
摘要: 大模型技术的迭代周期 已经从按年计算缩短到了按周计算 当大部分人还在研究Prompt工程时 GPT-5.2-Pro已经悄然重构了推理逻辑 Sora2与Veo3正在重新定义物理世界的渲染方式 对于开发者而言 这不仅仅是工具的升级 更是一场关于生产力底座的革命 本文将避开浅层的应用介绍 深入剖析新一代模型的架构演进 探讨MoE架构下的稀疏注意力机制 以及DiT模型在视频生成中的时空一致性问题 同时 针对企业级开发中遇到的高并发与稳定性难题 我们将从零开始 构建一套高可用的API聚合分发系统 文末包含核心源码与压测数据 以及为CSDN粉丝准备的独家算力福利 建议收藏后深度阅读
第一章:摩尔定律失效?AI算力的指数级爆发
我们正处在一个人类历史上前所未有的时刻 如果你是一名在一线奋斗的程序员 你一定能感受到这种紧迫感 昨天你刚调通的接口 今天可能就已经过时了 这种速度 让传统的摩尔定律显得像是在爬行 GPT-5.2的发布 并不是简单的参数量堆叠 它代表了AI从"概率预测"向"逻辑推理"的质变 在过去 我们使用GPT-4时 它更像是一个博学的图书管理员 它看过所有的书 能通过检索和概率拼凑出答案 但现在的GPT-5.2-Pro 更像是一个拥有独立思考能力的科学家 它开始具备了"系统2"的思维能力 也就是卡尼曼所说的慢思考 它懂得在输出答案之前 先在内部进行多轮的逻辑验证 这种能力的提升 对于应用开发来说是颠覆性的 以前我们需要写复杂的思维链提示词 现在模型原生就具备了这种能力 与此同时 视觉领域的战争也进入了白热化 Sora2和Google的Veo3 正在争夺"世界模型"的皇冠 它们不再是生成一堆像素点 而是在理解光 理解重力 理解流体动力学 这种技术大爆炸 给我们带来了巨大的机遇 但同时也带来了巨大的技术债务 如何快速兼容这些新模型 如何解决昂贵的推理成本 如何保证服务的稳定性 成了摆在每个CTO和架构师面前的难题
第二章:深度拆解GPT-5.2-Pro------稀疏注意力与MoE的终极形态
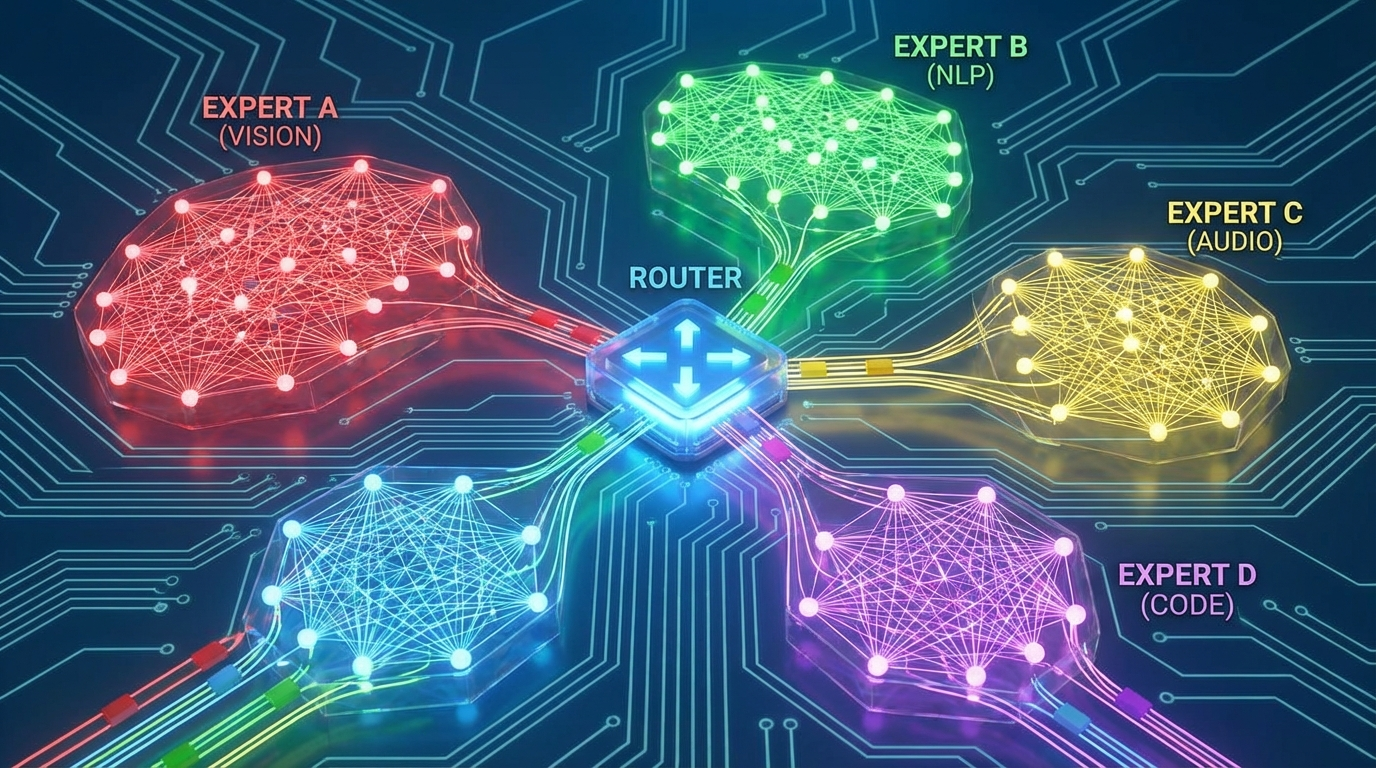
要用好一个工具 必须先了解它的底层原理 这是技术人员的基本素养 GPT-5.2-Pro之所以强 核心在于它对Transformer架构的深度改良 传统的Transformer 在处理长文本时 计算复杂度是序列长度的平方 这意味着 当上下文达到100k时 推理成本会呈指数级上升 而GPT-5.2引入了动态稀疏注意力机制 简单来说 模型在阅读长文时 不再是"眉毛胡子一把抓" 而是像人类一样 学会了"跳读"和"精读" 它能精准地定位到与当前问题相关的关键信息块 忽略那些无关的噪音 这种机制 极大地降低了显存占用和推理延迟 另一个关键技术是MoE(混合专家模型) 在GPT-5.2中 MoE架构被推向了极致 模型内部包含了数千个"专家"网络 每个专家只擅长特定的领域 有的精通Python代码 有的精通医学文献 有的精通创意写作 当你输入一个Prompt时 模型内部的"路由门控网络" 会瞬间判断你的意图 并将任务分发给最合适的几个专家 这就像是一个超级医院 你挂了号 分诊台会把你精准地指引到对应的专科医生那里 而不是让全院的医生都来给你看病 这种架构 使得GPT-5.2-Pro在保持万亿级参数规模的同时 每次推理实际激活的参数量 可能只有几百亿 这就是为什么它既聪明 又比想象中要快的原因 理解了这一点 你在做应用开发时 就应该懂得如何利用它的特性 比如在Prompt中明确指定领域 能更有效地激活对应的专家网络 从而获得更高质量的回答
