前言
一周暑期休假之后,大模型真好玩又来和大家分享LangChain智能体开发的相关教程啦!本系列分享前六篇分别讲述了
- LangChain&LangGraph的核心原理
- LangChain接入大模型的基本方法
- LangChain核心概念------链
- LangChain记忆存储与多轮对话机器人搭建
- LangChain接入工具基本流程
- LangChain Agent API快速搭建智能体
通过以上内容的学习大家基本具备了LangChain搭建简单智能体的能力。上篇文章中我们使用的create_tool_calling_agent函数是LangChain中一个通用的用来构建工具代理智能体的方法,除此以外LangChain还封装了丰富的Agent实现函数。本期内容通过一个多智能体协作实现浏览器自动化的项目继续向大家分享LangChain Agent智能体搭建的基本技巧。
本系列分享是笔者结合自己学习工作中使用LangChain&LangGraph经验倾心编写,力求帮助大家体系化快速掌握LangChain&LangGraph AI Agent智能体开发的技能!大家感兴趣可以关注笔者掘金账号和系列专栏。更可关注笔者同名微信公众号: 大模型真好玩 , 每期分享涉及的代码均可在公众号私信: LangChain智能体开发获得。
一、LangChain Agent API实现方式
除了create_tool_calling_agent这一通用的方法,LangChain还封装了许多不同的Agent实现形式,参考下表:
| 函数名 | 功能描述 | 适用场景 |
|---|---|---|
| create_tool_calling_agent | 创建使用工具的Agent | 通用工具调用 |
| create_openai_tools_agent | 创建OpenAI工具Agent | OpenAI模型专用 |
| create_openai_functions_agent | 创建OpenAI函数Agent | OpenAI函数调用 |
| create_react_agent | 创建ReAct推理Agent | 推理+行动模式 |
| create_structured_chat_agent | 创建结构化聊天Agent | 多输入工具支持 |
| create_conversational_retrieval_agent | 创建对话检索Agent | 检索增强对话 |
| create_json_chat_agent | 创建JSON聊天Agent | JSON格式交互 |
| create_xml_agent | 创建XML格式Agent | XML逻辑格式 |
| create_self_ask_with_search_agent | 创建自问自答搜索Agent | 自主搜索推理 |
以上实现形式中比较通用的场景是我们上篇文章使用的create_tool_calling_agent,而对于一些符合OpenAI RESTFUL API格式的请求可使用create_openai_tools_agent(OpenAI 定义的大模型及工具的请求格式,我们先前文章DeepSeek大模型API实战指南,python一键调用AI超能力打造多轮对话机器人! 使用的就是OpenAI请求大模型的接口,详细的请求格式可见OpenAI-API 接口文档(中文版))。另外像create_react_agent可以用于一些推理任务,create_conversational_retrieval_agent则可以用于一些对话系统。具体的api使用还是根据实际需求来选择。
二、LangChain PlayWright浏览器自动化实战
目前很多大模型的炫酷能力都是通过浏览器自动化操作来展示的。伴随着微软PlayWright 项目的兴起,不管是填写表格、发送文件还是获取不同类型的各个网页信息甚至自动购物等用户都可以通过PlayWright 模拟浏览器操作来完成。LangChain作为当之无愧的宇宙第一Agent开发框架,自然也集成了PlayWright的相关功能来实现浏览器自动化操作。
2.1 构建浏览器自动化代理环境
- 首先在我们之前创建的
anaconda虚拟环境langchainenv中执行如下命令安装浏览器自动化代理环境的依赖:
bash
pip install playwright lxml langchain_community beautifulsoup4 reportlab
- 此外还需要安装PlayWright内置的虚拟浏览器,在当前虚拟环境中执行如下命令:
