内存回收
Redis 之所以性能强,最主要的原因就是基于内存存储。然而单节点的 Redis 其内存大小不宜过大,会影响持久化或主从同步性能。
我们可以通过修改配置文件来设置 Redis 的最大内存:

当内存使用达到上限时,就无法存储更多数据了。
过期策略

Redis是如何知道一个key是否过期的?
DB结构

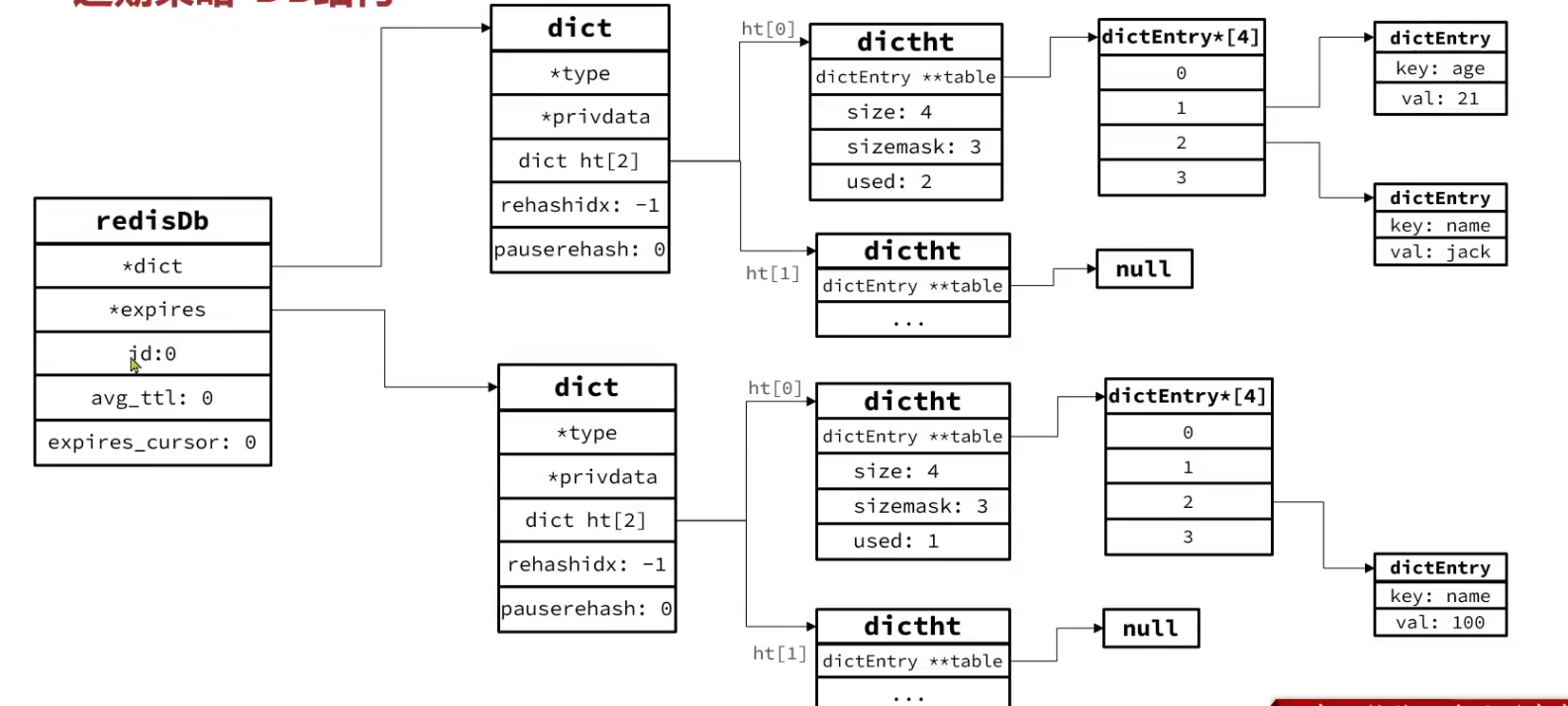
在 redisDb 结构体中,有一个 dict *expires; 字段:
- 作用 :专门存储「设置了 TTL 的 key」及其对应的过期时间(时间戳形式存储 )。
- 存储逻辑 :只有给 key 设置了
EXPIRE/PEXPIRE等命令时,Redis 才会将该 key 与过期时间的映射,写入expires字典。未设置 TTL 的 key,不会出现在expires中。

是不是TTL到期就立即删除了?