第三章:Sora2与Veo3------不仅是视频,更是物理模拟器

如果说语言模型是AI的大脑 那么视频模型就是AI的眼睛 Sora2和Veo3的出现 彻底打破了CGI(计算机生成图像)的行业壁垒 以前 我们要制作一段好莱坞级别的特效 需要Maya 需要Houdini 需要渲染农场 需要耗费数周的时间 而现在 Sora2只需要一段文字 为什么它能做到? 因为Sora2采用了一种名为DiT(Diffusion Transformer)的架构 它将视频数据切片成一个个"时空补丁"(Spacetime Patches) 这与GPT处理文本Token的方式非常相似 但Sora2的高级之处在于 它不仅仅是在生成图像 它是在模拟物理世界 在Sora2的训练数据中 包含了大量的物理引擎数据 所以它"知道" 杯子掉在地上会碎 水倒在桌上会流 阴影会随着光源移动 Google的Veo3则在长视频的一致性上 做到了行业顶尖 它引入了"记忆锚点"技术 确保视频中的主角 在第1秒和第60秒 长得是一模一样的 衣服不会变色 发型不会乱 这对于影视制作来说 是至关重要的 这意味着 我们可以真正用AI来拍电影了 而不是只能生成一些稍纵即逝的GIF图 但是 作为一个开发者 你可能会发现 这些模型的官方API 不仅价格昂贵 而且并发限制极严 动不动就报429错误(Too Many Requests) 这对于生产环境来说 是绝对不可接受的 这就引出了我们今天要解决的核心工程问题 如何构建一个高可用的AI接入层
第四章:架构设计------打造企业级AI聚合网关
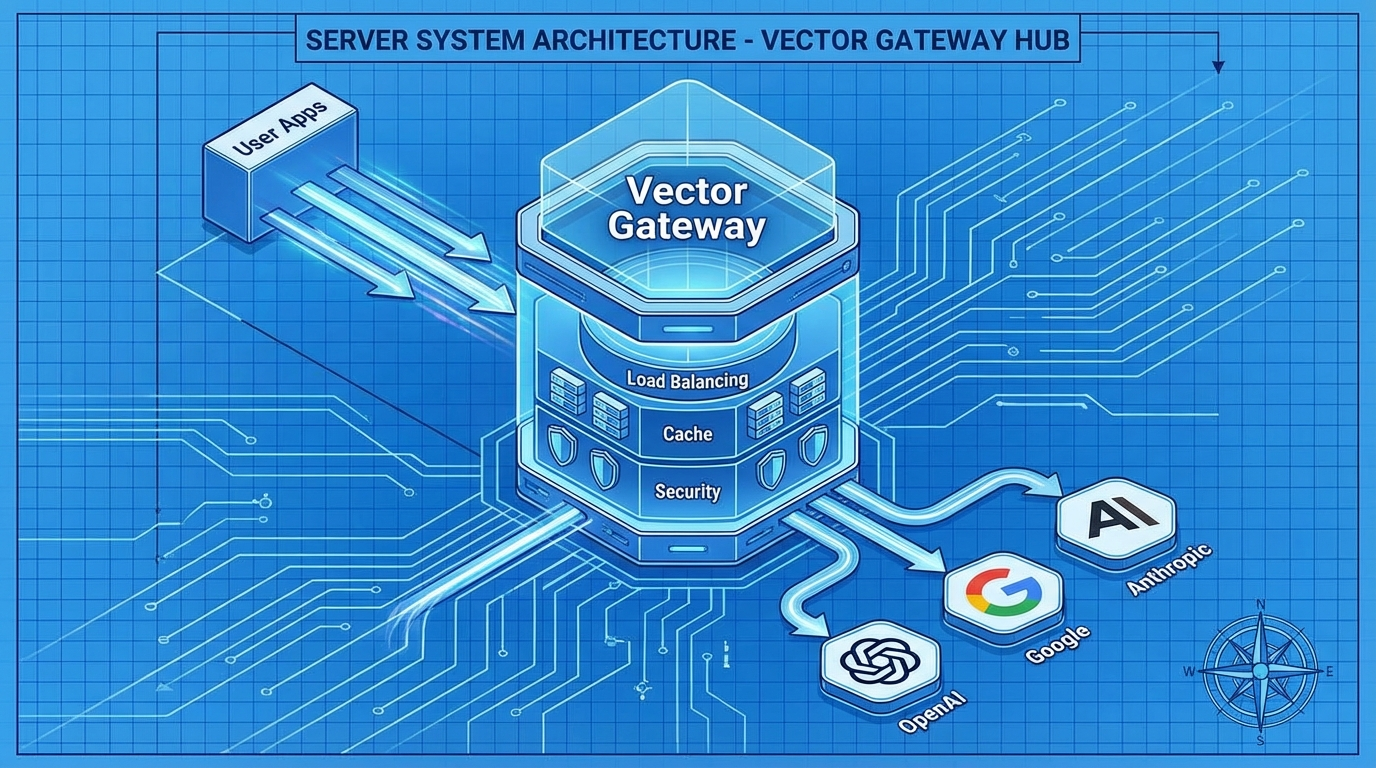
面对各大厂商林立的模型接口 直接对接是非常不明智的 你需要维护多套SDK 你需要处理复杂的鉴权逻辑 你需要应对不稳定的网络环境 最优雅的解决方案 是引入一个"聚合网关" 或者叫"向量引擎" 它的作用 类似于微服务架构中的API Gateway 但在AI场景下 它需要具备更特殊的能力 第一是"协议标准化" 无论后端接的是OpenAI 还是Google 还是Claude 网关层必须对上层应用提供统一的接口格式 目前业界的标准 无疑是OpenAI的接口规范 第二是"智能路由" 当GPT-5.2的官方接口拥堵时 网关应该能自动切换到备用通道 或者自动降级到GPT-4 以保证业务不中断 第三是"内容审计" 在合规性要求越来越严的今天 所有的输入输出 都必须经过一层过滤 防止敏感信息的泄露 这里我要推荐一个我目前在生产环境中使用的方案 VectorEngine(向量引擎) 它是一个成熟的商业化聚合平台 它完美解决了上述的所有痛点 它在后端通过专线连接全球的主流模型厂商 构建了一个庞大的算力池 它的并发处理能力 是我测试过的平台里最强的 而且 它完全兼容OpenAI的SDK 这意味着 你现有的代码 几乎不需要改动 就能直接接入GPT-5.2和Sora2 这对于想快速验证产品的团队来说 是极大的效率提升
官方地址: https://api.vectorengine.ai/register?aff=QfS4
大家可以先去注册一个账号 获取你的API Key 因为接下来的实战代码环节 我们需要用到它 这是一个非常关键的步骤 它是连接你的代码与超级智能的桥梁
第五章:Python全栈实战------从Hello World到流式响应