bash
playwright install该命令会下载并安装Playwright 支持的浏览器内核(注意:PlayWright 并不会使用我们本机已有的浏览器,而是使用额外内核)。下载的浏览器和内核包括Chromium(Chrome开源版浏览器内核)、Firefox、WebKit(苹果Safari使用的浏览器引擎),这些浏览器和内核将被下载到本地的.cache/ms-playwright目录或项目~/.playwright 目录中,以便Playwright使用稳定一致的运行环境。
2.2 编写自动化操作浏览器脚本
大模型应用开发领域有非常多的浏览器自动化需求,最常见的场景当属"自动化提取网页内容进行分析并生成报告",这样的流程扩宽了收集信息的有效途径,大大提升了信息分析效率。接下来我们就尝试使用create_openai_tools_agent开发一个浏览器自动化代理项目。
- 引入相关依赖,
PlayWrightBrowserToolkit和create_sync_playwright_browser与PlayWright 自动化浏览器的创建有关,hub是LangChain保存提示词的网站,下面会详细讲解。其它的引入包就是我们讲过的模型和Agent构建的常用依赖这里不再赘述。
python
from langchain_community.agent_toolkits import PlayWrightBrowserToolkit
from langchain_community.tools.playwright.utils import create_sync_playwright_browser
from langchain import hub
from langchain.agents import AgentExecutor, create_openai_tools_agent
from langchain.chat_models import init_chat_model- 初始化PlayWright浏览器。
python
# 初始化 Playwright 浏览器:
sync_browser = create_sync_playwright_browser() # 创建同步执行的浏览器
toolkit = PlayWrightBrowserToolkit.from_browser(sync_browser=sync_browser) # 构建PlayWright浏览器工具
tools = toolkit.get_tools() # 获取PlayWright浏览器操作函数- 初始化模型,这里为保证更强大的大模型Agent能力,本期内容继续使用
DeepSeek-V3模型,具体配置大家可参考LangChain接入大模型的基本方法。
python
# 初始化模型
model = init_chat_model(
model="deepseek-chat",
model_provider="deepseek",
api_key="你注册的DeepSeek API Key"
)- 现在Agent构建的三要素模型 、工具函数 和提示词 就缺提示词了,本期分享我们只需编写一行代码即可构造提示词,代码如下:
python
# 通过 LangChain Hub 拉取提示词模版
prompt = hub.pull("hwchase17/openai-tools-agent")这行代码的运行原理是从LangChainHub网站中拉取已经定义好的提示词模板,提示词模板如下:
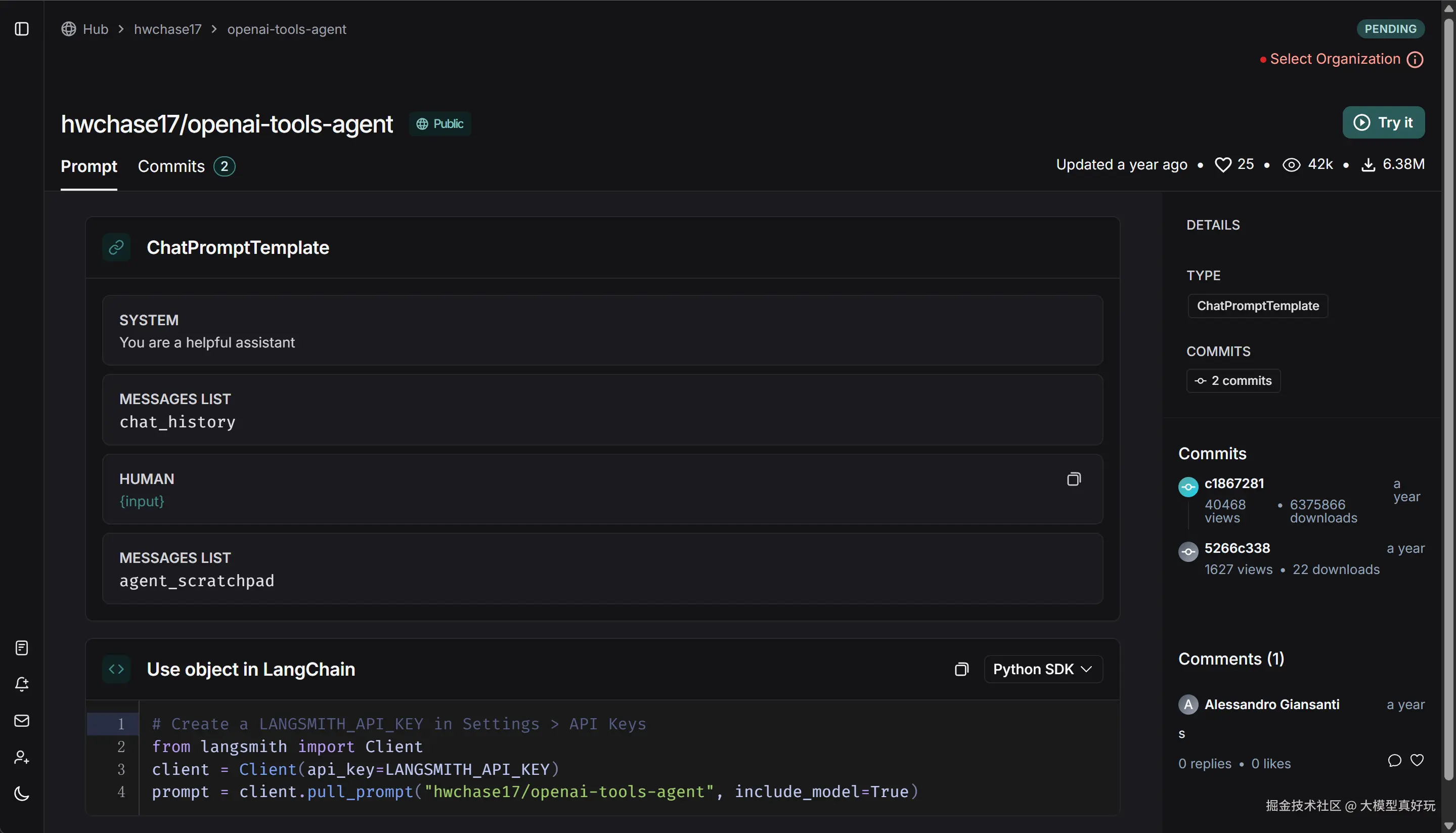
拉取提示词模板的代码与以下自定义提示词的代码等价:
python
prompt = ChatPromptTemplate.from_messages(
[
("system", "You are a helpful assistant"),
('placeholder': "{chat_history}"),
("human", "{input}"),
("placeholder", "{agent_scratchpad}"),
]
)现在大家应该理解了LangChain Hub的作用,LangChain通过这种方式内置了丰富的提示词模板,大大降低了实际开发过程中的开发难度。
- 使用
create_openai_tools_agent快速构建代理,并使用AgentExecutor构建代理执行类,这部分代码是我们上小节讲解的内容,这里就不加赘述了。
python
