎在演讲中表示,行业里还有很多的争论,到底是做单智能体还是多智能体。多智能体这个时代已经来了,因为单智能体的能力确实非常有限。今天我们就深入探讨多智能体系统的核心原理与工程实践。
一、为什么需要多智能体系统?
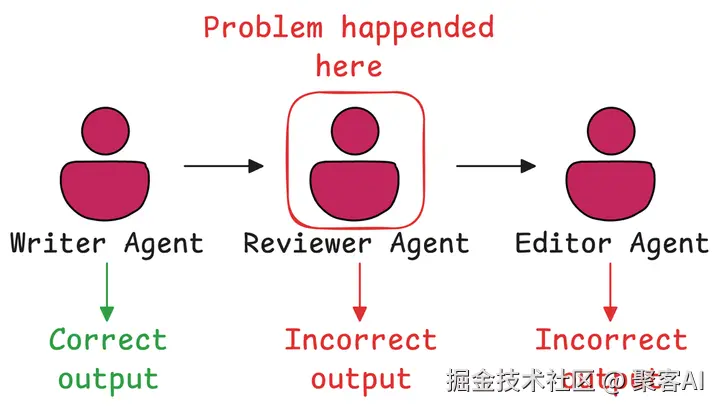
当单智能体面临复杂任务时,容易陷入思维混乱和工具滥用。多智能体系统通过角色分工解决三大核心问题:
- 模块化:各Agent专注特定能力域(如搜索/编码/审核)
- 错误隔离:单个Agent故障不影响整体系统
- 解释性:每个决策节点可追溯
二、核心架构设计
系统包含三层抽象结构:
1. Tool类:能力原子化
python
class Tool:
def __init__(self, name, func, params):
self.name = name # 工具名称
self.func = func # 底层函数
self.params = params # 参数规范
def validate_input(self, inputs):
# 类型检查与转换
if type(inputs) != self.params["type"]:
try:
return self.params["type"](inputs)
except:
raise ValueError("Invalid input type")
def execute(self, **kwargs):
validated = {k: self.validate_input(v) for k,v in kwargs.items()}
return self.func(**validated)典型工具示例:
- WebSearchTool: 网络信息获取
- CodeGenerator: 代码生成
- DataAnalyzer: 结构化数据分析
2. Agent类:自主决策单元
python
class Agent:
def __init__(self, role, tools, llm_backend):
self.role = role # 角色定义
self.tools = {t.name:t for t in tools} # 工具集
self.llm = llm_backend
self.memory = [] # 思维链存储
def react_loop(self, task):
while not self._is_task_done():
thought = self._generate_thought(task)
if "ACTION" in thought:
tool_name, params = self._parse_action(thought)
result = self.tools[tool_name].execute(**params)
self.memory.append(f"Observation: {result}")
else:
return thought # 最终输出关键特性:
- 内置ReAct决策循环
- 动态工具选择机制
- 思维链持久化存储
3. Crew类:智能体编排引擎
ini
class Crew:
def __init__(self):
self.agents = {} # 注册的智能体
self.dependencies = {} # 依赖图
def add_agent(self, name, agent, deps=[]):
self.agents[name] = agent
self.dependencies[name] = deps
def execute(self, input_data):
# 拓扑排序解决执行顺序
ordered_agents = self._topological_sort()
outputs = {}
for agent_name in ordered_agents:
agent_input = input_data if not outputs else outputs[agent_name]
result = self.agents[agent_name].react_loop(agent_input)
outputs[agent_name] = result
return outputs依赖解析算法:
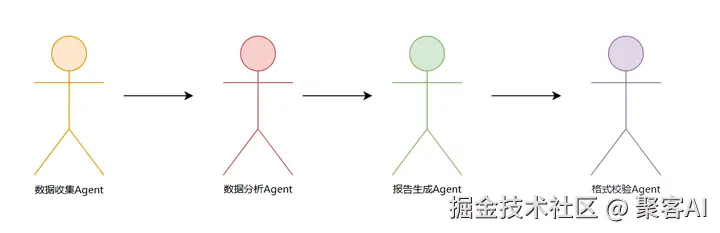
如前面所述,多智能体模式将AI工作流程结构化为一个智能体团队,这些智能体协同工作,每个智能体都有明确的角色。不是由一个代理从头到尾处理一个任务,而是有一个工作流程,其中多个代理各自负责任务的一部分,然后将结果交给下一个代理。
这种设计通常(不总是)由一个协调器来协调,以确保代理按正确的顺序运行并共享信息。
这个想法类似于装配线或接力队:代理A完成第1步,然后代理B使用A的输出完成第2步,依此类推,直到达到目标。
每个代理在其子问题上都有自己的思考/行动方式,但他们通过定义的工作流程协作,共同解决更大的问题。
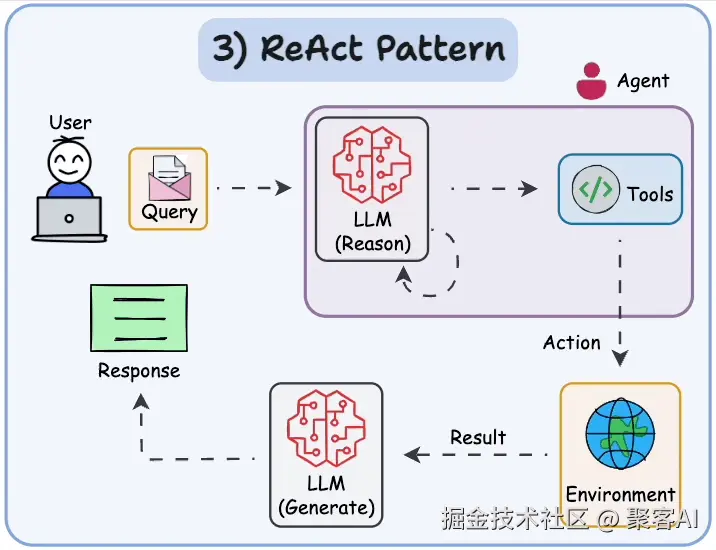
