Title
题目
SurgRIPE challenge: Benchmark of surgical robot instrument pose estimation
SurgRIPE 挑战赛:手术机器人器械位姿估计基准测试
01
文献速递介绍
机器人辅助微创手术(RAMIS)的发展与SurgRIPE挑战赛 在过去十年中,在人工智能(AI)和手术机器人技术的进步推动下,机器人辅助微创手术(RAMIS)取得了显著发展。达芬奇(da Vinci®)等手术平台通过提供更精准的器械控制和术中可视化功能,彻底革新了手术流程,极大地提升了手术辅助效果。在RAMIS中,手术器械的精确位姿估计已成为一项关键任务,因为它是实现自主手术任务执行(Wang等人,2018)、手术技能评估(Gao等人,2014)和手术流程分析(Lecuyer等人,2020)等应用的核心基础。 商用外部设备(如深度相机和电磁追踪器(Federico等人,2019))能够提供准确的器械位姿估计,但由于手术室的空间限制和硬件设置约束,它们在术中的适用性有限。另一种手术器械位姿估计方案是利用机器人平台(如达芬奇系统)集成关节编码器提供的运动学信息(Wang等人,2022)。尽管这种方法无需额外硬件,但需要进行额外的手眼校准,且由于绳驱动机器人系统的复杂性,容易产生估计误差(Cui等人,2023)。 表1 手术工具定位数据集对比 基于标记的手术器械位姿估计视觉方法通过外部标记简化任务(Cartucho等人,2021),但其局限性在于依赖标记始终出现在相机的视场(FOV)内,且对光反射、遮挡等背景变化敏感。此外,这些标记并不能直接反映器械的位姿,需要通过复杂的几何变换计算获取。因此,无标记方法无需对硬件进行改造,为手术器械追踪提供了一种更具前景和实用性的方案。 在计算机视觉领域,目标位姿估计已得到广泛研究,LineMOD(Brachmann等人,2014)和YCB-Video(Xiang等人,2018)等基准数据集利用RGBD传感器和ArUco标记,在非医疗场景中实现了6自由度(DoF)位姿估计。这些数据集推动了自然场景任务中位姿估计方法的显著进步。然而,针对手术任务和场景的6自由度位姿估计基准仍较为缺乏。现有医学数据集如表1所示,多侧重于2D信息处理,忽略了6自由度位姿估计所需的3D信息。例如,EndoVis18 RobSeg(Allan等人,2020)、EndoVis17 RobSeg(Allan等人,2019)和ROBUST-MIS(Roß等人,2021)提供带2D分割标注的数据集;EndoVisPose(Du等人,2018)提供带真实2D器械关键点标注的数据;SuPer(Li等人,2019)提供真实运动学信息,但无法从这些运动学信息中直接获取相关的6自由度位姿。 Peng等人(2019)和Wen等人(2023)等最先进(SOTA)方法已在自然场景6自由度目标位姿估计任务中得到验证。但由于缺乏手术领域的基准和数据集,将这些方法迁移到RAMIS中面临诸多挑战,这源于手术场景的独特性: - 物体部分可见性:RAMIS中有限的操作空间导致内窥镜相机离手术器械极近,仅能在相机视场内呈现器械的部分区域。而许多先进位姿估计方法通常要求物体完全可见,因此部分可见性会严重影响其性能。 - 手术场景变化与遮挡:在RAMIS中,手术工具与软组织、器官的交互可能导致工具尖端被遮挡(如被血液遮挡),使位姿估计不稳定。此外,手术场景中的光照变化、镜面反射等因素也会进一步影响位姿估计精度。 - 高精度要求:位姿估计数据集通常使用RGBD相机生成真值数据,误差在厘米级。但手术工具的典型直径约为5毫米,因此RAMIS中的精度要求需达到毫米级。 为解决上述问题,我们发起了SurgRIPE挑战赛,该赛事于2023年在第26届医学图像计算与计算机辅助干预国际会议(MICCAI)上举办。本文首先介绍SurgRIPE数据集,该数据集旨在实现手术器械腕部机构的6自由度无标记位姿估计。为在真实手术环境中采集视频数据的同时获取准确且一致的手术器械真值位姿,我们采用了图1所示的新型流程:将基于标记的位姿估计与基于深度学习的图像修复相结合。通过关键点标记获取真实6自由度位姿数据后,利用深度学习修复模型(Suvorov等人,2021)去除标记,以避免产生任何可能导致位姿估计偏差的捷径视觉线索。最后,利用3D模型生成手术器械的分割掩码。 该数据集包含用于两项任务的视频序列,即无遮挡位姿估计(图2)和有遮挡位姿估计(图3)。六支参赛队伍在SurgRIPE数据集上验证了各自提出的无标记手术器械位姿估计方法。该数据集、基准测试工具和标注工具已在线公开,可通过以下链接获取:https://www.synapse.org/#!Synapse:syn51471789/wiki/。
Abatract
摘要
Accurate instrument pose estimation is a crucial step towards the future of robotic surgery, enabling applications such as autonomous surgical task execution. Vision-based methods for surgical instrument poseestimation provide a practical approach to tool tracking, but they often require markers to be attached to theinstruments. Recently, more research has focused on the development of markerless methods based on deeplearning. However, acquiring realistic surgical data, with ground truth (GT) instrument poses, required for deeplearning training, is challenging. To address the issues in surgical instrument pose estimation, we introduce theSurgical Robot Instrument Pose Estimation (SurgRIPE) challenge, hosted at the 26th International Conferenceon Medical Image Computing and Computer-Assisted Intervention (MICCAI) in 2023. The objectives of thischallenge are: (1) to provide the surgical vision community with realistic surgical video data paired withground truth instrument poses, and (2) to establish a benchmark for evaluating markerless pose estimationmethods. The challenge led to the development of several novel algorithms that showcased improved accuracyand robustness over existing methods. The performance evaluation study on the SurgRIPE dataset highlightsthe potential of these advanced algorithms to be integrated into robotic surgery systems, paving the way formore precise and autonomous surgical procedures. The SurgRIPE challenge has successfully established a newbenchmark for the field, encouraging further research and development in surgical robot instrument poseestimation.