# 通过 LangChain 创建 OpenAI 工具代理
agent = create_openai_tools_agent(model, tools, prompt)
# 通过 AgentExecutor 执行代理
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)- 接下来我们要求PlayWright 爬取微软Copilot的官方介绍网页并总结网页内容,代码和执行结果如下:
python
if __name__ == "__main__":
# 定义任务
command = {
"input": "访问这个网站 https://www.microsoft.com/en-us/microsoft-365/blog/2025/01/16/copilot-is-now-included-in-microsoft-365-personal-and-family/?culture=zh-cn&country=cn 并帮我总结一下这个网站的内容"
}
# 执行任务
response = agent_executor.invoke(command)
print(response)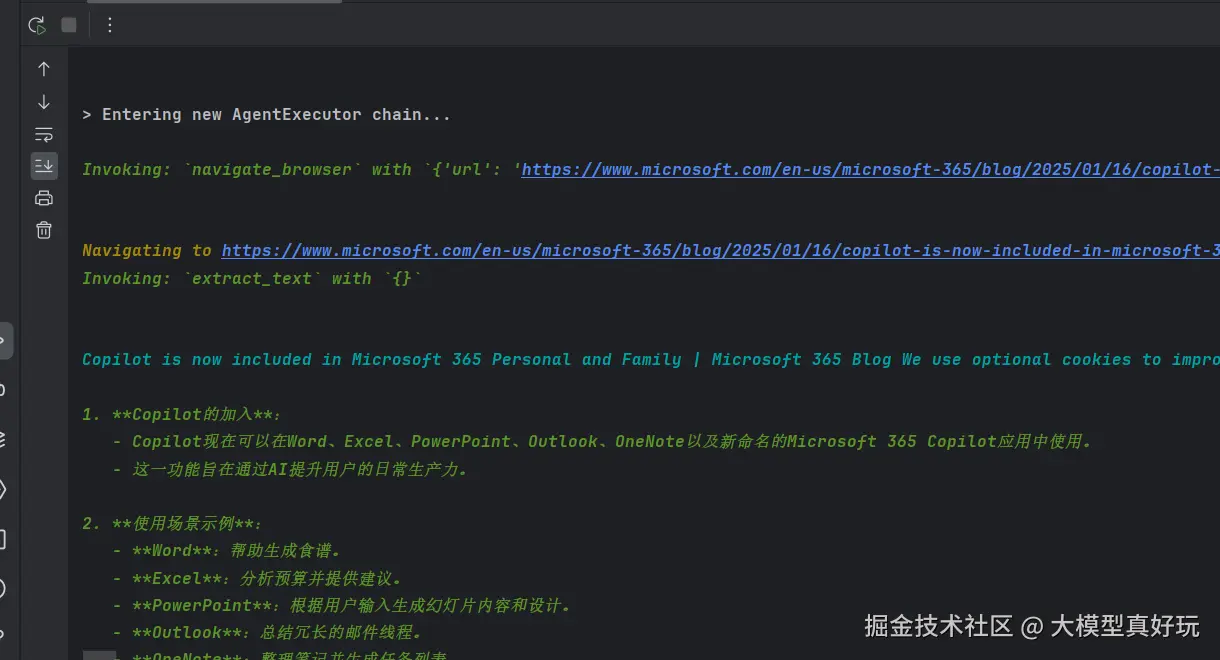
完整代码如下,大家可详细阅读理解,也可修改浏览器自动化访问的网站进行尝试(注意:部分网站有防爬防自动化机制,需要PlayWright绕过这些机制,本期分享不会讲绕过方法内容,以后会根据工作中使用的实际案例进行分享,大家可关注笔者同名微信公众号: 大模型真好玩获得更多精彩内容)
python
from langchain_community.agent_toolkits import PlayWrightBrowserToolkit
from langchain_community.tools.playwright.utils import create_sync_playwright_browser
from langchain import hub
from langchain.agents import AgentExecutor, create_openai_tools_agent
from langchain.chat_models import init_chat_model
# 初始化 Playwright 浏览器:
sync_browser = create_sync_playwright_browser()
toolkit = PlayWrightBrowserToolkit.from_browser(sync_browser=sync_browser)
tools = toolkit.get_tools()
# 通过 LangChain Hub 拉取提示词模版
prompt = hub.pull("hwchase17/openai-tools-agent")
# 初始化模型
model = init_chat_model(
model="deepseek-chat",
model_provider="deepseek",
api_key=""
)
# 通过 LangChain 创建 OpenAI 工具代理
agent = create_openai_tools_agent(model, tools, prompt)
# 通过 AgentExecutor 执行代理
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
if __name__ == "__main__":
# 定义任务
command = {
"input": "访问这个网站 https://www.microsoft.com/en-us/microsoft-365/blog/2025/01/16/copilot-is-now-included-in-microsoft-365-personal-and-family/?culture=zh-cn&country=cn 并帮我总结一下这个网站的内容"
}
# 执行任务
response = agent_executor.invoke(command)
print(response)三、多智能体协作生成报告
我们更进一步要编写一个更加复杂的浏览器自动化代理,将PlayWright Agent封装成工具函数,并结合LangChain的LCEL串行链,实现先爬取网页内容然后将网页内容写入到本地PDF文件中的自动报告生成效果。
- 引入相关依赖包,相比上述代码增加了PDF创建和写入的相关依赖
