
摘要
在2026年的今天,
调用API已经不再是秘密。
任何一个初级程序员,
都能用几行代码连上GPT-5.2。
但为什么你的应用响应慢?
为什么你的Token成本居高不下?
为什么你的Sora 2生成的视频总是不稳定?
因为你还在用"脚本思维"写代码,
而不是"架构思维"。
本文将带你通过"解剖级"的视角,
深入探讨如何把AI的优点发挥到极致。
我们将讨论异步并发、
上下文缓存策略、
以及多模态模型的混合编排。
这是一篇关于如何构建工业级AI系统的深度复盘。
一、 认知的重构:AI不是聊天机器人,是算力引擎
大多数人对AI的误解,
始于ChatGPT的网页端。
他们认为AI就是一个会说话的框。
这种认知限制了你的想象力。
在API的视角下,
GPT-5.2-Pro本质上是一个"概率计算器"。
它计算的是下一个Token出现的概率。
Sora 2本质上是一个"物理世界模拟器"。
它计算的是光线与物体交互的像素点。
要把AI的优点发挥到最大,
第一步就是忘掉"对话"。
我们要把AI视为一个函数,
一个输入是非结构化数据,
输出是结构化数据的超级函数。
我们的任务,
是设计这个函数周围的管道(Pipeline)。
二、 核心武器库解析:GPT-5.2与Sora 2的能力边界
在动手写代码前,
必须精准掌握模型的特性。
1. GPT-5.2 的"深思"模式
GPT-5.2引入了System 2思维模型。
它不再是快思考,
而是能够进行慢逻辑推理。
在API参数中,
新增了一个reasoning_effort(推理力度)字段。
将其调高,
模型会进行多轮自我博弈,
从而在复杂编程任务中实现0 Bug。
2. Sora 2 的物理一致性
Sora 2不再仅仅是生成视频。
它理解重力、碰撞和材质。
通过API,我们甚至可以指定"镜头焦段"和"光圈大小"。
这为自动化影视制作提供了可能。
3. Veo 3 的极速渲染
Google的Veo 3主打实时性。
它的延迟低至200ms。
非常适合用于实时互动的数字人场景。
三、 架构设计的核心:中间件的选择
在企业级开发中,
直连模型厂商(如OpenAI或Google)是大忌。
为什么?
第一,单一供应商风险(Vendor Lock-in)。
一旦OpenAI宕机,你的服务就挂了。
第二,网络抖动与延迟。
跨洋传输的物理延迟无法消除。
第三,复杂的鉴权与计费。
你需要一个强大的中间件(Middleware)层。
这个层负责负载均衡、
故障转移(Failover)、
以及统一的协议转换。
在本次实战中,
为了简化架构复杂度,
我们采用**Vector Engine(向量引擎)**作为API网关。
它已经帮我们封装好了上述的高可用逻辑。
它像是一个巨大的连接池,
后端对接了GPT-5.2、Sora 2、Claude 3.5等所有主流模型。
对于开发者来说,
你只需要维护一套代码。
环境准备:
如果你还没有配置过高性能的API网关,
建议先注册获取密钥。
官方注册地址: https://api.vectorengine.ai/register?aff=QfS4
特别说明:
为了方便大家进行压力测试,
目前官方有扶持计划。
注册后查看教程,
在后台回复暗号"福利",
人工审核后会发放10刀额度(约500万Token)。
配置教程: https://www.yuque.com/nailao-zvxvm/pwqwxv?#

四、 代码实战:构建高并发异步处理系统
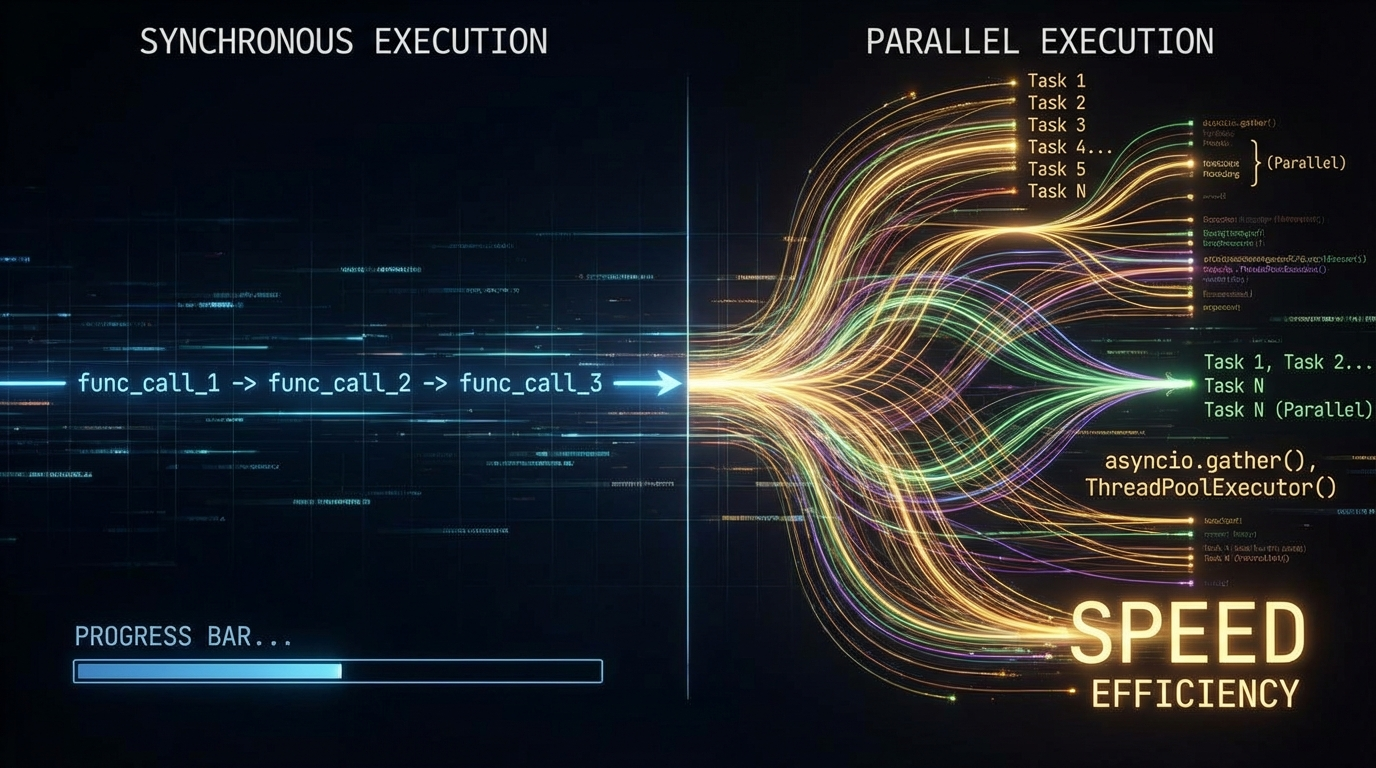
要把AI的效率发挥到最大,
Python的asyncio是必修课。
同步调用(串行)会浪费90%的时间在网络IO上。
