【AI应用探索】-7- LLaMA-Factory微调模型
- [1 环境配置](#1 环境配置)
-
- [1.1 软件依赖](#1.1 软件依赖)
- [1.2 环境搭建](#1.2 环境搭建)
- [1.3 安装llama-Factory](#1.3 安装llama-Factory)
-
- [1.3.1 参数配置](#1.3.1 参数配置)
-
- [1.3.1.1 FlashAttention](#1.3.1.1 FlashAttention)
- [1.3.1.2 Unsloth](#1.3.1.2 Unsloth)
- [1.3.1.3 Liger Kernel](#1.3.1.3 Liger Kernel)
- [1.4 下载模型](#1.4 下载模型)
- [1.5 关键参数解析](#1.5 关键参数解析)
- [1.6 准备微调数据集](#1.6 准备微调数据集)
-
- [1.6.1 自己准备数据集处理](#1.6.1 自己准备数据集处理)
-
- [1.6.1.1 数据集处理](#1.6.1.1 数据集处理)
- [1.6.1.2 配置参数](#1.6.1.2 配置参数)
- [1.6.2 使用准备好的数据集](#1.6.2 使用准备好的数据集)
- [1.7 开始训练](#1.7 开始训练)
- [1.8 导出模型](#1.8 导出模型)
1 环境配置
我们统一使用conda来管理我们的python环境
1.1 软件依赖
1.1.1必需项
| 软件/库 | 至少版本 | 推荐版本 |
|---|---|---|
| python | 3.9 | 3.10 |
| torch | 1.13.1 | 2.6.0 |
| transformers | 4.41.2 | 4.50.0 |
| datasets | 2.16.0 | 3.2.0 |
| accelerate | 0.34.0 | 1.2.1 |
| peft | 0.14.0 | 0.15.0 |