从技术上讲,多智能体模式中的每个智能体仍然在内部遵循推理+行动循环 (这个我之前有写过一篇关于 ReAct 代理全流程的技术文档,粉丝朋友自行领取:《 从头构建 ReAct 代理全流程》)。
三、实践:构建多智能体新闻生成器
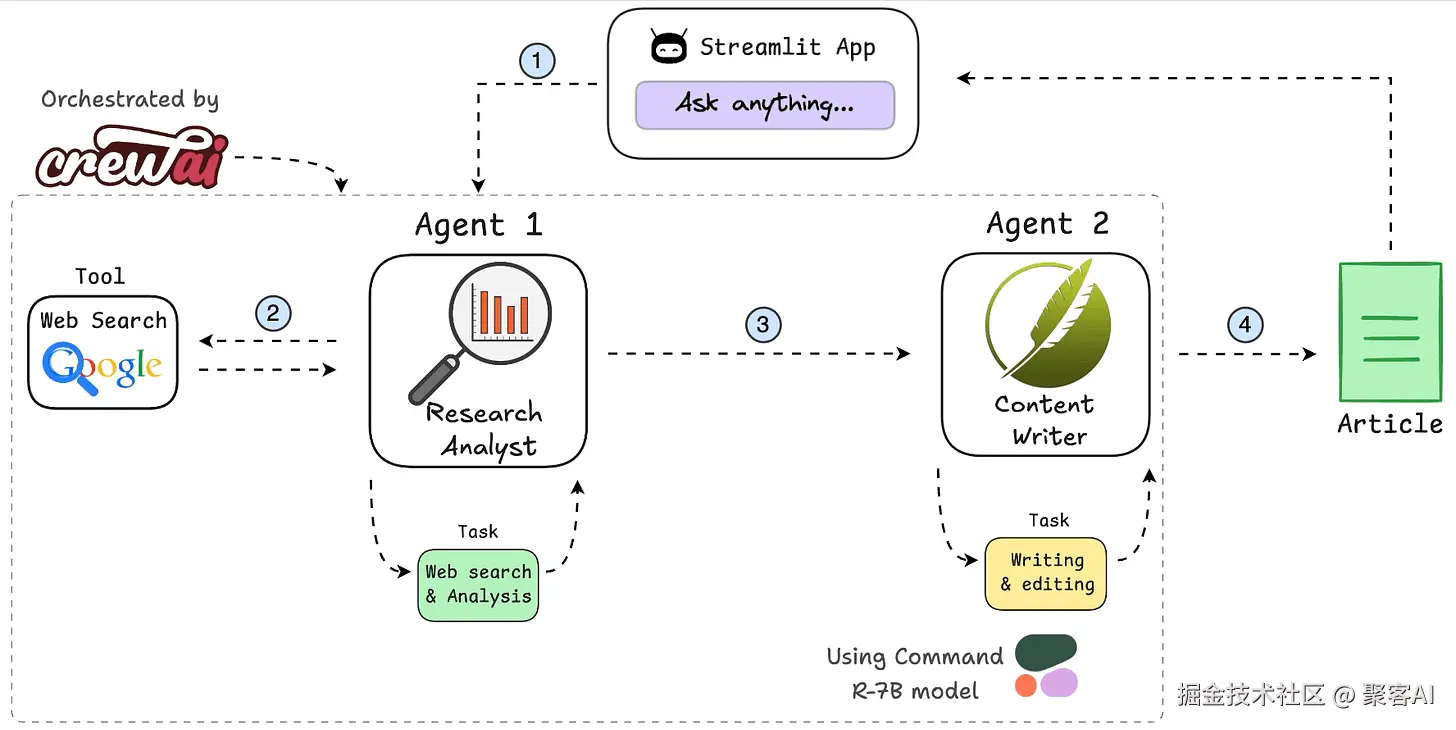
该应用程序将接受用户的查询,在网络上搜索,并将其转化为一篇引证良好的新闻文章!(代码放在下方,感兴趣的朋友可以实践一下)
这是此演示的技术栈:
- CrewAI 用于多代理编排。
- Cohere 的 CommandR-7B 作为 LLM。
在这个多智能体应用中,我们将有两个智能体:
1) 分析师Agent:
- 接受用户查询。
- 使用Serper网络搜索工具从互联网获取结果。
- 汇总结果。
2) 内容撰写Agent:
- 使用精心整理的结果来准备一篇 polished、出版准备好的文章。
实现代码:
安装依赖项:确保您已安装 Python 3.11 或更高版本。
pip install crewai crewai-toolsenv示例:
ini
SERPER_API_KEY=your_serper_api_key
COHERE_API_KEY=your_cohere_apikey应用代码:
ini
import os
import streamlit as st
from crewai import Agent, Task, Crew, LLM
from crewai_tools import SerperDevTool
from dotenv import load_dotenv
# Load environment variables
load_dotenv()
# Streamlit page config
st.set_page_config(page_title="AI News Generator", page_icon="📰", layout="wide")
# Title and description
st.title("🤖 AI News Generator, powered by CrewAI and Cohere's Command R7B")
st.markdown("Generate comprehensive blog posts about any topic using AI agents.")
# Sidebar
with st.sidebar:
st.header("Content Settings")
# Make the text input take up more space
topic = st.text_area(
"Enter your topic",
height=100,
placeholder="Enter the topic you want to generate content about..."
)
# Add more sidebar controls if needed
st.markdown("### Advanced Settings")
temperature = st.slider("Temperature", 0.0, 1.0, 0.7)
# Add some spacing
st.markdown("---")
# Make the generate button more prominent in the sidebar
generate_button = st.button("Generate Content", type="primary", use_container_width=True)
# Add some helpful information
with st.expander("ℹ️ How to use"):
st.markdown("""
1. Enter your desired topic in the text area above
2. Adjust the temperature if needed (higher = more creative)
3. Click 'Generate Content' to start
4. Wait for the AI to generate your article
5. Download the result as a markdown file
""")
def generate_content(topic):
llm = LLM(
model="command-r",
temperature=0.7
)
search_tool = SerperDevTool(n_results=10)
# First Agent: Senior Research Analyst
senior_research_analyst = Agent(
role="Senior Research Analyst",
goal=f"Research, analyze, and synthesize comprehensive information on {topic} from reliable web sources",
