1.机器学习包括监督学习和无监督学习
【1】在机器学习中,表示输入的标准符号是小写的x,我们称为输入变量,它也被称为特征或输入特征;表示输出变量的标准符号,即你正在尝试预测的变量,有时称为目标变量,小写的y;
2我们会使用m表示训练样本的总数;为表示单个训练样本,我们将使用符号(x,y) 
图中的i指的是表格中的特定行,不是幂运算,i只是训练中的一个索引
2. 监督学习supervised learning
【1】类似从X->Y/从输入到输出映射的算法
【2】关键特征是。你给学习算法提供包含正确答案的示例

在所有这些应用中,你首先会用输入x和正确答案(即标签y,来训练你的模型;因此后期它可以接受一个全新的输入x(它以前从未见过的),并尝试生成相应的y
3这种房价预测是监督学习的一种特定类型,称为回归:regression,即指我们试图从多个无限多个可能的数字中预测一个数字;
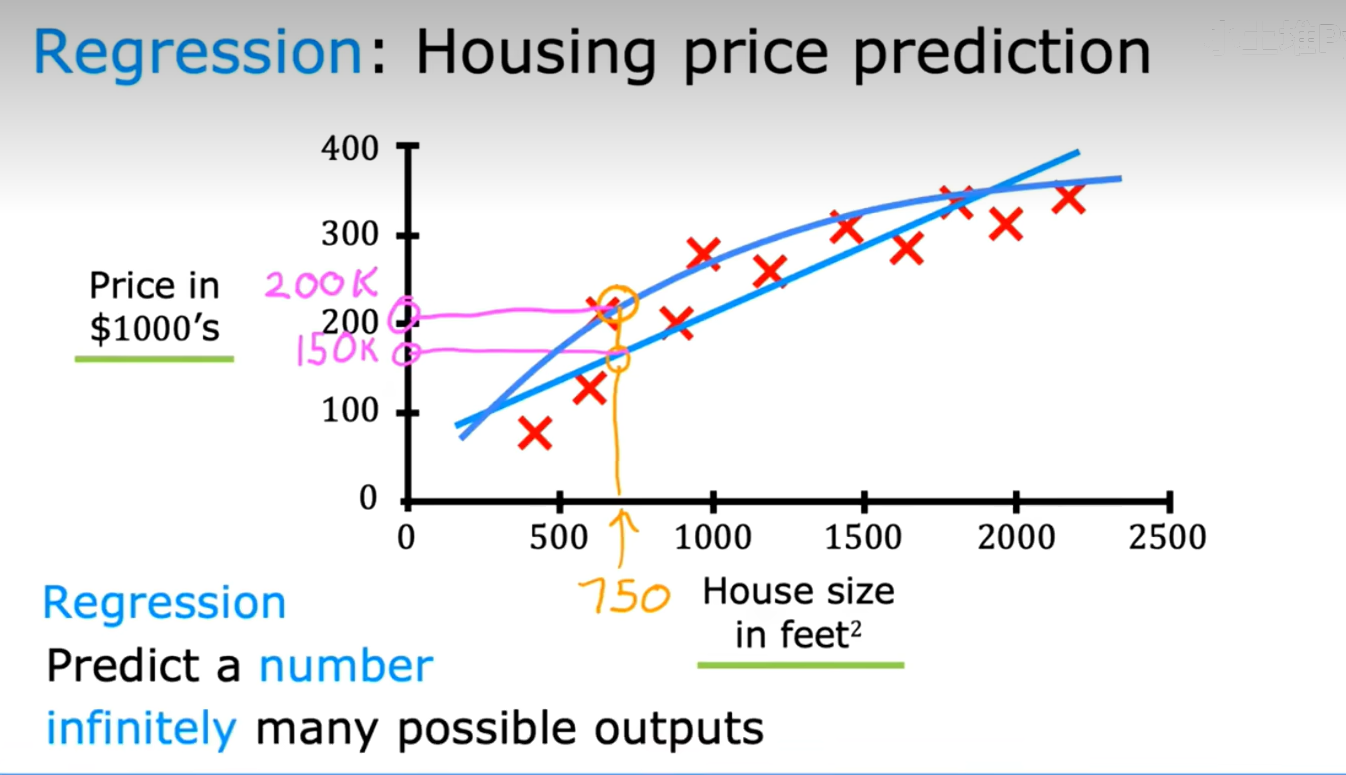
线性回归模型是一种特定的监督学习模型,它以数字作为输出

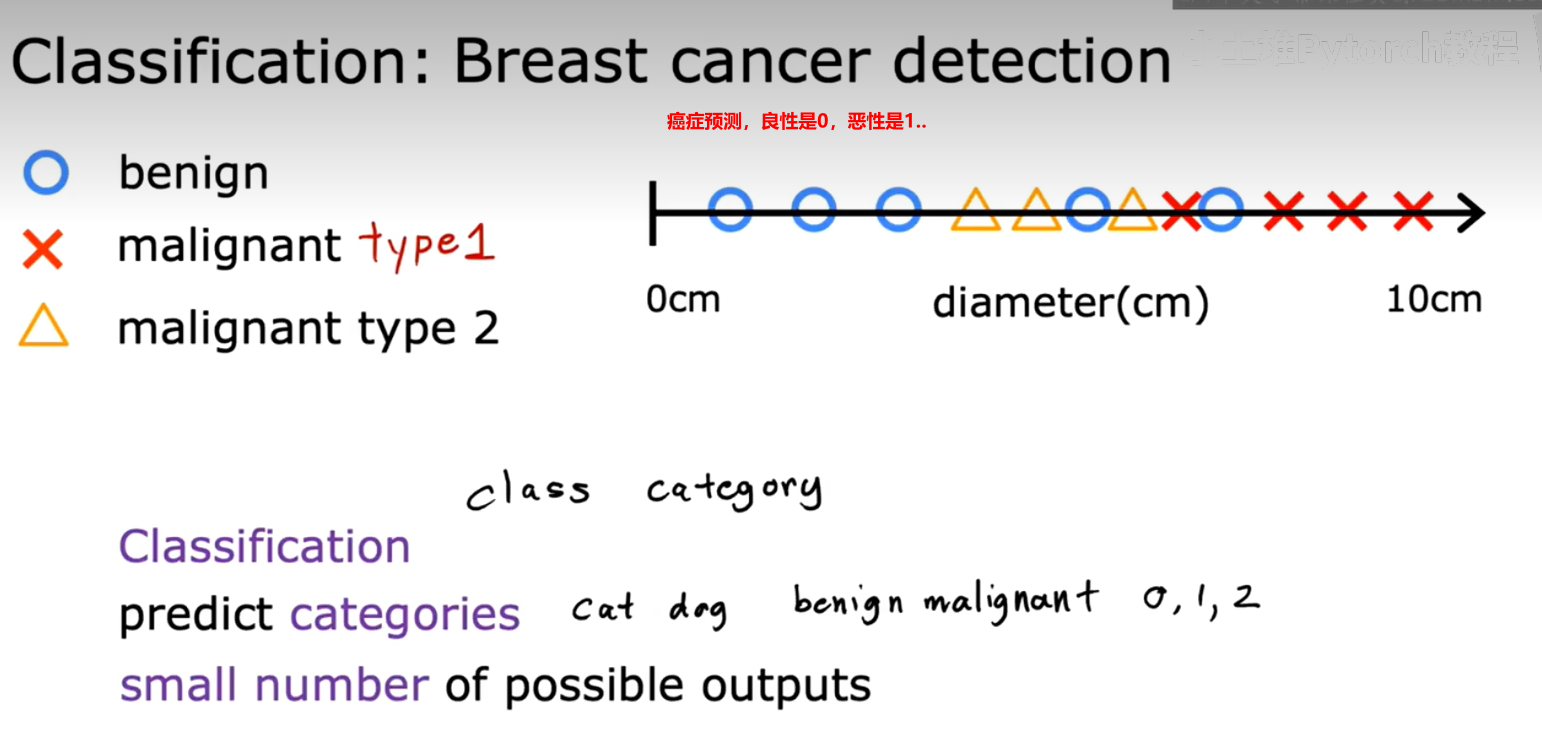
【4】还有第二种主要的监督学习问题类型,称为分类classification;这与回归不同的一个原因是,我们试图预测的只有少数几个可能的输出或类别,因此,只有两个可能的输出这一事实使得这是分类;ps:预测的类别不一定是数字,
在分类中,术语输出类和输出类别经常互换使用,
可以有多个输入,如通过年龄和良性/恶性进行划界限;
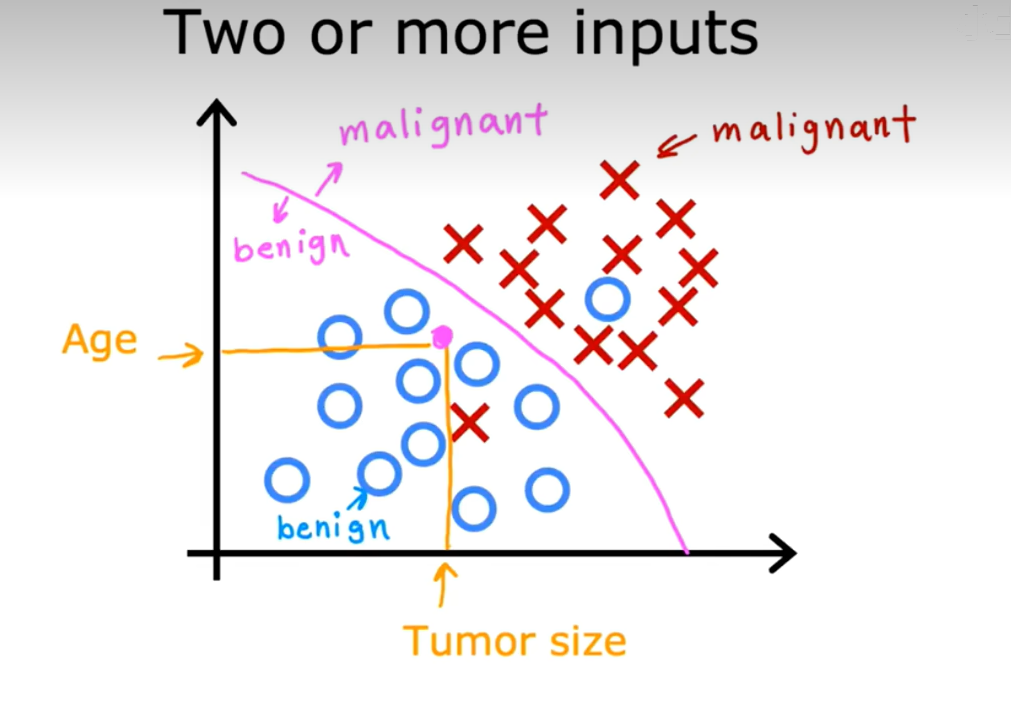
因此,学习算法必须决定如何拟合一条边界线来划分这些数据
【5】回归与分类的不同之处在于;
分类:预测的是一个小的、有限的、有限可能的输出类别集合

