一.人工智能概述
1.人工智能的定义
定义: 让机器模拟、延伸和扩展人类智能的理论、方法、技术及应用系统的一门技术科学。简单说,就是让机器像人一样思考、学习、推理、决策和解决问题。
目标: 创建能够执行通常需要人类智能才能完成的任务的系统。
范围: 非常广泛,包含机器学习、深度学习、计算机视觉、自然语言处理、机器人学、专家系统、规划、推理、知识表示等众多子领域。
类比: 就像"智能"本身是一个宽泛的概念一样。
**人工智能(AI)**指通过计算机系统模拟人类智能行为的科学与工程。其目标是使机器具备以下能力:
感知(如视觉、语音识别)
推理(逻辑分析、决策)
学习(从数据中自我优化)
解决问题(处理复杂任务)
交互(自然语言对话、协作)
2.人工智能的发展历程
| 时期 | 里程碑事件 |
|---|---|
| 1950s | 图灵提出"图灵测试",达特茅斯会议确立AI概念 |
| 1980s | 专家系统兴起(用规则模拟人类知识) |
| 1990s | 机器学习成为主流(数据驱动取代规则编程) |
| 2010s至今 | 深度学习爆发(算力+大数据推动AI革命) |
3.AI的典型应用场景
| 领域 | 应用案例 |
|---|---|
| 医疗 | 医学影像分析、药物研发辅助 |
| 金融 | 欺诈检测、量化交易、风险评估 |
| 交通 | 自动驾驶、智能交通调度 |
| 消费电子 | 语音助手(Siri/Alexa)、推荐系统 |
| 工业 | 预测性设备维护、智能制造 |
| 内容创作 | AI绘画(Midjourney)、文本生成(GPT) |
二.人工智能技术的主要分支
1. 机器学习(ML)
定义:让计算机通过数据自动学习规律,无需显式编程。
类型:
-
监督学习(带标签数据,如分类/回归)
-
无监督学习(无标签数据,如聚类)
-
强化学习(环境反馈优化决策,如AlphaGo)
2. 深度学习(DL)
本质:基于多层神经网络的机器学习。
突破领域:
-
计算机视觉(图像识别、人脸检测)
-
自然语言处理(机器翻译、ChatGPT)
3. 其他关键技术
知识图谱:结构化表示现实世界关系(如谷歌搜索)
机器人技术:物理世界感知与行动(如工业机器人)
计算机视觉:让机器"看懂"图像/视频
机器学习是人工智能的一个实现途径,深度学习是人工智能的一个方法发展而来
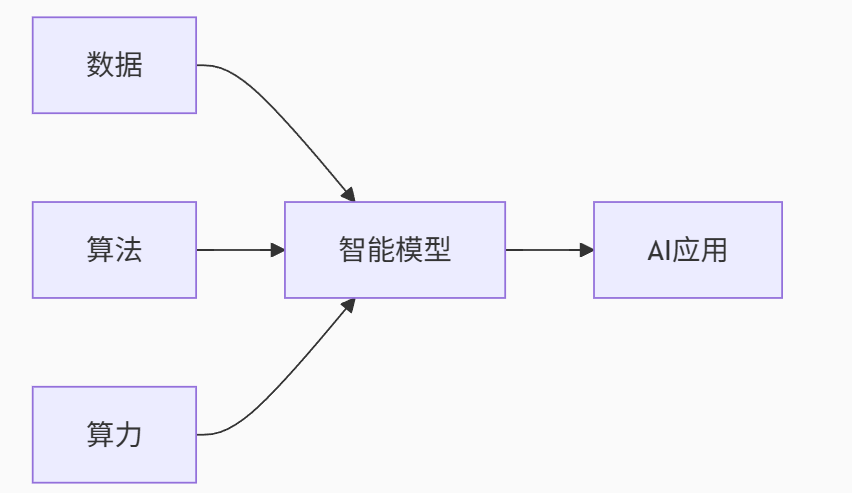
三.人工智能发展的必备三要素
1. 数据(Data)------ AI的"燃料"