backstory="You're an expert research analyst with advanced web research skills. "
"You excel at finding, analyzing, and synthesizing information from "
"across the internet using search tools. You're skilled at "
"distinguishing reliable sources from unreliable ones, "
"fact-checking, cross-referencing information, and "
"identifying key patterns and insights. You provide "
"well-organized research briefs with proper citations "
"and source verification. Your analysis includes both "
"raw data and interpreted insights, making complex "
"information accessible and actionable.",
allow_delegation=False,
verbose=True,
tools=[search_tool],
llm=llm
)
# Second Agent: Content Writer
content_writer = Agent(
role="Content Writer",
goal="Transform research findings into engaging blog posts while maintaining accuracy",
backstory="You're a skilled content writer specialized in creating "
"engaging, accessible content from technical research. "
"You work closely with the Senior Research Analyst and excel at maintaining the perfect "
"balance between informative and entertaining writing, "
"while ensuring all facts and citations from the research "
"are properly incorporated. You have a talent for making "
"complex topics approachable without oversimplifying them.",
allow_delegation=False,
verbose=True,
llm=llm
)
# Research Task
research_task = Task(
description=("""
1. Conduct comprehensive research on {topic} including:
- Recent developments and news
- Key industry trends and innovations
- Expert opinions and analyses
- Statistical data and market insights
2. Evaluate source credibility and fact-check all information
3. Organize findings into a structured research brief
4. Include all relevant citations and sources
"""),
expected_output="""A detailed research report containing:
- Executive summary of key findings
- Comprehensive analysis of current trends and developments
- List of verified facts and statistics
- All citations and links to original sources
- Clear categorization of main themes and patterns
Please format with clear sections and bullet points for easy reference.""",
agent=senior_research_analyst
)
# Writing Task
writing_task = Task(