惰性删除


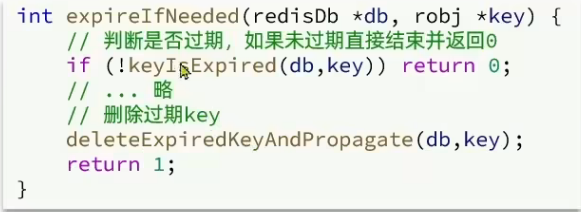
内存回收不及时:如果某些过期 key 长时间没有被访问,它们就会一直占用内存,导致 Redis 内存无法及时回收,可能会出现内存占用过高的情况
周期删除

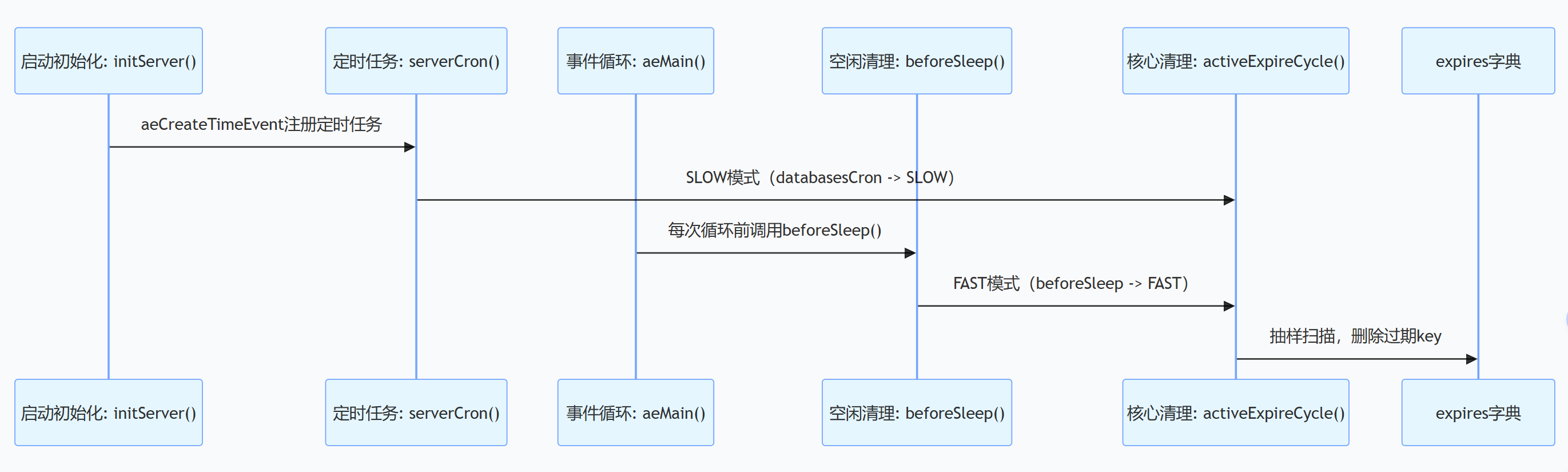
- 启动初始化:注册定时任务(SLOW 模式入口)
java
// server.c -> initServer()
void initServer(void) {
// 创建定时器,关联回调函数 serverCron
// 执行周期:1 毫秒(实际受 server.hz 调节,默认 10 次/秒)
aeCreateTimeEvent(server.el, 1, serverCron, NULL, NULL);
}- 作用 :Redis 启动时,注册
serverCron为定时任务,为 SLOW 模式提供执行入口。
- 定时任务执行:
serverCron驱动 SLOW 模式
cpp
// server.c -> serverCron()
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
// 更新 LRU 时钟(为淘汰策略准备)
unsigned int lruclock = getLRUClock();
atomicSet(server.lruclock, lruclock);
// 执行数据库级清理(包括过期 key 清理)
databasesCron();
// 控制执行频率:返回 1000/server.hz 毫秒(默认 100 毫秒/次)
return 1000/server.hz;
}- 关键逻辑 :
databasesCron()是 SLOW 模式的直接入口。return 1000/server.hz动态调整定时任务的执行间隔(server.hz越大,间隔越短 )。
- 数据库级清理:
databasesCron调用 SLOW 模式
java
// server.c -> databasesCron()
void databasesCron(void) {
// 执行过期 key 清理,模式为 SLOW
activeExpireCycle(ACTIVE_EXPIRE_CYCLE_SLOW);
}- 作用 :将定时任务的 "宏观调度",下放到 "数据库级清理",调用
activeExpireCycle执行具体的过期 key 扫描。
- 事件循环前置:
beforeSleep驱动 FAST 模式
cpp
// server.c -> beforeSleep()
void beforeSleep(struct aeEventLoop *eventLoop) {
// 执行过期 key 清理,模式为 FAST
activeExpireCycle(ACTIVE_EXPIRE_CYCLE_FAST);
}- 触发时机 :Redis 处理完一轮事件(如客户端请求)后,进入 "等待新事件" 的循环前,会调用
beforeSleep。 - 作用:利用 "事件循环空闲时间" 执行 FAST 模式清理,提升过期 key 清理的及时性。
- 事件循环主逻辑:
aeMain关联 FAST 模式
cpp
// ae.c -> aeMain()
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
while (!eventLoop->stop) {
// 进入事件循环前,调用 beforeSleep(FAST 模式入口)
beforeSleep(eventLoop);
// 等待并处理新事件(客户端请求、定时任务等)
int n = aeApiPoll(eventLoop, 1000/server.hz);
if (n > 0) {
aeProcessEvents(eventLoop, AE_ALL_EVENTS);
}
}
}- 逻辑串联 :
aeMain是 Redis 事件循环的主函数。- 每次循环前调用
beforeSleep(FAST 模式 ),循环内处理定时任务(SLOW 模式 )。
- 核心清理函数:
activeExpireCycle
cpp
