
Agent配置最佳实践:Prompt工程与参数调优
🌟Hello,我是摘星!
🌈 在彩虹般绚烂的技术栈中,我是那个永不停歇的色彩收集者。
🦋 每一个优化都是我培育的花朵,每一个特性都是我放飞的蝴蝶。
🔬 每一次代码审查都是我的显微镜观察,每一次重构都是我的化学实验。
🎵 在编程的交响乐中,我既是指挥家也是演奏者。让我们一起,在技术的音乐厅里,奏响属于程序员的华美乐章。
目录
[1. Prompt工程基础理论](#1. Prompt工程基础理论)
[1.1 Prompt工程核心概念](#1.1 Prompt工程核心概念)
[1.2 Prompt设计模式](#1.2 Prompt设计模式)
[1.3 高质量Prompt特征](#1.3 高质量Prompt特征)
[2. 系统级Prompt设计](#2. 系统级Prompt设计)
[2.1 角色定义与人格塑造](#2.1 角色定义与人格塑造)
[2.2 上下文管理策略](#2.2 上下文管理策略)
[2.3 动态Prompt生成](#2.3 动态Prompt生成)
[3. 参数调优策略](#3. 参数调优策略)
[3.1 核心参数详解](#3.1 核心参数详解)
[3.2 A/B测试与参数优化](#3.2 A/B测试与参数优化)
[4. 性能监控与评估](#4. 性能监控与评估)
[4.1 质量评估指标](#4.1 质量评估指标)
[5. 实战案例分析](#5. 实战案例分析)
[5.1 客服Agent优化案例](#5.1 客服Agent优化案例)
[6. 高级优化技巧](#6. 高级优化技巧)
[6.1 动态参数调整](#6.1 动态参数调整)
[6.2 多模型集成策略](#6.2 多模型集成策略)
[7. 总结与最佳实践建议](#7. 总结与最佳实践建议)
[7.1 配置优化检查清单](#7.1 配置优化检查清单)
[7.2 配置优化流程](#7.2 配置优化流程)
[7.3 实践建议总结](#7.3 实践建议总结)
作为一名在AI应用开发领域深耕多年的技术专家,我深刻认识到Agent配置优化在整个智能体系统中的关键作用。在过去的实践中,我发现许多开发者虽然能够快速搭建Agent应用,但往往在配置优化环节遇到瓶颈,导致系统性能不佳、响应质量不稳定、成本控制困难等问题。经过大量的实验和实践,我逐渐总结出一套系统性的Agent配置优化方法论,涵盖Prompt工程、参数调优、性能监控等多个维度。无论是金融领域的风险评估Agent,还是教育平台的智能辅导系统,亦或是电商场景的个性化推荐引擎,每一个成功案例的背后都离不开精心的配置优化工作。Prompt工程作为Agent配置的核心,不仅决定了模型的理解能力和输出质量,更直接影响着用户体验和业务效果。而参数调优则是在Prompt基础上的精细化控制,通过合理设置温度、最大令牌数、频率惩罚等参数,可以显著提升Agent的表现稳定性和响应准确性。本文将从理论基础到实践应用,从基础配置到高级优化,全面介绍Agent配置的最佳实践,帮助开发者构建高性能、高质量的智能体应用,真正发挥AI技术的最大价值。
1. Prompt工程基础理论
1.1 Prompt工程核心概念
Prompt工程是通过精心设计输入提示来引导大语言模型产生期望输出的技术和艺术。
python
# Prompt工程核心组件
from typing import Dict, List, Any, Optional
from dataclasses import dataclass
from enum import Enum
class PromptType(Enum):
"""Prompt类型枚举"""
SYSTEM = "system" # 系统提示
USER = "user" # 用户输入
ASSISTANT = "assistant" # 助手回复
FUNCTION = "function" # 函数调用
@dataclass
class PromptComponent:
"""Prompt组件"""
role: PromptType
content: str
metadata: Dict[str, Any] = None
def __post_init__(self):
if self.metadata is None:
self.metadata = {}
class PromptTemplate:
"""Prompt模板类"""
def __init__(self, template: str, variables: List[str] = None):
self.template = template
self.variables = variables or []
self.components = []
def add_component(self, component: PromptComponent):
"""添加Prompt组件"""
self.components.append(component)
def render(self, **kwargs) -> str:
"""渲染Prompt模板"""
rendered_template = self.template
# 替换变量
for var in self.variables:
if var in kwargs:
placeholder = f"{{{var}}}"
rendered_template = rendered_template.replace(placeholder, str(kwargs[var]))
return rendered_template
def validate(self, **kwargs) -> bool:
"""验证必需变量"""
missing_vars = [var for var in self.variables if var not in kwargs]
if missing_vars:
raise ValueError(f"缺少必需变量: {missing_vars}")
return True
# Prompt工程最佳实践示例
class PromptEngineer:
"""Prompt工程师"""
def __init__(self):
self.templates = {}
self.best_practices = {
"clarity": "使用清晰、具体的指令",
"context": "提供充分的上下文信息",
"examples": "包含相关的示例",
"constraints": "明确输出格式和约束",
"role_definition": "清晰定义AI的角色"
}
def create_system_prompt(self, role: str, capabilities: List[str],
constraints: List[str], examples: List[Dict] = None) -> str:
"""创建系统提示"""
prompt_parts = [
f"你是一个{role}。",
"",
"你的能力包括:",
]
# 添加能力描述
for i, capability in enumerate(capabilities, 1):
prompt_parts.append(f"{i}. {capability}")
prompt_parts.append("")
prompt_parts.append("请遵循以下约束:")
# 添加约束条件
for i, constraint in enumerate(constraints, 1):
prompt_parts.append(f"{i}. {constraint}")
# 添加示例
if examples:
prompt_parts.append("")
prompt_parts.append("示例:")
for example in examples:
prompt_parts.append(f"输入:{example.get('input', '')}")
prompt_parts.append(f"输出:{example.get('output', '')}")
prompt_parts.append("")
return "\n".join(prompt_parts)1.2 Prompt设计模式
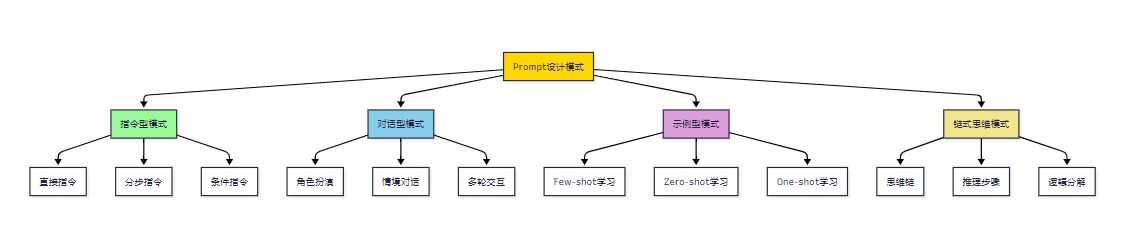
图1:Prompt设计模式分类图
1.3 高质量Prompt特征
|------|------------|------------------------|------|
| 特征维度 | 描述 | 示例 | 评分标准 |
| 清晰性 | 指令明确,无歧义 | "请总结以下文章的主要观点" | 1-5分 |
| 具体性 | 提供具体的要求和约束 | "用3-5个要点总结,每个要点不超过50字" | 1-5分 |
| 完整性 | 包含所有必要信息 | 提供背景、任务、格式要求 | 1-5分 |
| 一致性 | 风格和语调保持一致 | 统一使用正式或非正式语调 | 1-5分 |
| 可测试性 | 输出结果可以验证 | 明确的成功标准 | 1-5分 |
2. 系统级Prompt设计
2.1 角色定义与人格塑造
python
# 角色定义框架
class AgentPersonality:
"""Agent人格定义"""
def __init__(self):
self.role_templates = {
"professional_consultant": {
"base_role": "专业顾问",
"personality_traits": [
"专业严谨", "逻辑清晰", "善于分析", "注重细节"
],
"communication_style": "正式、专业、条理清晰",
"knowledge_areas": [],
"response_patterns": {
"greeting": "您好,我是您的专业顾问,很高兴为您服务。",
"analysis": "基于我的专业分析,我认为...",
"recommendation": "我建议您考虑以下几个方面:",
"clarification": "为了给您更准确的建议,我需要了解..."