description=("""
Using the research brief provided, create an engaging blog post that:
1. Transforms technical information into accessible content
2. Maintains all factual accuracy and citations from the research
3. Includes:
- Attention-grabbing introduction
- Well-structured body sections with clear headings
- Compelling conclusion
4. Preserves all source citations in [Source: URL] format
5. Includes a References section at the end
"""),
expected_output="""A polished blog post in markdown format that:
- Engages readers while maintaining accuracy
- Contains properly structured sections
- Includes Inline citations hyperlinked to the original source url
- Presents information in an accessible yet informative way
- Follows proper markdown formatting, use H1 for the title and H3 for the sub-sections""",
agent=content_writer
)
# Create Crew
crew = Crew(
agents=[senior_research_analyst, content_writer],
tasks=[research_task, writing_task],
verbose=True
)
return crew.kickoff(inputs={"topic": topic})
# Main content area
if generate_button:
with st.spinner('Generating content... This may take a moment.'):
try:
result = generate_content(topic)
st.markdown("### Generated Content")
st.markdown(result)
# Add download button
st.download_button(
label="Download Content",
data=result.raw,
file_name=f"{topic.lower().replace(' ', '_')}_article.md",
mime="text/markdown"
)
except Exception as e:
st.error(f"An error occurred: {str(e)}")
# Footer
st.markdown("---")
st.markdown("Built with CrewAI, Streamlit and powered by Cohere's Command R7B")四、性能优化策略
- 短路机制:当工具返回关键错误时提前终止流程
- 缓存层:对稳定数据(如地点信息)启用结果缓存
- 并发控制:
csharp
# 并行执行独立Agent
with concurrent.futures.ThreadPoolExecutor() as executor:
futures = {executor.submit(agent.react_loop): agent
for agent in independent_agents}与传统框架对比
| 维度 | 原生实现 | LangChain | CrewAI |
|---|---|---|---|
| 启动速度 | ⚡️ 0.5s | 🐢 3.2s | 🐢 2.8s |
| 定制灵活性 | ⭐️⭐️⭐️⭐️⭐️ | ⭐️⭐️⭐️ | ⭐️⭐️⭐️⭐️ |
| 内存占用 | 78MB | 210MB | 195MB |
| 学习曲线 | 陡峭 | 平缓 | 中等 |
适用场景:需要深度定制的复杂工作流推荐原生实现,快速原型建议使用CrewAI
好了,总结一下,本次分享通过分层架构设计和模块化实现,可构建出适应复杂场景的智能协作系统。如果本次分享对你有所帮助,记得告诉身边有需要的朋友,"我们正在经历的不仅是技术迭代,而是认知革命。当人类智慧与机器智能形成共生关系,文明的火种将在新的维度延续。"在这场波澜壮阔的文明跃迁中,主动拥抱AI时代,就是掌握打开新纪元之门的密钥,让每个人都能在智能化的星辰大海中,找到属于自己的航向。