void activeExpireCycle(int type) {
// 根据 type(SLOW/FAST)设置不同的扫描参数:
// - 扫描时长上限
// - 抽样 key 数量
// 从 redisDb.expires 中抽样 key,检查是否过期,过期则删除
// ...(具体实现逻辑)
}- 核心逻辑 :
- 根据
type(SLOW/FAST)调整扫描的 "激进程度":- SLOW 模式:扫描时长短、抽样少,避免阻塞主线程。
- FAST 模式:扫描时长较长、抽样多,利用空闲时间更彻底清理。
- 根据
- SLOW 模式规则 :
- 执行频率受
server.hz影响,默认每秒执行 10 次,周期 100ms 。 - 清理耗时不超执行周期的 25% 。
- 遍历 db 及其中 bucket,抽取 20 个 key 判断过期 。
- 未达 25ms 且过期 key 比例>10% 则继续抽样,否则结束 。
- 执行频率受
- FAST 模式规则(过期 key 比例小于 10% 不执行 ) :
- 执行频率受
beforeSleep()调用频率影响,两次间隔不低于 2ms 。 - 清理耗时不超 1ms 。
- 遍历 db 及其中 bucket,抽取 20 个 key 判断过期 。
- 未达 1ms 且过期 key 比例>10% 则继续抽样,否则结束 。
- 执行频率受
slow与fast的区别
- 执行频率
- SLOW 模式 :执行频率由
server.hz参数决定,默认值为 10,意味着每秒执行 10 次,执行周期是 100ms 。这是一个相对固定的、周期性的执行频率,不受 Redis 事件循环等其他因素干扰。 - FAST 模式 :执行频率受
beforeSleep()函数的调用频率影响,而beforeSleep()在 Redis 每次事件循环前被调用。虽然执行较为高频,但为了避免过度占用资源,两次 FAST 模式执行的时间间隔不低于 2ms。相比 SLOW 模式,FAST 模式的执行更加依赖 Redis 事件循环的情况 。
- 单次清理耗时
- SLOW 模式 :执行清理操作的耗时不能超过一次执行周期的 25% 。以默认配置为例,
server.hz为 10,执行周期是 100ms,那么 SLOW 模式下每次清理最长耗时为 25ms。这是为了在不严重影响 Redis 主线程处理其他请求的前提下,进行过期 key 清理。 - FAST 模式:执行清理操作的耗时上限为 1ms 。相比 SLOW 模式,FAST 模式对单次清理的耗时限制更为严格,进一步减少对主线程的影响,确保 Redis 能快速回到处理事件循环的工作中。
- 触发条件
- SLOW 模式 :按照固定的
server.hz频率定时触发,无论当前过期 key 的比例是多少,都会在设定的周期时间点执行清理操作。 - FAST 模式 :在 Redis 每个事件循环前调用
beforeSleep()函数触发,但有一个前提条件,即只有当过期 key 比例大于 10% 时才会执行 。如果过期 key 比例小于 10%,则不执行 FAST 模式的清理操作。
- 扫描和清理力度
- SLOW 模式:逐个遍历 Redis 中的所有数据库(db),再逐个遍历每个 db 中的哈希桶(bucket),抽取 20 个 key 判断是否过期。如果没有达到时间上限(25ms),并且过期 key 比例大于 10%,会再进行一次抽样,尽可能在允许的时间内清理更多过期 key,对过期 key 的清理较为积极 。
- FAST 模式:同样是逐个遍历 db 和其中的 bucket,抽取 20 个 key 判断是否过期 。不过,由于单次清理耗时限制更短(1ms),在扫描和清理的力度上相对 SLOW 模式要弱一些,主要是利用事件循环前的短暂空闲时间,快速处理部分过期 key。
- 资源占用与适用场景
- SLOW 模式:由于执行周期相对固定且单次清理时间较长,占用的 CPU 等资源相对较多,但能保证定期对过期 key 进行清理,适用于日常持续清理过期 key,维持内存空间稳定的场景。
- FAST 模式:执行时间短,对资源的占用相对较少,主要在系统相对空闲(事件循环前)且过期 key 较多(比例大于 10%)时,快速清理一部分过期 key,作为 SLOW 模式的补充,避免大量过期 key 积累影响内存使用。