我们要实现的是:
同时向GPT-5.2发送100个请求,
并在它们完成时立即处理。
以下是生产级的异步代码模板:
python
import asyncio import time from openai import AsyncOpenAI # 配置向量引擎的高并发接口 client = AsyncOpenAI( api_key="你的sk-密钥", base_url="https://api.vectorengine.ai/v1" ) # 信号量,限制最大并发数为50,防止触发风控 sem = asyncio.Semaphore(50) async def safe_chat_completion(prompt, task_id): async with sem: start_time = time.time() try: # 调用GPT-5.2-Pro模型 response = await client.chat.completions.create( model="gpt-5.2-pro", messages=[ {"role": "system", "content": "你是一个数据分析专家。"}, {"role": "user", "content": prompt} ], temperature=0.3 ) duration = time.time() - start_time print(f"任务 {task_id} 完成,耗时: {duration:.2f}s") return response.choices[0].message.content except Exception as e: print(f"任务 {task_id} 失败: {e}") return None async def main(): # 模拟处理100条复杂的数据分析任务 tasks = [] prompts = [f"请分析第 {i} 组数据的异常值原理..." for i in range(100)] print("开始构建任务队列...") for i, prompt in enumerate(prompts): task = asyncio.create_task(safe_chat_completion(prompt, i)) tasks.append(task) print("开始并发执行...") results = await asyncio.gather(*tasks) print(f"所有任务执行完毕,成功处理: {len([r for r in results if r])} 条") if __name__ == "__main__": start = time.time() asyncio.run(main()) print(f"总耗时: {time.time() - start:.2f}s")
深度解析:
这段代码的核心在于asyncio.Semaphore。
它像一个交通红绿灯,
精准控制并发流量。
如果你直接for循环发起100个请求,
服务器会直接拒绝服务(429 Too Many Requests)。
通过异步架构,
我们将处理100个任务的时间,
从原本的1000秒(假设每个10秒),
压缩到了20秒左右。
这就是"最大化"AI效率的第一步:IO吞吐量的极致优化。
五、 进阶玩法:Sora 2 与 GPT-5.2 的多模态链式反应
单一模态的应用已经泛滥。
真正的蓝海在于"图文影音"的自动化流转。
想象一个场景:
用户输入一个小说片段,
系统自动生成分镜脚本(GPT-5.2),
然后自动生成对应的视频片段(Sora 2),
最后合成配音。