精确的器械位姿估计是机器人手术未来发展的关键环节,它为自主手术任务执行等应用提供了可能。基于视觉的手术器械位姿估计方法为工具追踪提供了一种实用方案,但这类方法通常需要在器械上附着标记物。近年来,越来越多的研究聚焦于基于深度学习的无标记方法开发。然而,获取深度学习训练所需的、带有真实标签(GT)器械位姿的真实手术数据面临诸多挑战。为解决手术器械位姿估计领域的这些问题,我们发起了手术机器人器械位姿估计(SurgRIPE)挑战赛,该赛事于 2023 年在第 26 届医学图像计算与计算机辅助干预国际会议(MICCAI)上举办。挑战赛的目标包括:(1)为手术视觉领域提供配对真实标签器械位姿的真实手术视频数据;(2)建立评估无标记位姿估计方法的基准。此次挑战赛催生出多种新型算法,这些算法相比现有方法展现出更高的精度和鲁棒性。在 SurgRIPE 数据集上开展的性能评估研究表明,这些先进算法有望集成到机器人手术系统中,为更精准、更自主的手术流程奠定基础。SurgRIPE 挑战赛成功为该领域建立了新基准,将推动手术机器人器械位姿估计领域的进一步研究与发展。
Results
结果
There were 44 registered teams by the submission deadline. Fiveteams provided valid submissions before the deadline, and one teamprovided a valid submission after the deadline. All the submitted challenge results for each subset are presented in Tables 4--7. We noticedthat if the pose estimation fails in one frame, it will cause an outlierwith a large translation and rotation error. This makes the averagetranslation and rotation error of several methods heavily affected bythese extreme error values. Therefore, to rank the competing methods,we mainly focus on the ADD, Accuracy--ADD threshold Curve and theAvg Acc as defined in Section 3.2. IGTUM was awarded first place, andICL was awarded second place. In the results, late submissions havebeen denoted using an asterisk.
