依赖
xml
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<java.version>17</java.version>
<spring.boot.version>3.5.0</spring.boot.version>
<spring-ai.version>1.0.0</spring-ai.version>
<lombok.version>1.18.20</lombok.version>
<mybatis-plus.version>3.5.7</mybatis-plus.version>
<fastjson.version>1.2.83</fastjson.version>
<hutool.version>5.8.25</hutool.version>
</properties>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-openai</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-deepseek</artifactId>
</dependency>
<!--持久化插件-->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-chat-memory-repository-jdbc</artifactId>
</dependency>
<!--rag相关-->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-rag</artifactId>
</dependency>
<!--向量化存储,这里用Postgresql-->
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>42.7.5</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pgvector-store</artifactId>
</dependency>
<!-- pg-->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-pgvector</artifactId>
</dependency>
<!-- JDBC-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
</dependency>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>42.7.5</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-spring-boot3-starter</artifactId>
<version>${mybatis-plus.version}</version>
</dependency>
<!--文档解析插件-->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-markdown-document-reader</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pdf-document-reader</artifactId>
</dependency>
<!--其他-->
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>${hutool.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-log4j2</artifactId>
</dependency>配置文件
- 只展示Springai 相关配置
yaml
spring:
datasource:
mysql:
jdbc-url: jdbc:mysql://localhost:3306/scai?serverTimezone=Asia/Shanghai&useSSL=false&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&transformedBitIsBoolean=true&tinyInt1isBit=false&allowPublicKeyRetrieval=true&allowMultiQueries=true&useServerPrepStmts=false