python
import os
from langchain_community.agent_toolkits import PlayWrightBrowserToolkit
from langchain_community.tools.playwright.utils import create_sync_playwright_browser
from langchain import hub
from langchain.agents import AgentExecutor, create_openai_tools_agent
from langchain.chat_models import init_chat_model
from langchain_core.tools import tool
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
# 以下依赖用于编写pdf创建写入相关代码
from reportlab.lib.pagesizes import A4
from reportlab.platypus import SimpleDocTemplate, Paragraph, Spacer
from reportlab.lib.styles import getSampleStyleSheet, ParagraphStyle
from reportlab.lib.enums import TA_JUSTIFY, TA_CENTER
from reportlab.pdfbase import pdfmetrics
from reportlab.pdfbase.ttfonts import TTFont
from datetime import datetime- 创建网站总结工具,将上述PlayWright智能体代码封装为工具函数:
python
@tool
def summarize_website(url):
"""访问指定网站并返回内容总结"""
try:
# 创建浏览器实例
sync_browser = create_sync_playwright_browser()
toolkit = PlayWrightBrowserToolkit.from_browser(sync_browser=sync_browser)
tools = toolkit.get_tools()
# 初始化模型和Agent
model = init_chat_model(
model="deepseek-chat",
model_provider="deepseek",
api_key=""
)
prompt = hub.pull("hwchase17/openai-tools-agent")
agent = create_openai_tools_agent(model, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=False)
# 执行总结任务
command = {
"input": f"访问这个网站 {url} 并帮我详细总结一下这个网站的内容,包括主要功能、特点和使用方法"
}
result = agent_executor.invoke(command)
return result.get("output", "无法获取网站内容总结")
except Exception as e:
return f"网站访问失败: {str(e)}"- 创建PDF生成的工具函数
python
@tool
def generate_pdf(content):
"""将文本内容生成为PDF文件"""
try:
# 生成文件名(带时间戳)
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
filename = f"website_summary_{timestamp}.pdf"
# 创建PDF文档
doc = SimpleDocTemplate(filename, pagesize=A4)
styles = getSampleStyleSheet()
# 注册中文字体(如果系统有的话)
try:
# Windows 系统字体路径
font_paths = [
"C:/Windows/Fonts/simhei.ttf", # 黑体
"C:/Windows/Fonts/simsun.ttc", # 宋体
"C:/Windows/Fonts/msyh.ttc", # 微软雅黑