参赛队伍表现与评估结果概述 截至提交截止日期,共有44支队伍注册参赛。其中5支队伍在截止日期前提交了有效结果,1支队伍在截止日期后提交了有效结果。各子集的挑战赛提交结果均已汇总于表4至表7中。 我们发现,若某一帧的位姿估计失败,会产生具有极大平移和旋转误差的异常值,这导致部分方法的平均平移误差和旋转误差受到这些极端误差值的严重影响。因此,为对参赛方法进行排名,我们主要依据第3.2节定义的ADD(平均距离误差)、精度-ADD阈值曲线以及Avg Acc(平均精度)指标。最终,IGTUM团队获得第一名,ICL团队获得第二名。结果中,延迟提交的结果已用星号(*)标注。
Figure
图
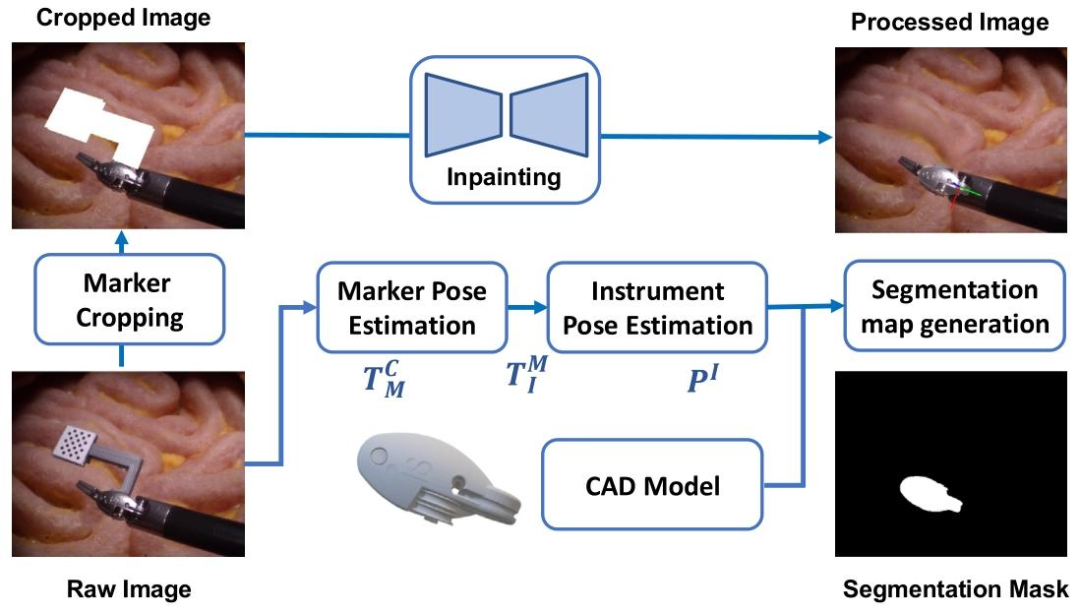
Fig. 1. SurgRIPE data collection pipeline. The GT pose was captured with a keydot marker which was removed using image inpainting. The 3D model of the tool was used togenerate the segmentation mask
图1. SurgRIPE数据采集流程 真实标签(GT)位姿通过关键点标记采集,随后利用图像修复技术去除该标记。工具的3D模型被用于生成分割掩码。
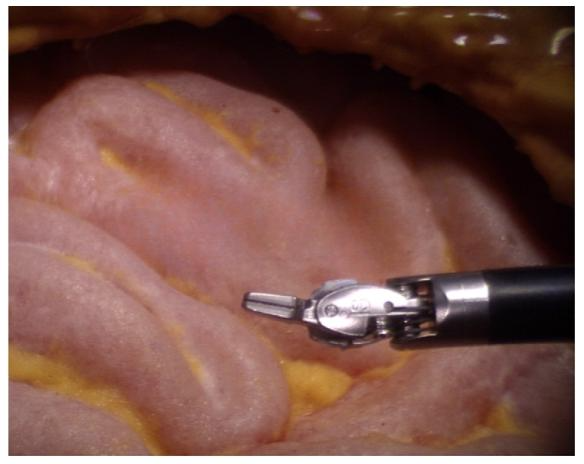
Fig. 2. Non-occlusion image sample.
图2. 无遮挡图像样本
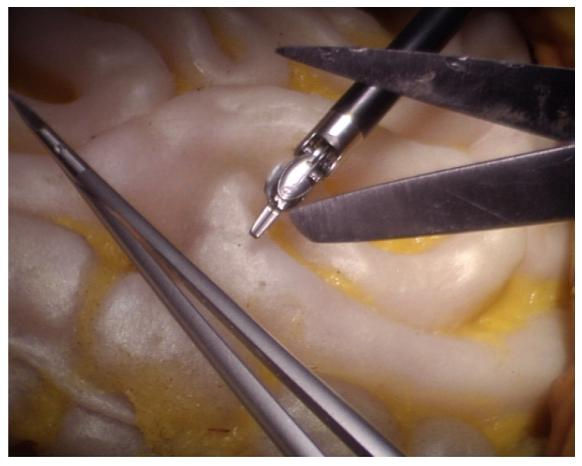
Fig. 3. Occlusion image sample.
图3. 有遮挡图像样本
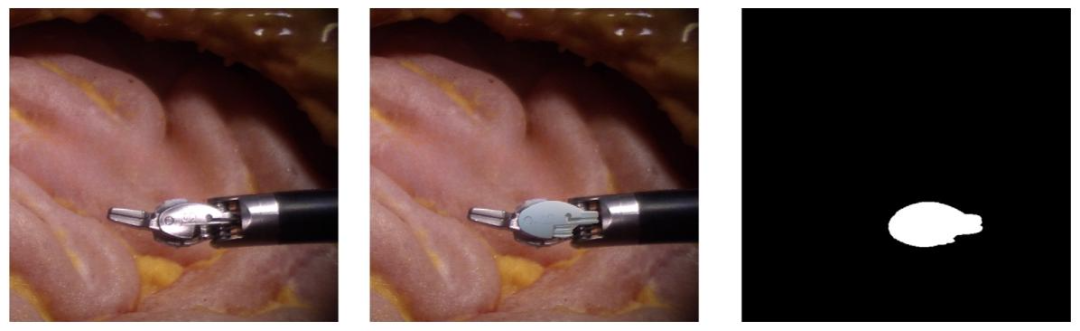
Fig. 4. (Left) The raw RGB image. (Middle) Projection of the 3D model onto the raw image given the estimated 6DoF pose. (Right) The final segmentation result
图4. (左)原始RGB图像。(中)基于估计的6自由度位姿将3D模型投影到原始图像上的结果。(右)最终分割结果
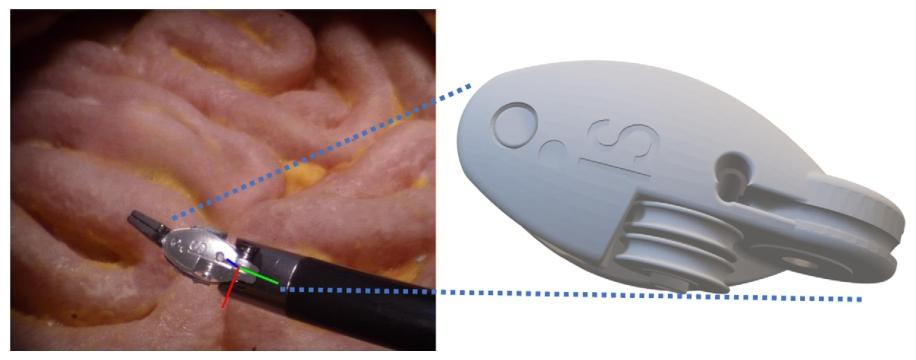
Fig. 5. Projection of the 3D model onto the 2D image.
