DeepSeek到底咋样?虽然网上有些媒体吹得有点过,但换个角度想想------在国内大厂一个个放弃从0到1的原创创新,转头去做"1到100"的应用生意的环境下,深度求索这样一家小公司还能咬牙坚持,硬是做出了一款媲美GPT的AI模型,还免费、还开源,这事本身就很值得夸一夸。
李白有句诗------"人生得意须尽欢"。在全球普遍觉得中国AI落后国外的大背景下,DeepSeek没花大价钱打广告,就靠实力冲上了苹果App Store的下载榜第一,这已经很能说明它有两把刷子了。
其实DeepSeek早在2023年底就发布了,我在2024年初就从GPT+KIMI转到DeepSeek,结果一用就是大半年。我的感受是:它的文字处理能力确实强,后来加了联网功能和"深度思考"模式,体验又上了一个台阶。平时问它问题,基本很少会答错,就算偶尔有小瑕疵,稍微改改提示词也能得到很满意的答案。
下面来分析一下:
一、国内外影响

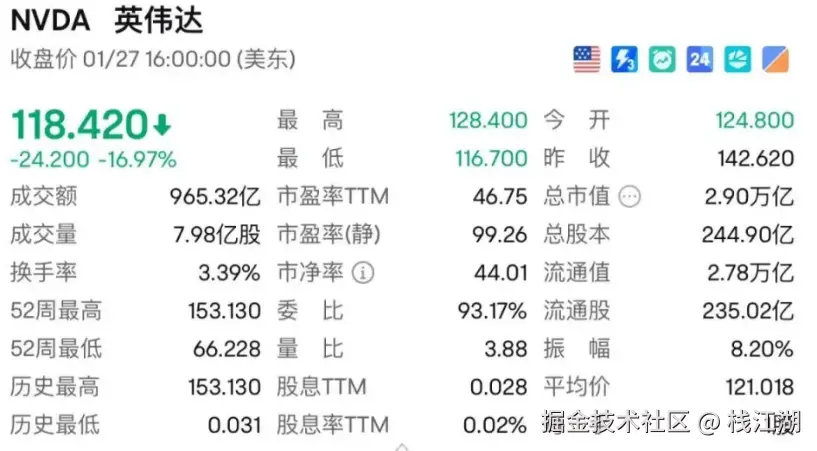
英伟达
DeepSeek-R1发布后,英伟达股价暴跌16.9%,市值在三天内蒸发了约6000亿美元 ,创下了美股单日蒸发市值的最高记录。虽然黄仁勋多次说过大家误解了DeepSeek,其实DeepSeek R1的推出是一件好事,推理模型的出现不会削弱英伟达在硬件方面的地位,反而会凸显英伟达硬件在处理复杂推理任务中的优势。但无疑DeepSeek的发布,特别是DeepSeek的相关能降低模型训练的硬件成本的能力对英伟达的影响肯定是有的。
最近看到一则新闻:"美股崩盘原因是DeepSeek"
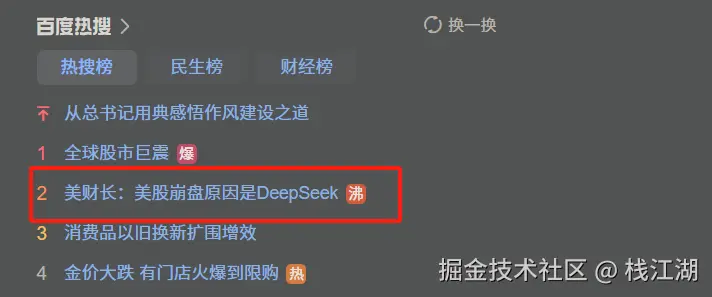
不论如何DeepSeek的确带来了一些连锁的影响,不论在中国还是国外。
OpenAI-奥特曼
DeepSeek发布后openai奥特曼在X上发布:DeepSeek-R1是一个令人印象深刻的模型,尤其是他们能够以这样的价格提供卓越性能。我们显然会推出更好的模型,同时,有一个新的竞争对手加入确实让人感到振奋!