核心作用:
- 训练模型的基础原料,决定AI的认知边界
- 数据质量直接影响模型性能(Garbage in, garbage out)
关键要求:
- 规模性:深度学习需海量数据(如GPT-3训练数据达45TB)
- 多样性:覆盖多场景避免模型偏见(如医疗AI需包含不同人种病例)
- 标注质量:监督学习依赖精准标注(ImageNet数据集含1400万人工标注图)
数据集的介绍:
一行的数据我们称为一个样本,一列数据我们称为一个特征。
常见的数据类型的构成有:
- 特征值+目标值
- 只有特征值,没有目标值
数据划分:
- 训练数据(训练集)-- 构建模型
- 测试数据(测试集)-- 测试模型
2. 算法(Algorithms)------ AI的"大脑"
核心作用:
- 将数据转化为智能决策的数学逻辑
- 决定AI的学习效率和能力上限
演进关键:
- 传统ML算法:SVM、决策树(解决结构化数据问题)
- 深度学习革命 :
- CNN(2012年AlexNet引爆图像识别)
- Transformer(2017年推动NLP跨越发展,支撑ChatGPT)
- 强化学习:AlphaGo自我博弈突破人类棋艺
3. 算力(Computing Power)------ AI的"发动机"
核心作用:
-
支撑复杂模型训练与实时推理
-
算力成本决定AI应用可行性
技术演进:
| 时代 | 算力载体 | 算力提升关键 |
|---|---|---|
| 2010年前 | CPU | 摩尔定律 |
| 2012-2018 | GPU(NVIDIA) | 并行计算架构 |
| 2019至今 | TPU/ASIC芯片 | 专用硬件设计 |
现状需求:
-
大模型训练需超算级集群(GPT-3训练耗电≈120个家庭年用电量)
-
边缘计算推动终端芯片革新(自动驾驶芯片算力达1000+TOPS)
四.机器学习工作流程
机器学习是从数据中自动分析获得模型,并利用模型对未知数据进行预测。

1.数据基本处理
主要包括问题定义,数据收集,数据预处理等。
(1).问题定义(Problem Formulation)
核心任务:将业务需求转化为机器学习可解决的问题
关键步骤:
-
明确目标(如预测用户流失、识别欺诈交易)
-
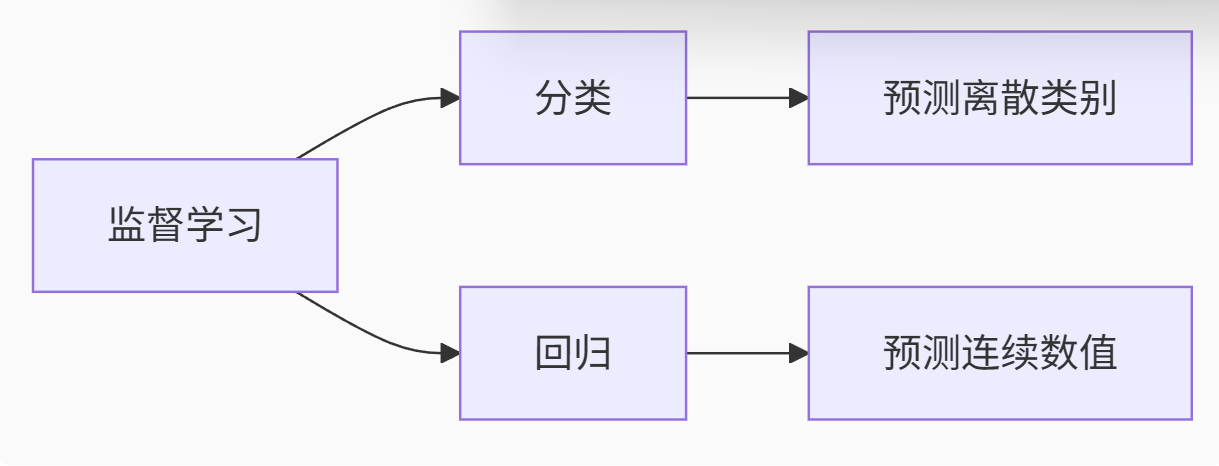
确定问题类型:
-
分类(Classification)→ 离散结果(是/否)
-
回归(Regression)→ 连续数值(房价、销量)
-
聚类(Clustering)→ 无标签分组