图5. 3D模型到2D图像的投影结果
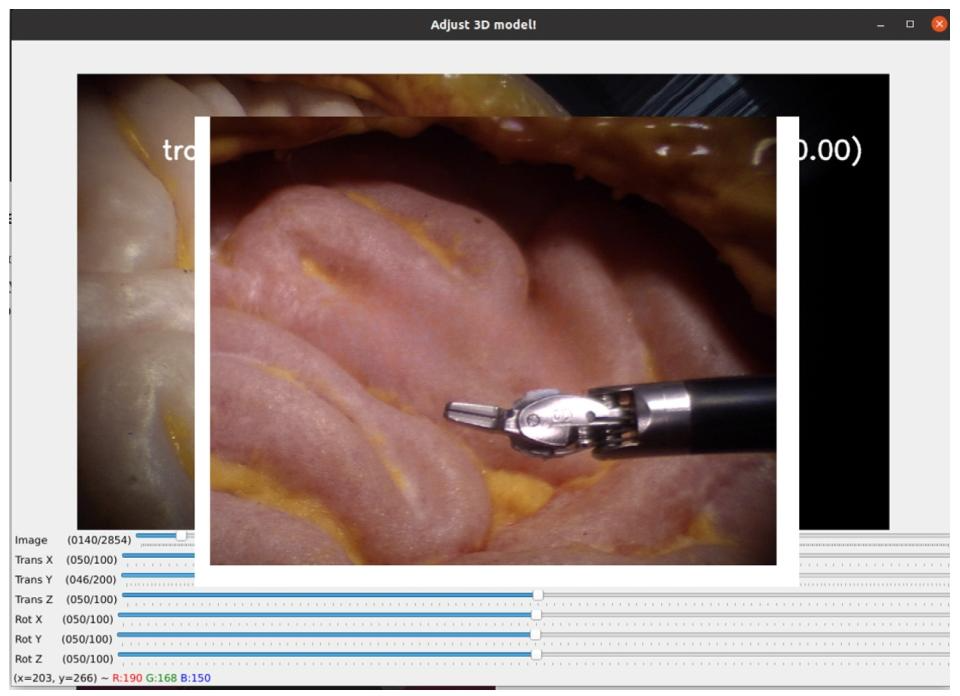
Fig. 6. GUI for 3D pose alignment
图6. 3D位姿对齐图形用户界面(GUI)
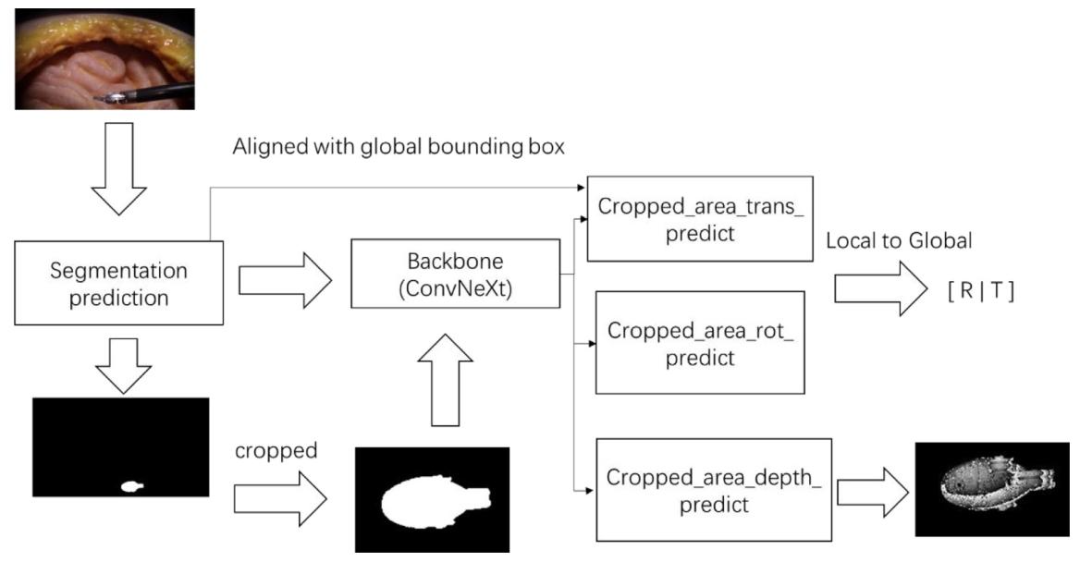
Fig. 7. TUDU architecture diagram. The method includes (1) The segmentation branch which segments and crops the instrument. (2) The pose prediction branch where thebackbone network predicts the tool pose based on the cropped regions.