淘汰策略

Redis会在处理客户端命令的方法processCommand()中尝试做内存淘汰
cpp
int processCommand(client *c) {
// 条件判断:如果服务器配置了maxmemory(即开启了内存限制),并且当前没有Lua脚本执行超时的情况
if (server.maxmemory && !server.lua_timedout) {
// 尝试执行内存淘汰策略,调用performEvictions函数
// performEvictions会根据配置的maxmemory-policy(如LRU、LFU等)尝试释放内存
// 返回值EVICT_FAIL表示内存淘汰失败(比如无法释放足够内存),这里将结果转换为布尔值给out_of_memory
int out_of_memory = (performEvictions() == EVICT_FAIL);
// 如果内存淘汰失败,并且配置了拒绝内存不足时的写命令(reject_cmd_on_oom为true)
if (out_of_memory && reject_cmd_on_oom) {
// 拒绝当前客户端的命令,向客户端返回内存不足的错误信息(shared.oomerr是预定义的错误回复)
rejectCommand(c, shared.oomerr);
// 返回C_OK表示命令处理完成(虽然实际是拒绝了命令,但流程上算处理完毕)
return C_OK;
}
}
// 后续还有其他命令处理逻辑(此处代码省略,比如实际执行命令、返回结果等)
// ...
return C_OK;
}Redis在任何的命令执行之前都要做内存的检查


