本文解读的是 OPPO AI Agent 团队于 2025 年 8 月发布的论文
《Efficient Agents: Building Effective Agents While Reducing Cost》
arXiv: 2508.02694v1
引言
大语言模型驱动的智能体(Agent)近年来在复杂任务上展现了惊人的能力------从多轮推理、跨工具调用,到信息检索与整合。然而,性能的提升往往伴随着成本的飙升:更多的推理步数、更多的工具调用、更复杂的记忆机制,都意味着更多的 token 消耗与 API 调用费用。
那么问题来了:
- 真的需要如此复杂的 Agent 才能解决任务吗?
- 哪些组件是"高成本、低收益"的?
- 能否在尽量保留性能的前提下降低成本?
来自 OPPO AI Agent 团队的这篇论文系统回答了这些问题,并提出了一套"高性价比"Agent 配置,在 GAIA 基准测试中保留了其他主流智能体框架的 96.7% 的准确率的前提下,单题过关成本降低了约 28.4%。
核心内容
论文提出了一个非常关键的指标来度量成本:cost-of-pass ,直观上的含义是:得到一个正确答案所需的期望花费 ,公式是单次推理成本/成功率 。 此外由于输入输出的计价方案往往不一样,论文研究中也会注意到计算花费是要分开算输入和输入的消耗再加起来。
本研究的评测基准是GAIA数据集,并且按照难度分成了L1,L2,L3三档分别统计指标。评测的对象维度有下面5个:
- Backbones (骨干LLM)
- 测试时扩展策略(Best-of-N)
- Planning(规划)
- Tool Using (工具使用)
- Memory (记忆)
Backbones