}
},
"friendly_assistant": {
"base_role": "友好助手",
"personality_traits": [
"热情友好", "耐心细致", "乐于助人", "积极正面"
],
"communication_style": "亲切、温暖、易懂",
"knowledge_areas": [],
"response_patterns": {
"greeting": "你好!我是你的小助手,有什么可以帮助你的吗?😊",
"encouragement": "你做得很棒!让我们继续努力吧!",
"help_offer": "别担心,我来帮你解决这个问题!",
"farewell": "希望我的帮助对你有用,祝你一切顺利!"
}
}
}
def generate_personality_prompt(self, role_type: str,
custom_traits: List[str] = None,
domain_knowledge: List[str] = None) -> str:
"""生成人格化提示"""
if role_type not in self.role_templates:
raise ValueError(f"不支持的角色类型: {role_type}")
template = self.role_templates[role_type]
# 合并自定义特征
traits = template["personality_traits"].copy()
if custom_traits:
traits.extend(custom_traits)
# 合并领域知识
knowledge = template["knowledge_areas"].copy()
if domain_knowledge:
knowledge.extend(domain_knowledge)
prompt = f"""
你是一个{template['base_role']},具有以下人格特征:
{', '.join(traits)}
你的沟通风格是:{template['communication_style']}
你在以下领域具有专业知识:
{chr(10).join(f"- {area}" for area in knowledge)}
在对话中,请遵循以下模式:
"""
for pattern_name, pattern_text in template["response_patterns"].items():
prompt += f"\n{pattern_name.replace('_', ' ').title()}: {pattern_text}"
return prompt
# 使用示例
personality_manager = AgentPersonality()
# 创建专业的金融顾问
financial_advisor_prompt = personality_manager.generate_personality_prompt(
role_type="professional_consultant",
custom_traits=["风险意识强", "数据驱动"],
domain_knowledge=["投资理财", "风险管理", "市场分析", "金融产品"]
)2.2 上下文管理策略
# 上下文管理系统
from collections import deque
from datetime import datetime, timedelta
import json
class ContextManager:
"""上下文管理器"""
def __init__(self, max_context_length: int = 4000,
max_history_turns: int = 10):
self.max_context_length = max_context_length
self.max_history_turns = max_history_turns
self.conversation_history = deque(maxlen=max_history_turns)
self.persistent_context = {}
self.session_context = {}
self.context_priorities = {
"system": 10, # 系统提示优先级最高
"persistent": 8, # 持久化上下文
"recent": 6, # 最近对话
"session": 4, # 会话上下文
"background": 2 # 背景信息
}
def add_message(self, role: str, content: str, metadata: Dict = None):
"""添加消息到历史记录"""
message = {
"role": role,
"content": content,
"timestamp": datetime.now().isoformat(),
"metadata": metadata or {}
}
self.conversation_history.append(message)
def set_persistent_context(self, key: str, value: Any):
"""设置持久化上下文"""
self.persistent_context[key] = {
"value": value,
"timestamp": datetime.now().isoformat()
}
def set_session_context(self, key: str, value: Any, ttl_minutes: int = 60):
"""设置会话上下文"""
expiry_time = datetime.now() + timedelta(minutes=ttl_minutes)
self.session_context[key] = {
"value": value,
"expires_at": expiry_time.isoformat()
}
def get_context_summary(self) -> str:
"""获取上下文摘要"""
summary_parts = []
# 添加持久化上下文
if self.persistent_context:
summary_parts.append("持久化信息:")
for key, data in self.persistent_context.items():
summary_parts.append(f"- {key}: {data['value']}")
# 添加有效的会话上下文
valid_session_context = self._get_valid_session_context()
if valid_session_context:
summary_parts.append("\n当前会话信息:")
for key, data in valid_session_context.items():
summary_parts.append(f"- {key}: {data['value']}")
# 添加最近对话摘要
if self.conversation_history:
summary_parts.append("\n最近对话:")
for msg in list(self.conversation_history)[-3:]: # 最近3轮对话
role = msg["role"]
content = msg["content"][:100] + "..." if len(msg["content"]) > 100 else msg["content"]
summary_parts.append(f"- {role}: {content}")
return "\n".join(summary_parts)
def _get_valid_session_context(self) -> Dict[str, Any]:
"""获取有效的会话上下文"""
valid_context = {}
current_time = datetime.now()
for key, data in self.session_context.items():
expires_at = datetime.fromisoformat(data["expires_at"])
if current_time < expires_at:
valid_context[key] = data
return valid_context
def build_context_prompt(self, system_prompt: str,
current_input: str) -> List[Dict[str, str]]:
"""构建完整的上下文提示"""
messages = []
# 系统提示
enhanced_system_prompt = system_prompt
# 添加上下文摘要
context_summary = self.get_context_summary()
if context_summary:
enhanced_system_prompt += f"\n\n上下文信息:\n{context_summary}"
messages.append({
"role": "system",
"content": enhanced_system_prompt
})
# 添加历史对话(根据长度限制)
history_messages = self._select_relevant_history()
messages.extend(history_messages)
# 添加当前输入
messages.append({
"role": "user",
"content": current_input
})
return messages
def _select_relevant_history(self) -> List[Dict[str, str]]:
"""选择相关的历史对话"""
selected_messages = []
total_length = 0
# 从最新的消息开始选择
for message in reversed(list(self.conversation_history)):
message_length = len(message["content"])
if total_length + message_length > self.max_context_length:
break
selected_messages.insert(0, {
"role": message["role"],
"content": message["content"]
})
total_length += message_length
return selected_messages2.3 动态Prompt生成
python
# 动态Prompt生成系统
class DynamicPromptGenerator:
"""动态Prompt生成器"""
def __init__(self):
self.prompt_templates = {}
self.context_analyzers = {}
self.adaptation_rules = {}
def register_template(self, template_name: str, template: PromptTemplate):
"""注册Prompt模板"""
self.prompt_templates[template_name] = template
def register_context_analyzer(self, analyzer_name: str, analyzer_func: callable):
"""注册上下文分析器"""
self.context_analyzers[analyzer_name] = analyzer_func
def generate_adaptive_prompt(self, base_template: str,
context: Dict[str, Any],
user_profile: Dict[str, Any] = None) -> str:
"""生成自适应Prompt"""
# 分析上下文
context_analysis = self._analyze_context(context)