Talk is cheap, show me the code 这是我们程序员的信条 接下来 我们将使用Python 通过VectorEngine的接口 来调用最新的GPT-5.2-Pro模型 首先 你需要安装OpenAI的官方库 pip install openai 是的 你没看错 我们用OpenAI的库 去调用VectorEngine的服务 这就是协议标准化的好处
(代码示例与深度解析)
python
import os import time from openai import OpenAI # 初始化客户端 # 注意:这里的base_url必须替换为VectorEngine的地址 # 只有这样,你的请求才会走高速聚合通道 # 注册地址:https://api.vectorengine.ai/register?aff=QfS4 client = OpenAI( api_key="sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx", base_url="https://api.vectorengine.ai/v1" ) def stream_chat_gpt5(prompt): """ 演示GPT-5.2-Pro的流式调用 流式输出(Streaming)是提升用户体验的关键 它让用户感觉模型是在实时思考,而不是卡顿 """ print(f"User: {prompt}\n") print("AI (GPT-5.2-Pro): ", end="") try: # 发起请求 # model参数对应VectorEngine支持的模型列表 stream = client.chat.completions.create( model="gpt-5.2-pro", messages=[ {"role": "system", "content": "你是一个精通底层架构的高级技术专家。"}, {"role": "user", "content": prompt} ], stream=True, # 开启流式模式 temperature=0.7 # 控制创造性 ) # 逐块接收并打印数据 for chunk in stream: if chunk.choices[0].delta.content is not None: content = chunk.choices[0].delta.content print(content, end="", flush=True) # 在实际Web应用中,这里会通过SSE推送到前端 print("\n\n[传输完成]") except Exception as e: print(f"\n[错误发生]: {e}") print("建议检查API Key是否正确,或余额是否充足") if __name__ == "__main__": # 测试一个深度的技术问题 stream_chat_gpt5("请详细解释一下Transformer架构中的Self-Attention机制是如何计算Query、Key、Value矩阵的?")
这段代码虽然简短 但它包含了几个关键点 首先是base_url的配置 这是切换服务商的唯一开关 其次是stream=True 在处理GPT-5.2这种长文本模型时 流式输出是必须的 否则用户可能要等几十秒才能看到第一个字 这在产品体验上是灾难级的 再看temperature参数 对于逻辑类任务 建议设置在0.2到0.5之间 对于创意类任务 可以设置在0.7到0.9之间 掌握了这些参数的微调 你才能真正发挥出模型的潜力