-
-
定义评估指标:
-
分类:准确率、精确率、召回率、F1-score、AUC-ROC
-
回归:MAE(平均绝对误差)、RMSE(均方根误差)、R²
-
(2).数据收集(Data Collection)
数据来源:
-
结构化数据:数据库(MySQL)、数据仓库(Hive)
-
非结构化数据:日志文件、图像、文本、传感器流
关键原则:
-
覆盖场景:包含正负样本(如欺诈交易与非欺诈交易)
-
时间连贯性:训练/测试数据需按时间划分(避免未来数据泄漏)
(3).数据预处理(Data Preprocessing)
占整个项目60%以上时间,核心目标是构建干净、一致的数据集
| 任务 | 方法 | 说明 |
|---|---|---|
| 缺失值处理 | 删除样本/列、均值填充、插值法、预测模型填充 | 金融数据常用多重插补(MICE) |
| 异常值处理 | IQR法、Z-Score、孤立森林 | 谨慎删除(可能包含重要模式) |
| 数据标准化 | Min-Max缩放、Z-Score标准化 | 加速梯度下降收敛 |
| 类别编码 | One-Hot编码、标签编码(Label Encoding) | 树模型可直处理类别特征 |
| 不平衡数据处理 | SMOTE过采样、欠采样、类别权重调整 | 医疗诊断需保留少数类样本完整性 |
2.特征工程
目标 :从原始数据中提炼对预测有用的信息,使用专业背景知识和技巧处理数据,使得特征能在机器学习算法上发挥更好的作用的过程。
关键技术:
-
特征构造:
-
时间序列:生成"星期几"、"是否节假日"
-
文本数据:TF-IDF、词向量(Word2Vec)
-
-
特征选择:
-
过滤法:相关系数、卡方检验
-
包裹法:递归特征消除(RFE)
-
嵌入法:L1正则化(Lasso)、树模型特征重要性
-
-
维度约简:
- PCA(主成分分析)、t-SNE(高维可视化)
黄金法则:一个优秀的特征比复杂的模型更有效
3.机器学习(算法的分类)
(1).监督学习
**定义:**输入数据是由特征值和目标值组成的
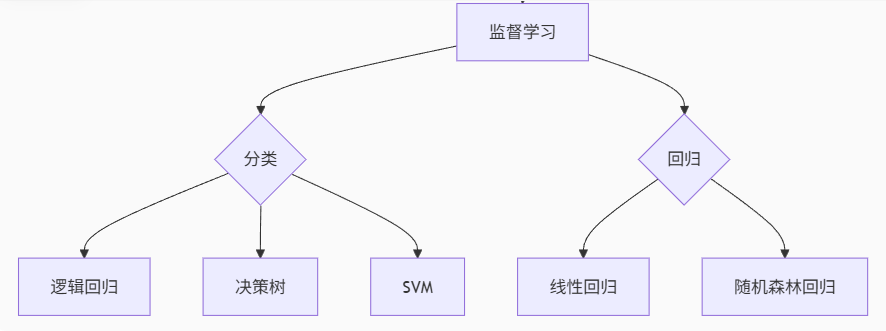
| 任务类型 | 代表算法 | 特点说明 | 典型应用场景 |
|---|---|---|---|
| 分类 | 逻辑回归 | 线性决策边界,可解释性强 | 垃圾邮件检测 |
| 决策树 | 可处理类别特征,易过拟合 | 贷款审批 | |
| 随机森林 | 集成多树,抗过拟合 | 医疗诊断 | |