]
chinese_font_registered = False
for font_path in font_paths:
if os.path.exists(font_path):
try:
pdfmetrics.registerFont(TTFont('ChineseFont', font_path))
chinese_font_registered = True
print(f"✅ 成功注册中文字体: {font_path}")
break
except:
continue
if not chinese_font_registered:
print("⚠️ 未找到中文字体,使用默认字体")
except Exception as e:
print(f"⚠️ 字体注册失败: {e}")
# 自定义样式 - 支持中文
title_style = ParagraphStyle(
'CustomTitle',
parent=styles['Heading1'],
fontSize=18,
alignment=TA_CENTER,
spaceAfter=30,
fontName='ChineseFont' if 'chinese_font_registered' in locals() and chinese_font_registered else 'Helvetica-Bold'
)
content_style = ParagraphStyle(
'CustomContent',
parent=styles['Normal'],
fontSize=11,
alignment=TA_JUSTIFY,
leftIndent=20,
rightIndent=20,
spaceAfter=12,
fontName='ChineseFont' if 'chinese_font_registered' in locals() and chinese_font_registered else 'Helvetica'
)
# 构建PDF内容
story = []
# 标题
story.append(Paragraph("网站内容总结报告", title_style))
story.append(Spacer(1, 20))
# 生成时间
time_text = f"生成时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}"
story.append(Paragraph(time_text, styles['Normal']))
story.append(Spacer(1, 20))
# 分隔线
story.append(Paragraph("=" * 50, styles['Normal']))
story.append(Spacer(1, 15))
# 主要内容 - 改进中文处理
if content:
# 清理和处理内容
content = content.replace('\r\n', '\n').replace('\r', '\n')
paragraphs = content.split('\n')
for para in paragraphs:
if para.strip():
# 处理特殊字符,确保PDF可以正确显示
clean_para = para.strip()
# 转换HTML实体
clean_para = clean_para.replace('<', '<').replace('>', '>').replace('&', '&')
try:
story.append(Paragraph(clean_para, content_style))
story.append(Spacer(1, 8))
except Exception as para_error:
# 如果段落有问题,尝试用默认字体
try:
fallback_style = ParagraphStyle(
'Fallback',
parent=styles['Normal'],
fontSize=10,
leftIndent=20,
rightIndent=20,
spaceAfter=10
)
story.append(Paragraph(clean_para, fallback_style))
story.append(Spacer(1, 8))
except:
# 如果还是有问题,记录错误但继续
print(f"⚠️ 段落处理失败: {clean_para[:50]}...")
