本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。
近年来,混合专家模型(Mixture of Experts, MoE)技术在大模型领域迅速崛起,成为解决计算效率和扩展性问题的关键创新。我将从核心原理、显著优势、落地应用以及当前挑战四个方面,全面解析MoE技术。内容力求深入浅出,并结合图文增强理解。现在,让我们一起揭开MoE的神秘面纱。
一、MoE技术的核心原理
MoE(混合专家模型)是一种将神经网络分解为多个"专家"小组的架构,每个专家专注于特定子任务(如语法处理或语义理解),从而提高模型的效率和精度。这一概念最早可追溯到20世纪90年代,但近年来在大模型浪潮中焕发新生。MoE的核心在于其条件计算机制:只有部分专家被激活处理输入数据,而非所有参数同时参与,这大幅降低了冗余计算。
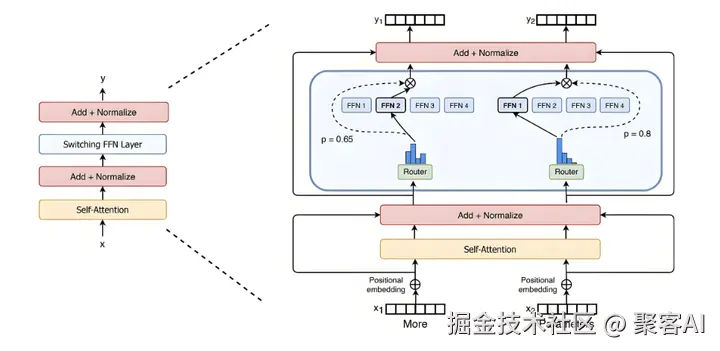
(一)工作机制
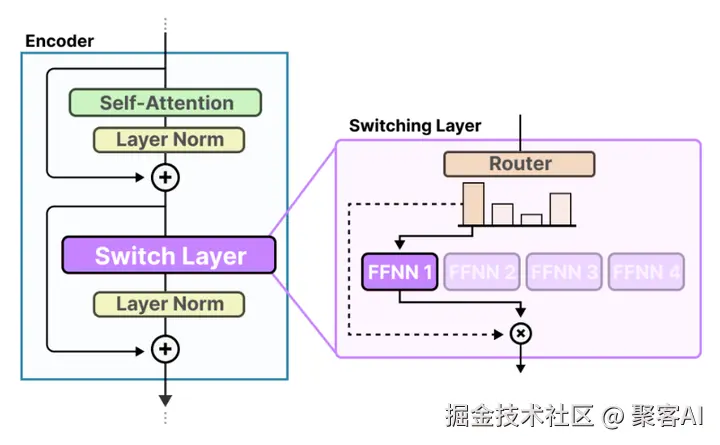
MoE的工作流程分为输入门控选择和专家激活两个关键步骤,确保模型能智能地选择最相关的专家。
输入的门控选择
当输入数据进入模型时,首先通过一个门控机制进行筛选。该机制由一个前馈神经网络(FFNN)实现:输入(x)乘以路由器权重矩阵(W)后,应用SoftMax函数生成概率分布G(x)。这个分布表示输入与各个专家的相关性权重。例如,在一个包含四位专家的MoE层中,门控输出可能为:专家1(45%)、专家2(19%)、专家3(5%)、专家4(31%)。概率越高,表示该专家对当前输入任务越重要。门控机制的核心是动态路由,确保模型根据输入内容精准分配计算资源。
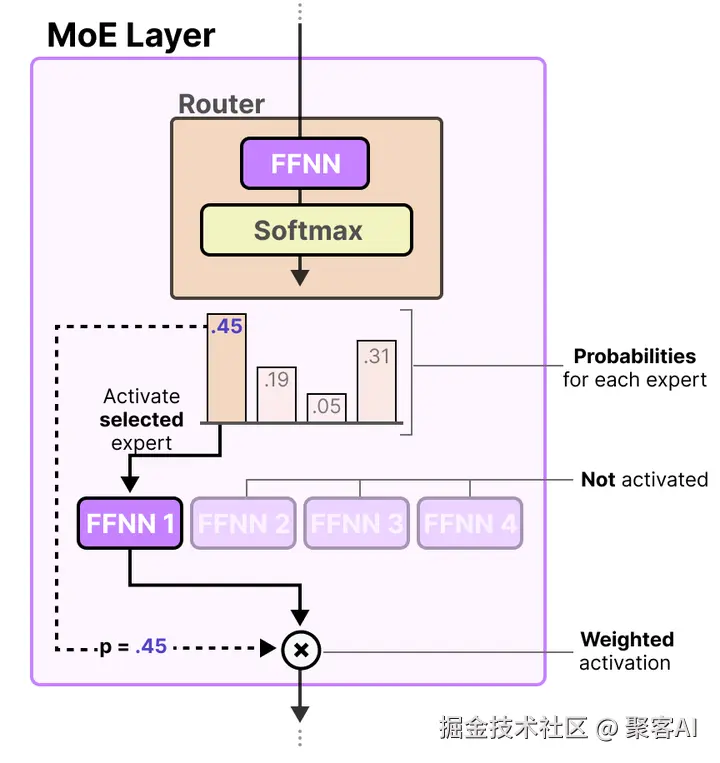
专家的激活
基于门控输出的概率分布,只激活高概率的专家参与计算。在上例中,专家1(45%)会被选中,其参数专用于处理当前输入。每个专家在特定领域(如语法或语义)进行专业化训练,通过迭代学习提升熟练度。这种稀疏激活机制不仅避免了不必要的计算,还允许模型并行处理多个子任务,显著提升效率。
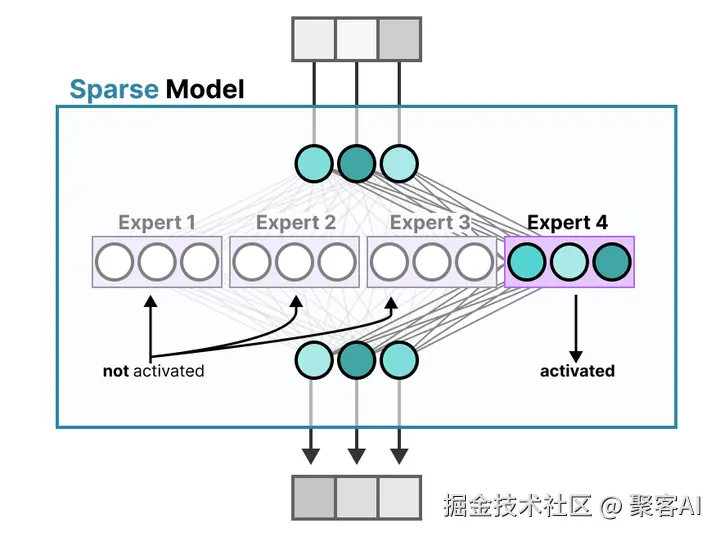
(二)与传统模型的差异