【6】
3.无监督学习unsupervised learning、

1不是试图监督算法为每个输入提供正确答案;而是要求算法找出数据中可能或存在的模式或结构
【2】聚类算法clustering从数篇文章中找到提到相关词语的文章,并将他们分组到簇中。
聚类算法处理无标签数据并尝试自动将他们分组到簇中
【3】无监督学习只有输入x,没有输出y标签,算法需要在这些数据中找到某种结构、模式、或有趣的东西
【4】异常检测anomaly detection用于检测异常事件
5降维dimensionality reduction,可以将大数据集几乎神奇的缩小为小得多的数据集,同时紧可能少的丢失信息
4.机器学习等需要用到一个工具JupyterNote book
1可以尝试写代码



5.成本函数和代价函数
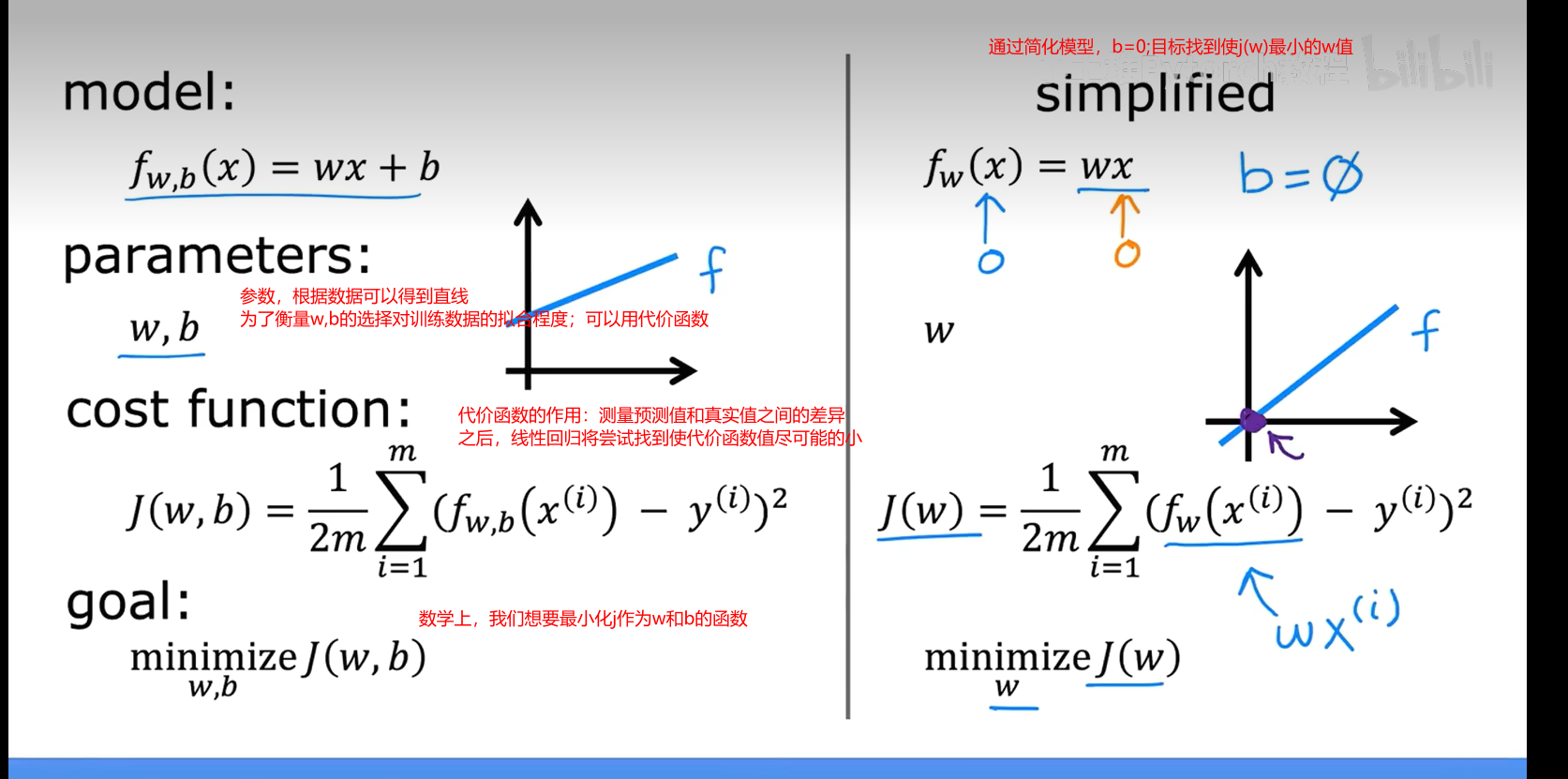
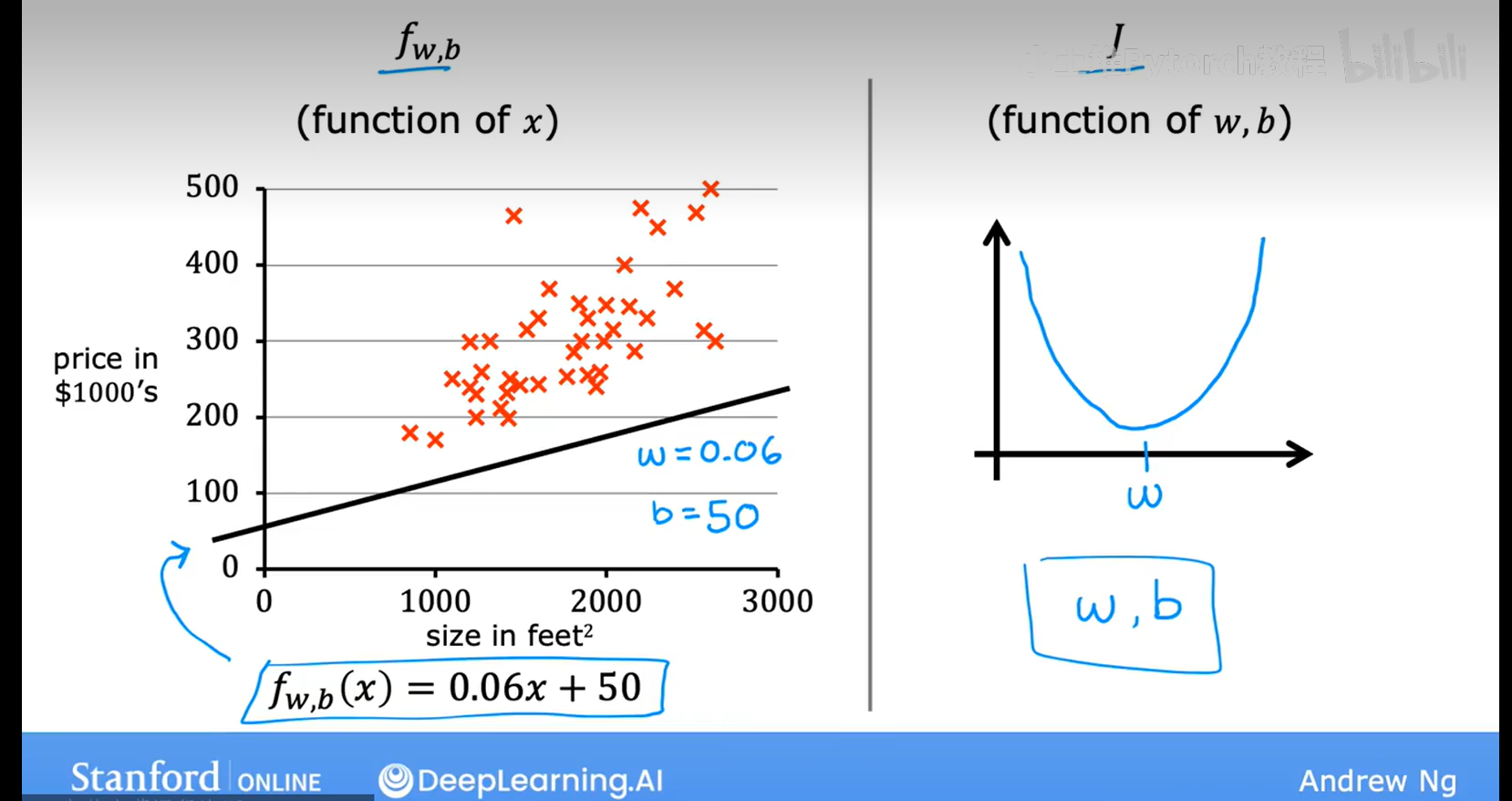
5.1介绍w和b
w,b被称为参数,有时被称为系数或权重;b也称为截距
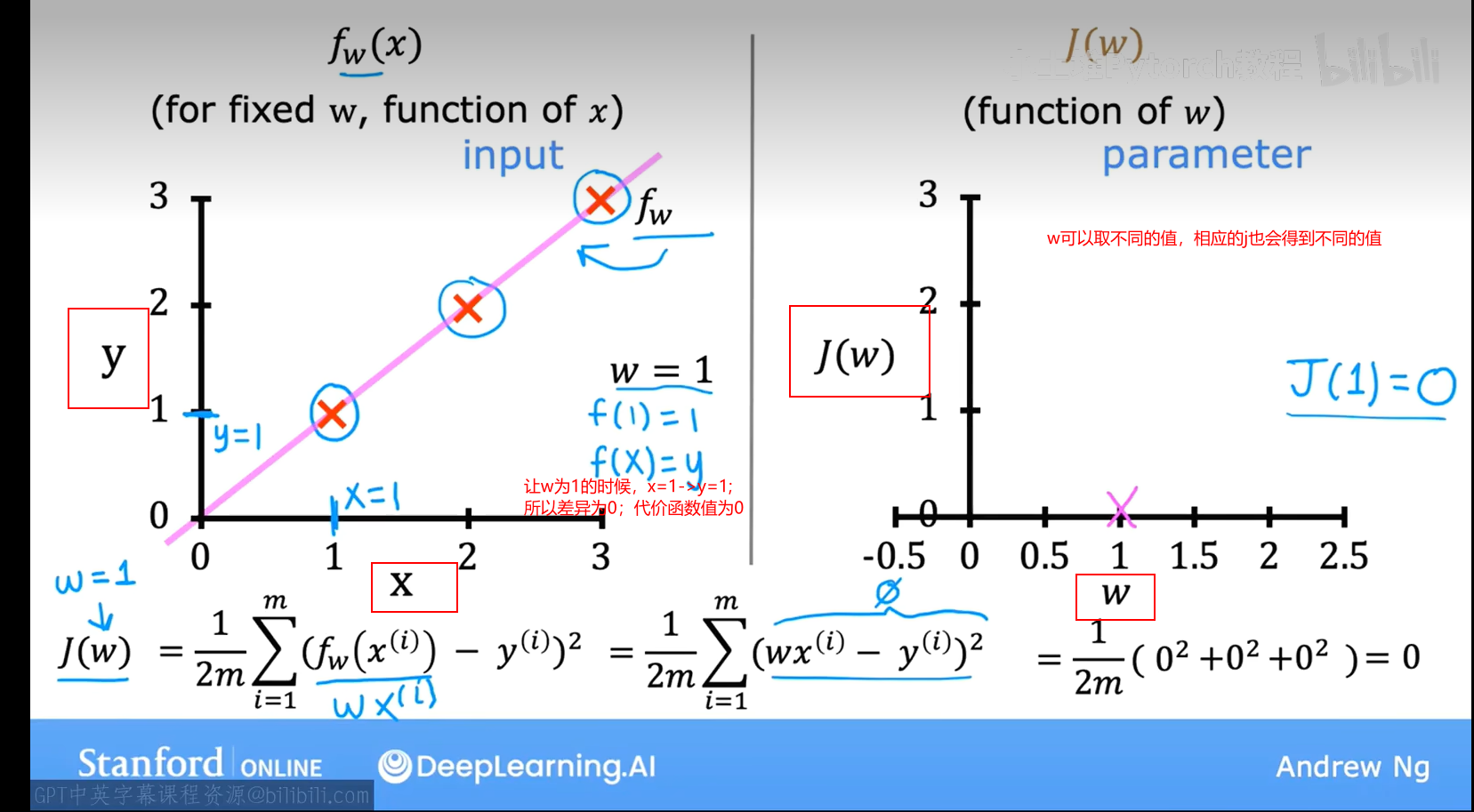
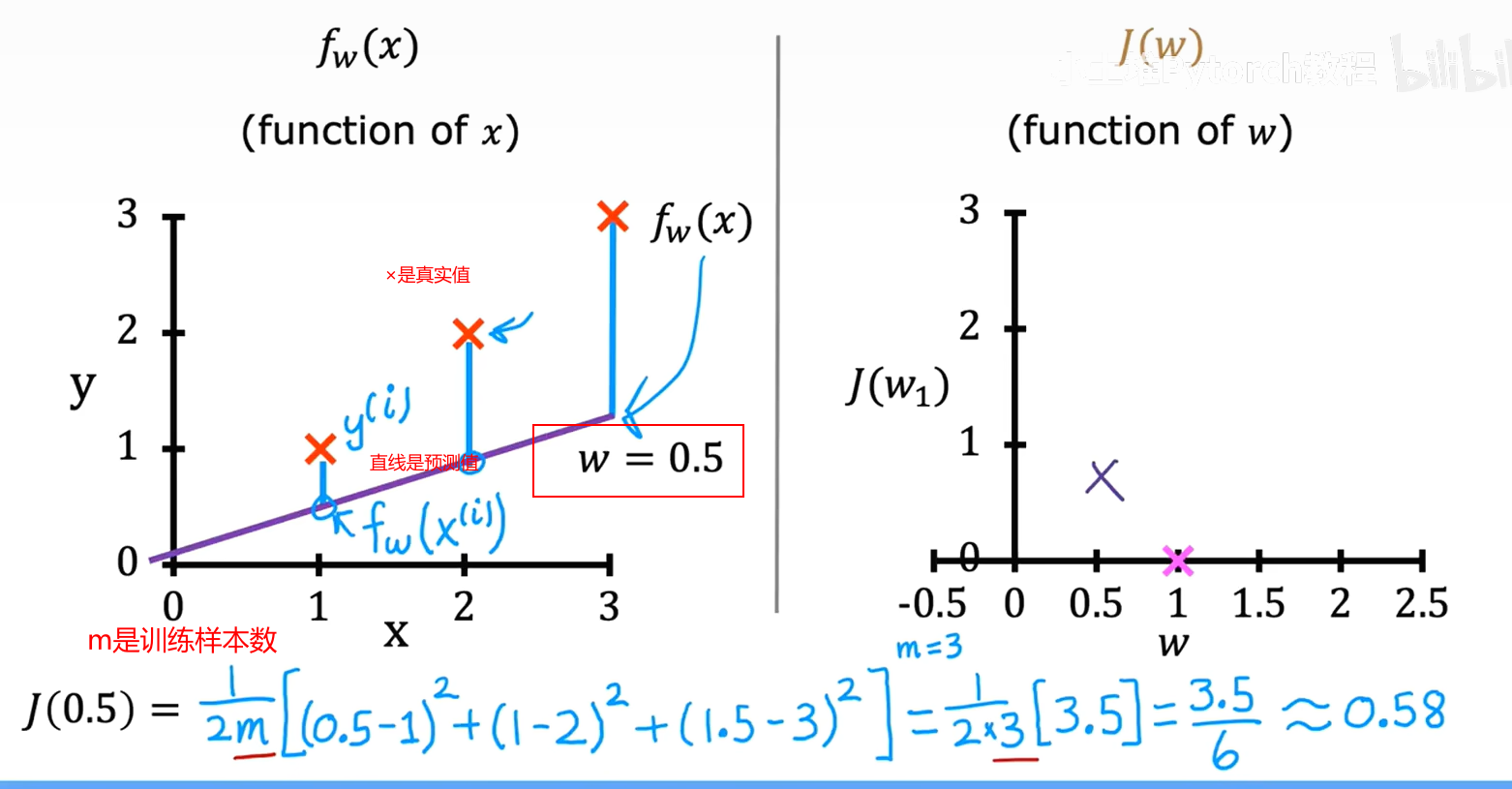
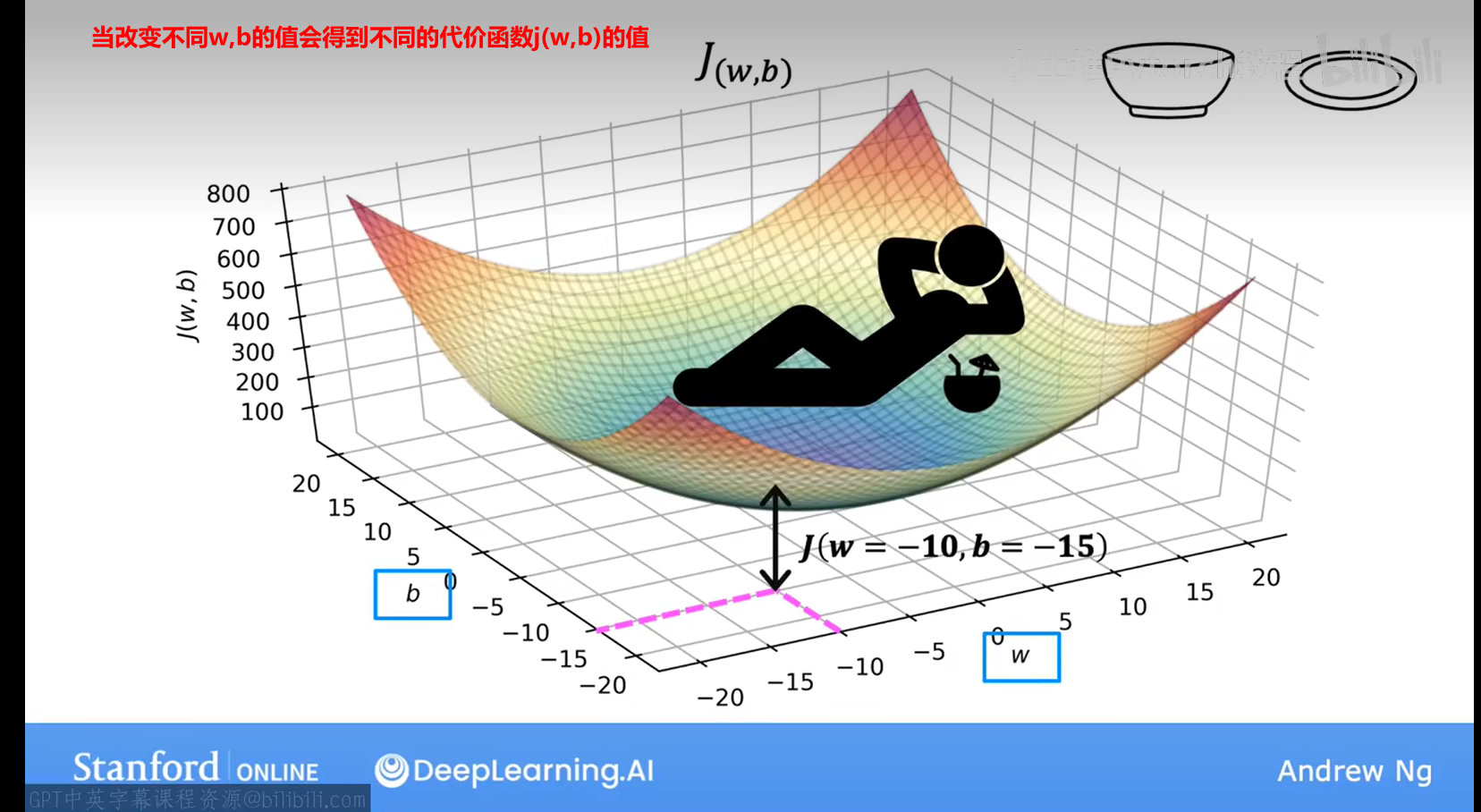
5.2代价函数(b=0)的可视化过程
代价函数也被称为平方误差代价函数,因为它是对这些误差项的平方进行计算