continue
else:
story.append(Paragraph("暂无内容", content_style))
# 页脚信息
story.append(Spacer(1, 30))
story.append(Paragraph("=" * 50, styles['Normal']))
story.append(Paragraph("本报告由 Playwright PDF Agent 自动生成", styles['Italic']))
# 生成PDF
doc.build(story)
# 获取绝对路径
abs_path = os.path.abspath(filename)
print(f"📄 PDF文件生成完成: {abs_path}")
return f"PDF文件已成功生成: {abs_path}"
except Exception as e:
error_msg = f"PDF生成失败: {str(e)}"
print(error_msg)
return error_msg- 创建串行链并编写测试函数,在LangChain接入工具基本流程分享中我们提到过LangChain tool工具函数也是
Runnable类型包含invoke()方法,因此工具函数间也可以串联构成"链"。
python
# 创建串行链
print("=== 创建串行链:网站总结 → PDF生成 ===")
simple_chain = summarize_website | generate_pdf
# 编写测试函数
def test_simple_chain(url):
"""测试简单串行链"""
print(f"\n🔄 开始处理URL: {url}")
print("📝 步骤1: 网站总结...")
print("📄 步骤2: 生成PDF...")
result = simple_chain.invoke(url)
print(f"✅ 完成: {result}")
return result- 执行测试程序,我们这里同样使用Copilot的官方介绍网页内容进行测试,代码和执行结果如下:
python
if __name__ == "__main__":
# 测试URL
test_url = "https://www.microsoft.com/en-us/microsoft-365/blog/2025/01/16/copilot-is-now-included-in-microsoft-365-personal-and-family/?culture=zh-cn&country=cn"
test_simple_chain(test_url)我们可以看到代码执行成功并在本地成功创建了PDF文件:
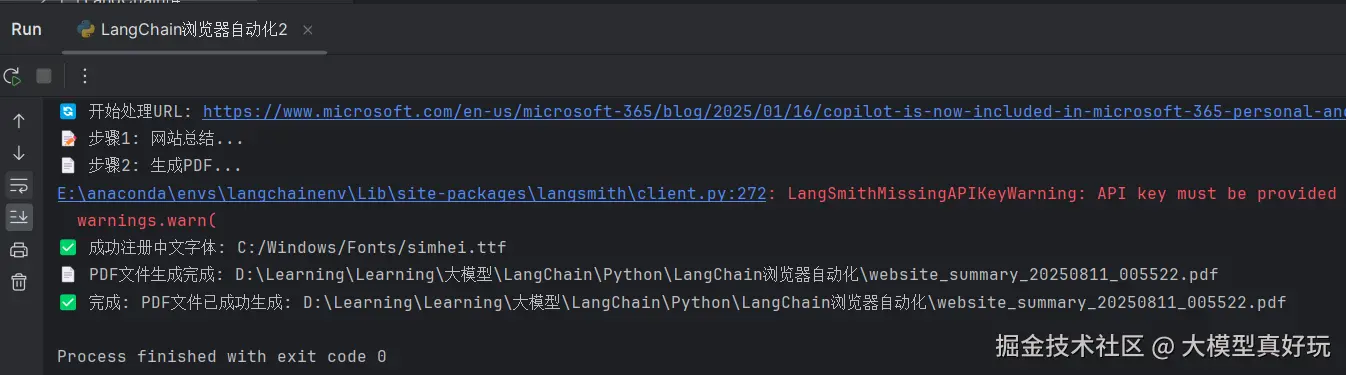
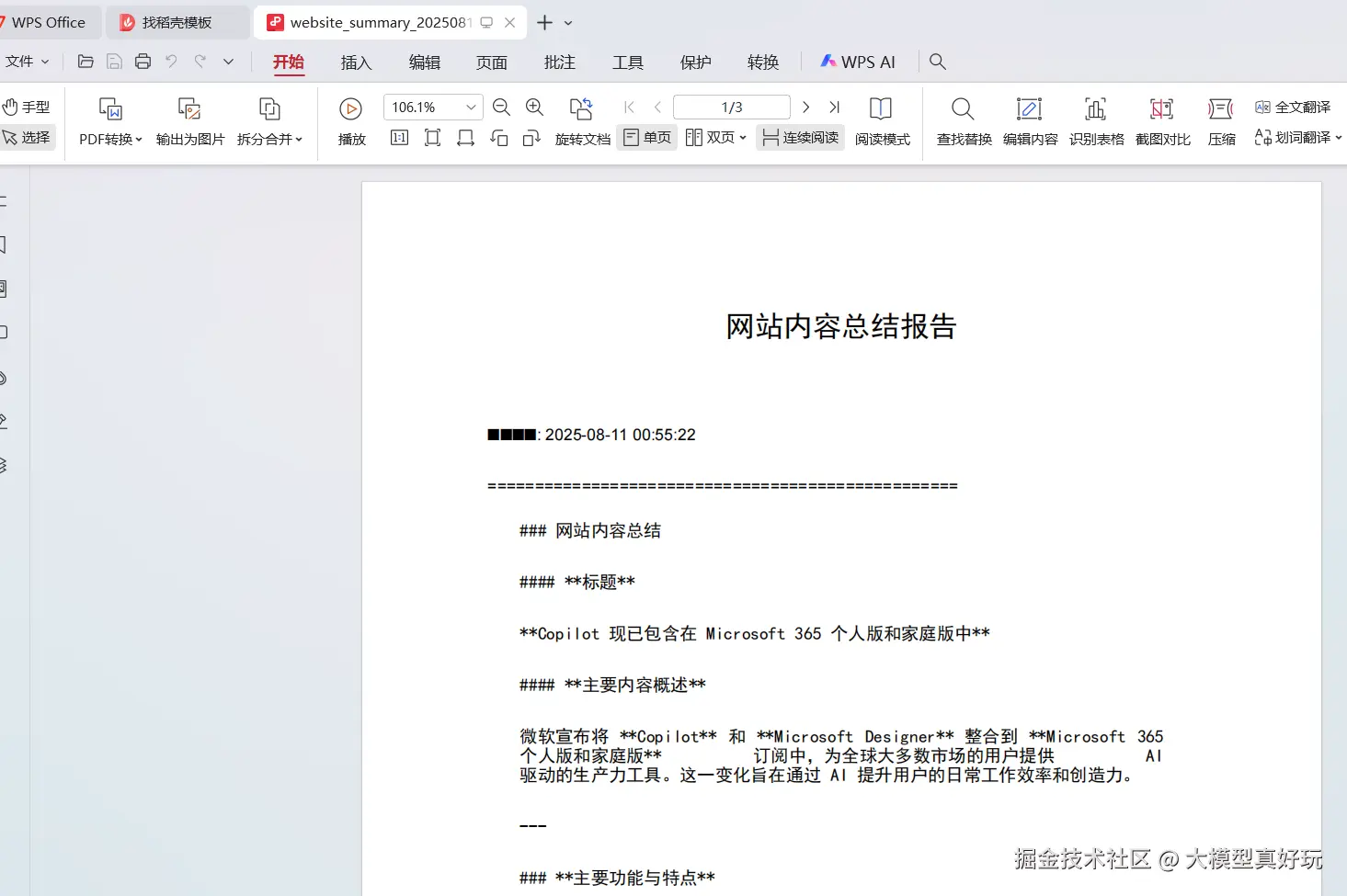
打开PDF文件也可以看到相关内容被完整保存
四、总结
本期分享通过编写浏览器自动化实现自动爬取指定网页并生成报告的实战案例进一步学习LangChain智能体搭建的相关技巧。通过LangChain提供的丰富API,程序员可以方便的搭建智能体并组合成工作流。除了工具函数调用的基本能力,MCP也是扩展大模型能力的热门手段,笔者也发布过MCP从基础到入门的多篇文章。从下期分享开始,笔者将使用LangChain与MCP技术相融合进一步拓宽大模型的能力边界,大家期待一下吧~(本周更完)
本系列分享预计会有20节左右的规模,保证大家看完一定能够掌握LangChain&LangGraph的开发能力,大家感兴趣可关注笔者掘金账号和专栏,更可关注笔者的同名微信公众号:大模型真好玩 , 本系列分享的全部代码均可在微信公众号私信笔者: LangChain智能体开发 免费获得