| trl | 0.8.6 | 0.9.6 |
1.1.2可选项
| 软件/库 | 至少版本 | 推荐版本 |
|---|---|---|
| CUDA | 11.6 | 12.2 |
| deepspeed | 0.10.0 | 0.16.4 |
| bitsandbytes | 0.39.0 | 0.43.1 |
| vllm | 0.4.3 | 0.7.3 |
| flash-attn | 2.3.0 | 2.7.2 |
1.2 环境搭建
创建python环境为3.10的conda环境并激活
bash
conda create -n llmfinetune python=3.10 -y
conda activate llmfinetune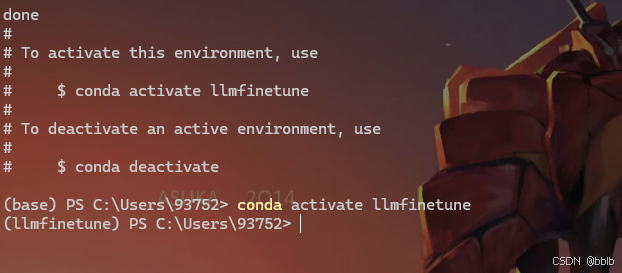
激活环境后,我们需要安装所有必需的库。
查看下我们的cuda版本,至少需要12.2以上
bash
nvidia-smi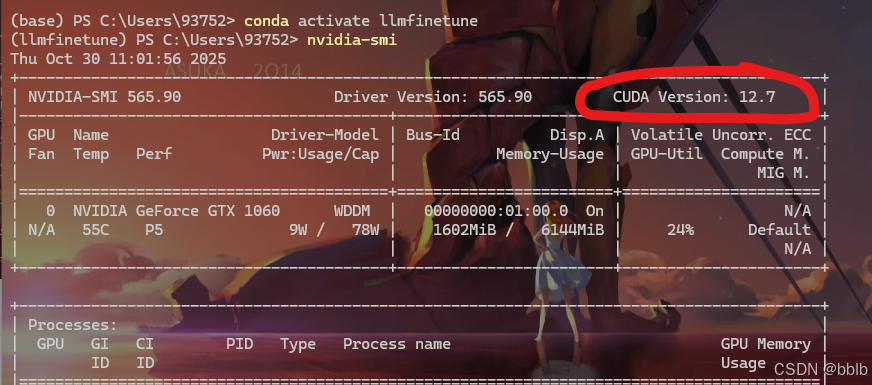
查看现在pytorch的版本,稳定版已经到2.9.0了
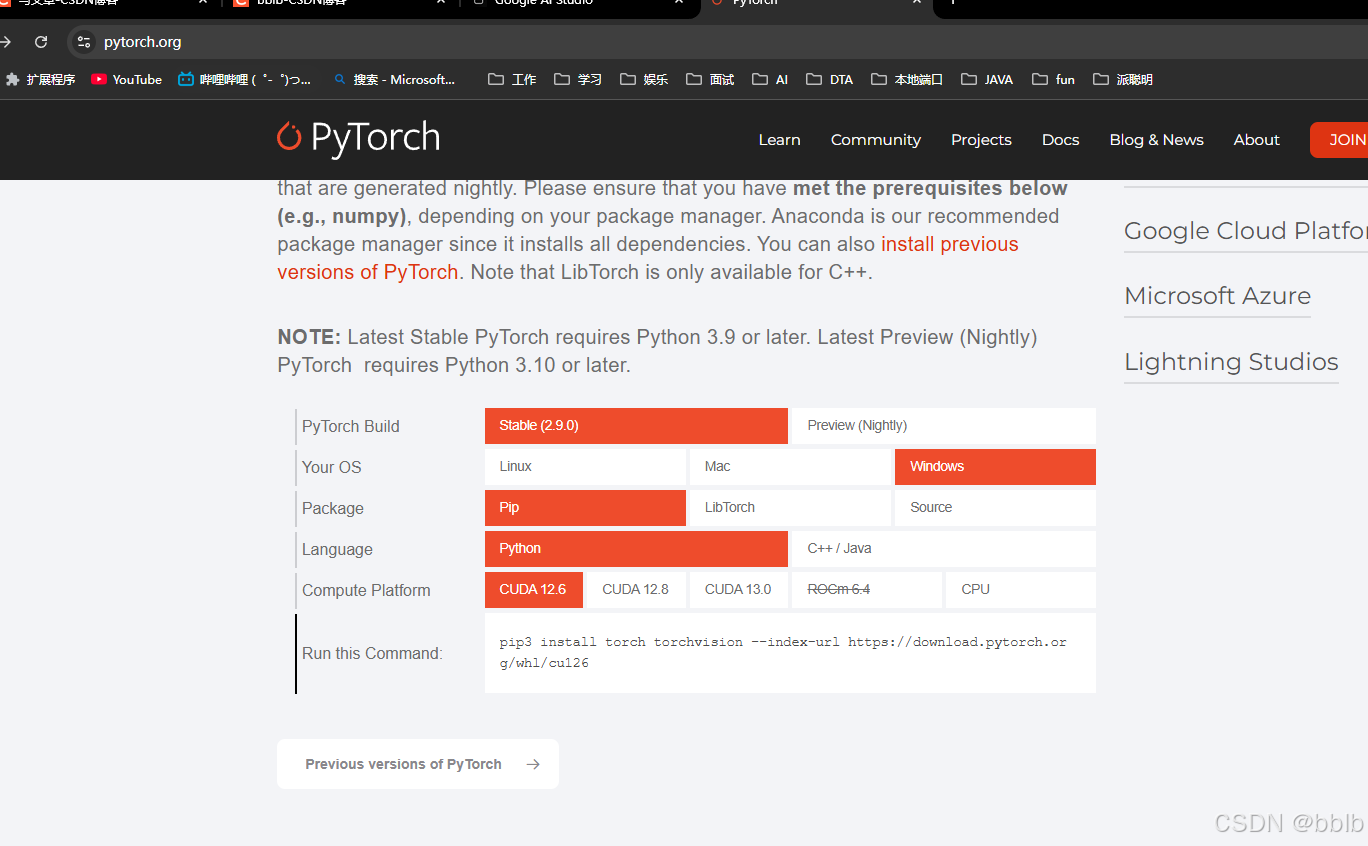
我们直接安装即可cuda版本为12.6的即可
bash
pip3 install torch torchvision --index-url https://download.pytorch.org/whl/cu126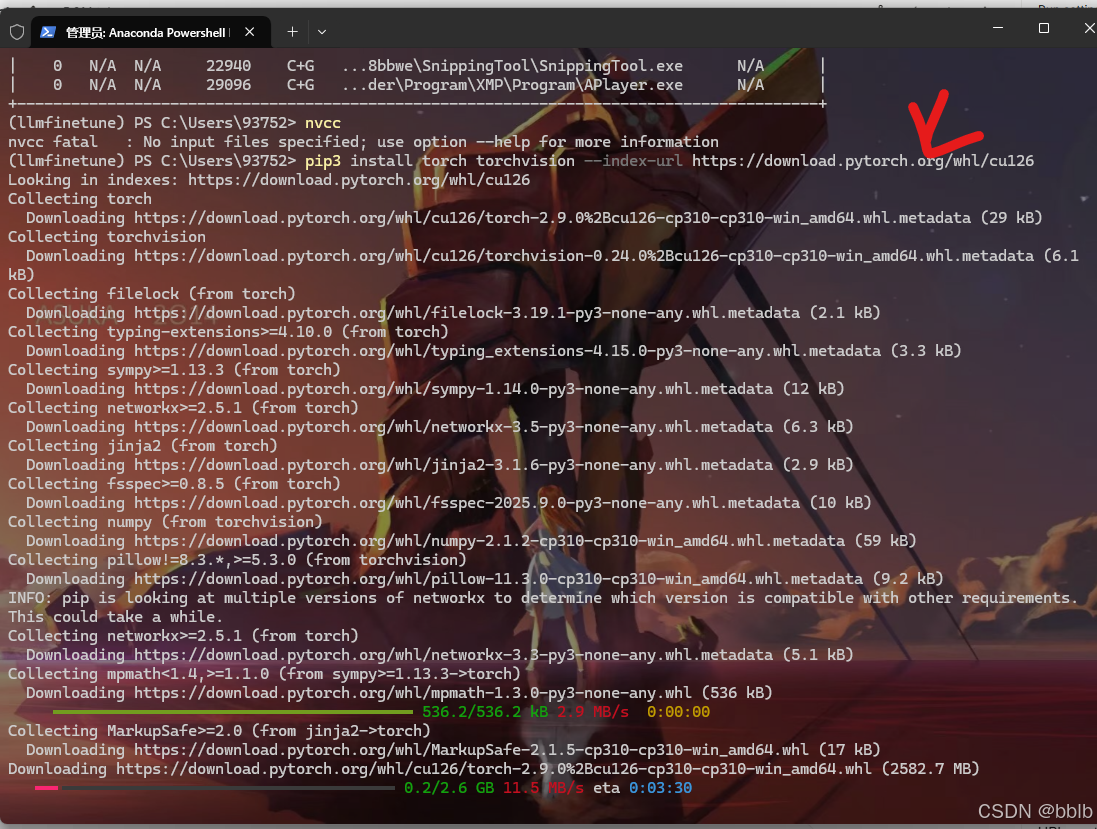
接下来依次安装剩余依赖
bash
# 必须
pip install transformers==4.50.0 datasets==3.2.0 accelerate==1.2.1 peft==0.15.0 trl==0.9.6