【3】了解如何使用代价函数来找到模型的最佳参数

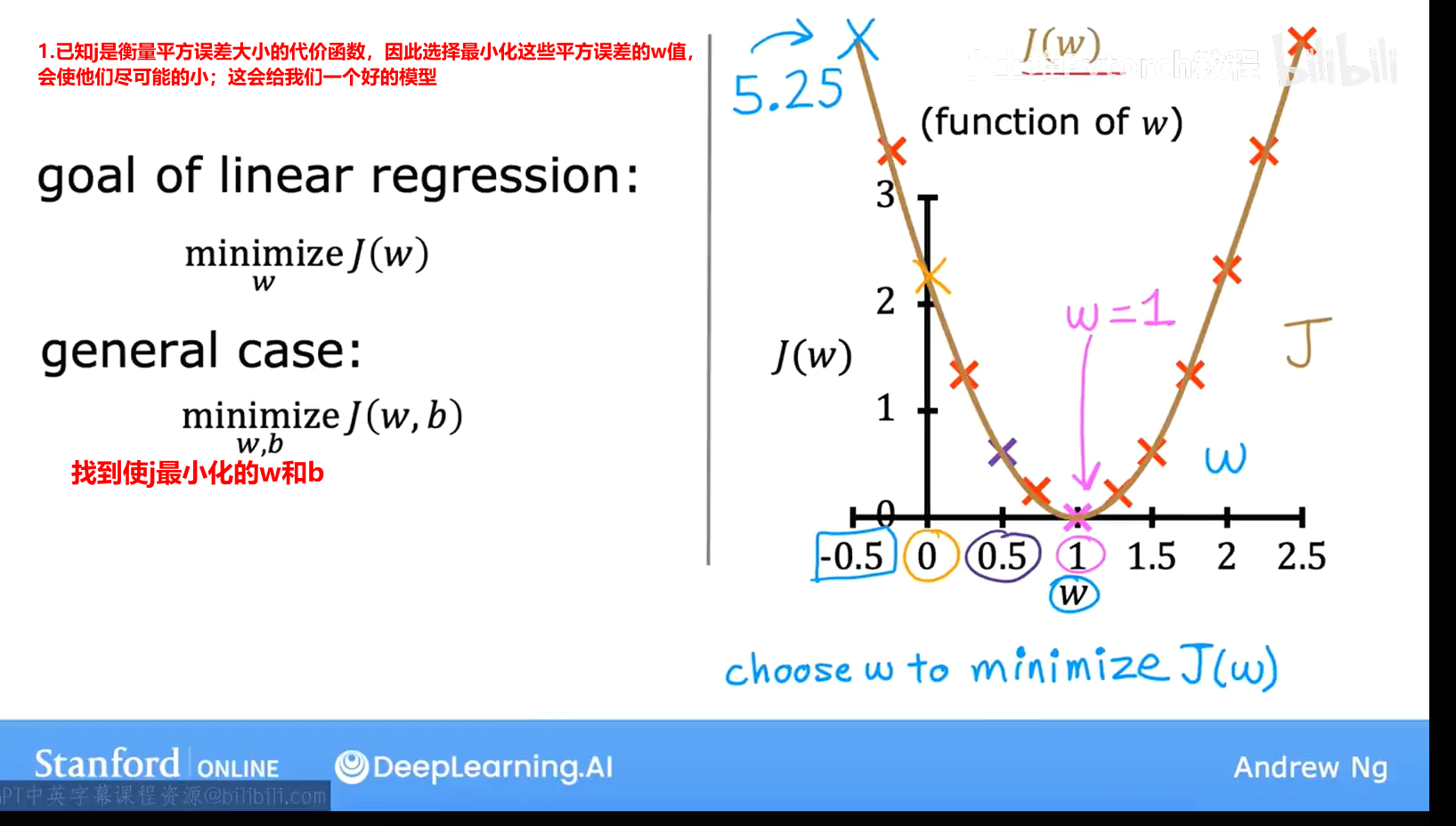
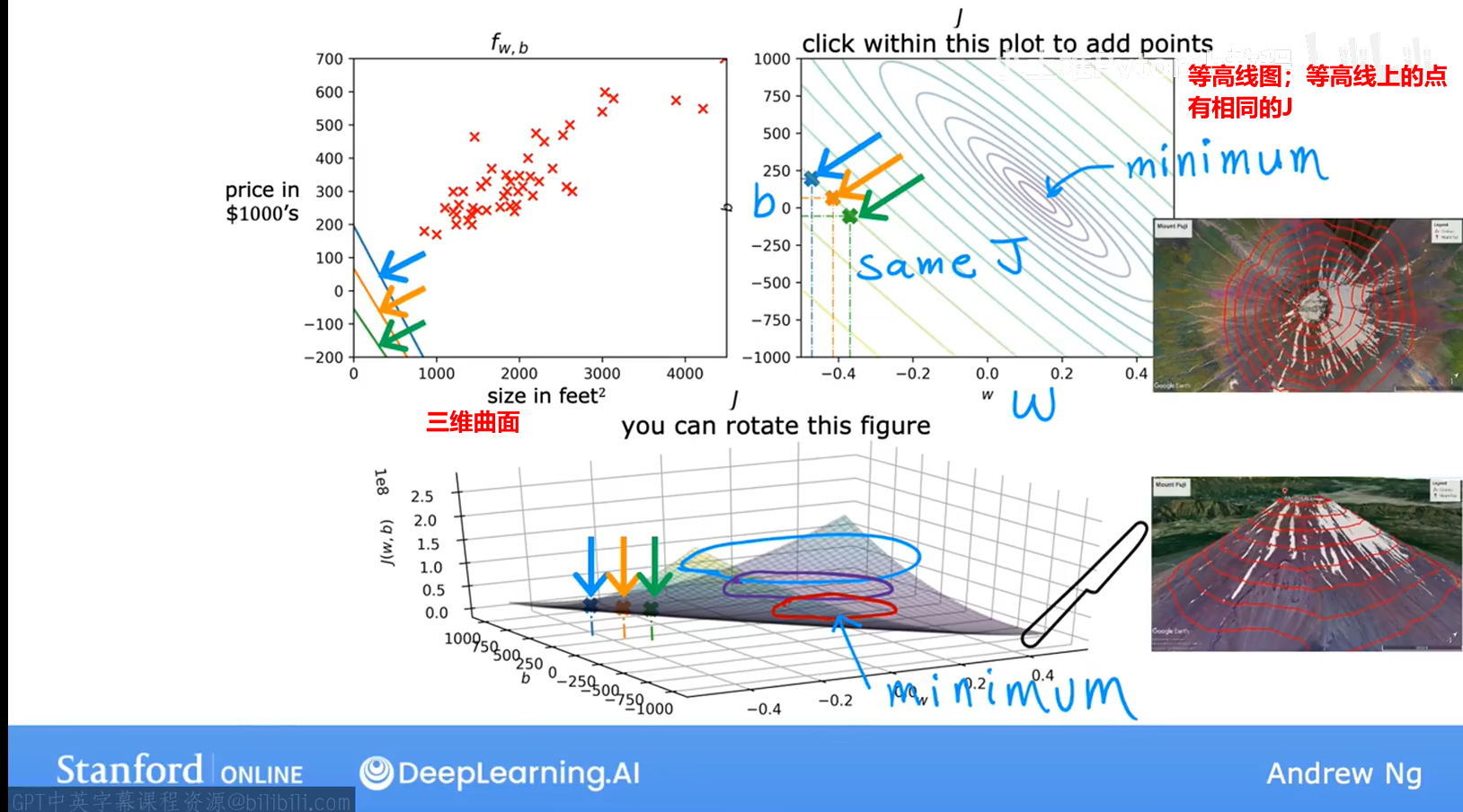
5.3 完整的代价函数可视化过程