这次AI革命的核心就是OpenAI在2022年11月发布的GPT。而前面国内发布出来的大模型并没有造成太大的影响,而此次DeepSeek的发布被视为竞争对手,同时DeepSeek来受到大量来自国外的非正常请求。这些无疑也表现出DeepSeek所带来的影响和它的地位。

2025年初AI局最热门的话题就是DeepSeek了,受DeepSeek的影响,奥特曼在2月13日宣布了GPT-5的免费访问计划。

百度文心一言-李彦宏
2025年年初国内AI局最热闹的事就是,在国内DeepSeek火爆后,国内360、百度、阿里、腾讯等大厂纷纷接入DeepSeek满血版。当然在国内除了各大厂接入DeepSeek满血版外,还有一个受DeepSeek影响最大的就是百度旗下的文心一言于2025年2月13日 宣布,将从2025年4月1日零时起全面免费。
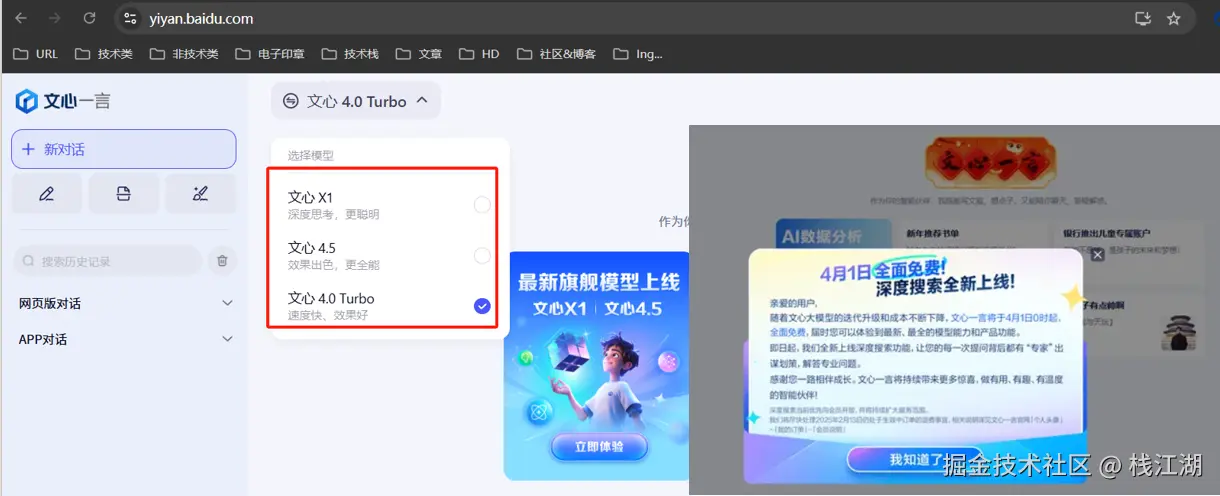
百度文心一言在国内有首发优势,但一直以来百度文心一言也是被骂的最狠的。当然主要原因之一就是我们使用的是免费版本而他们主要经历都是放在付费的版本上,所以相比其它的免费AI产品文心一言3.5的确就非常的差。此次受DeepSeek免费及开源的影响百度也把付费版全面开放。
黑神话悟空-冯骥
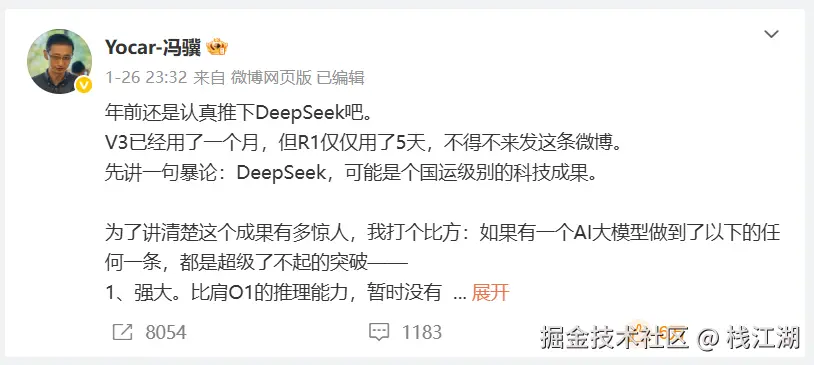