# 非必须
pip install deepspeed==0.16.4 bitsandbytes==0.43.1 vllm==0.7.3 flash-attn==2.7.2检验是否成功
bash
python
import torch
torch.cuda.is_available()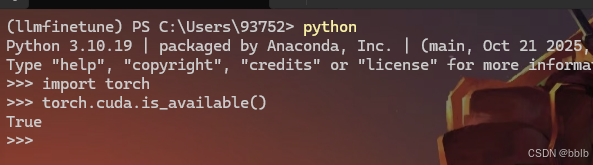
弹出True说明没问题。
1.3 安装llama-Factory
bash
# 1. 切换到父目录
cd F:\Code\Java\JavaCode\AI
# 2. 克隆仓库
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
# 3. 安装对应依赖
pip install -e ".[torch,metrics]"
安装完成后,您可以通过运行以下命令来检查LLaMA-Factory是否正确安装以及其版本号:
bash
llamafactory-cli version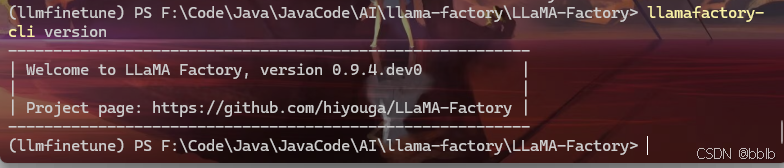
1.3.1 参数配置
LLaMA-Factory 支持多种加速技术,包括:FlashAttention 、 Unsloth 、 Liger Kernel 。
1.3.1.1 FlashAttention
FlashAttention 能够加快注意力机制的运算速度,同时减少对内存的使用。
如果您想使用 FlashAttention,请在启动训练时在训练配置文件中添加以下参数:
bash
flash_attn: fa21.3.1.2 Unsloth
Unsloth 框架支持 Llama, Mistral, Phi-3, Gemma, Yi, DeepSeek, Qwen等大语言模型并且支持 4-bit 和 16-bit 的 QLoRA/LoRA 微调,该框架在提高运算速度的同时还减少了显存占用。
如果您想使用 Unsloth, 请在启动训练时在训练配置文件中添加以下参数:
bash