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: root
postgres:
jdbc-url: jdbc:postgresql://localhost:5432/postgres
driver-class-name: org.postgresql.Driver # 建议明确指定驱动类
username: sats
password: 123456
ai:
vectorstore:
pgvector:
# datasource: postgres
inde-type: HNSW
dimensions: 1024
distance-metric: COSINE_DISTANCE
max-document-batch-size: 10000
chat:
memory:
repository:
# jdbc持久方式,查找jdbcTemplate
jdbc:
initialize-schema: ALWAYS
platform: mariadb
deepseek:
api-key: ni DeepSeek Key
base-url: https://api.deepseek.com
chat:
options:
model: deepseek-chat
openai:
base-url: https://dashscope.aliyuncs.com/compatible-mode
api-key: 你的openaikey或者支持openai规范的也行,吧URL和model换了
chat:
options:
model: qwen-max-latest
embedding:
options:
model: text-embedding-v3
dimensions: 1024数据源配置
- 由于有两个数据源Mysql和Postgresql,jdbcTemplate会冲突,故自定义
less
@Configuration
@Slf4j
public class DataSourceConfiguration {
// 主数据源配置(MySQL)
@Bean
@Primary
@ConfigurationProperties("spring.datasource.mysql")
public DataSource mysqlDataSource() {
return DataSourceBuilder.create().build();
}
// PostgreSQL数据源配置
@Bean
@ConfigurationProperties(prefix = "spring.datasource.postgres")
public DataSource postgresqlDataSource() {
log.info("创建。。。。。。。 postgresql <UNK>");
return DataSourceBuilder.create().build();
}
@Bean
@Primary // mysql----> 直接当作name为jdbcTemplate
public JdbcTemplate mysqlJdbcTemplate( @Qualifier("mysqlDataSource") DataSource dataSource) {
return new JdbcTemplate(dataSource);
}
@Bean
public JdbcTemplate postgresqlJdbcTemplate( @Qualifier("postgresqlDataSource") DataSource dataSource) {
log.info("创建。。。。。。。");
return new JdbcTemplate(dataSource);
}
}持久化目标
Spring AI自带持久化。记录会话内容
xml
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-chat-memory-repository-jdbc</artifactId>
</dependency>- 插件的JDBCChatMemoryRepository实现了springai ChatMemoryRepository提供的增删改查接法,通过注入JdbcTemplate
- 装配一个ChatMemory(以JDBC方式)Bean
scss
@Bean
public ChatMemory chatMemory(ChatMemoryRepository chatMemoryRepository) {