在DeepSeek-R1发布后,《黑神话:悟空》创作人冯骥于2025年1月26日晚发文力挺DeepSeek,称其"可能是个国运级别的科技成果"。他还总结DeepSeek强大之处在于:强大、便宜、开源、免费、联网、本地六大特点,他还强调只要AI大模型能做到其中一条就是超级了不起的的突破而DeepSeek全部、同时做到了。
而在第二天2025年1月27日DeepSeek-R1登顶苹果应用商店免费应用下载排行榜。
二、技术创新
当下国内的AI大模型面临着不少问题,其实总结起来就是算力、算法、数据、人才。算法、数据、人才说白了不会是关键问题主要还是在算力上,算力也就是GPU。
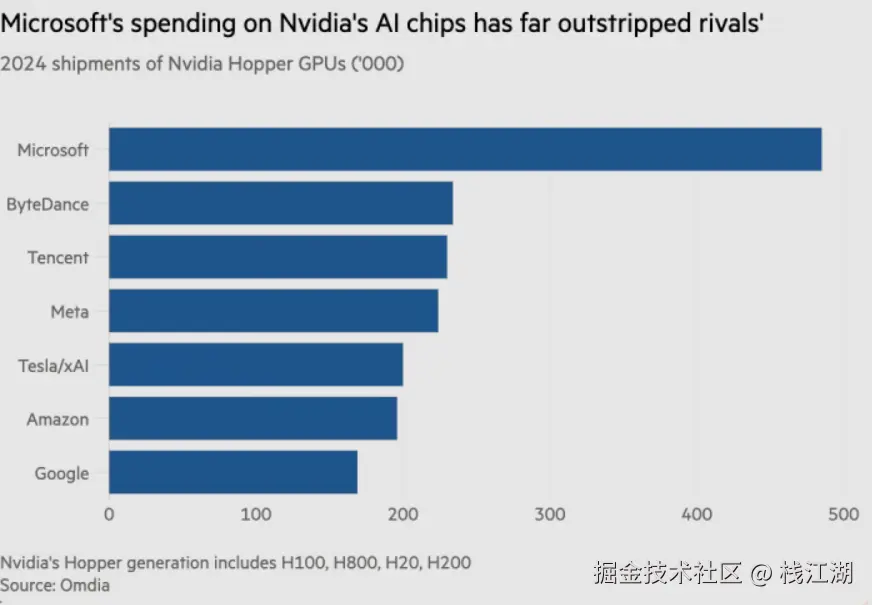 