use_unsloth: True1.3.1.3 Liger Kernel
Liger Kernel 是一个大语言模型训练的性能优化框架, 可有效地提高吞吐量并减少内存占用。
如果您想使用 Liger Kernel,请在启动训练时在训练配置文件中添加以下参数:
bash
enable_liger_kernel: True1.4 下载模型
我们之前在ollama里其实有个qwen4b的模型,但是我们只是推理,如果后续微调的话可能还是会爆显存,所以我们去下个1.5b比较小的模型来微调
https://modelscope.cn/models?name=1.5b\&page=1\&tabKey=task
我们去魔塔下一个比较小的,下载量高的
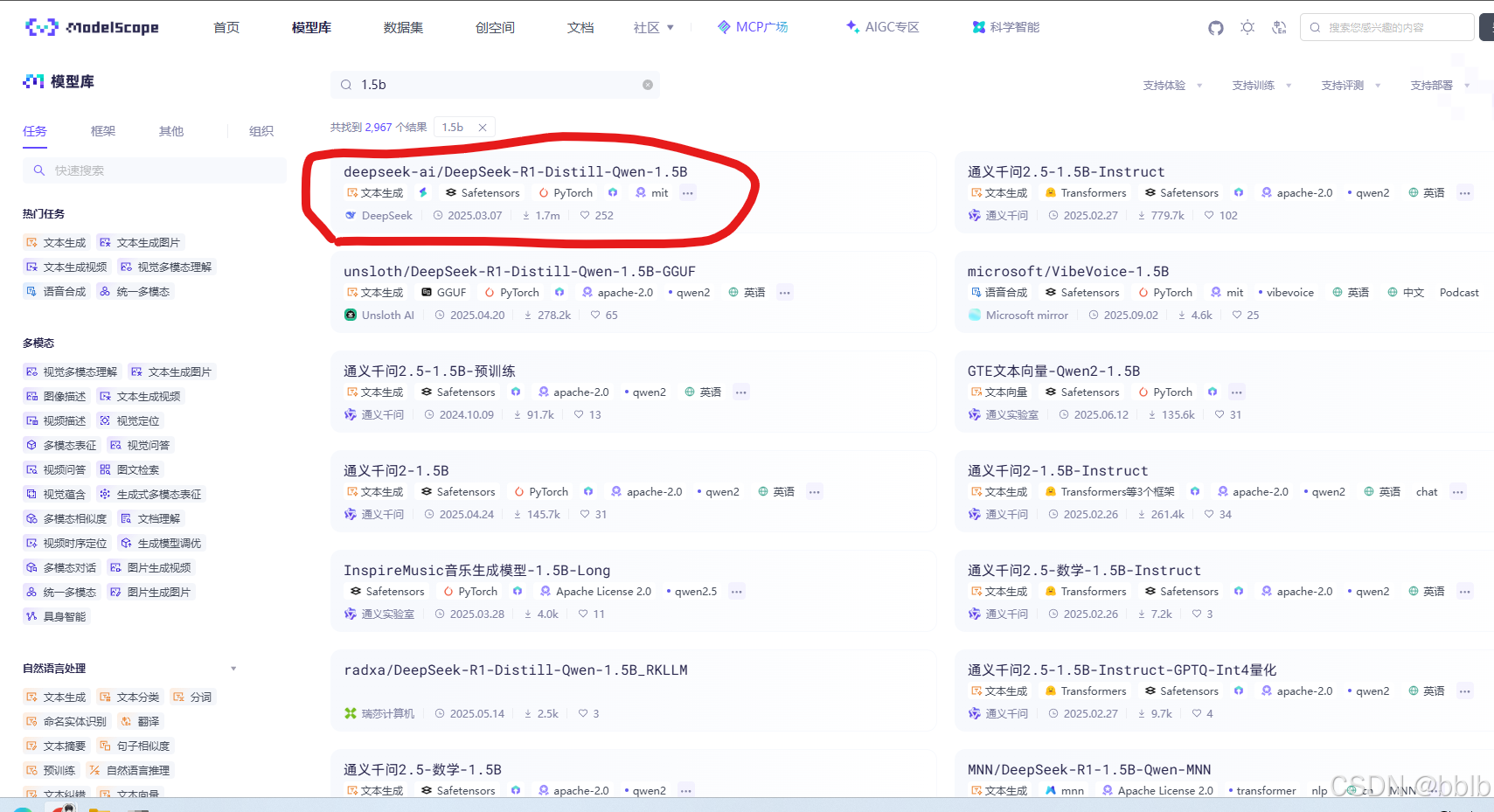
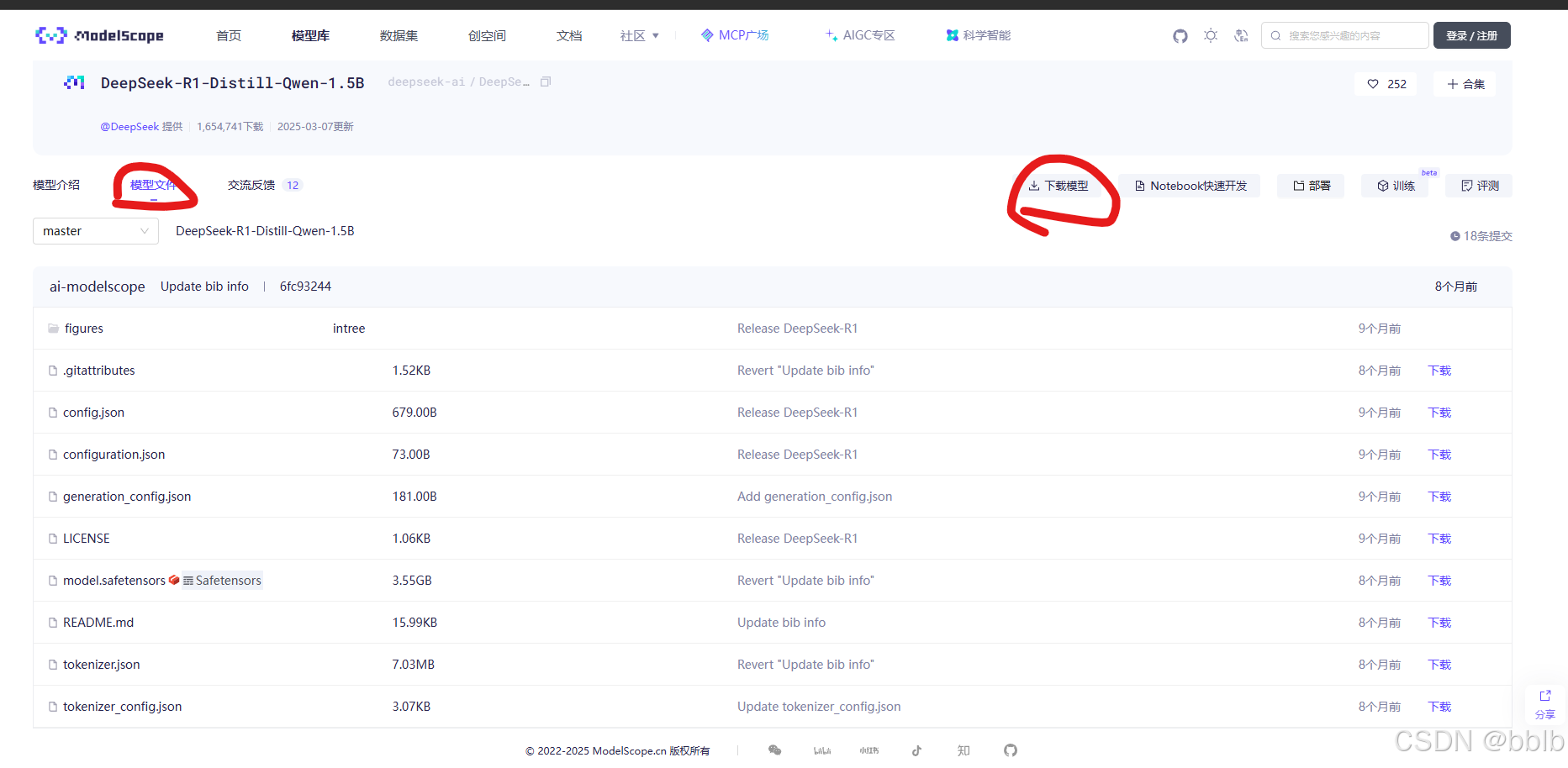
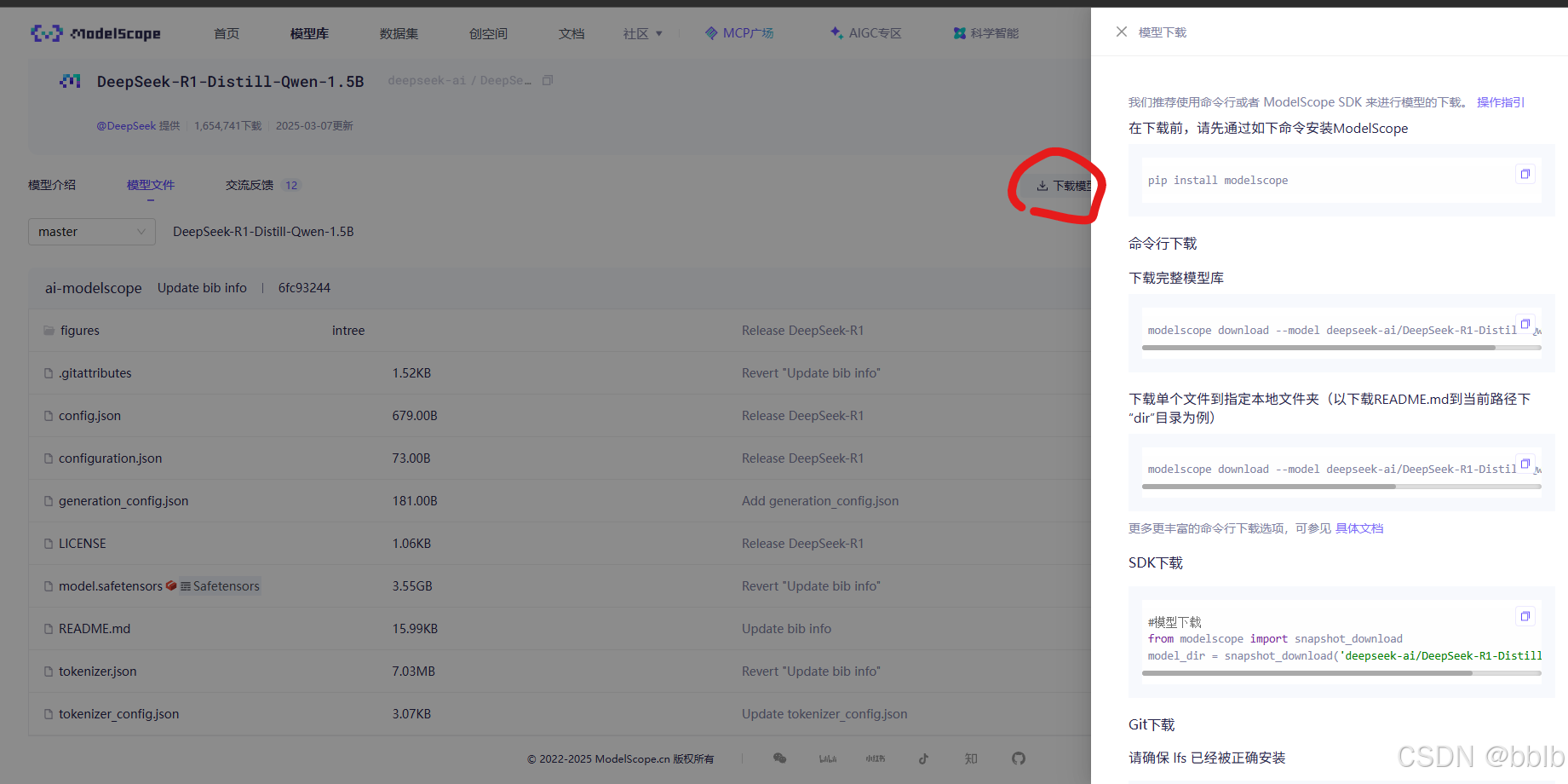
选择git下载。该模型的git下载url:git clone https://www.modelscope.cn/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B.git
启动llama-factory的webui,输入指令:
bash
llamafactory-cli webui
设置模型名称和模型路径:

切换页面到能部署模型的页面,点击chat
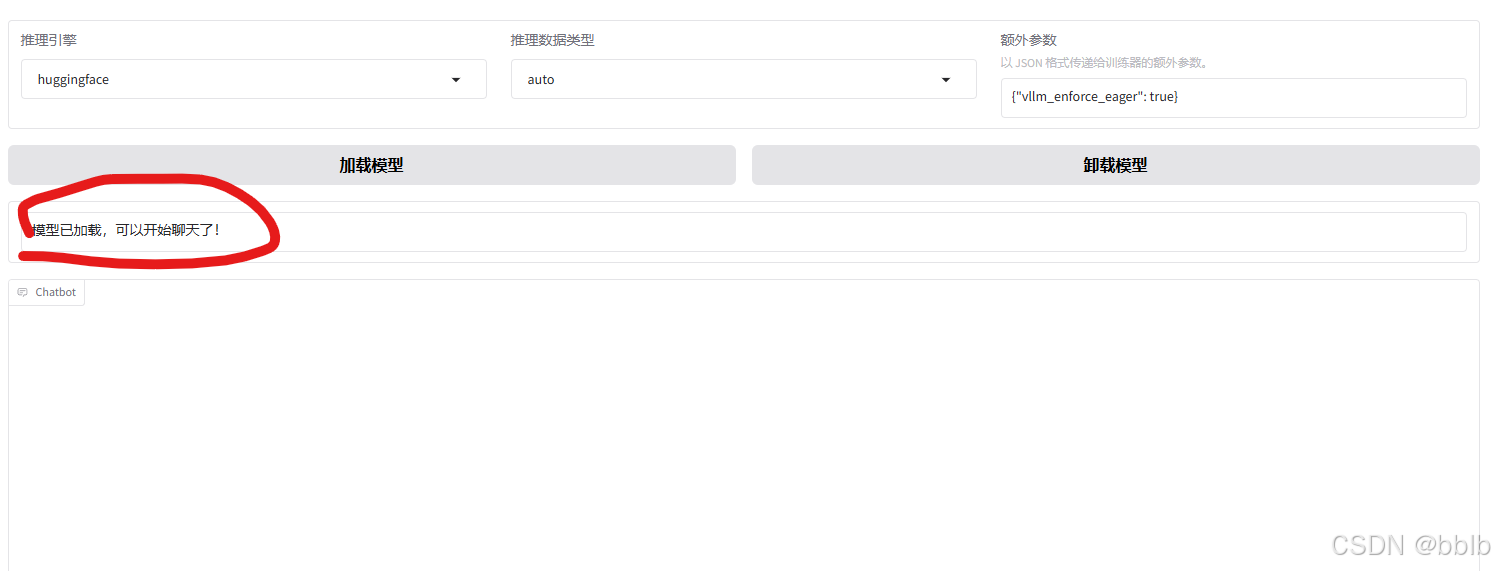
点击加载模型:
加载成功后,就可以进行聊天了。
1.5 关键参数解析
--cutoff_len 1024:截断长度
-
表示输入序列的最大长度。这个参数决定了每个输入序列的最大长度为 1024 个标记(tokens)。在自然语言处理任务中,输入序列可能会非常长,因此需要截断以确保模型可以处理。