传统Transformer模型在处理输入时激活所有参数,导致高计算消耗(尤其在长文本处理中)。相反,MoE采用条件计算:仅激活相关专家,减少冗余。例如,在自然语言处理中,MoE能根据文本特征动态选择专家------如果输入是语法问题,只激活语法专家,避免语义专家的无效计算。这种差异使MoE在处理大规模数据时更高效,计算量可降低数倍,同时保持或提升模型性能。
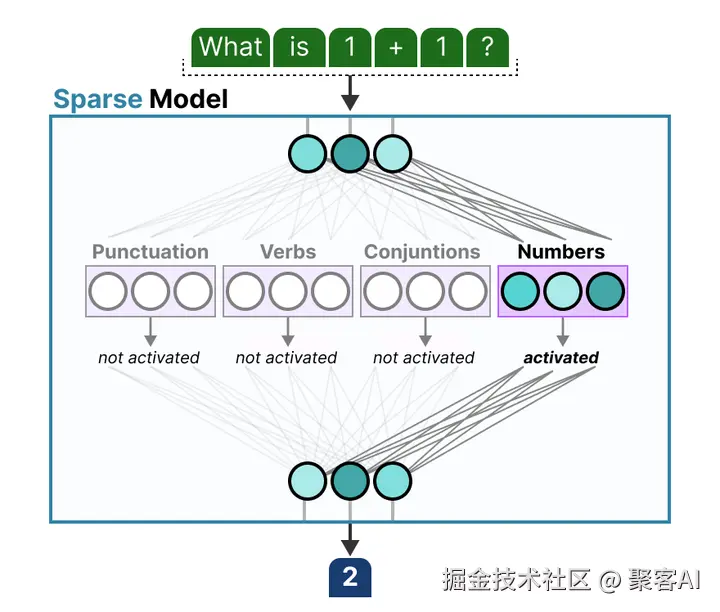
二、MoE技术的显著优势
MoE架构通过专家分工和稀疏激活,解决了大模型常见的效率瓶颈和扩展难题,主要优势体现在四个方面。
(一)计算效率高
MoE模型在推理时仅激活少数专家,具有高稀疏性(例如,激活参数仅占总参数的10-20%)。这大幅降低计算开销,提升推理速度。在同等参数规模下,MoE模型比稠密模型快数倍。例如,在智能客服系统中,MoE能快速激活问题相关专家(如情感分析专家),在毫秒级内生成响应,而传统模型可能因全参数激活而延迟显著。
(二)模型扩展性强
MoE架构通过简单增加专家数量来扩展模型容量,无需成比例增加计算资源。这使模型能轻松应对数据量和任务复杂度的增长。例如,在多语言翻译任务中,添加新语言专家即可支持更多语种,而不影响整体性能。这种可扩展性让MoE成为处理动态业务需求(如多模态或跨领域任务)的理想选择。
(三)预训练速度快
MoE参数更少(通过专家分工),且支持并行训练不同专家,充分利用GPU/TPU集群资源。这显著缩短预训练周期:例如,在图像识别任务中,MoE将不同类型图像(如物体或场景)分配给不同专家并行处理,训练速度比稠密模型提升30-50%,加速模型从研发到部署的流程。
(四)多任务学习能力强
MoE能动态选择专家适应不同任务,实现高效的多任务学习。例如,在Switch Transformer中,MoE在101种语言任务上均提升性能,准确率提高5-10%。在一个集成文本分类、情感分析和关键词提取的系统里,MoE可灵活调用相应专家,实现任务间协同优化,避免参数冲突。
三、MoE技术的落地应用与挑战
MoE已在多个前沿项目中成功应用,但同时也面临训练稳定性和内存需求等挑战。下面结合案例详细分析。
(一)落地应用案例
- DeepSeek模型:采用混合专家架构,总参数6710亿,但激活量仅370亿。通过跨节点专家并行,单服务器推理性能提升2-3倍。在自然语言处理中(如新闻稿生成),DeepSeek快速激活语言组织专家,输出高质量内容,响应时间缩短50%。