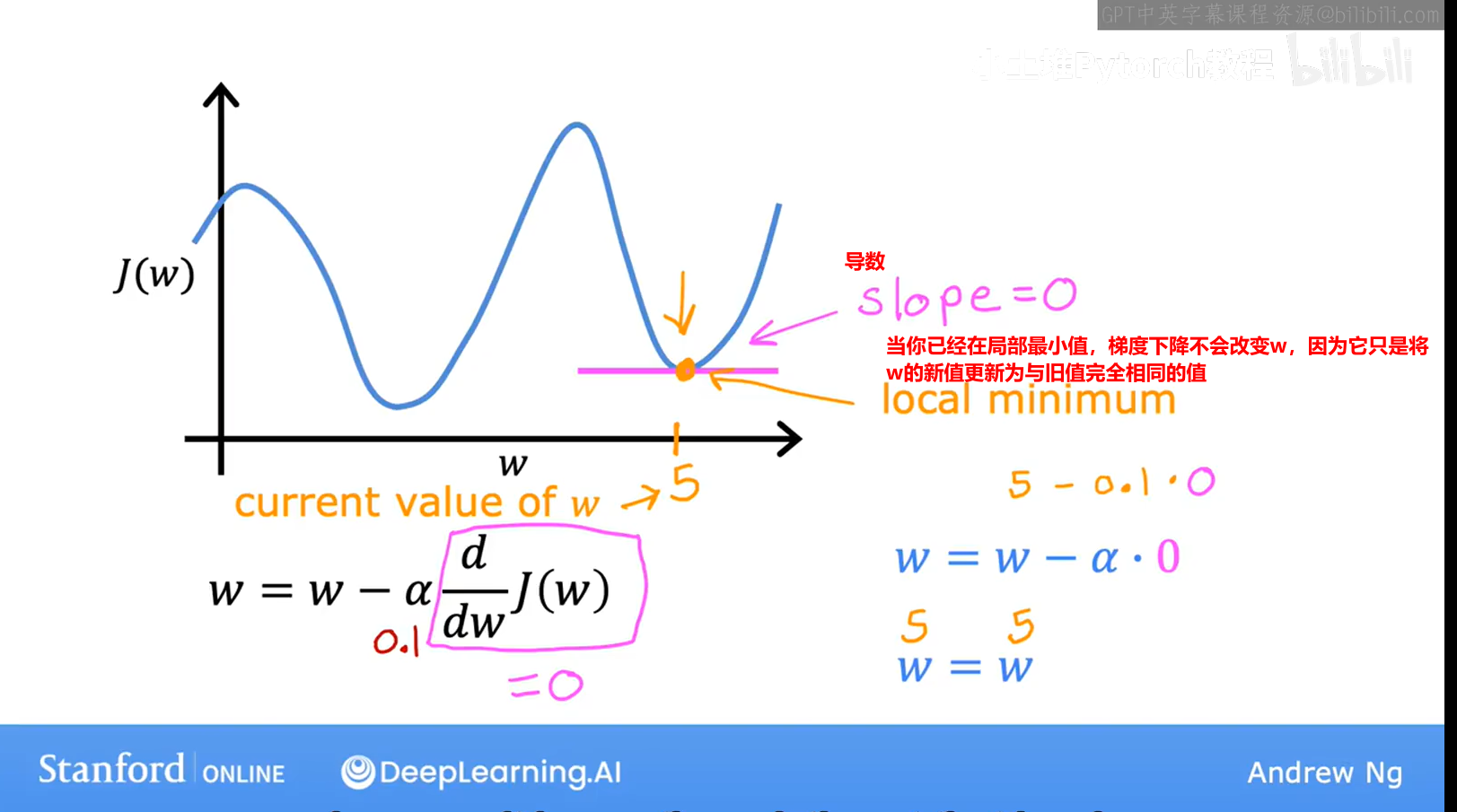
5.4梯度下降的算法可以更好的找到w,b
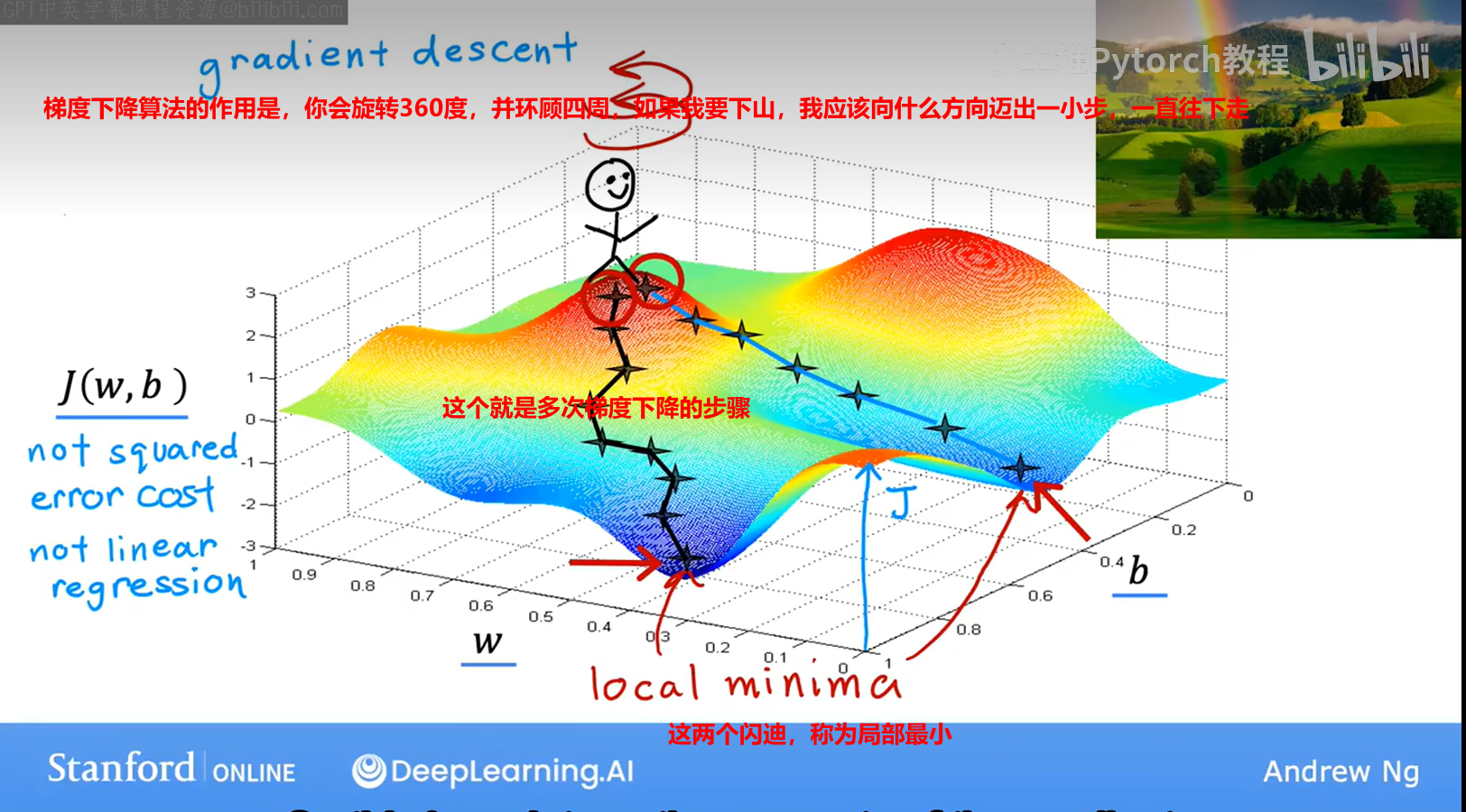
【1】梯度下降gradient descent