| SVM | 高维空间找最优超平面 | 图像分类 | |
| 朴素贝叶斯 | 基于概率,文本处理高效 | 情感分析 | |
| 回归 | 线性回归 | 拟合线性关系 | 房价预测 |
| 多项式回归 | 捕获非线性趋势 | 商品销量预测 | |
| 梯度提升树(GBRT) | 迭代优化,预测精度高 | 广告点击率预估 |
(2).无监督学习
**定义:**输入的数据由输入的特征值组成
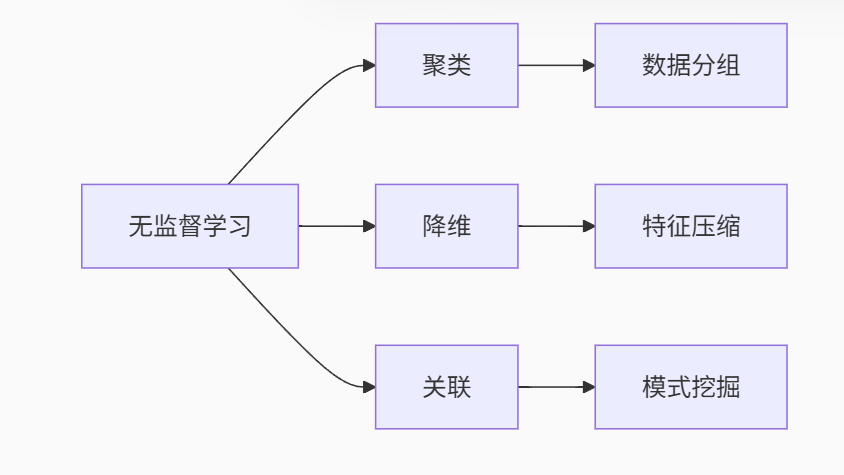
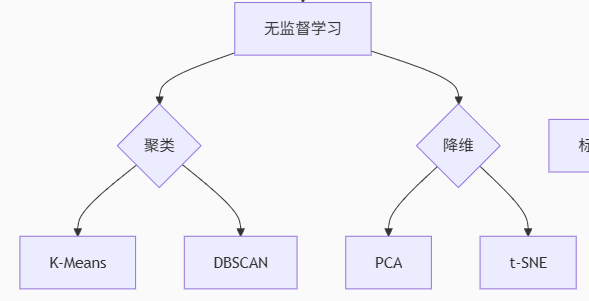
| 任务类型 | 代表算法 | 特点说明 | 典型应用场景 |
|---|---|---|---|
| 聚类 | K-Means | 球形簇,需指定K值 | 客户分群 |
| DBSCAN | 发现任意形状簇,抗噪声 | 异常检测 | |
| 层次聚类 | 树状结构,无需预设簇数 | 生物物种分类 | |
| 降维 | PCA | 线性投影保留最大方差 | 人脸识别预处理 |
| t-SNE | 非线性保留局部结构 | 高维数据可视化 | |
| 关联 | Apriori | 发现频繁项集 | 购物篮分析 |
(3).半监督学习
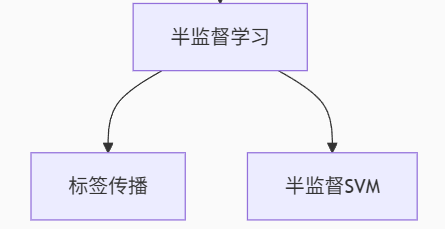
特点 :少量标签+大量无标签 数据协同训练
典型算法:
-
标签传播:基于图结构扩散标签(社交网络分析)
-
半监督SVM:利用无标签数据调整决策边界(医学影像分类)
-
自训练:用模型预测结果扩充训练集(低成本文本分类)
优势:
降低90%+标注成本,在医疗影像、语音识别等领域应用广泛
| 算法类型 | 原理说明 | 优势场景 |
|---|---|---|
| 标签传播 | 基于图结构扩散少量标签 | 社交网络用户分类 |
| 半监督SVM | 用未标注数据调整决策边界 | 医学影像标注不足时 |
| 自训练 | 用模型预测结果扩充训练集 | 文本分类低成本场景 |
(4). 强化学习(Reinforcement Learning)
实质是,make decisions问题,即自行进行决策,并且可以做连续决策
特点 :智能体通过环境反馈 学习最优策略
经典算法演进:

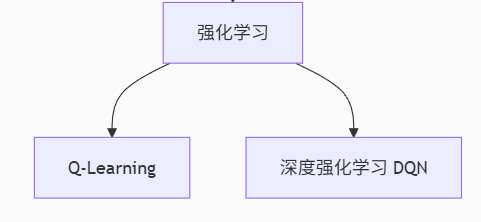
| 算法类型 | 关键机制 | 突破性应用 |
|---|---|---|
| Q-Learning | 学习状态-动作价值函数 | 机器人路径规划 |