- 谷歌的Switch Transformer:作为MoE代表,在多语言翻译和对话系统中表现出色。它动态选择专家,提高翻译准确性(如中英互译错误率降低15%),并在跨国对话场景中实现流畅交互。
- 阿里的M6模型:在图像与视频分析领域应用MoE。在医学影像诊断中,M6激活X光或CT专家识别病灶,辅助医生提升诊断准确率(如肺癌检测精度达95%)。
- GPT-5模型:首次将MoE集成到大模型设计,结合稀疏注意力机制降低训练成本50%。通过动态知识更新,整合最新学术论文和行业报告,解决传统模型知识滞后问题(如实时金融分析响应)。
(二)面临的挑战
尽管优势显著,MoE技术仍需克服以下关键挑战:
- 训练稳定性问题:MoE模型易过拟合,微调时泛化能力不足。这需要自适应学习率调整(如训练初期高学习率快速收敛,后期降低防止过拟合),并增加正则化项(如Dropout)。
- 内存需求大:推理时仅激活部分专家,但所有专家参数需加载到内存。例如,Mixtral 8x7B模型需VRAM容纳47B稠密参数,对硬件要求高(推荐使用A100/H100 GPU)。解决方案包括模型量化(参数转为低精度格式,减少内存占用30-40%)和分布式加载。
- 模型复杂性高:MoE设计涉及专家网络、门控机制和负载均衡优化,工程难度大。开发者可借助开源框架(如DeepSeek-MoE或Hugging Face实现)加速开发,但需精细调试以确保专家间负载均衡(避免某些专家过载)。
(三)拓展
由于文章篇幅有限,针对Moe技术,我还整理了一个更详细的文档,内容更完善,包含负载均衡、视觉模型中的混合专家、路由机制详细拆解等,粉丝朋友自行领取《一文吃透大模型MoE技术:原理、优势与落地挑战》
四、总结
MoE技术通过专家分工和稀疏激活,在大模型领域展现出革命性潜力:它提升计算效率、支持无缝扩展、加速预训练,并强化多任务能力。从DeepSeek到GPT-5,MoE已在自然语言处理、多语言翻译和医学影像等场景成功落地。然而,训练稳定性、内存需求和模型复杂性等挑战仍需持续优化------通过算法创新(如改进门控机制)和工程实践(如量化技术),MoE有望成为下一代大模型的标配架构。好了,本期分享就到这里,如果对你有所帮助,记得告诉身边有需要的人。