图7. TUDU架构图 该方法包括:(1)分割分支,用于分割并裁剪器械;(2)位姿预测分支,其中骨干网络基于裁剪区域预测工具位姿。
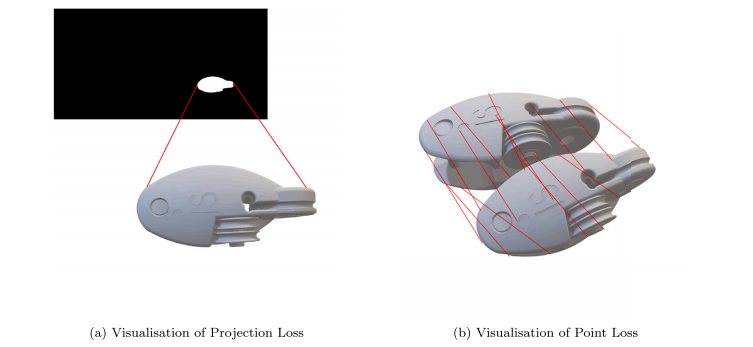
Fig. 8. Visualization of multi losses in UOL method
图8. UOL方法中多损失函数的可视化结果
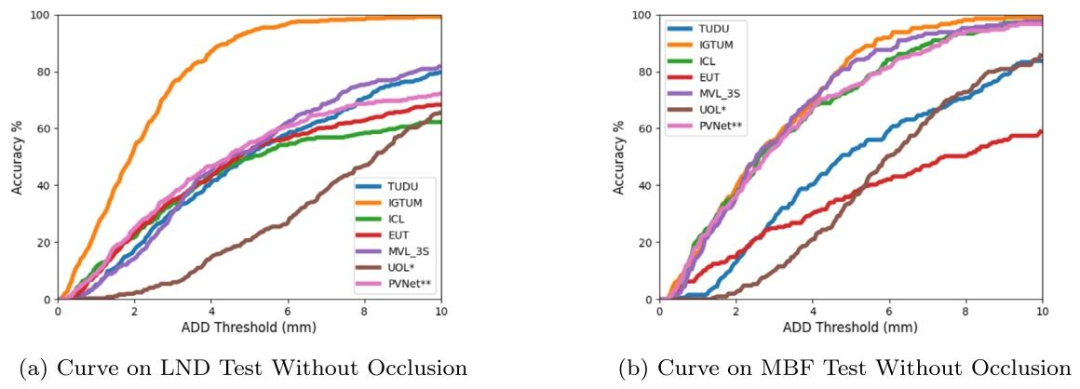
Fig. 9. Accuracy--ADD threshold curves for test data in testsets without occlusion.
图9. 无遮挡测试集数据的精度-ADD阈值曲线
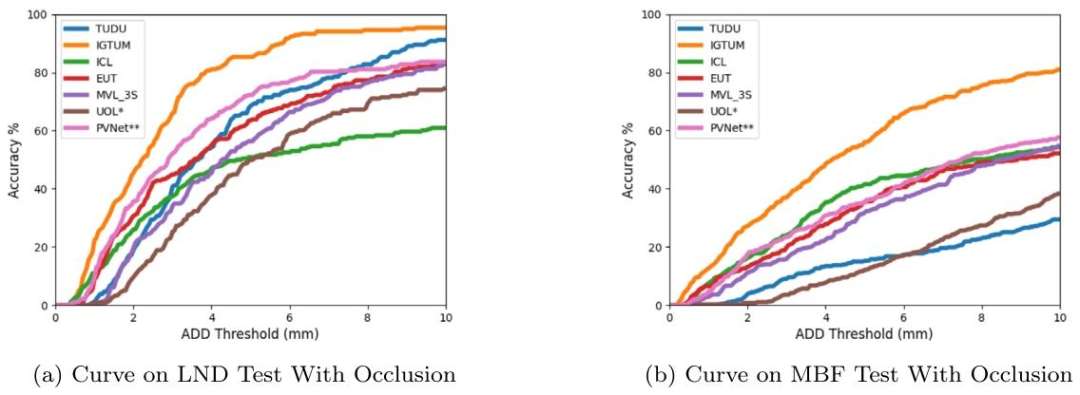
Fig. 10. Accuracy--ADD threshold curves for test data in testsets with occlusion.