# 分析用户画像
user_analysis = self._analyze_user_profile(user_profile or {})
# 选择最适合的模板变体
template_variant = self._select_template_variant(
base_template, context_analysis, user_analysis
)
# 动态调整Prompt内容
adapted_prompt = self._adapt_prompt_content(
template_variant, context_analysis, user_analysis
)
return adapted_prompt
def _analyze_context(self, context: Dict[str, Any]) -> Dict[str, Any]:
"""分析上下文"""
analysis = {
"complexity": self._assess_complexity(context),
"domain": self._identify_domain(context),
"urgency": self._assess_urgency(context),
"formality": self._assess_formality(context)
}
# 运行注册的分析器
for analyzer_name, analyzer_func in self.context_analyzers.items():
try:
analysis[analyzer_name] = analyzer_func(context)
except Exception as e:
print(f"上下文分析器 {analyzer_name} 执行失败: {e}")
return analysis
def _analyze_user_profile(self, user_profile: Dict[str, Any]) -> Dict[str, Any]:
"""分析用户画像"""
return {
"expertise_level": user_profile.get("expertise_level", "intermediate"),
"preferred_style": user_profile.get("communication_style", "balanced"),
"language_preference": user_profile.get("language", "zh-CN"),
"interaction_history": user_profile.get("interaction_count", 0)
}
def _select_template_variant(self, base_template: str,
context_analysis: Dict[str, Any],
user_analysis: Dict[str, Any]) -> str:
"""选择模板变体"""
# 根据复杂度调整
if context_analysis["complexity"] == "high":
template_variant = self._add_detailed_instructions(base_template)
elif context_analysis["complexity"] == "low":
template_variant = self._simplify_instructions(base_template)
else:
template_variant = base_template
# 根据用户专业水平调整
if user_analysis["expertise_level"] == "beginner":
template_variant = self._add_explanatory_content(template_variant)
elif user_analysis["expertise_level"] == "expert":
template_variant = self._add_advanced_options(template_variant)
return template_variant
def _adapt_prompt_content(self, template: str,
context_analysis: Dict[str, Any],
user_analysis: Dict[str, Any]) -> str:
"""适配Prompt内容"""
adapted_prompt = template
# 根据正式程度调整语调
if context_analysis["formality"] == "formal":
adapted_prompt = self._formalize_language(adapted_prompt)
elif context_analysis["formality"] == "casual":
adapted_prompt = self._casualize_language(adapted_prompt)
# 根据紧急程度调整
if context_analysis["urgency"] == "high":
adapted_prompt = self._add_urgency_indicators(adapted_prompt)
# 根据领域添加专业术语
domain = context_analysis["domain"]
if domain:
adapted_prompt = self._add_domain_context(adapted_prompt, domain)
return adapted_prompt
def _assess_complexity(self, context: Dict[str, Any]) -> str:
"""评估复杂度"""
# 简化的复杂度评估逻辑
text_length = len(str(context))
if text_length > 1000:
return "high"
elif text_length < 200:
return "low"
else:
return "medium"
def _identify_domain(self, context: Dict[str, Any]) -> str:
"""识别领域"""
# 简化的领域识别逻辑
text = str(context).lower()
domain_keywords = {
"finance": ["投资", "理财", "股票", "基金", "风险"],
"technology": ["编程", "代码", "算法", "系统", "开发"],
"education": ["学习", "教育", "课程", "知识", "培训"],
"healthcare": ["健康", "医疗", "疾病", "治疗", "药物"]
}
for domain, keywords in domain_keywords.items():
if any(keyword in text for keyword in keywords):
return domain
return "general"
def _assess_urgency(self, context: Dict[str, Any]) -> str:
"""评估紧急程度"""
text = str(context).lower()
urgent_keywords = ["紧急", "急需", "立即", "马上", "尽快"]
if any(keyword in text for keyword in urgent_keywords):
return "high"
else:
return "normal"
def _assess_formality(self, context: Dict[str, Any]) -> str:
"""评估正式程度"""
text = str(context)
# 简单的正式程度判断
formal_indicators = ["您", "请问", "敬请", "恳请"]
casual_indicators = ["你", "咋样", "怎么样", "啥"]
formal_count = sum(1 for indicator in formal_indicators if indicator in text)
casual_count = sum(1 for indicator in casual_indicators if indicator in text)
if formal_count > casual_count:
return "formal"
elif casual_count > formal_count:
return "casual"
else:
return "neutral"3. 参数调优策略
3.1 核心参数详解
python
# 参数配置管理系统
from dataclasses import dataclass
from typing import Union, Optional
import json
@dataclass
class ModelParameters:
"""模型参数配置"""
temperature: float = 0.7 # 创造性控制 (0.0-2.0)
max_tokens: int = 1000 # 最大输出长度
top_p: float = 1.0 # 核采样参数 (0.0-1.0)
frequency_penalty: float = 0.0 # 频率惩罚 (-2.0-2.0)
presence_penalty: float = 0.0 # 存在惩罚 (-2.0-2.0)
stop: Optional[List[str]] = None # 停止序列
def __post_init__(self):
"""参数验证"""
self._validate_parameters()
def _validate_parameters(self):
"""验证参数范围"""
if not 0.0 <= self.temperature <= 2.0:
raise ValueError("temperature必须在0.0-2.0范围内")
if not 1 <= self.max_tokens <= 4096:
raise ValueError("max_tokens必须在1-4096范围内")
if not 0.0 <= self.top_p <= 1.0:
raise ValueError("top_p必须在0.0-1.0范围内")
if not -2.0 <= self.frequency_penalty <= 2.0:
raise ValueError("frequency_penalty必须在-2.0-2.0范围内")
if not -2.0 <= self.presence_penalty <= 2.0:
raise ValueError("presence_penalty必须在-2.0-2.0范围内")
class ParameterOptimizer:
"""参数优化器"""
def __init__(self):
self.optimization_history = []
self.best_parameters = {}
self.parameter_effects = {
"temperature": {
"low": "输出更确定、一致,适合事实性任务",
"high": "输出更创造性、多样,适合创意性任务"
},
"top_p": {
"low": "只考虑最可能的词汇,输出更聚焦",
"high": "考虑更多词汇选择,输出更多样"
},
"frequency_penalty": {
"positive": "减少重复词汇,增加词汇多样性",
"negative": "允许更多重复,保持一致性"
},
"presence_penalty": {
"positive": "鼓励引入新话题和概念",
"negative": "保持当前话题的连贯性"
}
}
def suggest_parameters(self, task_type: str,
quality_requirements: Dict[str, str]) -> ModelParameters:
"""根据任务类型建议参数"""
parameter_presets = {
"creative_writing": ModelParameters(
temperature=0.9,