在模型选择上,最近很火热的推理类型的模型是必须要上阵的,这类模型的特点是利用扩展的链式推理能力可以提升回答的准确度,但带来的副作用是会消耗大量token甚至会出现过度思考。模型架构上也有MoE架构的Qwen3以及密集型的QwQ。
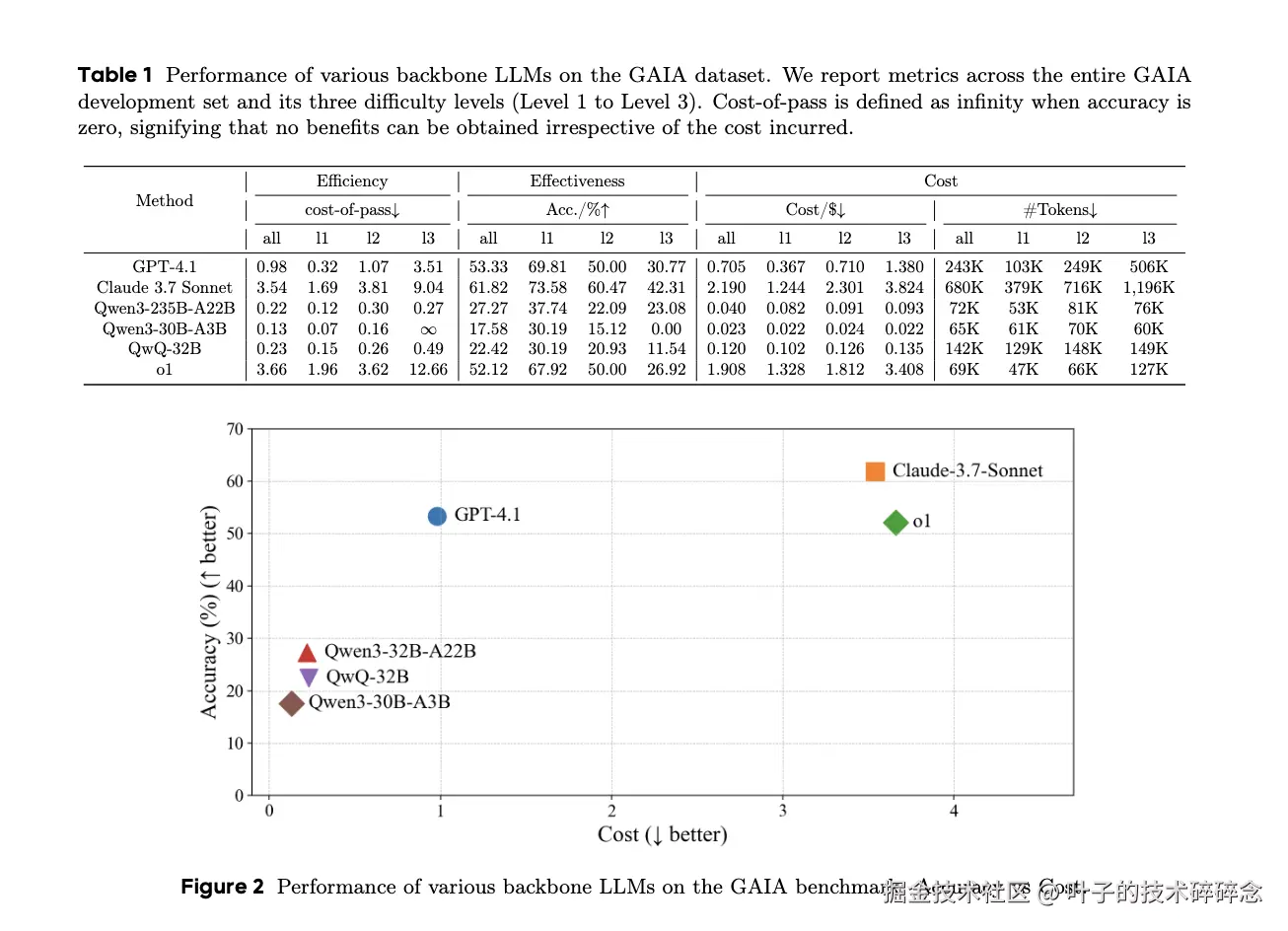
通过测试结果的图表就能很明显的看出来,任务越难(L3)推理型大模型 cost-of-pass 激增 (如 Claude 1.69→9.04;o1 1.96→12.66),显示高难任务效率恶化 显著。MoE 小激活在低复杂度/省钱 方面有优势,但效果有限。
Test-time Scaling Stratiges
在测试时利用多次推理运行可以提升模型性能,这种方式需要多次重复调用大模型,这显然会增加token的消耗。本研究中评估了常见的策略,即最佳N(BoN, Best-of-N)。在每个步骤中,从N个可能的动作中采样并通过进度奖励模型(PRM)进行评估。得分最高的动作被保留为下一个动作。
实验测试了N=1、N=2、N=4(每个任务分别生成 1、2、4 个解答,选最优)几种情况下的结果。
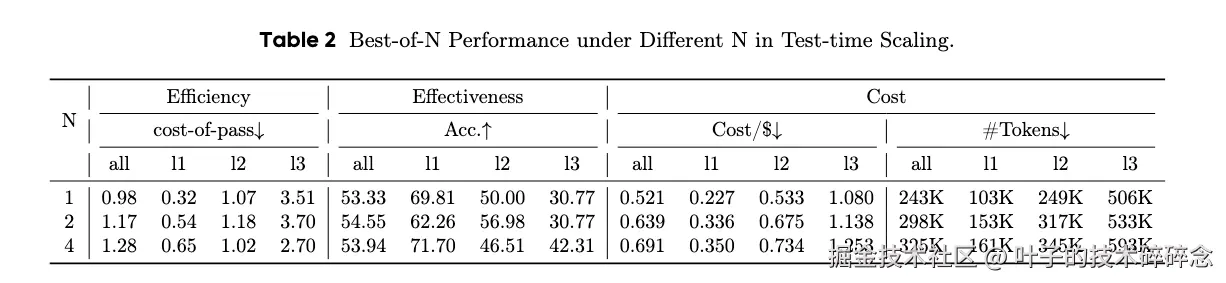
可以看出:
- N=1 → N=4,准确率仅从 53.33% 微升到 53.94%。
- 成本从 0.98 增加到 1.28(约上涨 30%)。
- Token 消耗从 243K → 325K。
BoN 对准确率提升有限 ,但显著增加调用次数与 token 消耗。
Planning