图10. 有遮挡测试集数据的精度-ADD阈值曲线
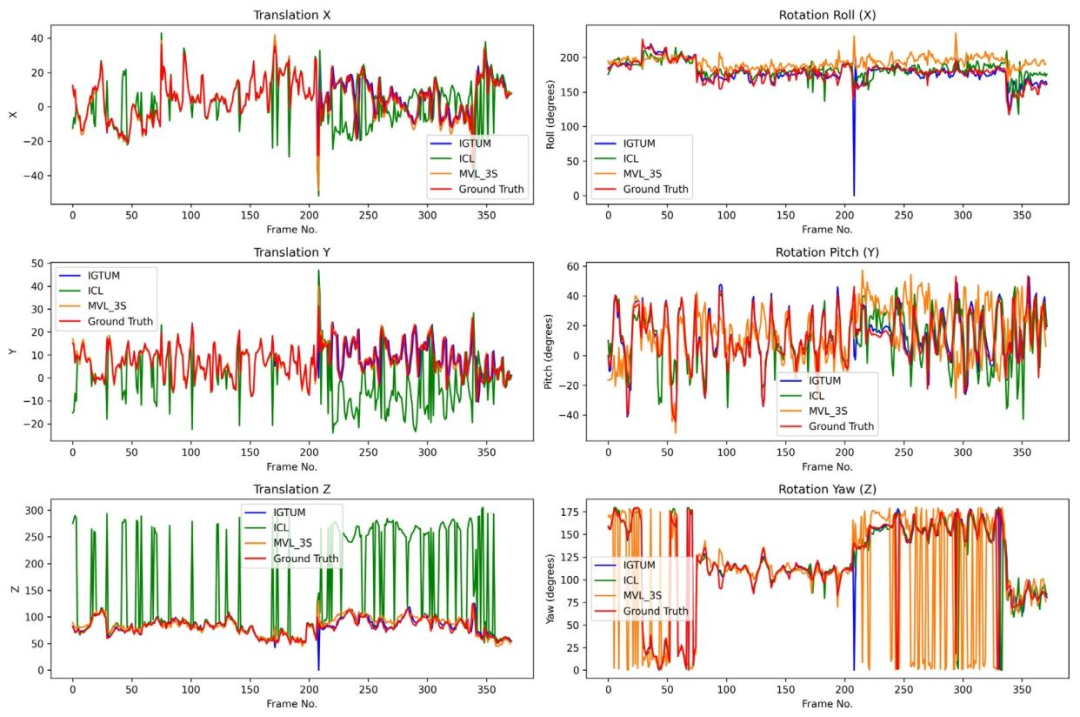
Fig. 11. Trajectory comparison in LND test without occlusion
图11. LND测试集无遮挡场景下的轨迹对比结果
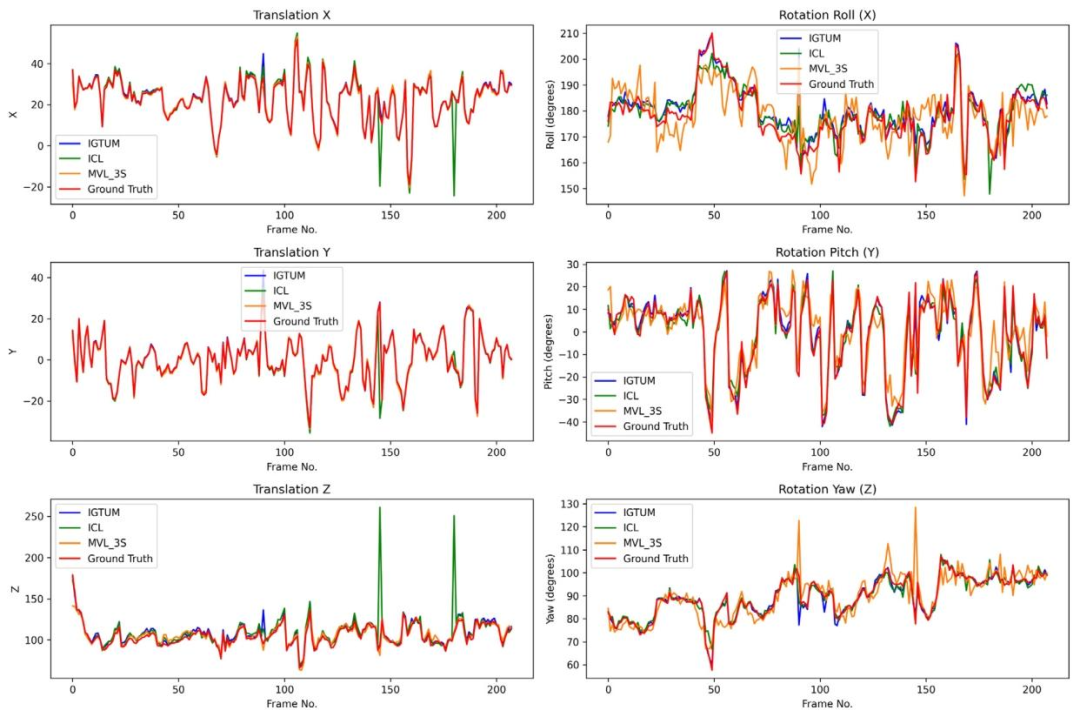
Fig. 12. Trajectory comparison in MBF test without occlusion.