- 重要性:设置合适的截断长度可以确保模型在计算资源有限的情况下高效运行,同时又不会丢失太多重要信息。
- 使用场景:适用于处理长文本的任务,如文本生成、问答系统等。
--flash_attn auto:Flash 注意力机制
-
flash_attn参数控制注意力机制的实现方式。设置为auto意味着系统会根据实际硬件配置和需求自动选择最优的注意力机制实现。- 重要性:可以优化计算效率和内存使用,特别是在处理大型模型和长序列时。
- 使用场景:适用于所有需要注意力机制的深度学习模型,如 Transformer 架构。
--lora_rank 8:LoRA 的秩
-
LoRA(Low-Rank Adaptation)通过引入低秩矩阵来更新模型参数,从而减少计算和存储成本。
--lora_rank 8表示使用秩为 8 的低秩矩阵来进行参数更新。- 重要性:较小的秩可以显著减少参数数量和计算量,但也可能限制模型的表达能力。
- 使用场景:适用于需要高效微调的大型预训练模型,如 GPT-3、BERT 等。
--lora_alpha 16:LoRA 的 Alpha 参数
-
LoRA 的 alpha 参数用于调整低秩矩阵对模型参数更新的影响。
--lora_alpha 16意味着将低秩矩阵的影响乘以 16,从而放大其效果。- 重要性:通过调整 alpha 值,可以控制低秩矩阵的影响,从而实现更加精细的参数调优。
- 使用场景:适用于需要对模型参数进行精细控制的场景,以平衡模型性能和过拟合风险。
--lora_dropout 0:LoRA 的 Dropout 比例
--lora_dropout 0 表示在 LoRA 的训练过程中不使用 dropout。Dropout 是一种正则化技术,用于防止模型过拟合。
- 重要性:在某些情况下,不使用 dropout 可以提高模型的训练稳定性和性能。
- 使用场景:适用于数据量大、过拟合风险较低的场景。
--lora_target all:LoRA 的目标模块