| DQN | 神经网络逼近Q值函数 | Atari游戏通关 |
| 策略梯度(PG) | 直接优化策略函数 | 连续控制(如机械臂) |
| A3C | 异步多线程加速训练 | 复杂3D环境导航 |
4.模型评估
模型评估是模型开发过程中不可缺少的一部分,它有助于发现表达数据的最佳模型和所选模型的性能如何。按照数据集的目标值不同,可以把模型评估分为分类模型评估和回归模型评估。
(1).监督学习评估指标
分类任务:
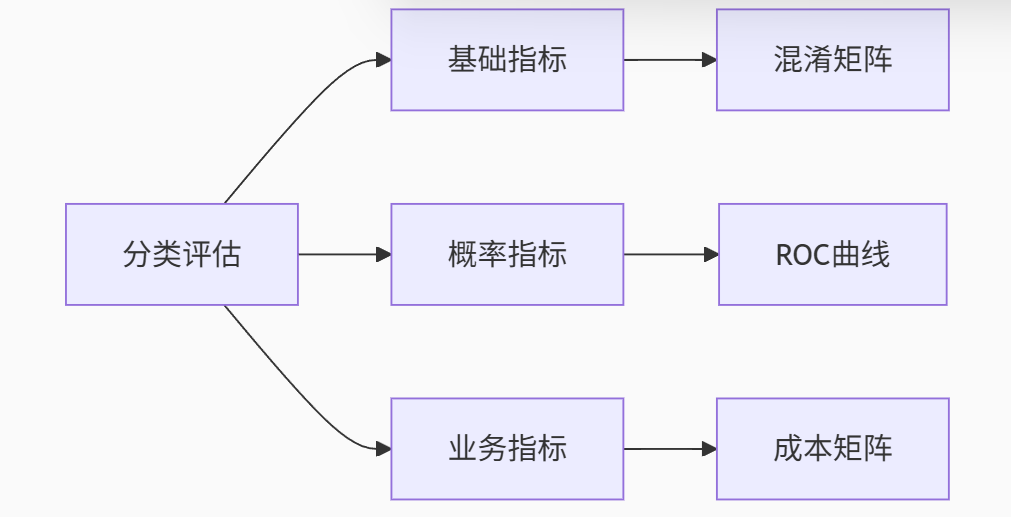
关键指标对比:
| 指标 | 公式 | 适用场景 | 缺陷 |
|---|---|---|---|
| 准确率(Accuracy) | (TP+TN)/(TP+FP+TN+FN) | 均衡数据 | 不平衡数据失效 |
| 精确率(Precision) | TP/(TP+FP) | 抑制误报(垃圾邮件过滤) | 忽略FN漏报风险 |
| 召回率(Recall) | TP/(TP+FN) | 避免漏报(癌症筛查) | 可能放大误报 |
| F1-Score | 2×Precision×Recall/(Precision+Recall) | 平衡精确率与召回率 | 无法区分业务代价差异 |
| AUC-ROC | ROC曲线下面积 | 综合评估分类器性能 | 对均衡数据不敏感 |
回归任务:
| 指标 | 公式 | 特点 |
|---|---|---|
| MAE | Σ|y_true - y_pred|/n | 直观反映平均误差 |
| MSE | Σ(y_true - y_pred)²/n | 放大大误差(惩罚离群点) |
| RMSE(均方根误差) | √MSE | 量纲与原始数据一致 |
| R² | 1 - Σ(y_true-y_pred)²/Σ(y_true-ȳ)² | 解释方差比例,越接近1越好 |
关键提示:预测房价时RMSE=5万,意味着68%预测值在真实值±5万内(正态分布假设)
(2).无监督学习评估
1. 聚类评估
| 方法类型 | 指标 | 原理 |
|---|---|---|
| 内部评估 | 轮廓系数(Silhouette) | 衡量样本与自身簇/其他簇距离 |
| 戴维斯堡丁指数(DBI) | 簇内紧密度/簇间分离度 | |
| 外部评估 | 调整兰德指数(ARI) | 对比聚类结果与真实标签 |
2. 降维评估
-
可解释方差比:PCA保留信息量(>85%达标)
-
重建误差:自编码器重建原始数据的能力