图12. MBF测试集无遮挡场景下的轨迹对比结果
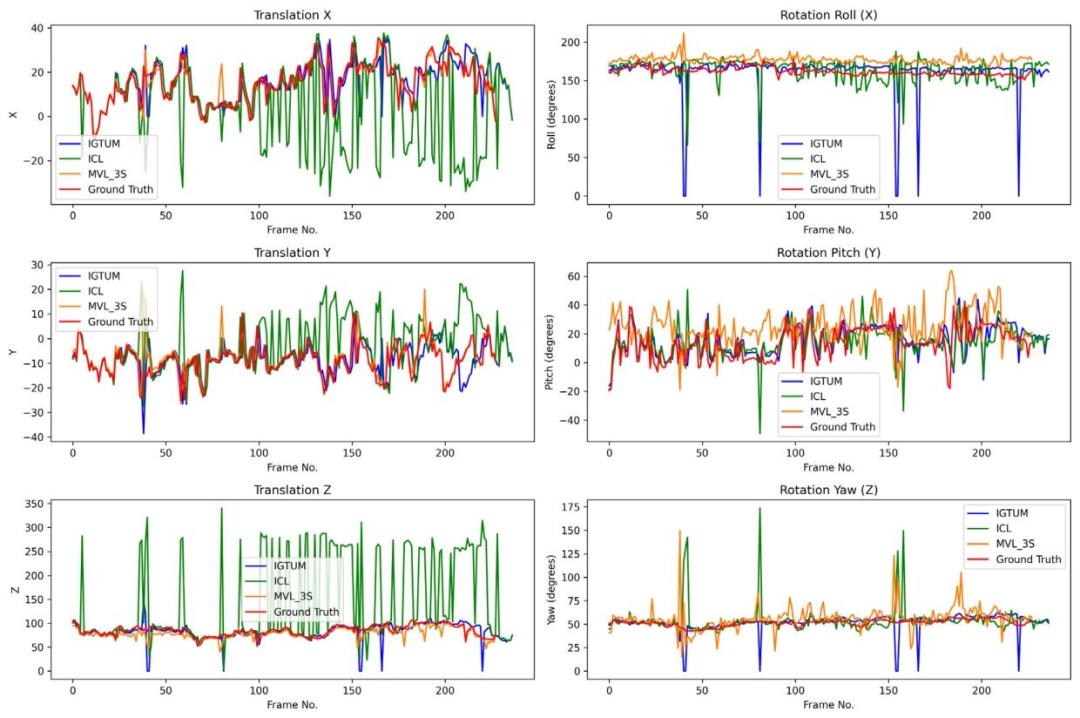
Fig. 13. Trajectory comparison in LND test with occlusion.
图13. LND测试集有遮挡场景下的轨迹对比结果
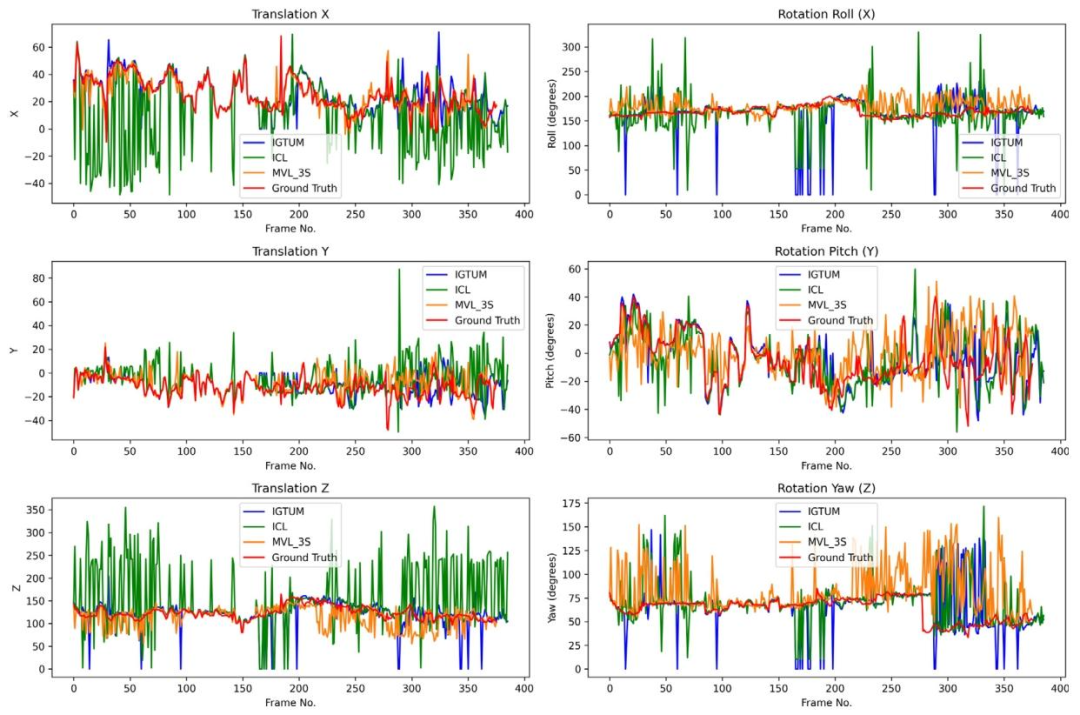
Fig. 14. Trajectory comparison in MBF test with occlusion.
