本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。
随着企业级LLM应用复杂度提升,构建科学评估体系成为工程落地核心瓶颈。今天我将系统拆解多轮对话、RAG、智能体三类场景的评估方案,并对比主流框架的工程适配性,希望对各位有所帮助。
一、评估范式演进:从传统指标到系统化评估
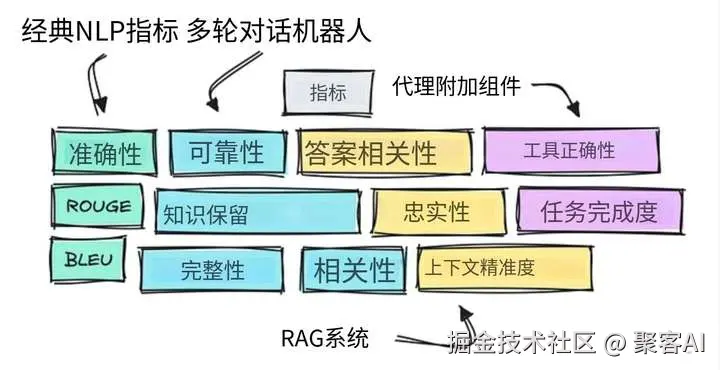
1.1 传统NLP指标的局限
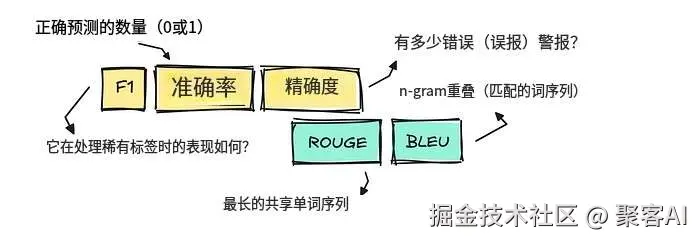
- 精确匹配型指标:准确率(Accuracy)、F1值在分类任务中仍有效,但依赖单标准答案
- 文本重叠型指标:BLEU/ROUGE适用于翻译、摘要等任务,但无法处理语义多样性
1.2 LLM基准测试的困境
- MMLU/GPQA等公共数据集存在过拟合风险
- 编码类测试(HumanEval)通过单元测试验证,但覆盖场景有限
1.3 新一代评估范式
- LLM-as-Judge:用大模型评估输出质量(如MT-Bench)
- 系统化评估:从单纯模型测试转向全链路验证(检索→推理→输出)
二、三大应用场景评估指标体系
2.1 多轮对话系统
| 评估维度 | 核心指标 | 检测方法 |
|---|---|---|
| 会话质量 | 相关性(Relevancy) | LLM评分器(0-1分) |
| 完整性(Completeness) | 用户目标达成率分析 | |
| 状态管理 | 知识保留(Retention) | 关键信息回溯验证 |
| 可靠性(Reliability) | 错误自我修正频次统计 | |
| 安全合规 | 幻觉率(Hallucination) | 声明拆解+事实核查 |
| 毒性/偏见(Toxicity) | 专用分类模型检测 |
2.2 RAG系统双阶段评估
✅检索阶段
传统IR指标:
- Precision@K:前K个结果的相关文档占比
- Recall@K:召回的相关文档比例
- Hit Rate@K:是否包含至少1个相关文档
无参考指标:
- 上下文精确率(Context Precision):LLM评估结果相关性
- 上下文召回率(Context Recall):关键信息覆盖度验证
✅生成阶段
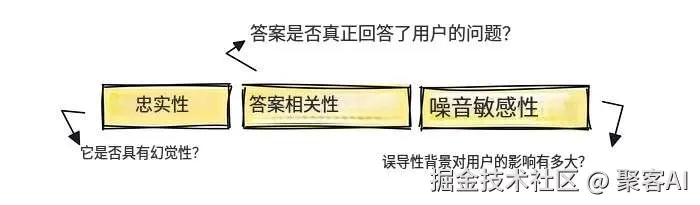
- 答案相关性(Answer Relevancy):LLM评估答案与问题匹配度
- 忠实度(Faithfulness):声明与上下文支持证据的对应关系
- 抗噪能力(Noise Sensitivity):注入无关信息时的稳定性
💡由于文章篇幅有限,关于RAG检索增强中更详细的技术点,我整理了一个文档,粉丝朋友自行领取:《RAG检索增强实践》
2.3 智能体系统扩展指标
任务完成度(Task Completion):
python
# 伪代码示例:基于轨迹的完成度评估
def evaluate_agent_trace(goal, execution_trace):
criteria = "目标达成度、步骤合理性、错误恢复能力"
return llm_judge(goal, trace, criteria)工具使用正确性(Tool Correctness):
- 工具选择准确率
- 参数填充正确率
执行效率:
- 平均推理步数(Step Efficiency)
- 任务耗时比(Time-Budget Ratio)
三、四大评估框架工程适配指南
| 框架 | 核心优势 | 适用场景 | 典型指标覆盖度 |
|---|---|---|---|
| RAGAS | 检索评估专项优化 | RAG系统快速验证 | 8项核心指标 |
| DeepEval | 40+开箱即用指标 | 企业级全链路监控 | ⭐⭐⭐⭐⭐ |
| MLFlow Evals | MLOps生态集成 | 已有MLFlow基建的团队 | ⭐⭐ |
| OpenAI Evals | 轻量级定制 | 基于OpenAI接口的简单测试 | ⭐ |
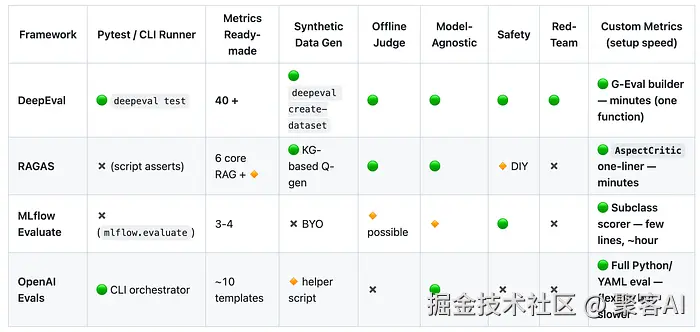
3.1 选型建议
- 初创验证阶段 → RAGAS(快速定位检索瓶颈)
- 生产环境部署 → DeepEval(定制指标+持续监控)
- 混合架构场景 → MLFlow(统一实验跟踪)
3.2 实施关键步骤
构建黄金数据集:
ini
# 使用合成数据增强
from ragas.testset import TestsetGenerator
generator = TestsetGenerator(llm, embeddings)
testset = generator.generate(documents, num_questions=100)配置自动化流水线:
yaml
# DeepEval 配置示例
metrics:
- name: faithfulness
threshold: 0.85
- name: answer_relevancy
threshold: 0.9设置波动告警:指标变化>15%时触发人工审核
四、 企业实际落地难点
- LLM评判可靠性:需20%样本人工验证
- 指标冲突:如忠实度提升导致相关性下降
- 持续迭代:评估体系随业务目标动态调整
最佳实践:
采用分层评估策略 基础层(天级):自动化指标测试 监控层(实时):用户负反馈捕获 审计层(周级):人工深度Case分析
笔者结语:评估体系需与业务目标强对齐,建议从RAGAS基础指标起步,逐步扩展至DeepEval全链路监控。技术团队应建立"评估即代码"(Evaluation-as-Code)理念,将评估流水线纳入CI/CD核心环节。