return MessageWindowChatMemory.builder()
.chatMemoryRepository(chatMemoryRepository)
.maxMessages(20)
.build();
}- 通过chatMemory就可以实现会上上下文记录,这个是spring自带的,表大概这样,需要手动设置字符utf8m64,要不然LLM回复的字符部分不能存
sql
-- auto-generated definition
create table SPRING_AI_CHAT_MEMORY
(
conversation_id varchar(36) not null,
content mediumtext not null,
type varchar(10) not null,
timestamp timestamp default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP
);- 以conversation_id标识相同会话,type记录是提问或者回答,可自定义
给不同用户、不同新会话建立关联
做到常见的网页端效果
在SPRING_AI_CHAT_MEMORY基础上,新建一个表
sql
-- 建数据库
create database if not exists scai character set utf8mb4;
-- 创建表
CREATE TABLE `d_chat_type_history` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键id',
`type` int NOT NULL COMMENT '会话类型,详见ChatType枚举',
`chat_id` varchar(225) NOT NULL COMMENT '会话id',
`title` varchar(512) DEFAULT NULL COMMENT '标题',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`edit_time` datetime DEFAULT NULL COMMENT '编辑时间',
`status` tinyint(1) DEFAULT '1' COMMENT '1:正常 0:删除',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb3 COMMENT='会话历史表';图方便就没用userid了
- 实现针对这个表的增删改查,我用的mybatisplus最终的服务类:ChatTypeHistoryService。
模型AI交互的ChatClient
- 由于我们引入了DeepSeek和OpenAI, 就会有对应的ChatModel,name="deepSeekChatModel", name="openAiChatModel"
- 实现和大模型的对话,通过ChatClient实现,通过自动装配方式配置,chatModel,advisor,systemPrompt等
advisor就相当于和AI交互的拦截器
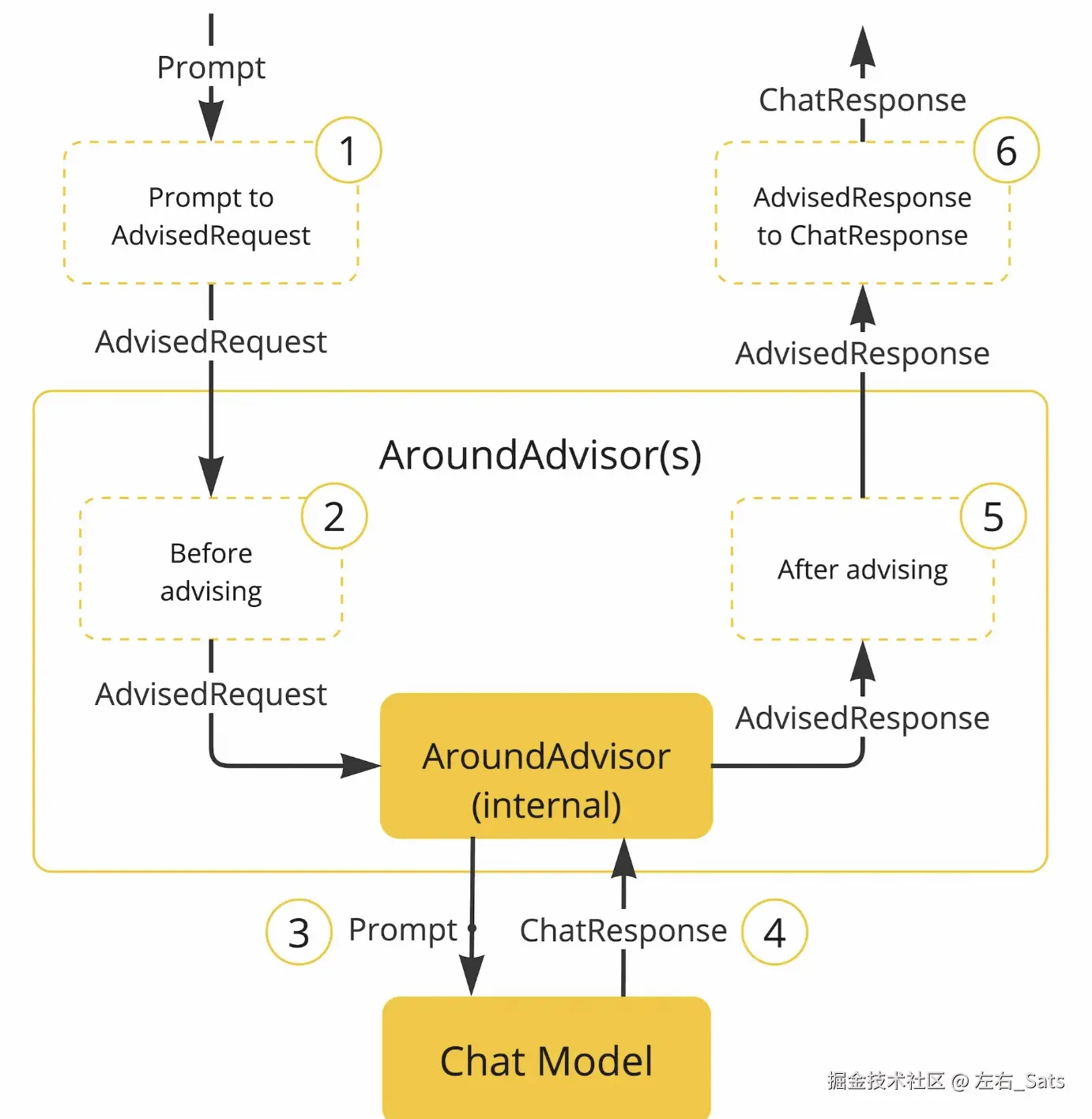
- 最简单的创建
less
@Bean
public ChatClient chatClient ( @Qualifier("deepSeekChatModel") ChatModel deepSeekChatModel) {
return ChatClient.builder(deepSeekChatModel).build();
} 配置一个助手ChatClient
助手目标:
- 限定助手角色
- 实现spring自带会话记忆,通过mysql持久化
- 实现我们想额外存储的会话
实现步骤
less
@Bean
public ChatClient loveChatClient( @Qualifier("deepSeekChatModel") ChatModel deepSeekChatModel, ChatMemory chatMemory,
ChatTypeHistoryService chatTypeHistoryService, @Qualifier("titleChatClient")ChatClient titleChatClient) {
return ChatClient.builder(deepSeekChatModel)
.defaultSystem(SystemPrompt.SYSTEM_PROMPT) // 角色
.defaultAdvisors(