【2】如何实现梯度下降算法

【3】导数项的意义

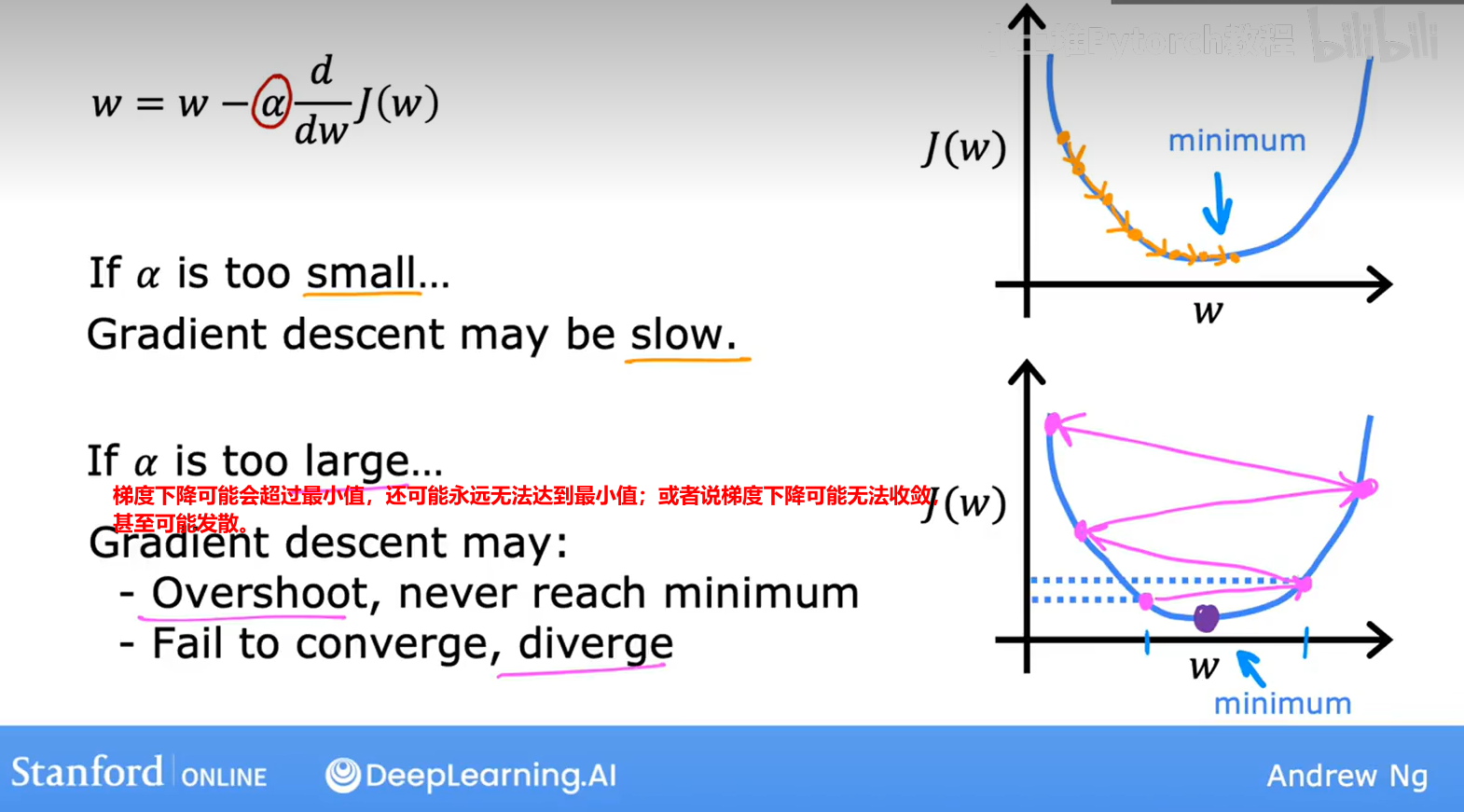
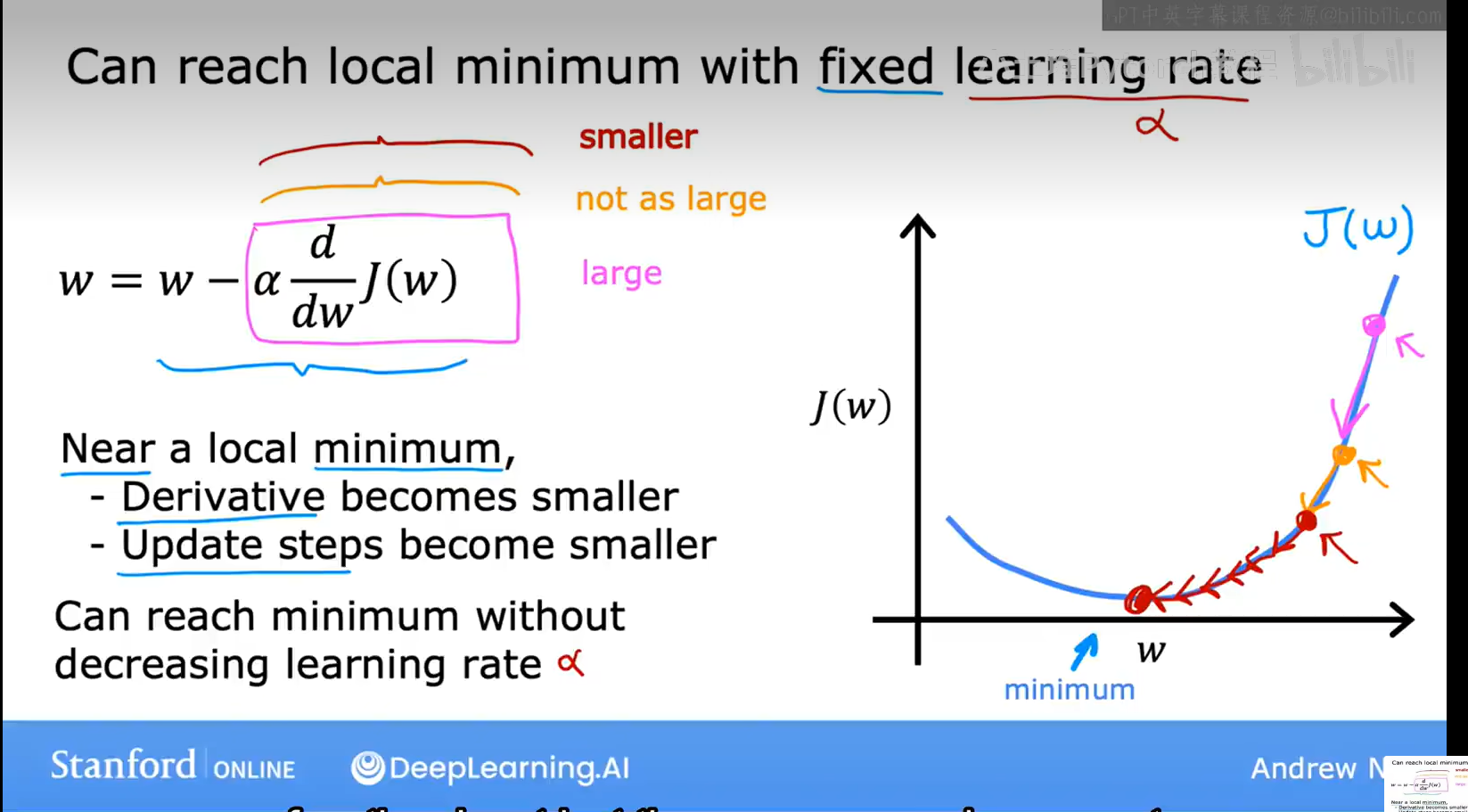
【4】学习率
学习率过大或者过小会造成什么
【5】线性回归的梯度下降