据报道2024年,微软向英伟达采购了约48.5万张GPU折算成货币就是一天文数字,而国内几个大户加起来才和微软一家差不多,并且美国还对出口中国的芯片进行限制。可想而知:训练需海量计算资源,硬件采购成本高。这么高昂的成本关键还被限制。
据报道2024年,微软向英伟达采购了约48.5万张GPU折算成货币就是一天文数字,而国内几个大户加起来才和微软一家差不多,并且美国还对出口中国的芯片进行限制。可想而知:训练需海量计算资源,硬件采购成本高。这么高昂的成本关键还被限制。
而DeepSeek的训练算法大大降低到大模型对硬件的消耗。早在2024年底发布DeepSeek V3模型时DeepSeek就开源了他的算法,当时B站很多大佬就说只要这些算法被推广和证实DeepSeek必定要火爆全球:
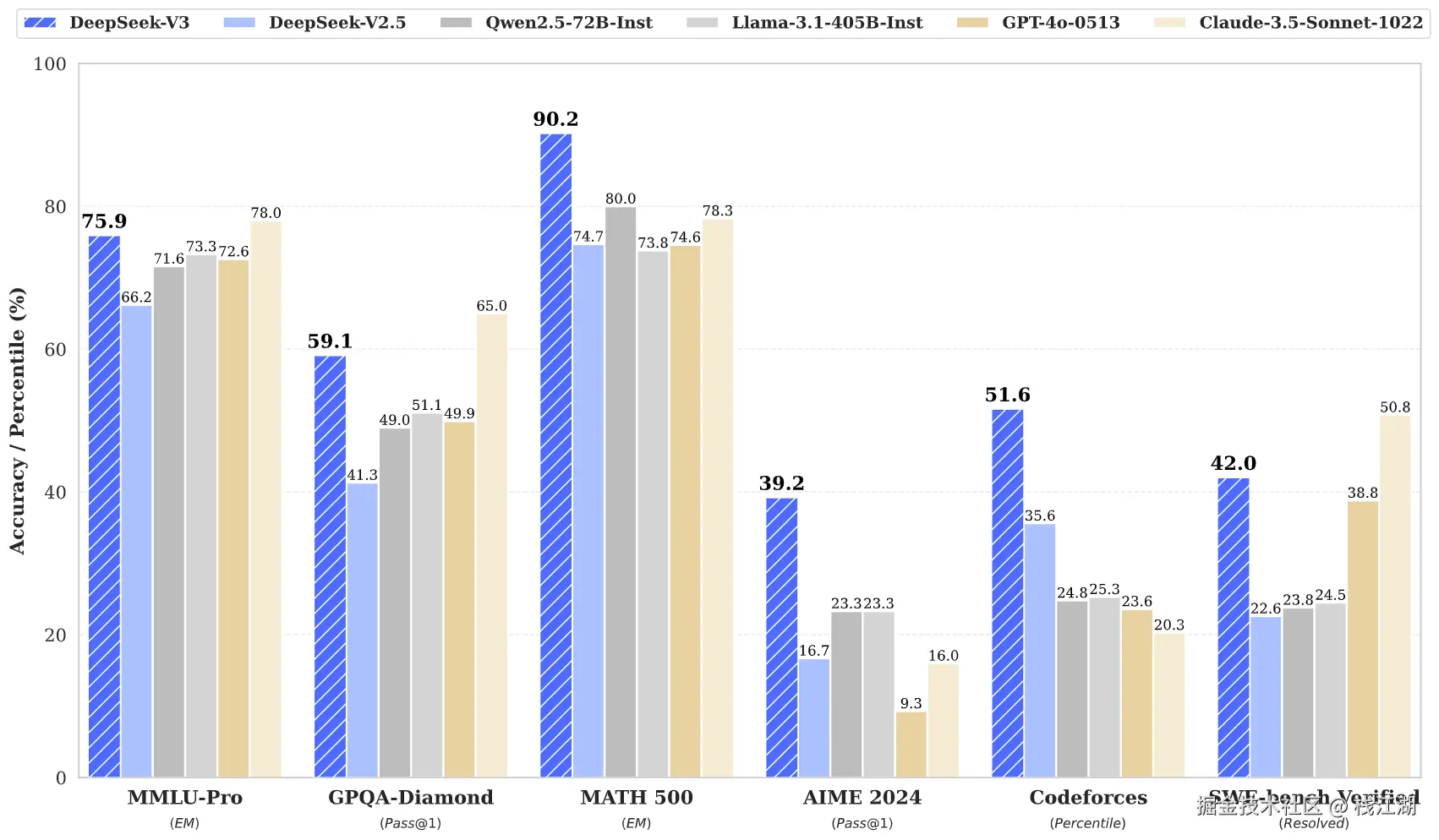
DualPipe算法: 模型采用类似流水线并行的优化策略,提高GPU的利用率,也通过PTX编程绕过CUDA限制。
精细化FP8: 模型采用FP8训练大幅减少计算和通信量,同时结合多令牌预测技术(MTP)提升训练密度。
高效训练架构: 模型采用混合专家(MoE )架构,减少了计算量和显存占用,同时设计一种创新的注意力机制 (MLA),提高推理效率。
专家模型架构: 模型引入共享专家和细粒度专家分配机制,这样可以动态调整专家负载,提高资源利用率。
2 能力升级
能力测试
在网上有不少网友整理了很多问题来测试大模型能力