目前智能体设计中,为了提升长期任务的处理能力,往往会在执行前先进行任务规划,这个规划的操作当然对于任务执行的效率是会产生影响的。在论文实验中,在采取任何行动前会被提示生成一个显式计划。随后,它将按照该计划一步步执行,这里采用了ReAct风格,且为了适应动态环境,计划会定期修订:每执行N步后,智能体将基于当前上下文重新生成计划。并且实验改变了允许的ReAct步骤的最大数量,选择4、8、12。此外还通过将规划间隔N设置为1、2、4来控制计划更新的频率。
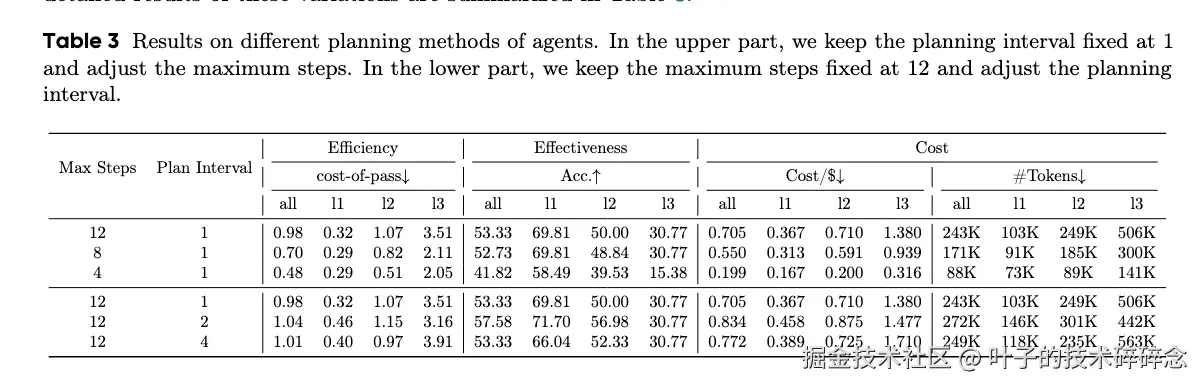
从实验结果可以看到:
- 从 4 步到 8 步准确率大幅提升,但继续提升到 12 步收益趋缓,成本显著增加。
- 过于频繁的重规划虽然可能带来小幅性能提升,但成本也同步增加。
当前模型在处理推理长度调节时面临挑战,常常出现过度思考的情况,导致在问题无法解决时成本过高。适度的规划复杂性能够显著提升效率。
Tool Using
现在的智能体设计有很多都会引入外部工具,但这显然会带来额外的开销。本论文研究中关注的是网页浏览器工具的有效性和效率。主要原因在于:1. 它是一个广泛使用的工具;2.这个工具可能对效率产生很大的影响,因为网页中会包含大量的文本、多媒体等内容,处理过程中会产生大量的token消耗。
实验中也控制了几种跟浏览相关的因素。包括多检索源 (Google、DuckDuckGo等)、浏览策略 (仅搜索静态元素、具有基本处理能力的浏览器、高级操作功能的浏览器。)以及扩展查询重写次数三个方面。
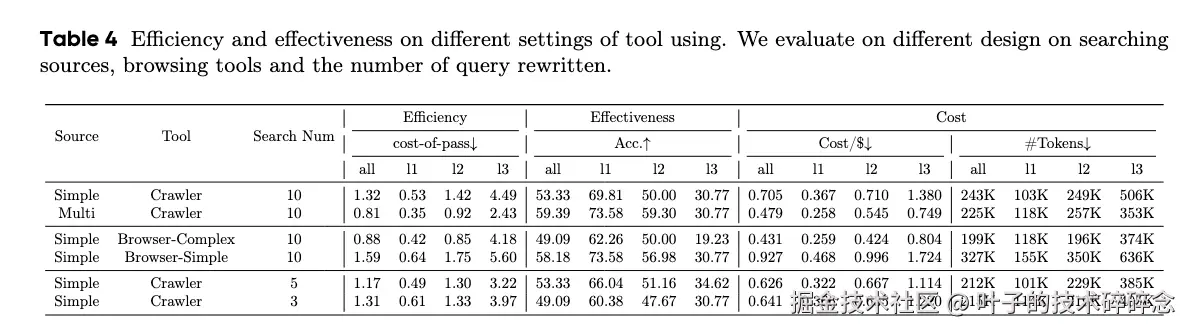
实验结果大概可以总结为:
- 检索源:多源检索(Google/Wiki/Bing/Baidu/DuckDuckGo)显著优于单源,准确率从 53.33% 提升到 59.39%,cost-of-pass 从 1.32 降到 0.81。
