论文地址:http://arxiv.org/pdf/2406.01820v1
代码地址:https://github.com/iurada/px-ntk-pruning
关注UP CV缝合怪,分享最计算机视觉新即插即用模块,并提供配套的论文资料与代码。
https://space.bilibili.com/473764881
摘要
本研究展示了如何在训练前降低深度学习模型的计算成本和内存需求。本研究专注于初始化时的剪枝框架 ,并提出了一种新的算法,利用神经正切核 (NTK) 理论 来使稀疏网络的训练动态与密集网络的训练动态对齐 。具体而言,本研究展示了如何通过提供NTK 迹的解析上界 来考虑 NTK 谱中通常被忽略的数据相关成分 ,该上界是通过将神经网络分解为单独的路径 获得的。这引出了本研究提出的路径排除 (PX) 方法 ,这是一种前瞻性剪枝方法 ,旨在保留对 NTK 迹影响最大的参数。PX 即使在高稀疏度 下也能够找到彩票 (即好的路径) ,并大大减少了额外训练的需求 。当应用于预训练模型 时,它可以直接提取用于多个下游任务 的子网络,其性能与密集网络相当 ,但成本和计算量却大大降低 。
引言
本研究关注神经网络剪枝 领域,旨在降低深度学习模型的计算成本和内存需求 。现代深度神经网络普遍存在过参数化 的问题,导致高昂的计算资源和能源成本,对未来的轻量级和高效模型 应用提出了挑战。为了缓解资源需求,减少不重要的神经元或连接 成为了一种有效的解决方案。目前,神经网络剪枝方法主要分为在训练后期或训练后 进行剪枝,以减少推理时间。近年来,初始化剪枝(PaI)方法逐渐兴起,它可以在训练前 就找到随机初始化的子网络,并在训练后达到与原始密集网络相当的测试精度,大大降低了学习成本。
以往的PaI策略主要基于参数对损失的影响 或基于估计网络信息流的不同显著性指标 来进行参数评分。一些最新的研究则关注基于神经正切核理论(NTK)对训练动态的评估来定义参数得分。然而,这些方法通常忽略或粗略地估计了数据对NTK谱的贡献 ,声称数据对寻找网络中的"彩票 "(即良好的路径)影响很小。此外,部分方法还会面临层坍塌 的问题,即过早地剪枝整个层,导致网络无法训练。同时,如何将剪枝应用于下游迁移前的预训练网络 仍然是一个开放性问题,这对于日益增长的预训练模型的压缩和迁移能力的保留至关重要。