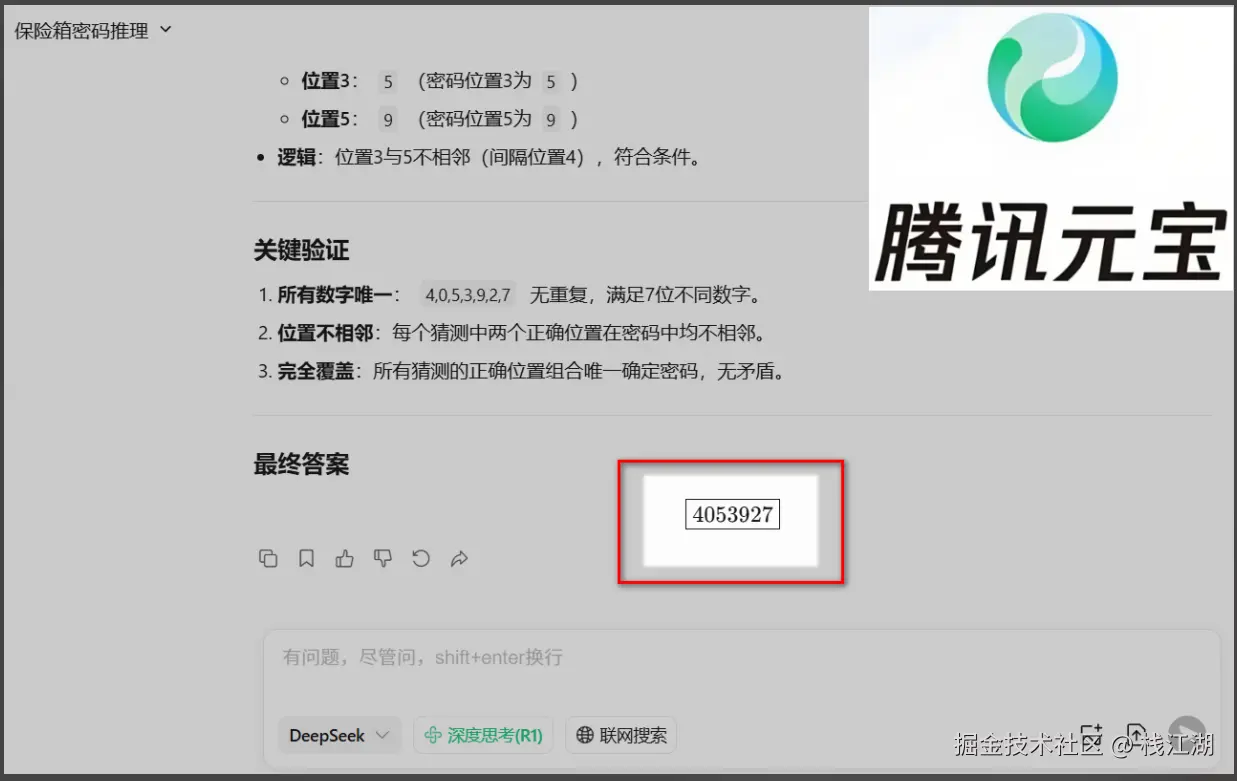
如果感兴趣的可以试试,比如这个推理保险箱密码的问题,大多数模型都算不出来。由于deepseek连续提问就会报服务器繁忙,所以使用腾讯元宝的DeepSeek-R1来测试,第5次得到正确的答案,当然在这个问题上和国外的AI还是一有定差距。
编码能力
DeepSeek 在多种编程语言和各种基准测试的开源代码模型中实现了最先进的性能。
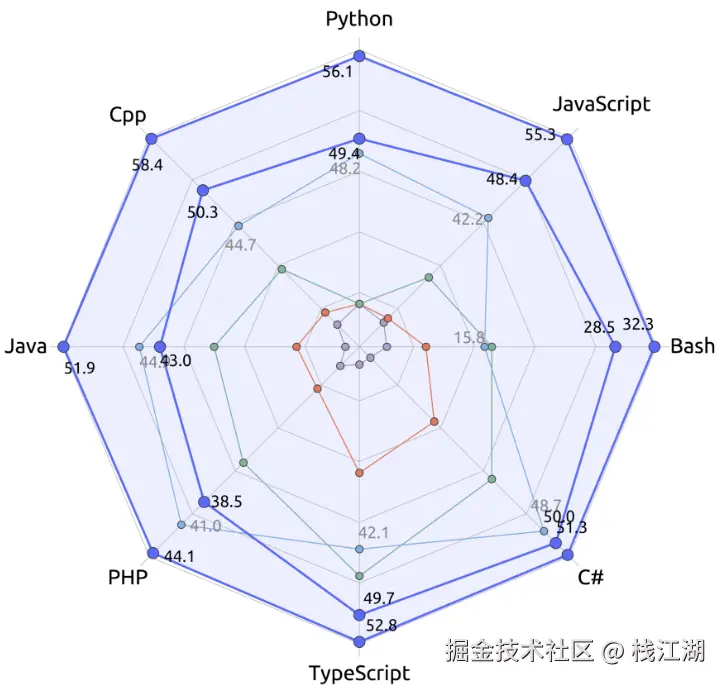
下面这个是来自Aider的一个排行榜
这个是来自Huggingface的编程能力排行榜
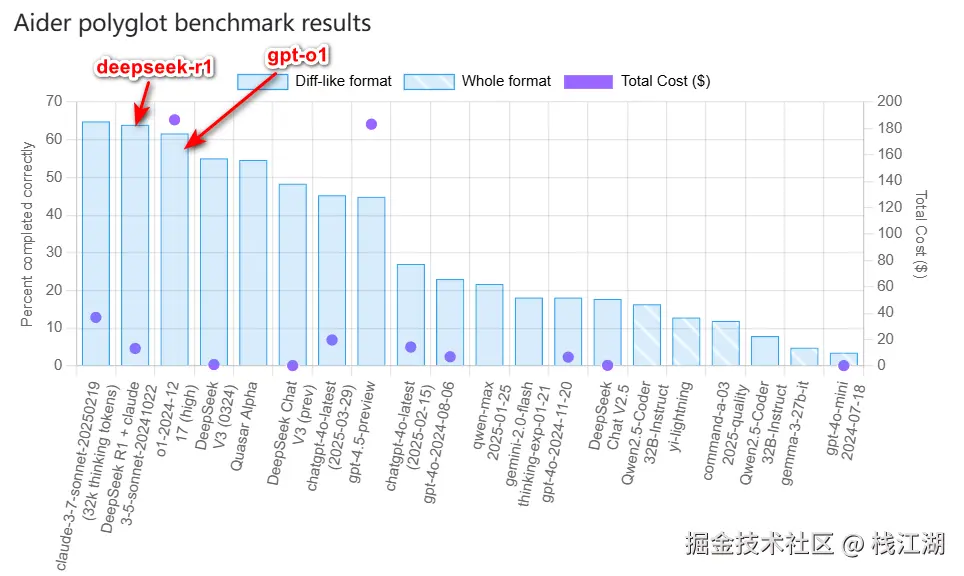