- 浏览策略:静态抓取/轻量处理比复杂交互更高效。
- 查询重写数量:更多的查询重写(如 10 次)有助于提升效果并降低成本。
不同的工具配置,例如增加搜索来源、简化浏览器操作以及扩展重写的查询用于网络搜索,显然能够提升信息检索的有效性和效率。
Memory
记忆模块是智能体系统中很重要的一个模块,它能够实现与动态环境的有效交互并从中学习。记忆模块支持经验积累和知识抽象等核心功能,同时作为推理过程的一部分,它也会引入额外的计算成本。本论文研究中设计了六种记忆配置来评估它们对整个系统的有效性和效率的影响,包括简单记忆、摘要记忆、w/o extra无额外内存记忆、额外摘要记忆、额外固定长度记忆、额外混合记忆。
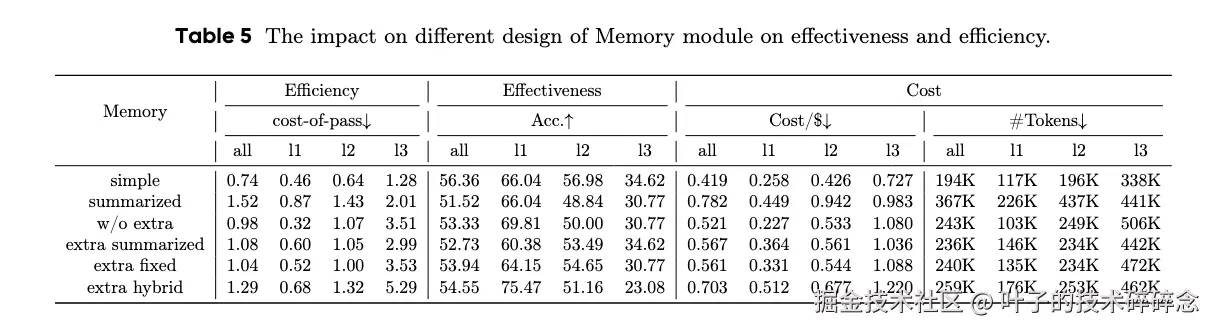
从实验结果来看,简单记忆往往优于复杂记忆,原因是摘要过程会引入信息损失,并额外消耗 token。
高效智能体的最优配置

文章最终给出了推荐的最高效智能体配置如上图所示,具体而言,就是对于智能体系统中的每个组件,采用在不导致性能显著下降的情况下成本最低的配置。
论文中还将当前这种智能体设计和两个开源智能体系统进行了比较,包括OWL和Smolagents。最终结果上,高效智能体在保持类似性能的同时,实现了28.4%的成本降低。
总结
这篇论文是一篇更像是系统性工程实证性的论文,并不难懂,但其最大的价值在于,它不是在"卷"能力,而是在"卷"性价比。 在 Agent 落地越来越多的今天,这种研究对于我们这些大模型应用开发者意识到:
- 高性能 ≠ 高复杂度
- 简单的设计有时反而更高效
- 数据驱动的成本分析,比凭感觉调参更靠谱