图14. MBF测试集有遮挡场景下的轨迹对比结果

Fig. 15. Simulation sample images
图15. 模拟样本图像
Table
表

Table 1Comparison of the surgical tool localization datasets
表1 手术工具定位数据集对比
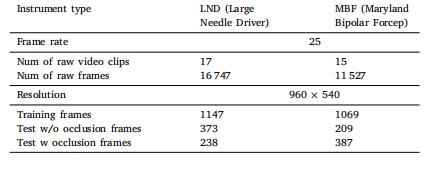
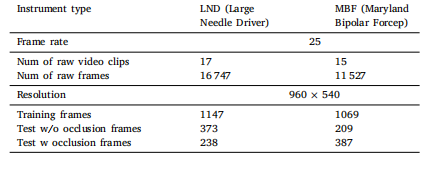
Table 2Description of the generated dataset.
表2 生成数据集的说明
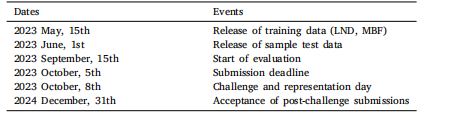
Table 3Timetable for the SurgRIPE challenge.Dates E
表3 SurgRIPE挑战赛时间表 日期 E
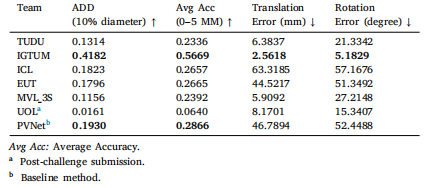
Table 4Evaluation on LND Test Without Occlusion subset. Best 2 methods are in bold.
表4 基于LND测试集无遮挡子集的评估结果 排名前2的方法以粗体标注。
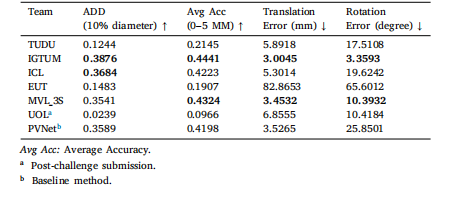
Table 5Evaluation on MBF Test Without Occlusion subset. Best 2 methods are in bold.
表5 基于MBF测试集无遮挡子集的评估结果 排名前2的方法以粗体标注。
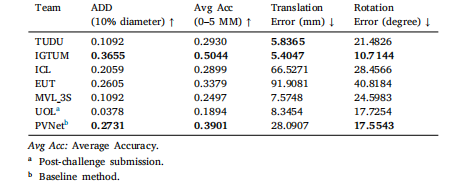
Table 6Evaluation on LND Test With Occlusion. Best 2 methods are in bold.
表6 基于LND测试集有遮挡子集的评估结果 排名前2的方法以粗体标注。
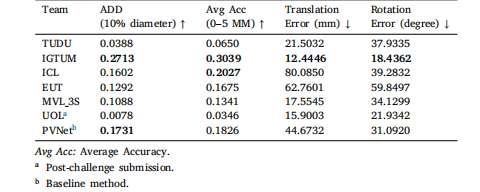
Table 7Evaluation on MBF Test With Occlusion. Best 2 methods are in bold.
表7 基于MBF测试集有遮挡子集的评估结果 排名前2的方法以粗体标注。
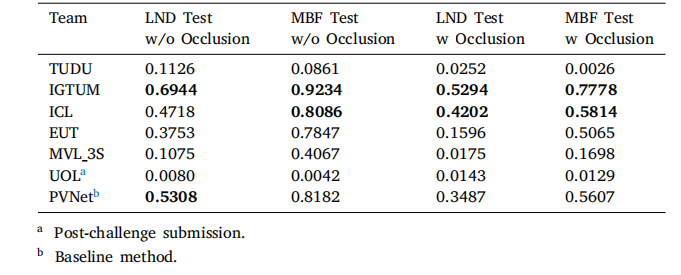
Table 8Evaluation on proj2d. Best 2 methods are in bold
表8 基于proj2d的评估结果 排名前2的方法以粗体标注。
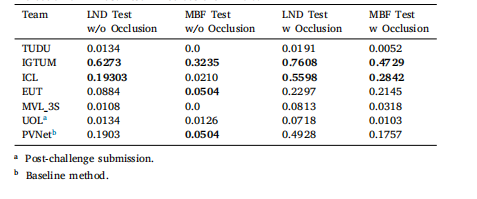
Table 9Evaluation on mmd5. Best 2 methods are in bold
表9 基于mmd5的评估结果 排名前2的方法以粗体标注。