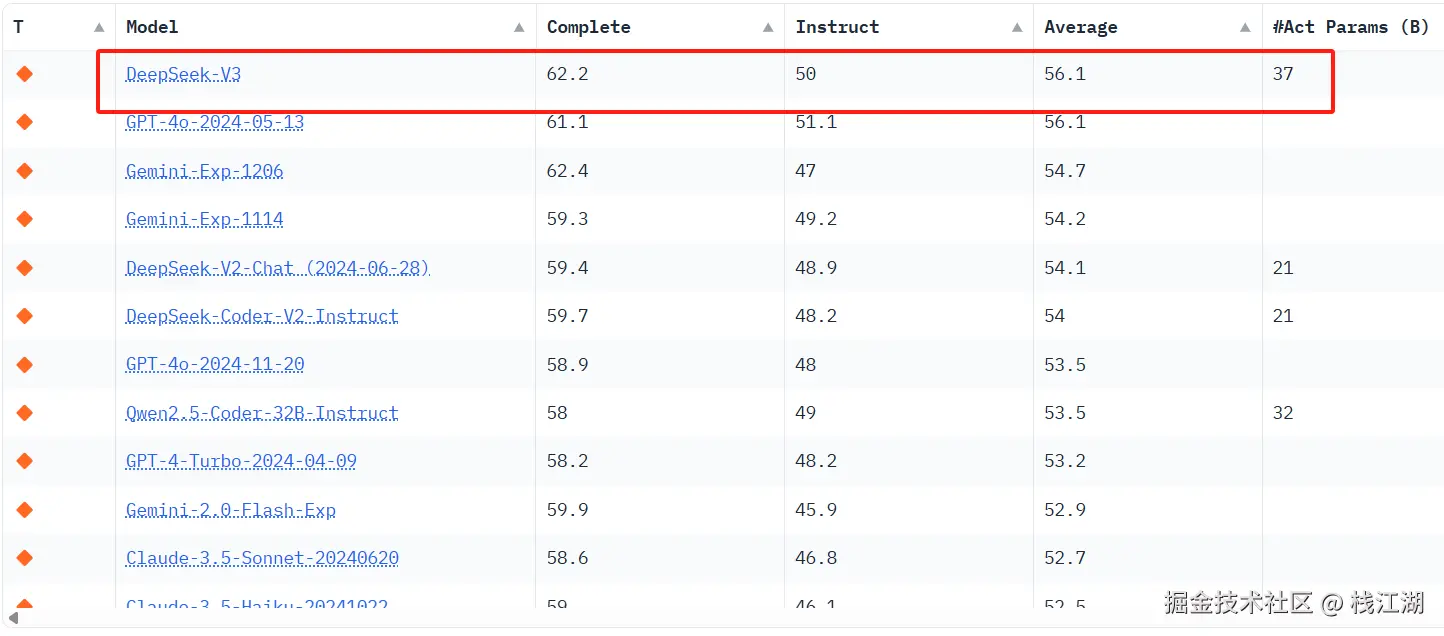
可以看到DeepSeek的编码能力非常的强,相信不少程序员已经在使用它。
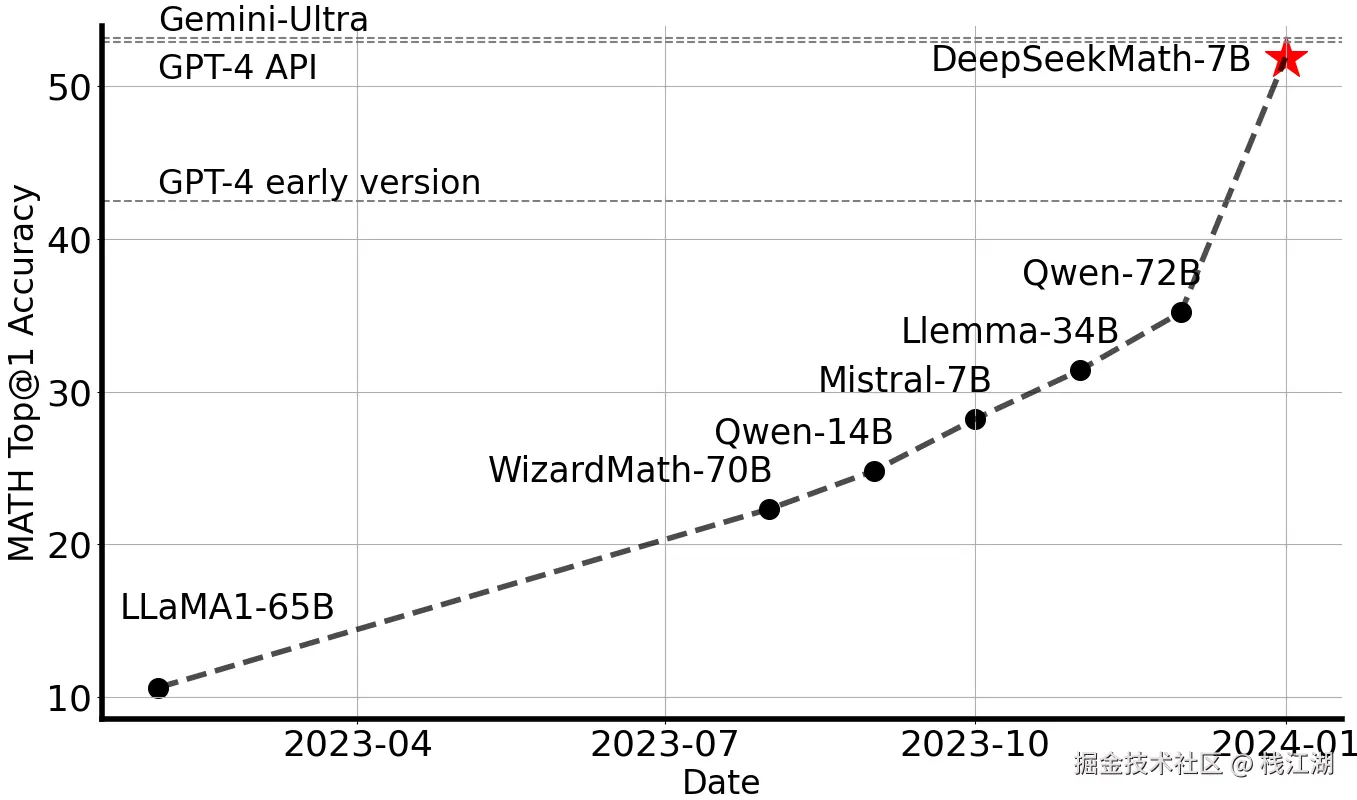
数学能力
在竞赛级 MATH 基准测试中取得了 51.7%,接近 Gemini-Ultra 和 GPT-4 的性能水平。
综合能力
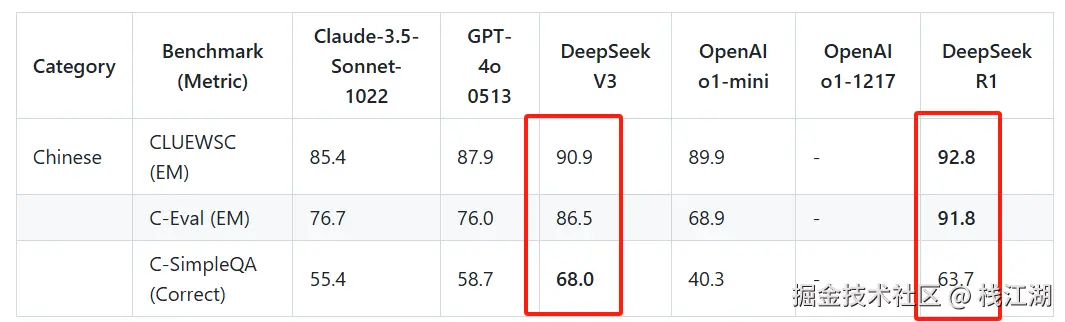
DeepSeek的发布一直以来都在媲美openai与claude
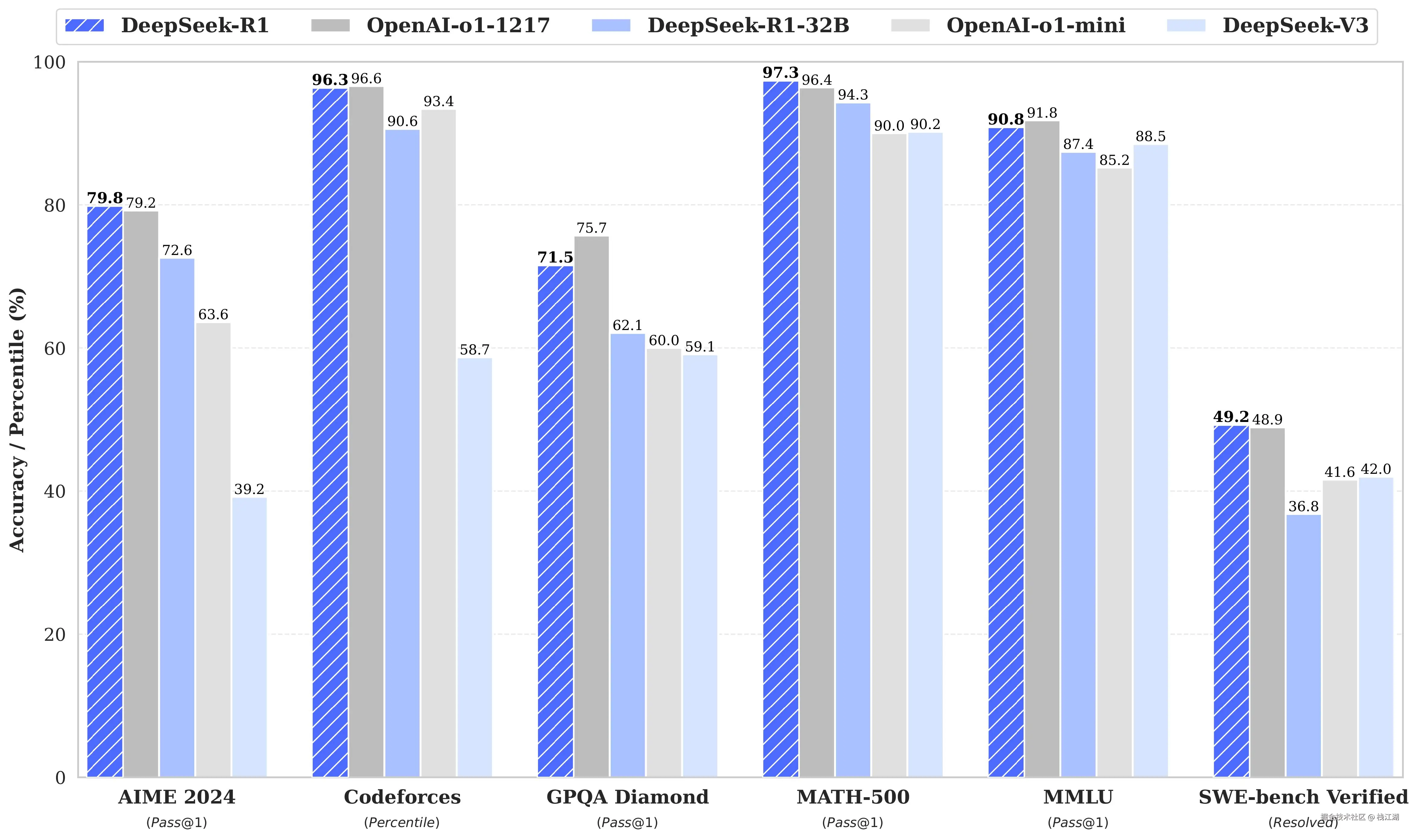
特点是在中文处理的能力