-
--lora_target all表示将 LoRA 应用于模型的所有参数。这种设置确保了 LoRA 的低秩适配器能够全面调整模型的参数,从而实现整体优化。- 重要性:全面应用 LoRA 可以最大程度地提高模型的适应能力和性能。
- 使用场景:适用于对模型整体进行微调的任务,如大规模预训练模型的全面优化。
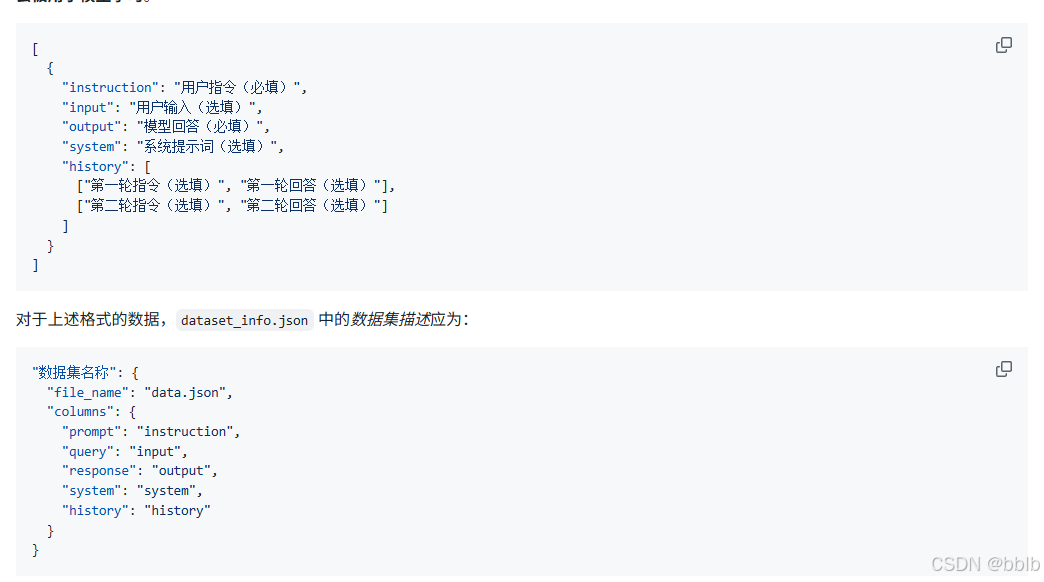
1.6 准备微调数据集
格式参考https://github.com/hiyouga/LLaMA-Factory/blob/main/data/README_zh.md
目前我们支持 alpaca 格式和 sharegpt 格式的数据集。允许的文件类型包括 json、jsonl、csv、parquet 和 arrow。
感谢大佬的帮助
1.6.1 自己准备数据集处理
1.6.1.1 数据集处理
java
@SpringBootTest
public class FineTuningData {
@Test
public void generateData(@Autowired ChatClient.Builder chatClientBuilder,
@Value("classpath:rag/02chunk.txt") Resource resource) throws IOException {
ChatClient chatClient = chatClientBuilder
.defaultSystem("""
你是一个数据处理专家,需要根据语义分隔成不同的问答片段,转换为Alpaca格式作为fine-turning使用:
格式:
[
{
"instruction": "[片段内容指令问题]",
"input": "[片段内容的简短问题]",
"output": "[片段内容的回复]",
},
]
只返回纯净的JSON数组,不要包含任何额外的解释性文字。
""")