new SimpleLoggerAdvisor(),
ChatTypeHistoryAdvisor.builder(chatTypeHistoryService).type(ChatType.ASSISTANT.getCode())
.order(998).build(),
ChatTypeTitleAdvisor.builder(chatTypeHistoryService).type(ChatType.ASSISTANT.getCode())
.chatClient(titleChatClient).chatMemory(chatMemory).order(999).build(),
MessageChatMemoryAdvisor.builder(chatMemory).order(1000).build()
) // 拦截器
.build();
}- defaultAdvisors实现传递了4个advisor
- SimpleLoggerAdvisor日志打印,没有传递order,默认最高
- ChatTypeHistoryAdvisor用于在表d_chat_type_history新建一条记录保存会话ID
- ChatTypeTitleAdvisor用于给本次对话生成标题,需要在传入一个chatClient,我们新创建一个简单的titleChatClient,通过titleChatClient让AI生成标题
less
@Bean
public ChatClient titleChatClient( @Qualifier("deepSeekChatModel") ChatModel deepSeekChatModel) {
return ChatClient
.builder(deepSeekChatModel)
.defaultAdvisors(
new SimpleLoggerAdvisor()
)
.build();
}- MessageChatMemoryAdvisor用于保存对话到SPRING_AI_CHAT_MEMORY
- 整体交互链路:
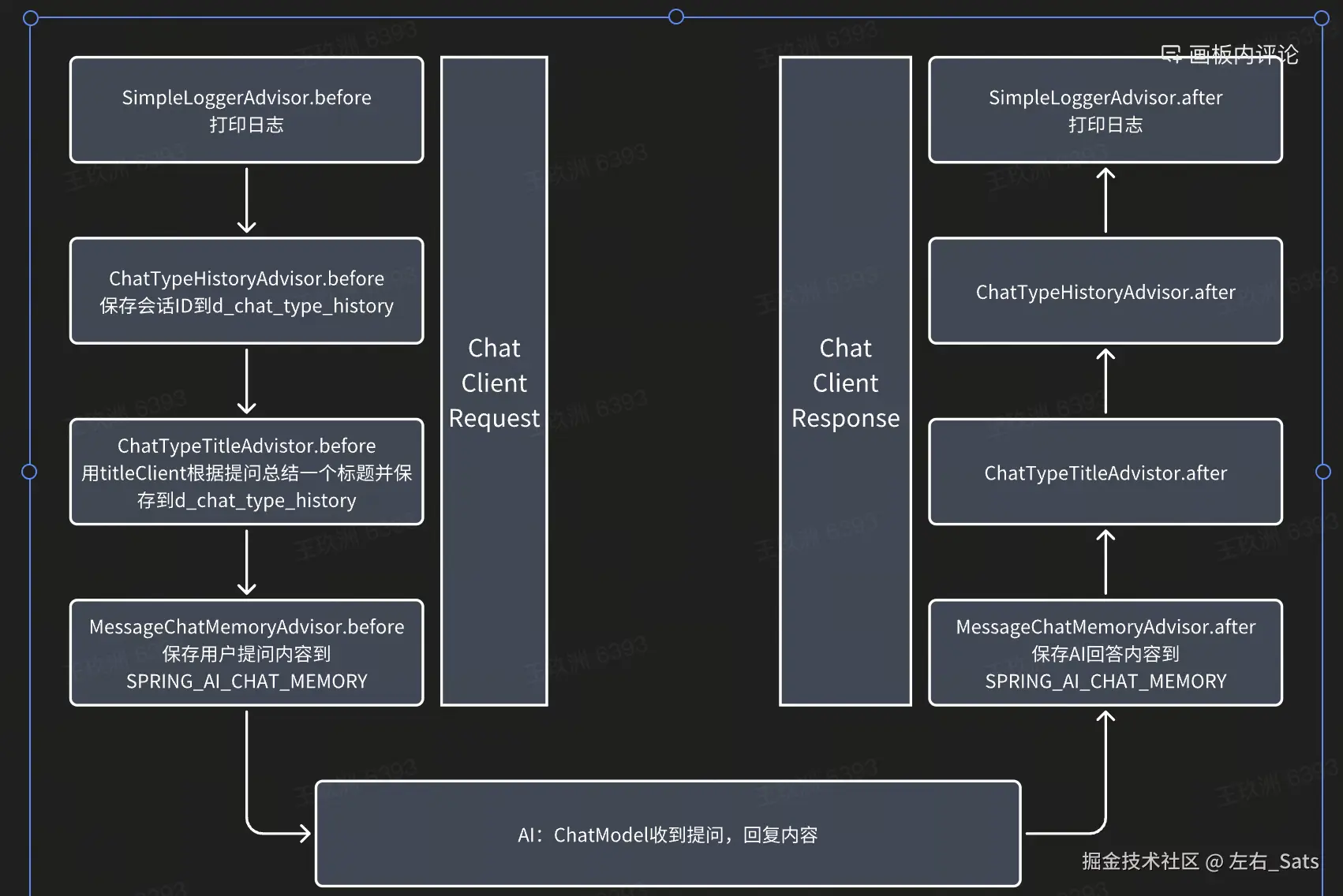
advisor的实现
- 实现CallAdvisor, StreamAdvisor接口, 重写方法
kotlin
public ChatClientResponse adviseCall(ChatClientRequest chatClientRequest, CallAdvisorChain callAdvisorChain) {
this.logRequest(chatClientRequest);
ChatClientResponse chatClientResponse = callAdvisorChain.nextCall(chatClientRequest);
this.logResponse(chatClientResponse);
return chatClientResponse;
}
public Flux<ChatClientResponse> adviseStream(ChatClientRequest chatClientRequest, StreamAdvisorChain streamAdvisorChain) {
this.logRequest(chatClientRequest);
Flux<ChatClientResponse> chatClientResponses = streamAdvisorChain.nextStream(chatClientRequest);
return (new ChatClientMessageAggregator()).aggregateChatClientResponse(chatClientResponses, this::logResponse);
}- 上面的ChatTypeHistoryAdvisor和ChatTypeTitleAdvisor,是基于BaseChatMemoryAdvisor实现的,BaseChatMemoryAdvisor继承BaseAdvisor继承了CallAdvisor, StreamAdvisor。
BaseChatMemoryAdvisor可以传递本次会话相关信息上下文,比如会话ID。定义了before,after方法适配链路
RAG向量知识库构建
Pgvector的接入: docs.spring.io/spring-ai/r...
VectorStore:docs.spring.io/spring-ai/r...
VectorStore