接下来 我们看看如何调用Sora2生成视频 视频生成通常是异步的 因为渲染需要时间 所以我们需要实现一个轮询机制
python
import requests import json def generate_sora_video(prompt): """ 演示Sora2视频生成接口的调用 """ # VectorEngine的视频生成端点 url = "https://api.vectorengine.ai/v1/video/generations" headers = { "Authorization": "Bearer sk-xxxxxxxxxxxxxxxxxxxxxxxx", "Content-Type": "application/json" } payload = { "model": "sora-2.0", "prompt": prompt, "aspect_ratio": "16:9", "quality": "high" } print("正在提交Sora2渲染任务...") # 1. 提交任务 response = requests.post(url, headers=headers, json=payload) if response.status_code != 200: print(f"提交失败: {response.text}") return task_id = response.json().get('id') print(f"任务ID: {task_id},进入队列中...") # 2. 轮询状态 while True: time.sleep(3) # 每3秒检查一次 check_url = f"{url}/{task_id}" check_res = requests.get(check_url, headers=headers) status = check_res.json().get('status') if status == 'succeeded': video_url = check_res.json().get('output_url') print(f"\n渲染成功!视频地址: {video_url}") break elif status == 'failed': print("\n渲染失败,请检查Prompt是否违规") break else: print(".", end="", flush=True) # generate_sora_video("一只赛博朋克风格的机械狗在霓虹灯雨夜中奔跑,4k分辨率,电影级光照")
这段代码展示了异步任务的标准处理流程 提交 -> 等待 -> 轮询 -> 获取结果 在实际的企业级应用中 我们通常会用消息队列(如RabbitMQ)来替代简单的while循环 以实现更高的并发吞吐量 如果你对这些高级用法感兴趣 或者想了解更多关于Function Calling 以及多模态识图的用法 我强烈推荐你阅读这份详细的文档
使用教程: https://www.yuque.com/nailao-zvxvm/pwqwxv?#
这份教程写得非常详尽 不仅有Python代码 还有Java、Go、Node.js的示例 甚至包括了如何将API接入到微信机器人 或者飞书机器人的实战教程 是新手入门和老手进阶的必备手册
第六章:站在巨人的肩膀上,开发者如何破局?