max_tokens=2000,
top_p=0.9,
frequency_penalty=0.3,
presence_penalty=0.3
),
"factual_qa": ModelParameters(
temperature=0.2,
max_tokens=500,
top_p=0.8,
frequency_penalty=0.0,
presence_penalty=0.0
),
"code_generation": ModelParameters(
temperature=0.1,
max_tokens=1500,
top_p=0.95,
frequency_penalty=0.0,
presence_penalty=0.0
),
"conversation": ModelParameters(
temperature=0.7,
max_tokens=800,
top_p=0.9,
frequency_penalty=0.2,
presence_penalty=0.1
),
"analysis": ModelParameters(
temperature=0.3,
max_tokens=1200,
top_p=0.85,
frequency_penalty=0.1,
presence_penalty=0.0
)
}
base_params = parameter_presets.get(task_type, ModelParameters())
# 根据质量要求调整
adjusted_params = self._adjust_for_quality_requirements(
base_params, quality_requirements
)
return adjusted_params
def _adjust_for_quality_requirements(self, base_params: ModelParameters,
requirements: Dict[str, str]) -> ModelParameters:
"""根据质量要求调整参数"""
adjusted = ModelParameters(
temperature=base_params.temperature,
max_tokens=base_params.max_tokens,
top_p=base_params.top_p,
frequency_penalty=base_params.frequency_penalty,
presence_penalty=base_params.presence_penalty,
stop=base_params.stop
)
# 创造性要求
creativity = requirements.get("creativity", "medium")
if creativity == "high":
adjusted.temperature = min(adjusted.temperature + 0.2, 1.0)
adjusted.top_p = min(adjusted.top_p + 0.1, 1.0)
elif creativity == "low":
adjusted.temperature = max(adjusted.temperature - 0.2, 0.1)
adjusted.top_p = max(adjusted.top_p - 0.1, 0.5)
# 一致性要求
consistency = requirements.get("consistency", "medium")
if consistency == "high":
adjusted.temperature = max(adjusted.temperature - 0.1, 0.1)
adjusted.frequency_penalty = max(adjusted.frequency_penalty - 0.1, -0.5)
elif consistency == "low":
adjusted.frequency_penalty = min(adjusted.frequency_penalty + 0.2, 1.0)
adjusted.presence_penalty = min(adjusted.presence_penalty + 0.1, 0.5)
# 长度要求
length = requirements.get("length", "medium")
if length == "short":
adjusted.max_tokens = min(adjusted.max_tokens, 300)
elif length == "long":
adjusted.max_tokens = max(adjusted.max_tokens, 1500)
return adjusted3.2 A/B测试与参数优化
# A/B测试框架
import random
import statistics
from typing import List, Dict, Any, Tuple
from datetime import datetime
import uuid
class ABTestManager:
"""A/B测试管理器"""
def __init__(self):
self.experiments = {}
self.results = {}
self.traffic_split = {}
def create_experiment(self, experiment_name: str,
variant_a: ModelParameters,
variant_b: ModelParameters,
traffic_split: float = 0.5,
success_metrics: List[str] = None) -> str:
"""创建A/B测试实验"""
experiment_id = str(uuid.uuid4())[:8]
self.experiments[experiment_id] = {
"name": experiment_name,
"variant_a": variant_a,
"variant_b": variant_b,
"traffic_split": traffic_split,
"success_metrics": success_metrics or ["response_quality", "user_satisfaction"],
"created_at": datetime.now().isoformat(),
"status": "active"
}
self.results[experiment_id] = {
"variant_a": {"samples": [], "metrics": {}},
"variant_b": {"samples": [], "metrics": {}}
}
return experiment_id
def get_variant(self, experiment_id: str, user_id: str = None) -> Tuple[str, ModelParameters]:
"""获取实验变体"""
if experiment_id not in self.experiments:
raise ValueError(f"实验不存在: {experiment_id}")
experiment = self.experiments[experiment_id]
# 确定性分配(基于用户ID)或随机分配
if user_id:
hash_value = hash(user_id) % 100
use_variant_a = hash_value < (experiment["traffic_split"] * 100)
else:
use_variant_a = random.random() < experiment["traffic_split"]
if use_variant_a:
return "variant_a", experiment["variant_a"]
else:
return "variant_b", experiment["variant_b"]
def record_result(self, experiment_id: str, variant: str,
metrics: Dict[str, float], metadata: Dict[str, Any] = None):
"""记录实验结果"""
if experiment_id not in self.results:
return
result_entry = {
"timestamp": datetime.now().isoformat(),
"metrics": metrics,
"metadata": metadata or {}
}
self.results[experiment_id][variant]["samples"].append(result_entry)
def analyze_experiment(self, experiment_id: str) -> Dict[str, Any]:
"""分析实验结果"""
if experiment_id not in self.results:
return {}
experiment = self.experiments[experiment_id]
results = self.results[experiment_id]
analysis = {
"experiment_name": experiment["name"],
"sample_sizes": {
"variant_a": len(results["variant_a"]["samples"]),
"variant_b": len(results["variant_b"]["samples"])
},
"metrics_comparison": {},
"statistical_significance": {},
"recommendation": ""
}
# 分析每个指标
for metric in experiment["success_metrics"]:
a_values = [s["metrics"].get(metric, 0) for s in results["variant_a"]["samples"]]
b_values = [s["metrics"].get(metric, 0) for s in results["variant_b"]["samples"]]
if a_values and b_values:
analysis["metrics_comparison"][metric] = {
"variant_a": {
"mean": statistics.mean(a_values),
"std": statistics.stdev(a_values) if len(a_values) > 1 else 0,
"samples": len(a_values)
},
"variant_b": {
"mean": statistics.mean(b_values),
"std": statistics.stdev(b_values) if len(b_values) > 1 else 0,
"samples": len(b_values)
}
}
# 简单的统计显著性检验
significance = self._calculate_significance(a_values, b_values)
analysis["statistical_significance"][metric] = significance
# 生成建议
analysis["recommendation"] = self._generate_recommendation(analysis)
return analysis
def _calculate_significance(self, a_values: List[float], b_values: List[float]) -> Dict[str, Any]:
"""计算统计显著性"""
if len(a_values) < 10 or len(b_values) < 10:
return {"significant": False, "reason": "样本量不足"}
mean_a = statistics.mean(a_values)