.build();
String text = new TextReader(resource).get().get(0).getText();
String finalJson = chatClient.prompt().user(text)
.stream()
.chatResponse()
.map(chatResponse -> {
if (chatResponse.getResult() != null && chatResponse.getResult().getOutput() != null) {
return chatResponse.getResult().getOutput().getText();
}
return null;
})
.filter(Objects::nonNull)
.collect(Collectors.joining())
.block();
if (finalJson != null && !finalJson.isBlank()) {
ObjectMapper objectMapper = new ObjectMapper();
List<JsonData> list = objectMapper.readValue(finalJson, new TypeReference<>() {});
objectMapper.writerWithDefaultPrettyPrinter().writeValue(new File("demo.json"), list);
}
}
}生成最后的格式
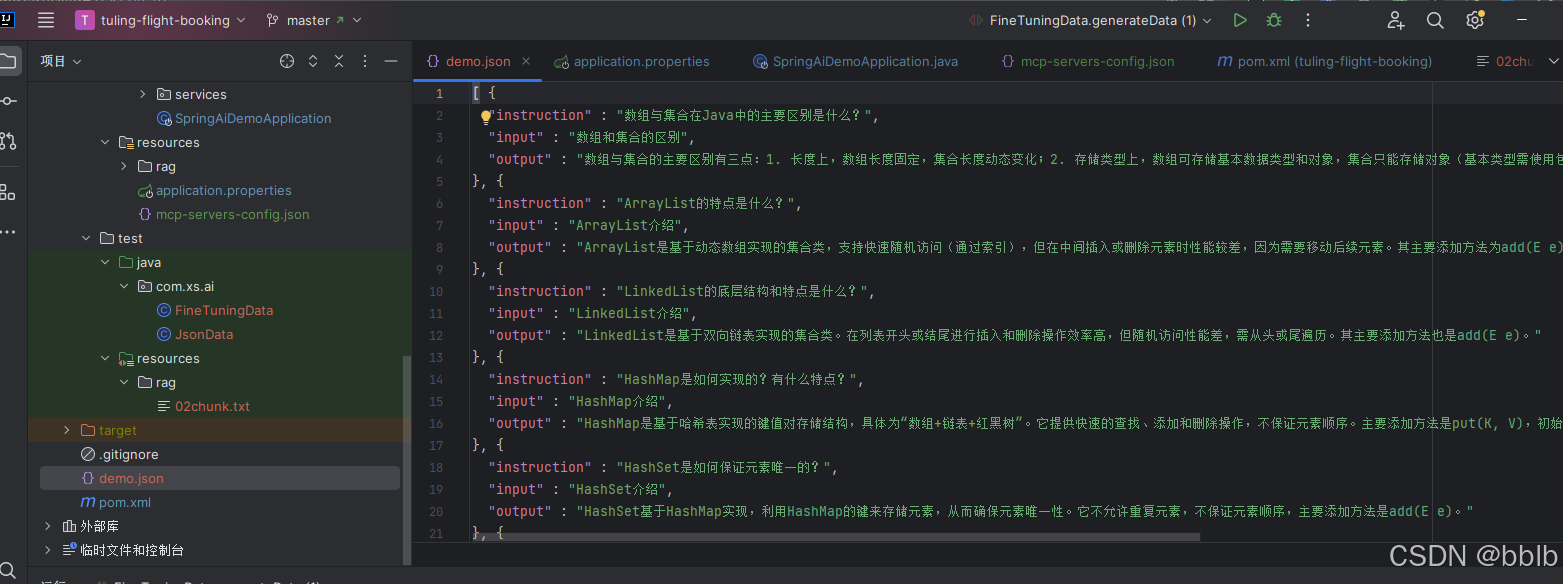
将demo.json复制到LLaMA-Factory\data\文件夹
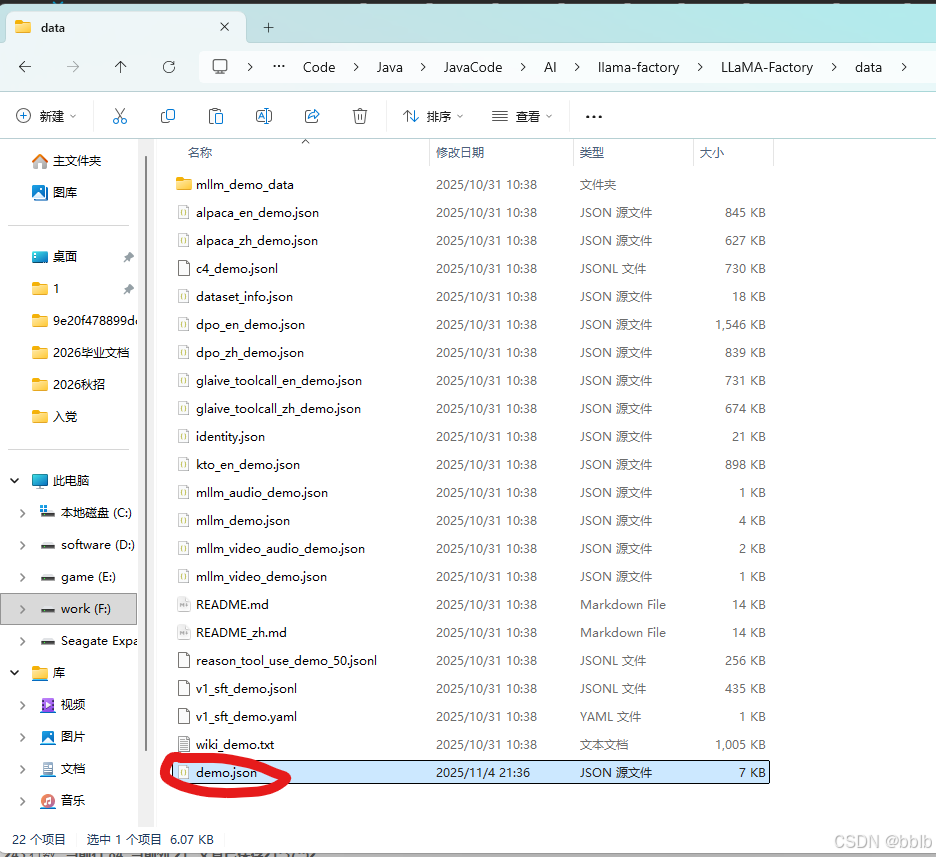
1.6.1.2 配置参数
配置训练参数
找到llama-factory中的训练参数集的配置文件