Redis如何去获取最近访问时间和最近访问频率?
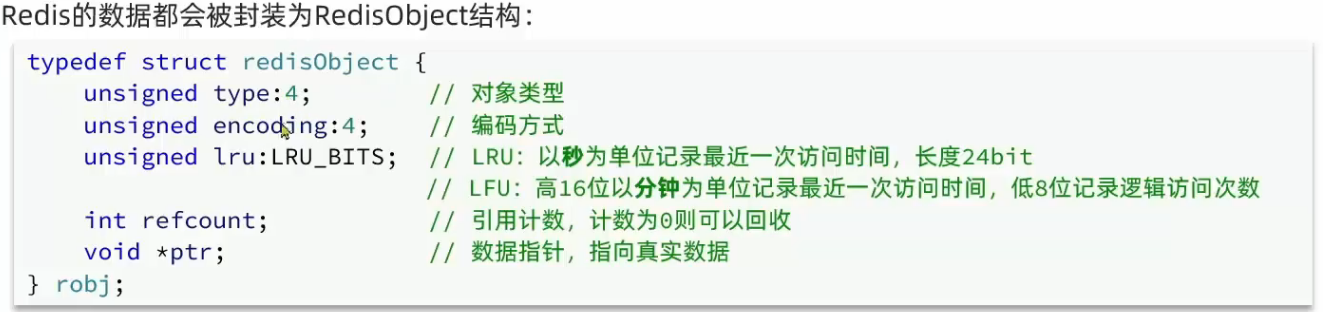
Redis 的 LFU 逻辑访问次数机制,并非直接统计实际访问次数,而是先生成 0 到 1 的随机数 R ,再利用公式 1/(旧次数 * lfu_log_factor + 1)(lfu_log_factor 默认 10 )算出概率阈值 P ,当 R 小于 P 时,计数器加 1 且最大不超 255 ;同时,访问次数会随时间衰减,距离上一次访问时间每隔 lfu_decay_time 分钟(默认 1 ),计数器减 1 ,通过这种概率性计数结合时间衰减的方式,将物理访问次数转化为逻辑访问次数,以此减少内存占用、区分不同访问频率的 key ,平衡高频与低频访问场景下的计数与淘汰逻辑 。