mean_b = statistics.mean(b_values)
# 简化的显著性检验
improvement = (mean_b - mean_a) / mean_a * 100 if mean_a != 0 else 0
return {
"significant": abs(improvement) > 5, # 简化标准:改进超过5%
"improvement_percent": improvement,
"better_variant": "variant_b" if improvement > 0 else "variant_a"
}
def _generate_recommendation(self, analysis: Dict[str, Any]) -> str:
"""生成优化建议"""
recommendations = []
for metric, significance in analysis["statistical_significance"].items():
if significance.get("significant", False):
better_variant = significance["better_variant"]
improvement = significance["improvement_percent"]
recommendations.append(
f"{metric}: {better_variant} 表现更好,改进 {improvement:.1f}%"
)
if not recommendations:
return "当前测试结果无显著差异,建议继续收集数据或尝试更大的参数差异"
return "; ".join(recommendations)
# 参数优化实例
class ParameterTuner:
"""参数调优器"""
def __init__(self):
self.optimization_history = []
self.best_score = 0
self.best_parameters = None
def grid_search(self, parameter_ranges: Dict[str, List],
evaluation_func: callable,
test_cases: List[Dict]) -> ModelParameters:
"""网格搜索优化"""
best_score = float('-inf')
best_params = None
# 生成参数组合
param_combinations = self._generate_combinations(parameter_ranges)
for params in param_combinations:
# 创建参数对象
model_params = ModelParameters(**params)
# 评估参数组合
scores = []
for test_case in test_cases:
try:
score = evaluation_func(model_params, test_case)
scores.append(score)
except Exception as e:
print(f"评估失败: {e}")
scores.append(0)
avg_score = statistics.mean(scores) if scores else 0
# 记录结果
self.optimization_history.append({
"parameters": params,
"score": avg_score,
"timestamp": datetime.now().isoformat()
})
# 更新最佳参数
if avg_score > best_score:
best_score = avg_score
best_params = model_params
self.best_score = best_score
self.best_parameters = best_params
return best_params
def _generate_combinations(self, parameter_ranges: Dict[str, List]) -> List[Dict]:
"""生成参数组合"""
import itertools
keys = list(parameter_ranges.keys())
values = list(parameter_ranges.values())
combinations = []
for combination in itertools.product(*values):
param_dict = dict(zip(keys, combination))
combinations.append(param_dict)
return combinations
# 使用示例
def evaluate_parameters(params: ModelParameters, test_case: Dict) -> float:
"""参数评估函数示例"""
# 这里应该是实际的模型调用和评估逻辑
# 返回0-1之间的分数
# 模拟评估逻辑
base_score = 0.7
# 根据参数调整分数
if test_case.get("task_type") == "creative":
if params.temperature > 0.7:
base_score += 0.1
if params.frequency_penalty > 0.2:
base_score += 0.05
elif test_case.get("task_type") == "factual":
if params.temperature < 0.3:
base_score += 0.1
if params.top_p < 0.9:
base_score += 0.05
return min(base_score, 1.0)
# 参数优化示例
tuner = ParameterTuner()
parameter_ranges = {
"temperature": [0.1, 0.3, 0.5, 0.7, 0.9],
"top_p": [0.8, 0.85, 0.9, 0.95, 1.0],
"frequency_penalty": [0.0, 0.1, 0.2, 0.3],
"presence_penalty": [0.0, 0.1, 0.2]
}
test_cases = [
{"task_type": "creative", "content": "创意写作任务"},
{"task_type": "factual", "content": "事实问答任务"},
{"task_type": "analysis", "content": "分析任务"}
]
# 执行优化
# best_params = tuner.grid_search(parameter_ranges, evaluate_parameters, test_cases)4. 性能监控与评估
4.1 质量评估指标
python
# 质量评估系统
from typing import List, Dict, Any
import re
import nltk
from textstat import flesch_reading_ease, flesch_kincaid_grade
class QualityEvaluator:
"""质量评估器"""
def __init__(self):
self.evaluation_metrics = {
"relevance": self._evaluate_relevance,
"coherence": self._evaluate_coherence,
"completeness": self._evaluate_completeness,
"accuracy": self._evaluate_accuracy,
"readability": self._evaluate_readability,
"creativity": self._evaluate_creativity
}
def evaluate_response(self, prompt: str, response: str,
expected_output: str = None,
evaluation_criteria: List[str] = None) -> Dict[str, float]:
"""评估响应质量"""
criteria = evaluation_criteria or list(self.evaluation_metrics.keys())
results = {}
for criterion in criteria:
if criterion in self.evaluation_metrics:
try:
score = self.evaluation_metrics[criterion](prompt, response, expected_output)
results[criterion] = score
except Exception as e:
print(f"评估 {criterion} 时出错: {e}")
results[criterion] = 0.0
# 计算综合分数
results["overall_score"] = sum(results.values()) / len(results)
return results
def _evaluate_relevance(self, prompt: str, response: str, expected: str = None) -> float:
"""评估相关性"""
# 简化的相关性评估:关键词重叠度
prompt_words = set(re.findall(r'\w+', prompt.lower()))
response_words = set(re.findall(r'\w+', response.lower()))
if not prompt_words:
return 0.0
overlap = len(prompt_words.intersection(response_words))
relevance_score = overlap / len(prompt_words)
return min(relevance_score, 1.0)
def _evaluate_coherence(self, prompt: str, response: str, expected: str = None) -> float:
"""评估连贯性"""
# 简化的连贯性评估:句子长度变化和连接词使用
sentences = re.split(r'[.!?]+', response)
sentences = [s.strip() for s in sentences if s.strip()]
if len(sentences) < 2:
return 0.8 # 单句响应默认连贯
# 计算句子长度变化
lengths = [len(s.split()) for s in sentences]
length_variance = statistics.variance(lengths) if len(lengths) > 1 else 0
# 连接词检查
connectors = ['因此', '然而', '此外', '另外', '同时', '首先', '其次', '最后']
connector_count = sum(1 for conn in connectors if conn in response)
# 综合评分
length_score = max(0, 1 - length_variance / 100) # 长度变化不宜过大
connector_score = min(connector_count / len(sentences), 0.5) # 适量连接词
return (length_score + connector_score) / 1.5
def _evaluate_completeness(self, prompt: str, response: str, expected: str = None) -> float:
"""评估完整性"""
# 检查是否回答了问题的所有部分
question_indicators = ['什么', '如何', '为什么', '哪里', '何时', '谁']