- VectorStore提供了对向量数据库的增删改查方法。继承自DocumentWriter, 也就是说VectorStore的基本操作对象是Document。
- 所以要实现知识向量入库,需要对应向量数据库的VectorStore+能够将知识转换为Document的工具。
- 通过自动装配方式来实现
PgVectorStore的配置
less
@Configuration
public class MyVectorStoreConfiguration {
@Bean
public VectorStore pgVectorVectorStore( @Qualifier("postgresqlJdbcTemplate") JdbcTemplate postgresqlJdbcTemplate,
EmbeddingModel openAIEmbeddingModel) {
VectorStore vectorStore = PgVectorStore.builder(postgresqlJdbcTemplate, openAIEmbeddingModel)
.dimensions(1024) // Optional: defaults to model dimensions or 1024
.distanceType(COSINE_DISTANCE) // Optional: defaults to COSINE_DISTANCE
.indexType(HNSW) // Optional: defaults to HNSW
.initializeSchema(true) // Optional: defaults to false
.schemaName("public") // Optional: defaults to "public"
.vectorTableName("vector_store") // Optional: defaults to "vector_store"
.maxDocumentBatchSize(10000) // Optional: defaults to 10000
.build();
return vectorStore;
}
}向量数据库一旦创建,维度确定,更换维度需要重新创建。
文档处理
Spring AI提供了系列对应的文档处理插件,可以将知识处理成SpringAI 的 document
以处理markdown为例子
ini
@Component
@Slf4j
public class MyDocumentLoader {
private final ResourcePatternResolver resourcePatternResolver;
MyDocumentLoader(ResourcePatternResolver resourcePatternResolver) {
this.resourcePatternResolver = resourcePatternResolver;
}
public List<Document> loadMarkdowns() {
List<Document> allDocuments = new ArrayList<>();
try {
Resource[] resources = resourcePatternResolver.getResources("classpath:document/*.md");
for (Resource resource : resources) {
String fileName = resource.getFilename();
MarkdownDocumentReaderConfig config = MarkdownDocumentReaderConfig.builder()
.withHorizontalRuleCreateDocument(true)
.withIncludeCodeBlock(false)
.withIncludeBlockquote(false)
.withAdditionalMetadata("filename", fileName)
.build();
MarkdownDocumentReader reader = new MarkdownDocumentReader(resource, config);
allDocuments.addAll(reader.get());
}
} catch (IOException e) {
// log.error("Markdown 文档加载失败", e);
}
return allDocuments;
}
}待续