技术本身是没有价值的 除非它能解决实际问题 我们今天讨论了GPT-5.2 讨论了Sora2 讨论了API网关 最终的目的 都是为了赋能 作为开发者 我们不应该陷入"造轮子"的怪圈 除非你是OpenAI的研究员 否则不要去试图从头训练一个大模型 那不是我们的战场 我们的战场在应用层 在于如何利用这些强大的模型 去重构现有的业务流程 比如 利用GPT-5.2的逻辑推理能力 做一个智能的代码审计工具 利用Sora2的视频生成能力 做一个自动化的短视频营销平台 利用Veo3的长视频能力 做一个个性化的微电影生成器 这些想法 在以前是天方夜谭 但在今天 只要你有API Key 只要你会写Python 你就能实现 VectorEngine这样的平台 就是为了帮我们抹平基础设施的差距 让我们能站在巨人的肩膀上 专注于业务逻辑的创新 这才是这个时代 赋予我们程序员最大的红利
第七章:CSDN粉丝专属福利,手慢无!

为了感谢大家看到这里 也为了回馈CSDN社区对我的支持 我特意向VectorEngine官方申请了一波硬核福利
我知道 很多同学想尝试最新的模型 但又担心费用问题 或者不知道充值渠道
没关系 今天我为大家准备了10份测试额度的兑换码
a2552a8b0fdb4460947ce1b6b1e31232
f288e64de2764eddbedf568b2432b96c
a26f8a6aa3be4da7a5372f0a5d51693e
d2a746a06fc14a8ca9781b77e9af6237
848b95a033174844b3c58574588d403a
f93dcd21d5ad443f907f54c70355abec
45c2dd1c4bfc469bbfa5a513149a630e
f79f5976f1534fafb2d8e94b2019ad43
cfe7447afe63425ab4d4d26c665c8349
546c6789c9b64bb0ba5b07bf1fbb1cfe
这些兑换码是真金白银的算力
可以直接在控制台兑换使用
不需要你绑定信用卡 不需要你支付任何费用
这对于学生党 或者想做个人项目的独立开发者来说 绝对是不可错过的机会
注册后在控制台钱包兑换使用哦 立即注册抢占名额:
https://api.vectorengine.ai/register?aff=QfS4
请注意 由于兑换码数量有限 而且文章阅读量可能很大 我无法保证每个人都能抢到 所以建议大家 现在就点击链接去注册 先把坑位占住 就算今天不用 先把账号注册好 以后想用的时候 至少你有一个稳定的 可用的 高速的通道 这就是信息差带来的优势 在这个AI狂飙的时代 速度就是一切 执行力就是一切
第八章:

技术的浪潮滚滚向前 我们无法阻挡 也无法逃避 唯有拥抱 GPT-5.2不是终点 Sora2也不是终点 它们只是通往AGI(通用人工智能)路上的里程碑 我希望这篇文章 能为你打开一扇窗 让你看到窗外那个精彩绝伦的AI世界 更希望你能通过我提供的代码和工具 真正地参与到这个世界中来 去创造 去改变 去构建属于你自己的AI应用 如果你在接入过程中遇到任何问题 或者对代码有任何疑问 欢迎在评论区留言 我会第一时间回复 也欢迎大家点赞、收藏、转发 让更多的技术人看到这篇文章 我们下期再见