questions_in_prompt = sum(1 for indicator in question_indicators if indicator in prompt)
if questions_in_prompt == 0:
return 0.8 # 非问答类任务默认分数
# 简化评估:响应长度与问题复杂度的比例
response_length = len(response)
expected_length = questions_in_prompt * 50 # 每个问题期望50字回答
completeness_ratio = min(response_length / expected_length, 1.0)
return completeness_ratio
def _evaluate_accuracy(self, prompt: str, response: str, expected: str = None) -> float:
"""评估准确性"""
if not expected:
return 0.5 # 无参考答案时返回中性分数
# 简化的准确性评估:与期望输出的相似度
expected_words = set(re.findall(r'\w+', expected.lower()))
response_words = set(re.findall(r'\w+', response.lower()))
if not expected_words:
return 0.5
overlap = len(expected_words.intersection(response_words))
accuracy_score = overlap / len(expected_words)
return accuracy_score
def _evaluate_readability(self, prompt: str, response: str, expected: str = None) -> float:
"""评估可读性"""
try:
# 使用Flesch阅读难度评分
flesch_score = flesch_reading_ease(response)
# 转换为0-1分数(Flesch分数越高越易读)
readability_score = min(flesch_score / 100, 1.0)
return max(readability_score, 0.0)
except:
# 简化的可读性评估
sentences = re.split(r'[.!?]+', response)
avg_sentence_length = sum(len(s.split()) for s in sentences) / len(sentences) if sentences else 0
# 理想句子长度15-20词
if 15 <= avg_sentence_length <= 20:
return 1.0
elif 10 <= avg_sentence_length <= 25:
return 0.8
else:
return 0.6
def _evaluate_creativity(self, prompt: str, response: str, expected: str = None) -> float:
"""评估创造性"""
# 简化的创造性评估:词汇多样性和表达方式
words = re.findall(r'\w+', response.lower())
unique_words = set(words)
if not words:
return 0.0
# 词汇多样性
diversity_ratio = len(unique_words) / len(words)
# 创意表达检查
creative_patterns = [
r'比如说', r'换句话说', r'打个比方', r'想象一下',
r'不妨', r'或许', r'可能', r'也许'
]
creative_expressions = sum(1 for pattern in creative_patterns
if re.search(pattern, response))
creativity_score = (diversity_ratio + min(creative_expressions / 10, 0.3)) / 1.3
return min(creativity_score, 1.0)
# 性能监控系统
class PerformanceMonitor:
"""性能监控器"""
def __init__(self):
self.metrics_history = []
self.alert_thresholds = {
"response_time": 5.0, # 5秒
"quality_score": 0.7, # 70%
"error_rate": 0.05, # 5%
"token_usage": 1000 # 1000 tokens
}
self.quality_evaluator = QualityEvaluator()
def record_interaction(self, interaction_data: Dict[str, Any]):
"""记录交互数据"""
timestamp = datetime.now().isoformat()
# 计算质量分数
quality_scores = self.quality_evaluator.evaluate_response(
prompt=interaction_data.get("prompt", ""),
response=interaction_data.get("response", ""),
expected_output=interaction_data.get("expected", None)
)
# 记录完整指标
metrics = {
"timestamp": timestamp,
"response_time": interaction_data.get("response_time", 0),
"token_usage": interaction_data.get("token_usage", 0),
"quality_scores": quality_scores,
"parameters": interaction_data.get("parameters", {}),
"success": interaction_data.get("success", True),
"user_feedback": interaction_data.get("user_feedback", None)
}
self.metrics_history.append(metrics)
# 检查告警
self._check_alerts(metrics)
def _check_alerts(self, metrics: Dict[str, Any]):
"""检查告警条件"""
alerts = []
# 响应时间告警
if metrics["response_time"] > self.alert_thresholds["response_time"]:
alerts.append(f"响应时间过长: {metrics['response_time']:.2f}秒")
# 质量分数告警
overall_quality = metrics["quality_scores"].get("overall_score", 0)
if overall_quality < self.alert_thresholds["quality_score"]:
alerts.append(f"质量分数过低: {overall_quality:.2f}")
# Token使用告警
if metrics["token_usage"] > self.alert_thresholds["token_usage"]:
alerts.append(f"Token使用过多: {metrics['token_usage']}")
if alerts:
self._send_alerts(alerts, metrics)
def _send_alerts(self, alerts: List[str], metrics: Dict[str, Any]):
"""发送告警"""
print(f"[ALERT] {datetime.now()}: {'; '.join(alerts)}")
# 实际应用中可以发送邮件、短信或推送到监控系统
def generate_performance_report(self, time_range_hours: int = 24) -> Dict[str, Any]:
"""生成性能报告"""
cutoff_time = datetime.now() - timedelta(hours=time_range_hours)
# 筛选时间范围内的数据
recent_metrics = [
m for m in self.metrics_history
if datetime.fromisoformat(m["timestamp"]) > cutoff_time
]
if not recent_metrics:
return {"message": "无数据"}
# 计算统计指标
response_times = [m["response_time"] for m in recent_metrics]
token_usages = [m["token_usage"] for m in recent_metrics]
quality_scores = [m["quality_scores"]["overall_score"] for m in recent_metrics]
success_count = sum(1 for m in recent_metrics if m["success"])
report = {
"time_range": f"最近{time_range_hours}小时",
"total_interactions": len(recent_metrics),
"success_rate": success_count / len(recent_metrics) * 100,
"performance_metrics": {
"avg_response_time": statistics.mean(response_times),
"p95_response_time": sorted(response_times)[int(len(response_times) * 0.95)],
"avg_token_usage": statistics.mean(token_usages),
"total_tokens": sum(token_usages)
},
"quality_metrics": {
"avg_quality_score": statistics.mean(quality_scores),
"min_quality_score": min(quality_scores),
"quality_distribution": self._calculate_quality_distribution(quality_scores)
},
"recommendations": self._generate_performance_recommendations(recent_metrics)
}
return report
def _calculate_quality_distribution(self, scores: List[float]) -> Dict[str, int]:
"""计算质量分数分布"""
distribution = {"excellent": 0, "good": 0, "fair": 0, "poor": 0}
for score in scores:
if score >= 0.9:
distribution["excellent"] += 1
elif score >= 0.7:
distribution["good"] += 1
elif score >= 0.5:
distribution["fair"] += 1
else:
distribution["poor"] += 1
return distribution
def _generate_performance_recommendations(self, metrics: List[Dict]) -> List[str]:
"""生成性能优化建议"""
recommendations = []
# 分析响应时间
response_times = [m["response_time"] for m in metrics]
avg_response_time = statistics.mean(response_times)
if avg_response_time > 3.0:
recommendations.append("响应时间较长,建议优化Prompt长度或降低max_tokens参数")
# 分析质量分数
quality_scores = [m["quality_scores"]["overall_score"] for m in metrics]
avg_quality = statistics.mean(quality_scores)
if avg_quality < 0.7:
recommendations.append("整体质量偏低,建议优化系统Prompt或调整temperature参数")
# 分析Token使用
token_usages = [m["token_usage"] for m in metrics]
avg_tokens = statistics.mean(token_usages)
if avg_tokens > 800:
recommendations.append("Token使用量较高,建议优化Prompt效率或设置更严格的max_tokens限制")
if not recommendations:
recommendations.append("当前性能表现良好,继续保持")
return recommendations5. 实战案例分析
5.1 客服Agent优化案例
python
# 客服Agent配置优化实例
class CustomerServiceAgentOptimizer:
"""客服Agent优化器"""
def __init__(self):
self.base_config = {
"system_prompt": """
你是一位专业的客服代表,具有以下特点:
1. 友好、耐心、专业
2. 能够准确理解客户问题
3. 提供清晰、有用的解决方案
4. 在无法解决时及时转接人工客服
请始终保持礼貌和专业的态度。
""",
"parameters": ModelParameters(
temperature=0.3,
max_tokens=500,
top_p=0.9,
frequency_penalty=0.1,
presence_penalty=0.0
)
}
self.optimization_results = []
def optimize_for_scenario(self, scenario_type: str) -> Dict[str, Any]:
"""针对特定场景优化配置"""
optimizations = {
"complaint_handling": {
"system_prompt_additions": """
特别注意:
- 首先表达同理心和歉意
- 仔细倾听客户的具体问题
- 提供具体的解决步骤
- 确认客户满意度
""",
"parameter_adjustments": {
"temperature": 0.2, # 更稳定的回复
"max_tokens": 800, # 允许更详细的解释
"presence_penalty": 0.1 # 鼓励提及解决方案
}
},
"product_inquiry": {
"system_prompt_additions": """
产品咨询重点:
- 准确介绍产品特性和优势
- 根据客户需求推荐合适产品
- 提供详细的使用指导
- 主动询问是否需要更多信息
""",
"parameter_adjustments": {
"temperature": 0.4, # 适度创造性
"max_tokens": 600,
"frequency_penalty": 0.2 # 避免重复介绍
}
},
"technical_support": {
"system_prompt_additions": """
技术支持要求:
- 使用清晰的步骤说明
- 避免过于技术性的术语
- 提供多种解决方案
- 确认问题是否解决
""",
"parameter_adjustments": {
"temperature": 0.1, # 高度准确性
"max_tokens": 1000, # 详细的技术说明
"top_p": 0.8 # 更聚焦的回答
}
}
}
if scenario_type not in optimizations:
return self.base_config
optimization = optimizations[scenario_type]
# 构建优化后的配置
optimized_config = {
"system_prompt": self.base_config["system_prompt"] + optimization["system_prompt_additions"],
"parameters": ModelParameters(
temperature=optimization["parameter_adjustments"].get("temperature", self.base_config["parameters"].temperature),
max_tokens=optimization["parameter_adjustments"].get("max_tokens", self.base_config["parameters"].max_tokens),
top_p=optimization["parameter_adjustments"].get("top_p", self.base_config["parameters"].top_p),
frequency_penalty=optimization["parameter_adjustments"].get("frequency_penalty", self.base_config["parameters"].frequency_penalty),
presence_penalty=optimization["parameter_adjustments"].get("presence_penalty", self.base_config["parameters"].presence_penalty)
)
}
return optimized_config
def run_optimization_experiment(self, test_cases: List[Dict]) -> Dict[str, Any]:
"""运行优化实验"""
scenarios = ["complaint_handling", "product_inquiry", "technical_support"]
results = {}
for scenario in scenarios:
optimized_config = self.optimize_for_scenario(scenario)
scenario_results = []
# 筛选相关测试用例
relevant_cases = [case for case in test_cases if case.get("scenario") == scenario]
for test_case in relevant_cases:
# 模拟Agent响应(实际应用中调用真实API)
simulated_response = self._simulate_response(optimized_config, test_case)
# 评估响应质量
quality_scores = QualityEvaluator().evaluate_response(
prompt=test_case["input"],
response=simulated_response,
expected_output=test_case.get("expected_output")
)
scenario_results.append({
"test_case": test_case["input"][:50] + "...",
"quality_score": quality_scores["overall_score"],
"specific_scores": quality_scores
})
results[scenario] = {
"avg_quality": statistics.mean([r["quality_score"] for r in scenario_results]),
"config": optimized_config,
"detailed_results": scenario_results
}
return results
def _simulate_response(self, config: Dict[str, Any], test_case: Dict[str, str]) -> str:
"""模拟Agent响应"""
# 这里应该是实际的模型调用
# 为演示目的,返回模拟响应
scenario = test_case.get("scenario", "general")
input_text = test_case["input"]
if scenario == "complaint_handling":
return f"非常抱歉给您带来不便。我理解您的困扰,让我来帮您解决这个问题。针对您提到的{input_text[:20]}...问题,我建议采取以下步骤..."
elif scenario == "product_inquiry":
return f"感谢您对我们产品的关注。根据您的需求,我为您推荐以下产品特性..."
elif scenario == "technical_support":
return f"我来帮您解决这个技术问题。请按照以下步骤操作:1. 首先检查... 2. 然后确认... 3. 最后验证..."
else:
return "感谢您的咨询,我很乐意为您提供帮助。"
# 测试用例示例
test_cases = [
{
"scenario": "complaint_handling",
"input": "我对你们的服务非常不满意,产品质量有问题,要求退款!",
"expected_output": "表达同理心,提供解决方案,确认客户需求"
},
{
"scenario": "product_inquiry",
"input": "请介绍一下你们的高端产品系列,我需要专业级的功能",
"expected_output": "详细介绍产品特性,根据需求推荐"
},
{
"scenario": "technical_support",
"input": "软件安装后无法启动,显示错误代码E001",
"expected_output": "提供具体的故障排除步骤"
}
]
# 运行优化实验
optimizer = CustomerServiceAgentOptimizer()
# results = optimizer.run_optimization_experiment(test_cases)6. 高级优化技巧
6.1 动态参数调整
python
# 动态参数调整系统
class DynamicParameterAdjuster:
"""动态参数调整器"""
def __init__(self):
self.adjustment_rules = {}
self.performance_history = []
self.learning_rate = 0.1
def add_adjustment_rule(self, rule_name: str, condition: callable,
adjustment: callable):
"""添加调整规则"""
self.adjustment_rules[rule_name] = {
"condition": condition,
"adjustment": adjustment
}
def adjust_parameters(self, current_params: ModelParameters,
context: Dict[str, Any],
performance_metrics: Dict[str, float]) -> ModelParameters:
"""动态调整参数"""
adjusted_params = ModelParameters(
temperature=current_params.temperature,
max_tokens=current_params.max_tokens,
top_p=current_params.top_p,
frequency_penalty=current_params.frequency_penalty,
presence_penalty=current_params.presence_penalty
)
# 应用调整规则
for rule_name, rule in self.adjustment_rules.items():
if rule["condition"](context, performance_metrics):
adjusted_params = rule["adjustment"](adjusted_params, context, performance_metrics)
return adjusted_params
def setup_default_rules(self):
"""设置默认调整规则"""
# 规则1:质量分数低时降低temperature
def low_quality_condition(context, metrics):
return metrics.get("quality_score", 1.0) < 0.6
def reduce_temperature(params, context, metrics):
params.temperature = max(params.temperature - 0.1, 0.1)
return params
self.add_adjustment_rule("low_quality", low_quality_condition, reduce_temperature)
# 规则2:响应时间长时减少max_tokens
def slow_response_condition(context, metrics):
return metrics.get("response_time", 0) > 5.0
def reduce_tokens(params, context, metrics):
params.max_tokens = max(params.max_tokens - 100, 200)
return params
self.add_adjustment_rule("slow_response", slow_response_condition, reduce_tokens)
# 规则3:重复内容多时增加frequency_penalty
def repetitive_condition(context, metrics):
return metrics.get("repetition_score", 0) > 0.7
def increase_frequency_penalty(params, context, metrics):
params.frequency_penalty = min(params.frequency_penalty + 0.1, 1.0)
return params
self.add_adjustment_rule("repetitive", repetitive_condition, increase_frequency_penalty)
# 使用示例
adjuster = DynamicParameterAdjuster()
adjuster.setup_default_rules()
# 模拟参数调整
current_params = ModelParameters(temperature=0.7, max_tokens=1000)
context = {"task_type": "creative_writing", "user_level": "beginner"}
metrics = {"quality_score": 0.5, "response_time": 6.0, "repetition_score": 0.8}
# adjusted_params = adjuster.adjust_parameters(current_params, context, metrics)6.2 多模型集成策略
php
# 多模型集成配置
class MultiModelEnsemble:
"""多模型集成系统"""
def __init__(self):
self.models = {}
self.routing_rules = {}
self.fallback_chain = []
def register_model(self, model_name: str, model_config: Dict[str, Any]):
"""注册模型配置"""
self.models[model_name] = {
"config": model_config,
"performance_stats": {
"success_rate": 1.0,
"avg_quality": 0.8,
"avg_response_time": 2.0
}
}
def add_routing_rule(self, rule_name: str, condition: callable, target_model: str):
"""添加路由规则"""
self.routing_rules[rule_name] = {
"condition": condition,
"target_model": target_model
}
def route_request(self, request_context: Dict[str, Any]) -> str:
"""路由请求到合适的模型"""
# 检查路由规则
for rule_name, rule in self.routing_rules.items():
if rule["condition"](request_context):
target_model = rule["target_model"]
if target_model in self.models:
return target_model
# 默认选择性能最好的模型
best_model = max(self.models.keys(),
key=lambda m: self.models[m]["performance_stats"]["success_rate"])
return best_model
def setup_default_routing(self):
"""设置默认路由规则"""
# 创意任务路由到高temperature模型
def creative_task_condition(context):
return context.get("task_type") == "creative"
self.add_routing_rule("creative_tasks", creative_task_condition, "creative_model")
# 事实性任务路由到低temperature模型
def factual_task_condition(context):
return context.get("task_type") == "factual"
self.add_routing_rule("factual_tasks", factual_task_condition, "factual_model")
# 长文本任务路由到大token模型
def long_text_condition(context):
return len(context.get("input_text", "")) > 2000
self.add_routing_rule("long_text", long_text_condition, "long_context_model")
# 配置多模型集成
ensemble = MultiModelEnsemble()
# 注册不同配置的模型
ensemble.register_model("creative_model", {
"parameters": ModelParameters(temperature=0.9, max_tokens=2000, frequency_penalty=0.3),
"system_prompt": "你是一个富有创造力的助手..."
})
ensemble.register_model("factual_model", {
"parameters": ModelParameters(temperature=0.2, max_tokens=800, top_p=0.8),
"system_prompt": "你是一个准确可靠的信息助手..."
})
ensemble.register_model("long_context_model", {
"parameters": ModelParameters(temperature=0.5, max_tokens=4000, top_p=0.9),
"system_prompt": "你擅长处理长文本和复杂分析..."
})
ensemble.setup_default_routing()7. 总结与最佳实践建议
7.1 配置优化检查清单
|----------|---------------|--------------|-----------------|
| 优化维度 | 检查项目 | 最佳实践 | 常见问题 |
| Prompt设计 | 角色定义清晰 | 明确AI的身份和能力边界 | 角色模糊导致回答不一致 |
| Prompt设计 | 指令具体明确 | 使用具体的动词和量化指标 | 指令过于抽象或模糊 |
| Prompt设计 | 示例质量高 | 提供多样化的高质量示例 | 示例单一或质量差 |
| 参数调优 | Temperature合理 | 根据任务类型选择合适值 | 创意任务用低值,事实任务用高值 |
| 参数调优 | Token限制适当 | 平衡完整性和成本 | 限制过严或过松 |
| 参数调优 | 惩罚参数平衡 | 避免过度重复或过度发散 | 参数设置极端 |
| 性能监控 | 质量指标全面 | 多维度评估响应质量 | 只关注单一指标 |
| 性能监控 | 实时监控告警 | 设置合理的告警阈值 | 缺乏监控或告警过频 |
7.2 配置优化流程
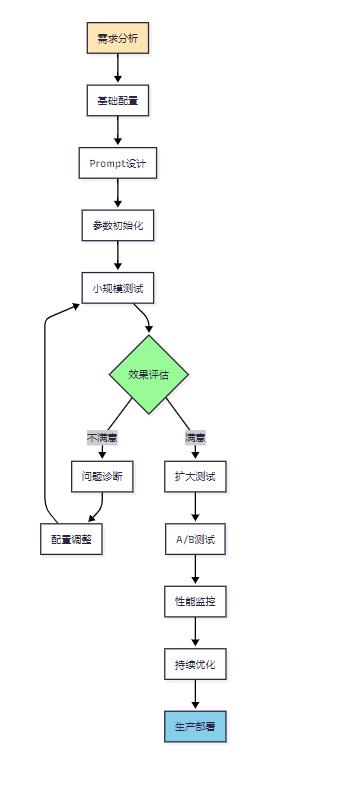
图2:Agent配置优化流程图
7.3 实践建议总结
1. Prompt工程最佳实践
- 始终从用户需求出发设计Prompt
- 使用结构化的Prompt模板
- 定期收集用户反馈优化Prompt
- 建立Prompt版本管理机制
2. 参数调优策略
- 基于任务类型选择初始参数
- 使用A/B测试验证参数效果
- 建立参数调优的标准流程
- 记录参数变更的影响
3. 性能监控要点
- 建立全面的质量评估体系
- 设置合理的性能告警机制
- 定期分析性能趋势
- 基于数据驱动优化决策
作为一名深度参与Agent配置优化的技术专家,通过本文的系统性介绍,我希望能够帮助开发者全面掌握Agent配置的核心技术和最佳实践。从Prompt工程的基础理论到参数调优的高级技巧,从性能监控的指标设计到动态优化的实现方案,每一个环节都直接影响着Agent的最终表现。在实际应用中,我建议开发者要始终坚持数据驱动的优化理念,通过持续的测试、监控和调整来提升Agent的性能。同时,要注重用户体验的反馈,将定量的指标评估与定性的用户感受相结合,才能真正构建出高质量的智能体应用。随着AI技术的不断发展,Agent配置优化也将朝着更加智能化、自动化的方向演进,未来必将为我们带来更多令人惊喜的优化工具和方法。让我们一起在Agent配置优化的道路上不断探索,为用户创造更好的AI交互体验。
Untitled diagram | Mermaid Chart
我是摘星!如果这篇文章在你的技术成长路上留下了印记:
👁️ 【关注】与我一起探索技术的无限可能,见证每一次突破
👍 【点赞】为优质技术内容点亮明灯,传递知识的力量
🔖 【收藏】将精华内容珍藏,随时回顾技术要点
💬 【评论】分享你的独特见解,让思维碰撞出智慧火花
🗳️ 【投票】用你的选择为技术社区贡献一份力量
技术路漫漫,让我们携手前行,在代码的世界里摘取属于程序员的那片星辰大海!
标签: #Agent配置 #Prompt工程 #参数调优 #性能优化 #智能体开发