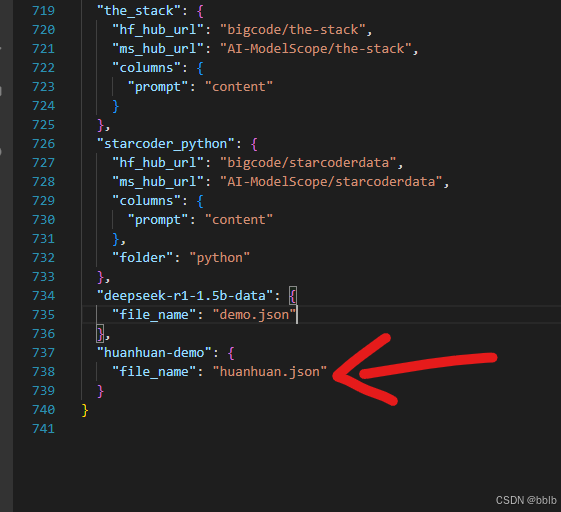
data文件夹中的dataset_info文件。打开文件并配置。
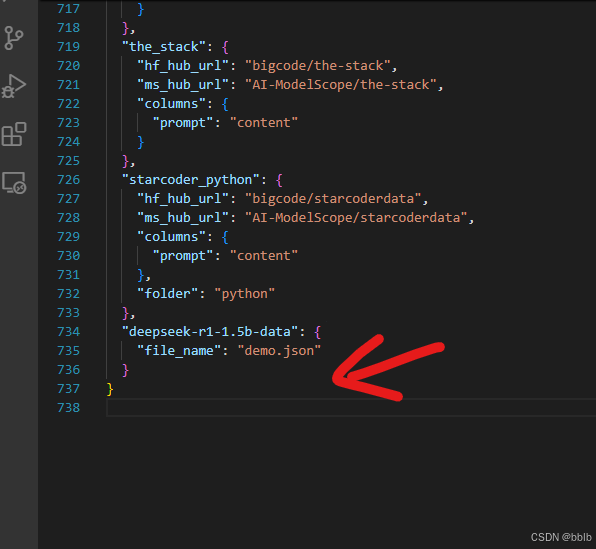
我们在json字符串中再加入一组
bash
"deepseek-r1-1.5b-data": {
"file_name": "demo.json"
}
1.6.2 使用准备好的数据集
可以使用魔塔已经准备好的数据集
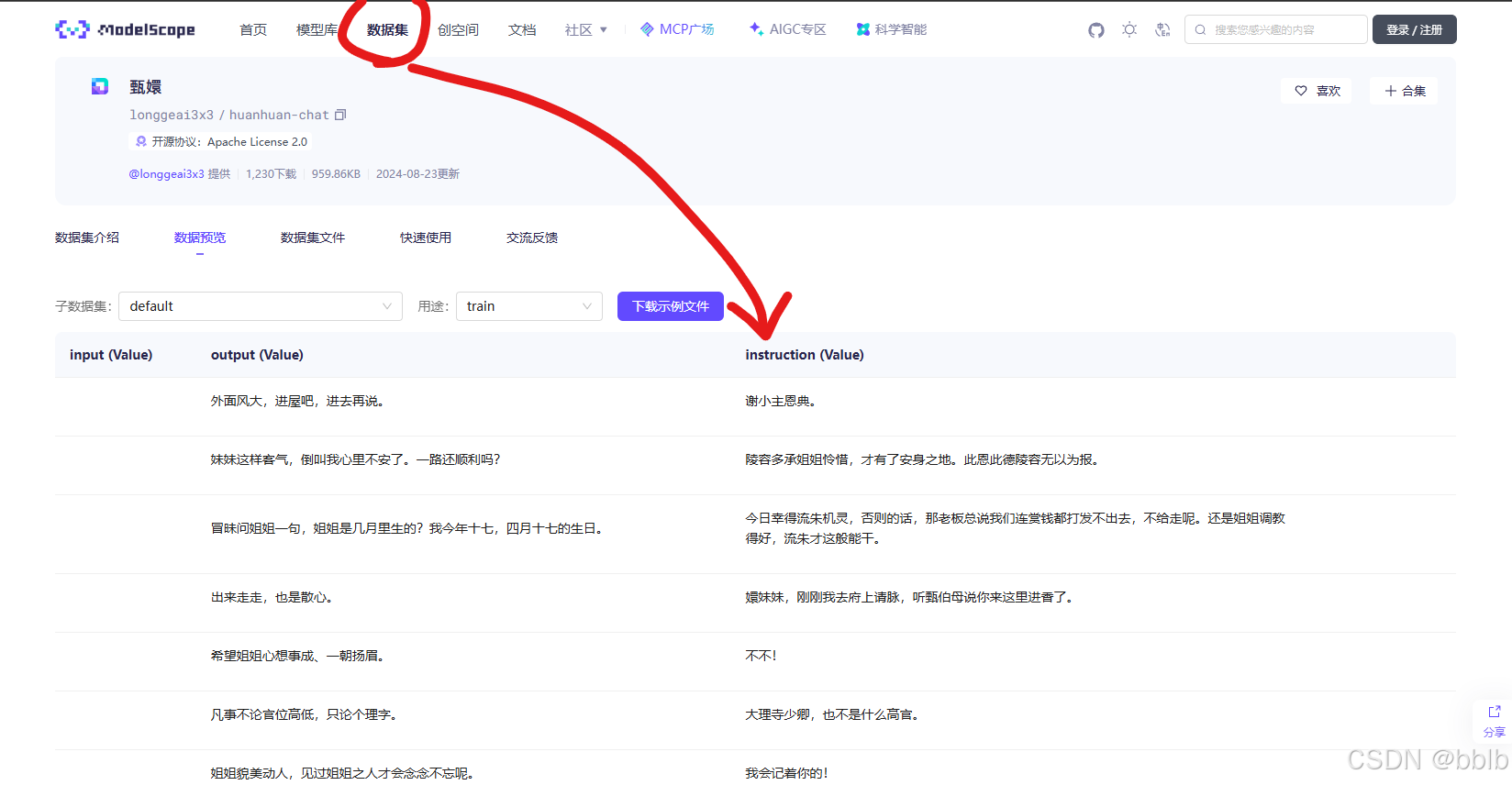
下载数据集
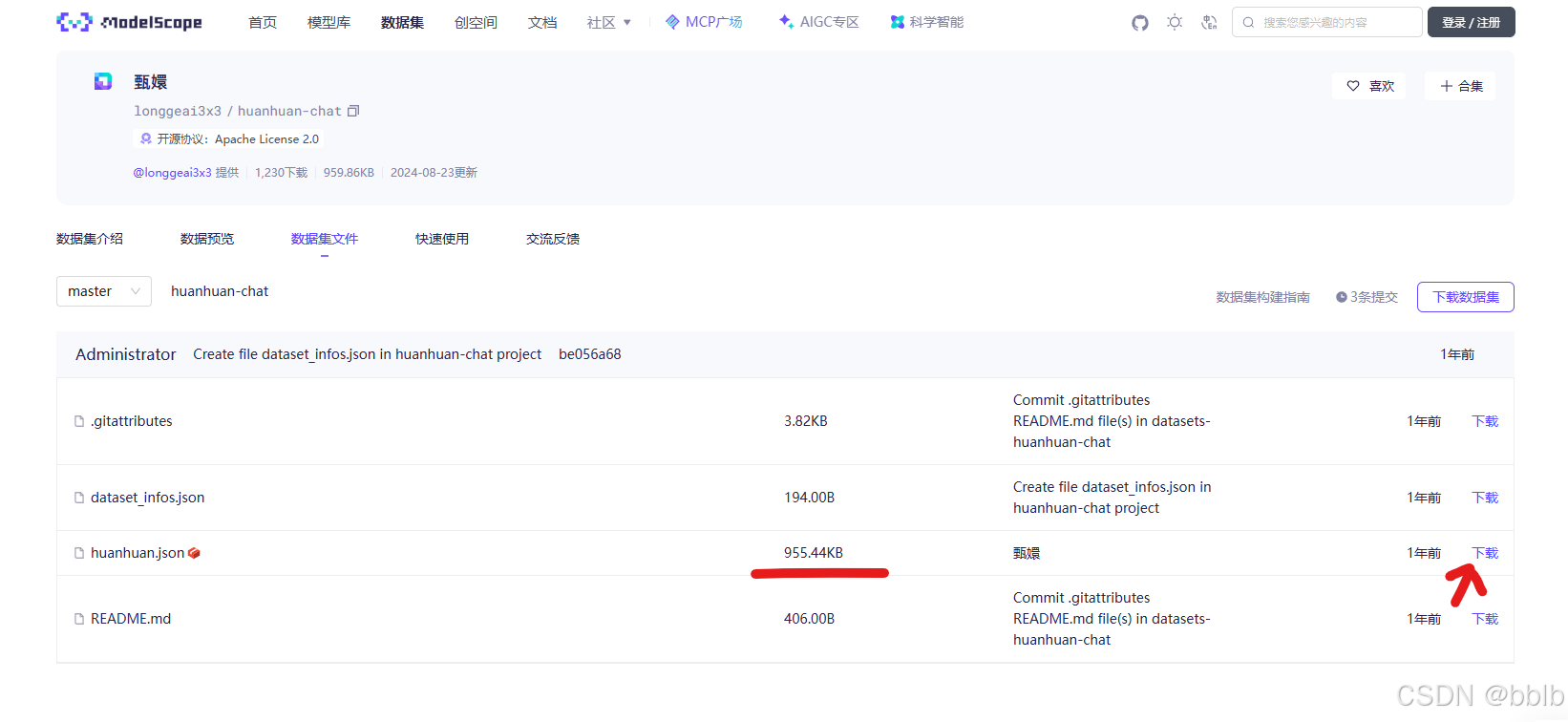
下载好后也放到LLaMA-Factory\data\文件夹
也同样要配置到dataset_info中
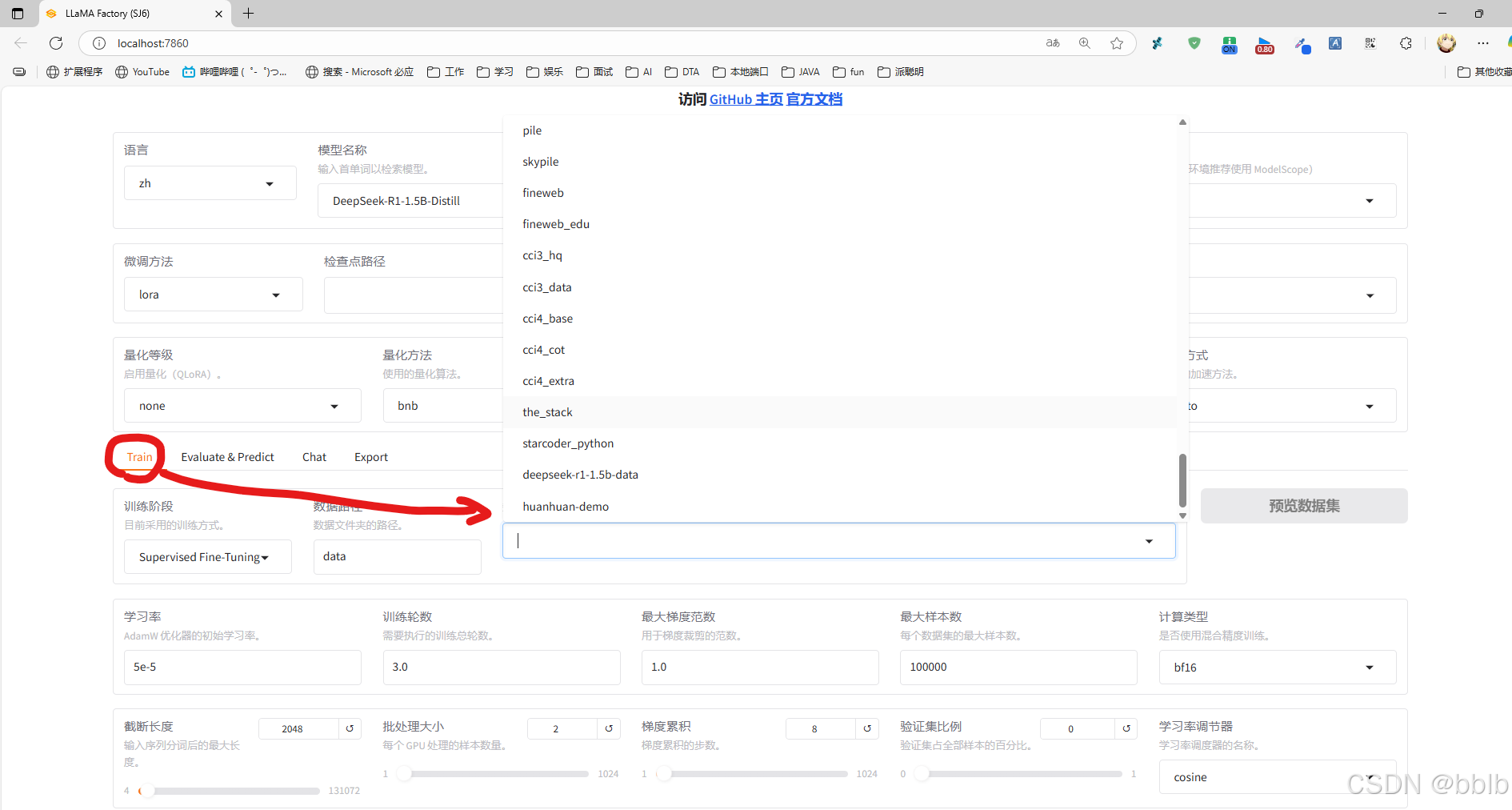
1.7 开始训练
进入webui,点击train,选择我们的数据集
准备好后就可以开始训练了
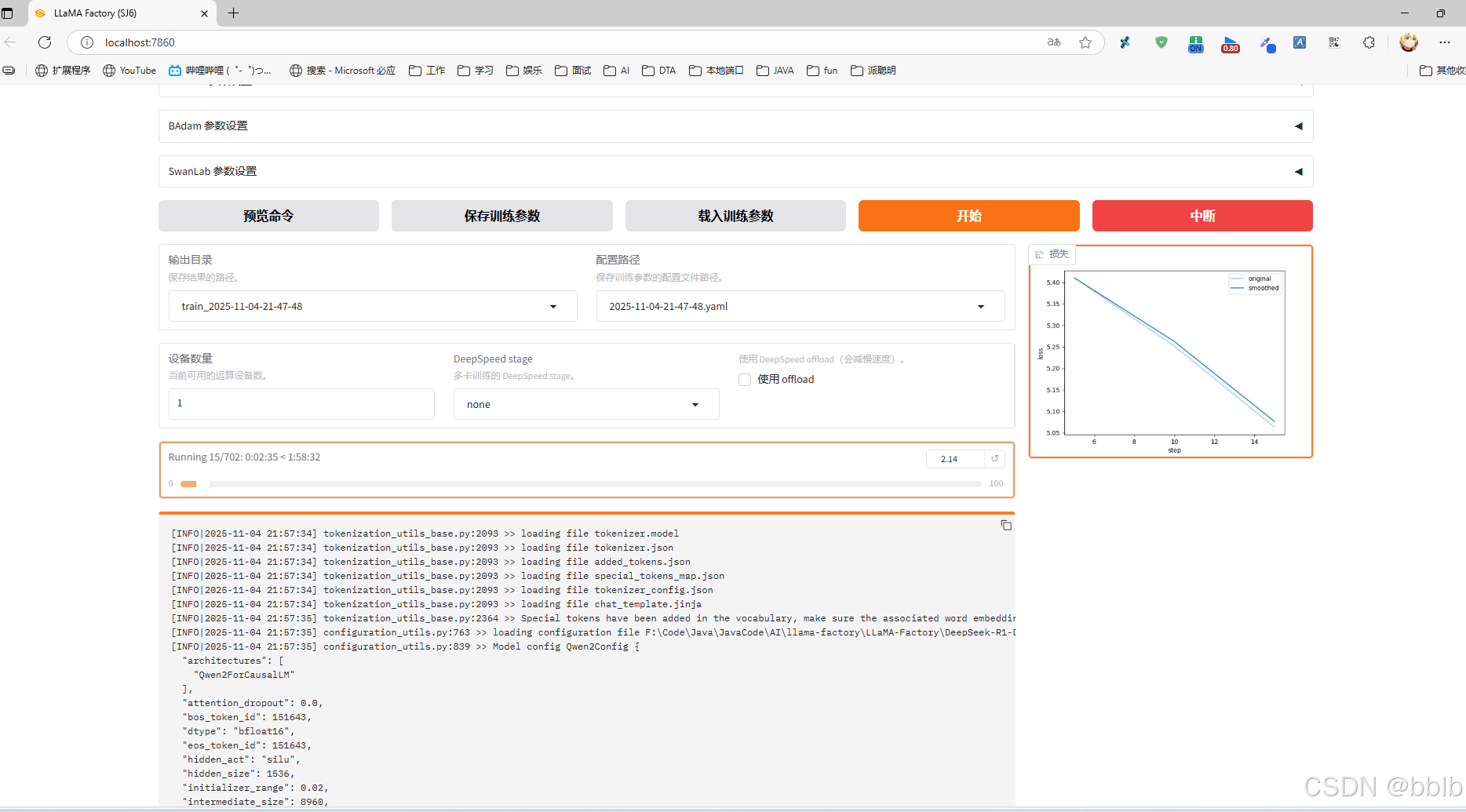
看到log上面出现训练完毕,表示训练结束了。
训练验证:
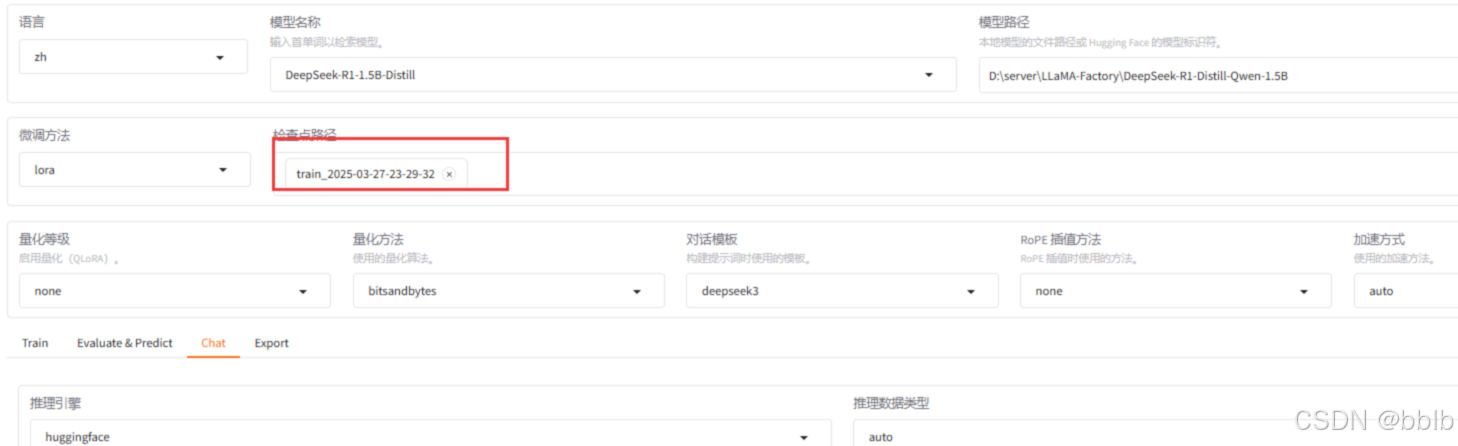 卸载重新加载模型:
卸载重新加载模型:
测试你的数据集中的提问:
注意,由于我的文本比较少, 所以如果文本少可以多训练几轮,否则可能没效果
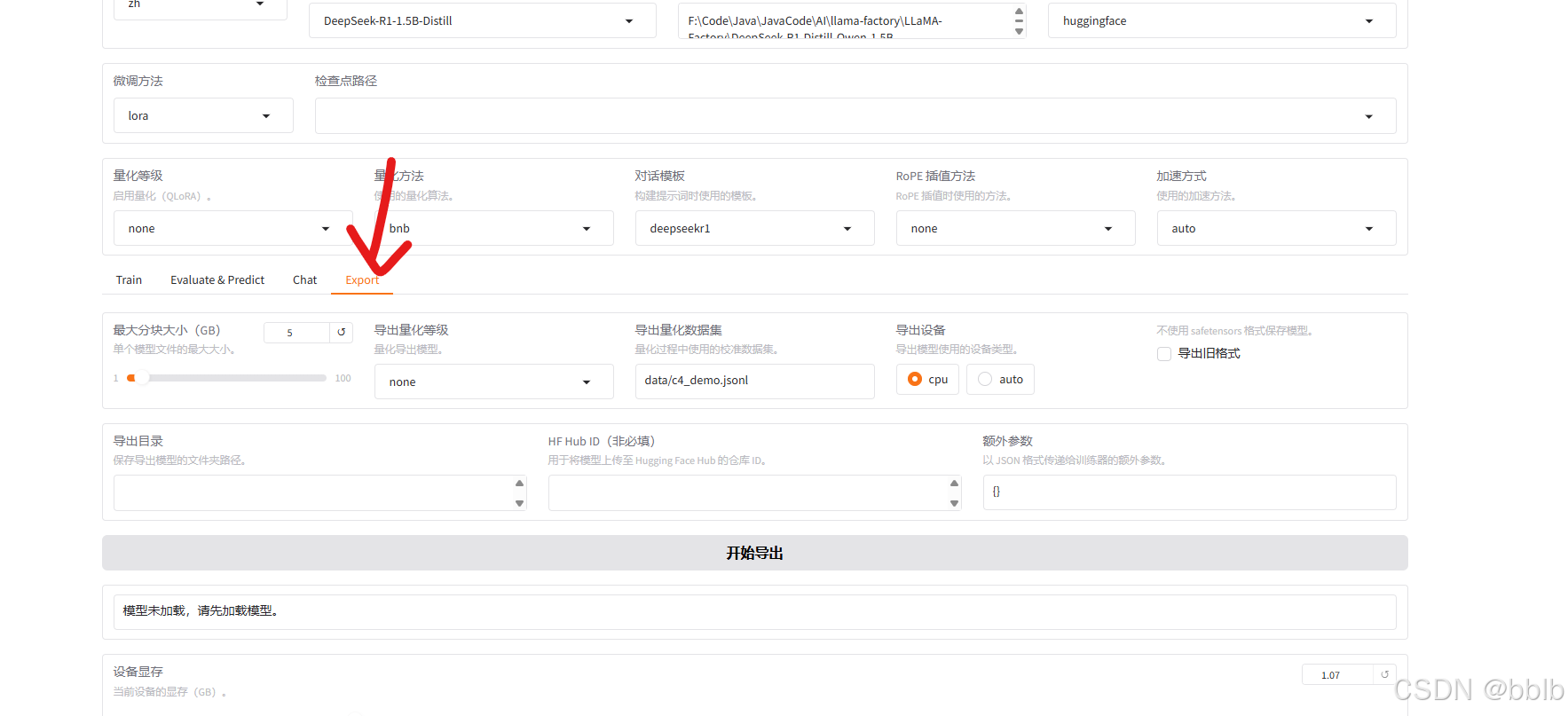
1.8 导出模型
导出, 设置导出目录
通过ollama导入
bash
cd 到你导出的目录
ollama create demo_deepseekr1_1_5b -f Modelfile
通过ollama list就能查看到导入的模型
当然也可以通过ollama进行加载和调用了,和之前的springai或者langchain4j的调用方法类似。