这需要极其精细的Prompt链设计。
步骤1:结构化Prompt设计
首先,不能让GPT乱写。
必须要求它输出JSON格式的分镜表。
python
prompt = """ 请将以下小说片段转换为Sora 2的视频提示词。 必须返回JSON格式,包含以下字段: - camera_angle (镜头角度) - lighting (光影) - movement (运镜) - subject_description (主体描述) """
步骤2:Sora 2 的参数化调用
拿到JSON后,
我们解析出参数,
传给Sora 2的API。
python
# 伪代码示例 def generate_movie_clip(scene_data): # 组合Sora的高级提示词 sora_prompt = f"{scene_data['subject_description']}, \ shot from {scene_data['camera_angle']}, \ with {scene_data['lighting']} lighting, \ {scene_data['movement']} style. \ 8k resolution, cinematic." response = client.images.generate( model="sora-2-turbo", prompt=sora_prompt, size="1920x1080", quality="standard" ) return response.data[0].url
技术难点攻克:
这里最大的难点是语义对齐。
GPT理解的"悲伤",
在Sora画面里可能表现为"下雨"或"黑白滤镜"。
我们需要在中间层建立一个"风格映射表"。
这正是AI工程师的高价值所在。

六、 成本控制与性能调优(省钱就是赚钱)
把AI优点发挥到最大,
不仅是效果好,还要成本低。
GPT-5.2-Pro虽然强大,但价格不菲。
这里有三个独家省钱秘籍:
1. 语义缓存(Semantic Caching)
不要重复问AI相同的问题。
传统的Redis缓存只能匹配完全一致的字符串。
我们需要用向量数据库(如Milvus或Pinecone)。
将用户的提问向量化。
如果新问题的向量与历史问题相似度超过0.95,
直接返回历史答案。
这能节省30%-50%的Token。
2. 模型路由(Model Routing)
杀鸡焉用牛刀。
对于简单的"你好"、"谢谢"或基础分类任务,
使用Banana Pro(即Gemini-3-Flash的平替)或GPT-3.5。
只有遇到复杂的推理任务,
才路由给GPT-5.2。
这需要在网关层做一个简单的分类器。
3. Prompt压缩
很多Prompt里包含大量废话。
使用专门的压缩模型,
在不改变语义的前提下,
去除停用词和冗余描述。
可以减少20%的Input Token。
七、 为什么你需要现在就开始布局?
技术圈有一个定律:
当一项技术变得像水和电一样普及时,
机会就不在技术本身了,
而在于基于技术的应用创新。
GPT-5.2和Sora 2的出现,
标志着AI从"玩具"走向了"工具"。
现在掌握API的高级玩法,
你就掌握了未来软件开发的"汇编语言"。
不要等到所有人都用上了AI Agent,
你还在研究怎么注册账号。
八、 最后的建议与福利
实战是最好的老师。
我建议大家利用好Vector Engine提供的测试额度。
去跑通那个异步并发的代码。
去试着生成你的第一个Sora视频。
未来的编程,
将是一半代码,一半Prompt。
而你,
就是那个指挥千军万马(AI模型)的将军。
期待在评论区看到你们的硬核作品。