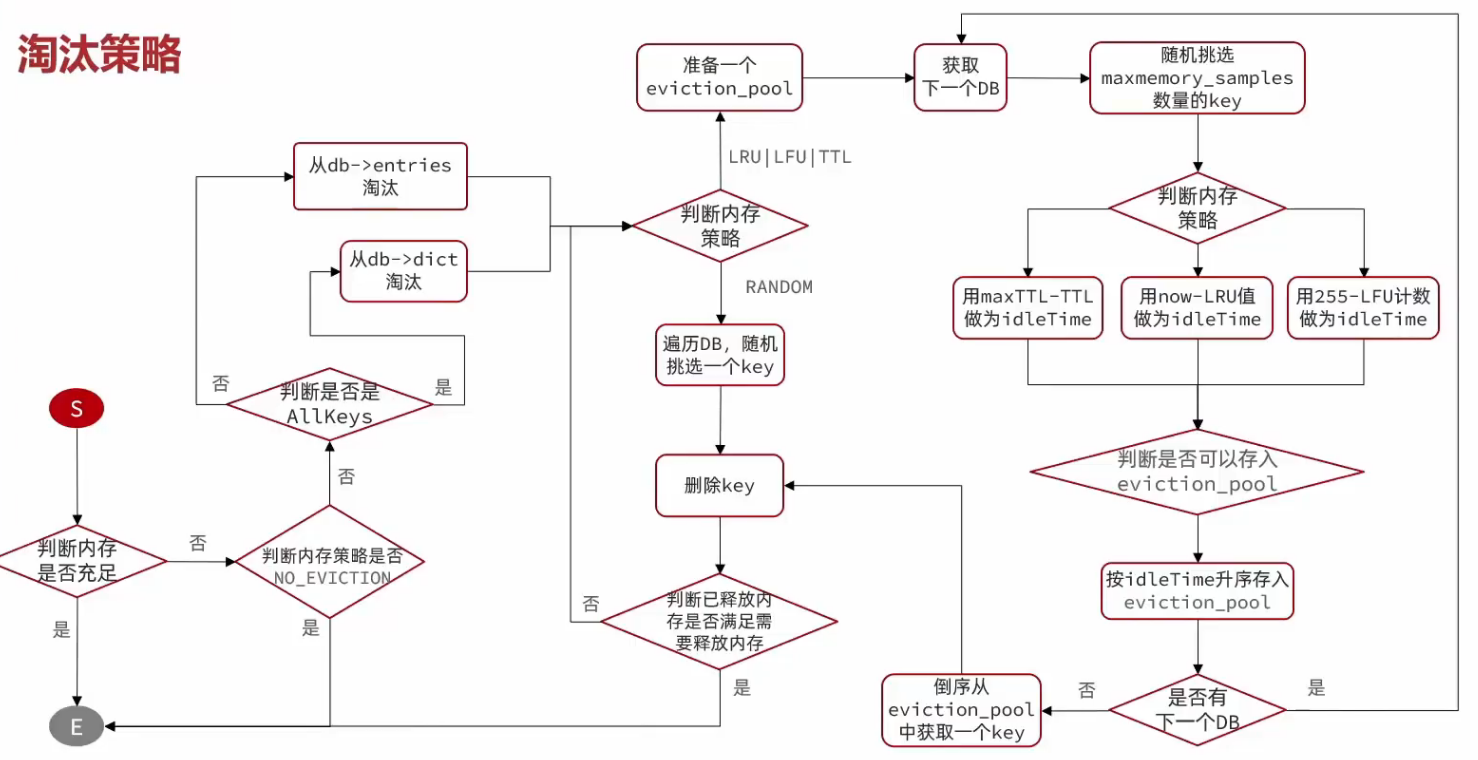
1. 内存充足判断
先检查 Redis 当前内存是否充足,若充足则无需淘汰,直接结束流程(对应流程图起始判断 "判断内存是否充足" )。
2. 非淘汰策略处理
若内存不足,判断内存策略是否为NO_EVICTION(不淘汰策略 ),若是则不执行淘汰,流程终止(对应 "判断内存策略是否 NO_EVICTION" )。
3. 淘汰范围判定
根据策略判断是从db->entries还是db->dict淘汰,通过 "判断是否是 AllKeys" 决定:若是AllKeys策略,从全量 key 里选;否则仅从设置过期的 key 里选(对应 "判断是否是 AllKeys" 分支 )。
4. 策略分支选择
- RANDOM(随机淘汰):无需复杂计算,直接遍历当前 DB,随机挑选 1 个 key 执行删除。逻辑简单,适合对 "淘汰精准度" 要求低的场景,但可能误删重要 key。
- LRU/LFU/TTL(精准淘汰) :需借助
eviction_pool(淘汰池 )实现 "按优先级排序淘汰",流程更复杂但能精准筛选 "最该淘汰的 key"。
5. 淘汰池(eviction_pool)初始化
- 遍历 DB :按配置的
maxmemory-samples(默认 5 )数量,从当前 DB 中随机抽样 key(抽样避免全量遍历,平衡性能与精准度 )。 - 填充淘汰池 :为每个抽样 key 计算 "闲置优先级"(如 LRU 的闲置时间、LFU 的访问频率、TTL 的剩余过期时间 ),按优先级排序存入
eviction_pool。
6. idleTime 计算
根据不同策略计算 key 的 "闲置时间(idleTime)":
- TTL 策略 :
idleTime = maxTTL - TTL(maxTTL是抽样 key 中的最大 TTL,差值越大,key 越 "早该过期",优先级越高 )。 - LRU 策略 :
idleTime = 当前时间 - LRU 时间戳(差值越大,key 越久未被访问,优先级越高 )。 - LFU 策略 :
idleTime = 255 - LFU 计数(计数越小,访问频率越低,优先级越高 )。
7. 淘汰池填充与排序
eviction_pool 按 idleTime升序存储(闲置时间越长,排越前 ),便于优先淘汰 "最该淘汰" 的 key。同时,会判断是否有下一个 DB 需处理,若有则循环填充淘汰池,覆盖所有 DB 的抽样 key。
8. 淘汰执行与循环
从 eviction_pool倒序取 key(取闲置最久的 )执行删除,释放内存后:
- 检查已释放内存是否满足
maxmemory要求,若满足则流程结束。 - 若不满足,继续从淘汰池取 key 淘汰,或循环处理下一个 DB,直到内存达标。