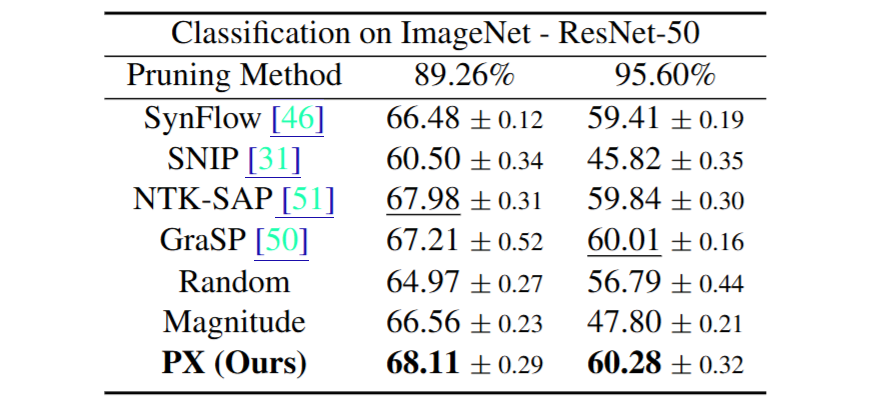
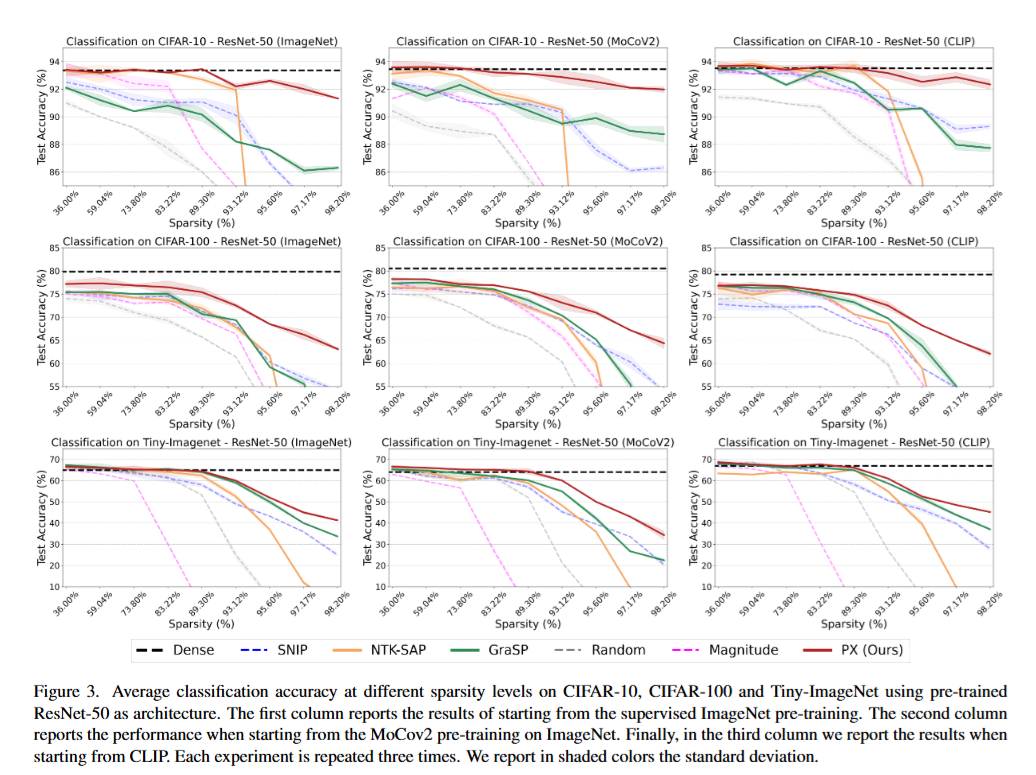
本研究提出了一个名为路径排除(PX)的初始化剪枝方法,通过一个新定义的NTK迹上界 来估计每个网络参数对训练动态的相关性。PX的显著性函数 来自于该上界,保证了网络参数的得分均为正值。结合PX的迭代特性 ,这可以避免层坍塌的发生。与先前的工作不同,PX的相关性得分同时依赖于数据、原生神经元和层连接 。实验结果表明,PX不仅对不同的架构和任务具有鲁棒性 ,而且可以有效地用于在大型预训练模型 中搜索子网络,并在很大程度上保持其迁移能力。
论文创新点
✨ 本研究提出了一个名为Path eXclusion (PX) 的新型剪枝方法,该方法在初始化阶段进行剪枝,利用神经正切核(NTK)理论来使稀疏网络的训练动态与稠密网络的训练动态保持一致。 ✨
-
🔍 利用NTK迹的新型上界进行剪枝: 🔍
- 不同于以往只关注与路径核相关的数据无关项的工作,PX考虑了数据相关项,从而更好地反映了每个权重对NTK迹的贡献。
- 通过保留对NTK迹影响最大的参数,PX能够识别对网络性能至关重要的"彩票路径"。
-
🛡️ 避免层坍塌问题: 🛡️
- 由于PX的显著性函数只产生正值,并结合其迭代剪枝过程,保证了层间显著性的保留,从而避免了整层神经元的移除,保证了网络的可训练性。
-
🚀 鲁棒性和有效性: 🚀
- PX不仅对不同的架构和任务具有鲁棒性,而且可以有效地用于搜索大型预训练模型中的子网络,同时几乎完整地保留其迁移学习能力。
- 在极高的稀疏度下,PX的性能优于其他剪枝方法,并且在从预训练模型进行迁移学习时,PX能够保持接近稠密网络的性能。
-
📊 特征谱保留和层宽度保持: 📊
- 通过分析固定权重NTK的特征谱,证实PX能够有效地保留原始稠密网络的特征谱,进一步验证了PX的设计理念。
- PX能够在高稀疏度下保持每层的输出宽度,避免了其他迭代剪枝方法中常见的瓶颈问题。
论文实验