梯度算法利用微积分的推导过程


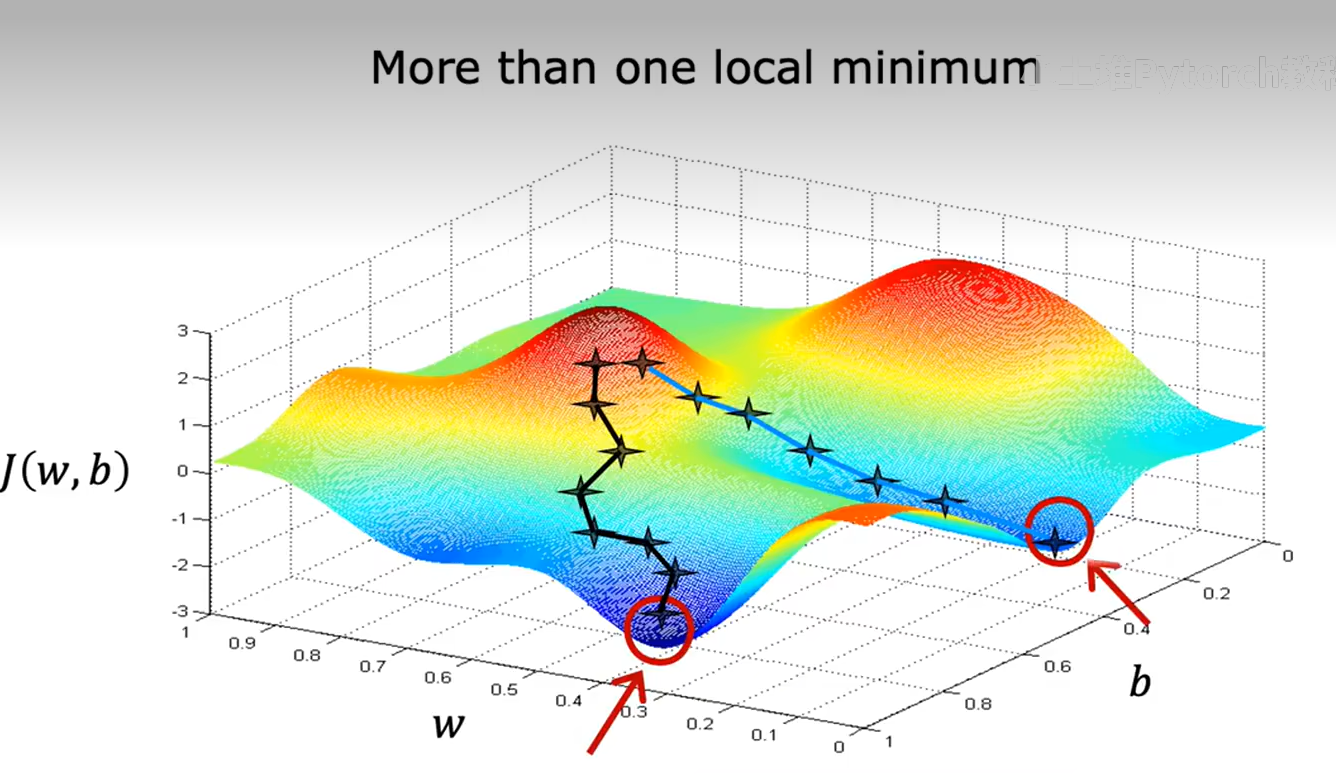
它不止有一个局部最小值
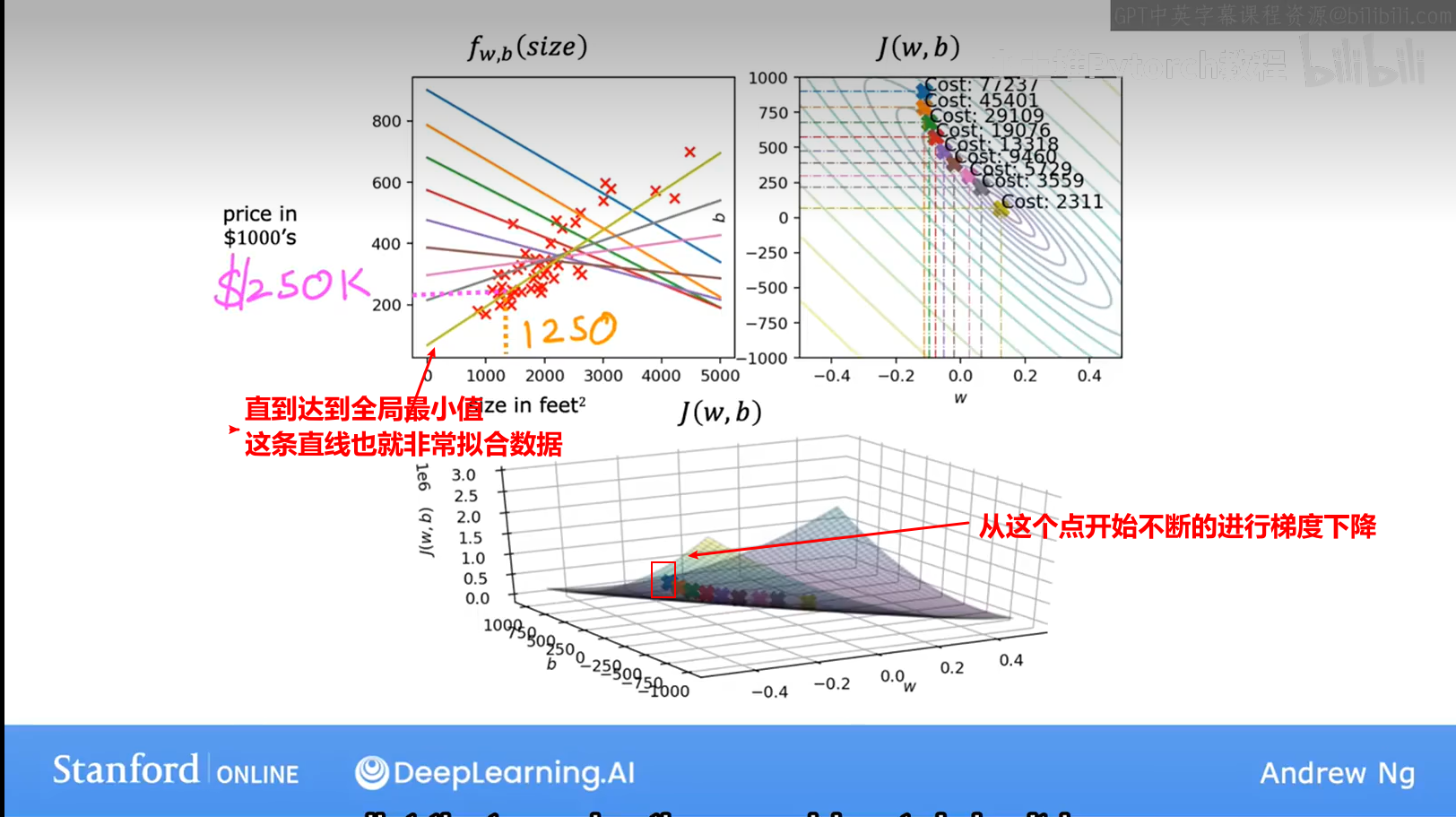
这个像碗状的图形,技术术语是这个代价函数是一个凸函数;非正式的说,凸函数是一个弓形的函数,它不能有任何局部最小值,除了单一的全局最小值。因此当你在凸函数上实现梯度下降时,一个很好的特性是,只要你选择适当的学习率,它总是会收敛到全局最小值。

【6】运行梯度下降

6.多特征
6.1多特征的过程

因此得出了多特征的模型
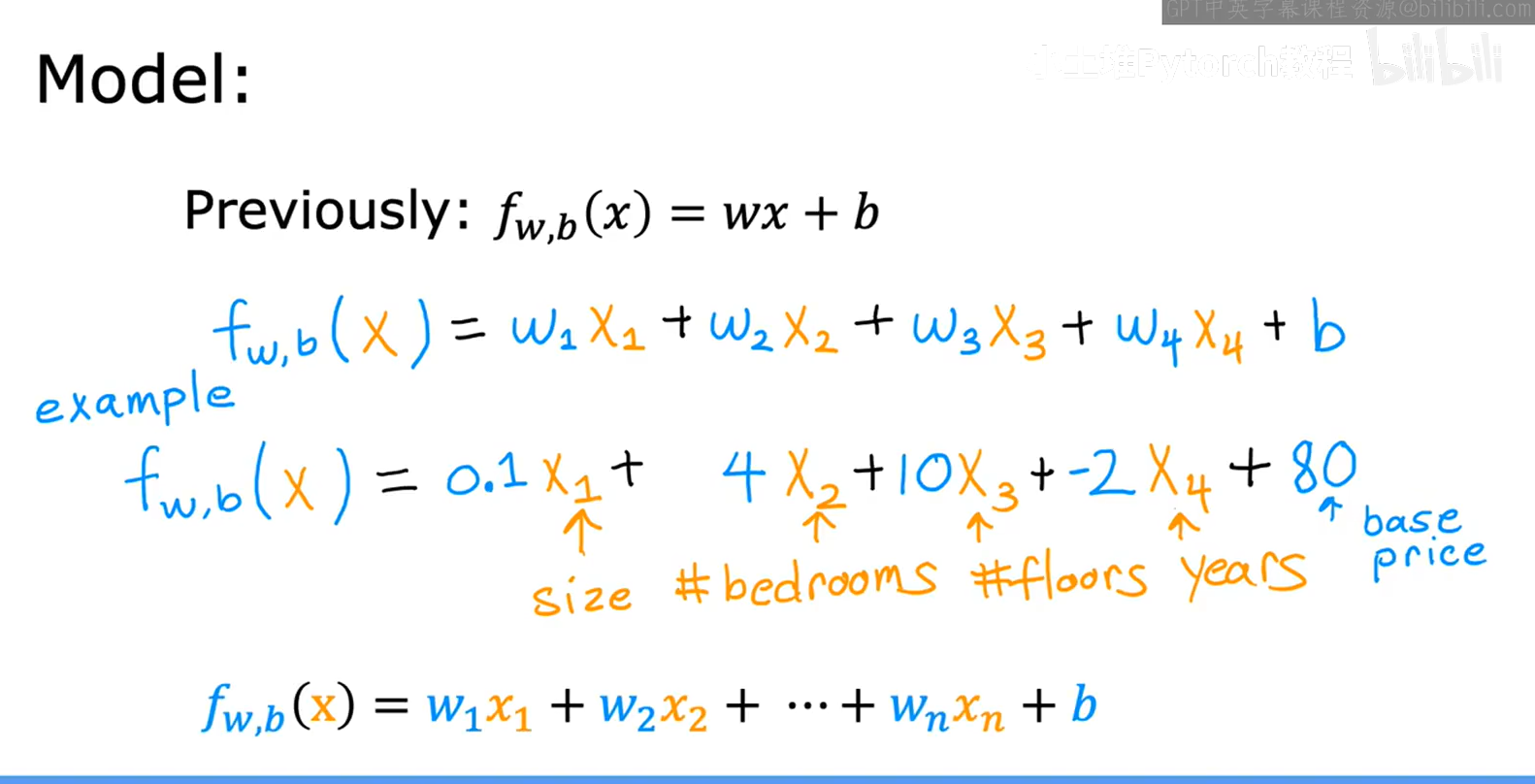

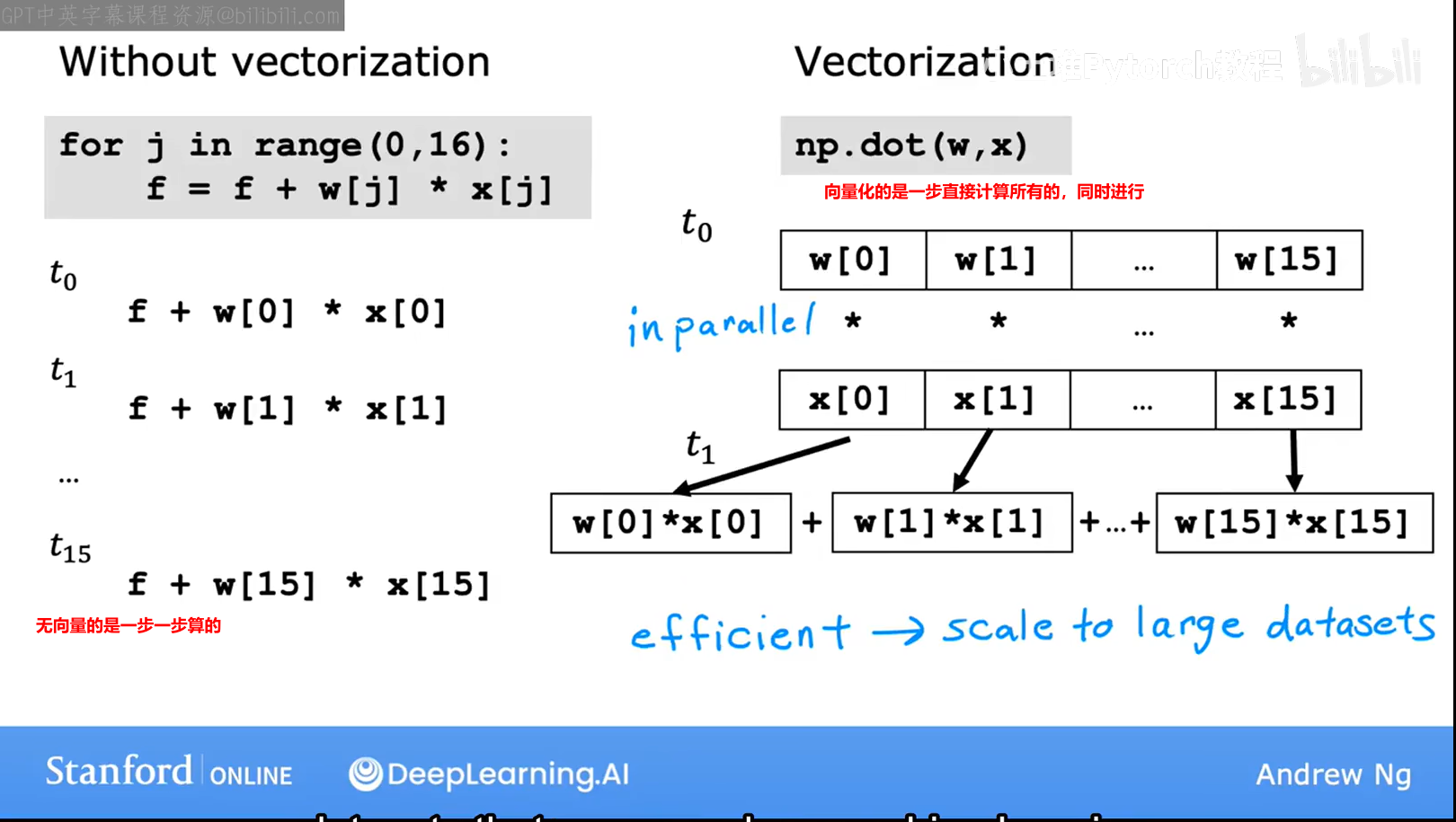
6.2 用到的向量化
使用向量化的好处:
1.代码更简洁,2.它还使得代码比未使用向量化的前两个实现运行的快;这是了因为numpy点函数利用并行硬件的能力使其比我们之前看到的循环或顺序计算更高效。

向量化的过程

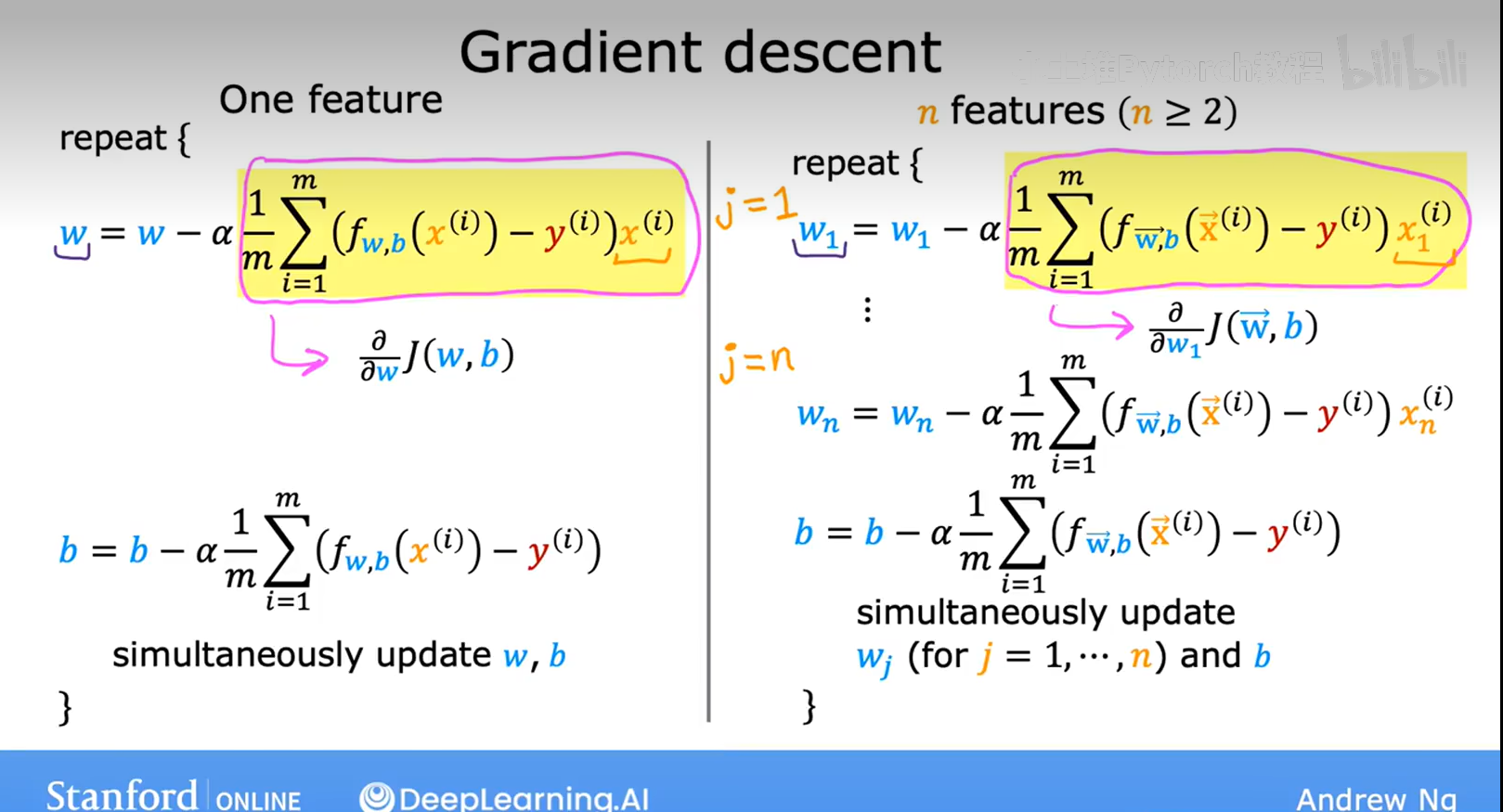
6.3 多重线性回归的梯度下降


6.4特征缩放(使梯度下降运行的更快)


因此,当你有不同的特征取值范围差异很大时,可能会导致梯度下降运行缓慢,但是通过重新缩放不同的特征值,使他们都取值在可比范围内,可以显著加快梯度下降的速度
