(1)表的创建
sql
create table table_name (
field1 datatype,
field2 datatype,
field3 datatype
) character set 字符集 collate 校验规则 engine 存储引擎;
--field 表示列名
--datatype 表示列的类型
--character set 字符集,如果没有指定字符集,则以所在数据库的字符集为准
--collate 校验规则,如果没有指定校验规则,则以所在数据库的排序规则为准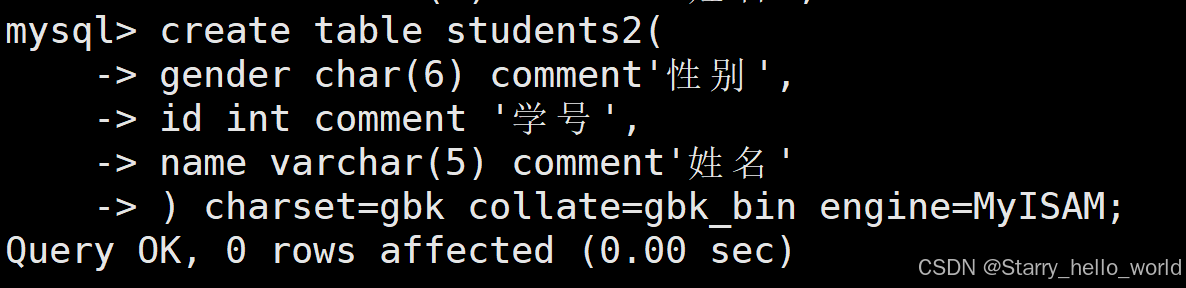
当然这个地方我们不显示写字符集 排序规则 存储引擎 也会生成环境下默认的
MySQL 建表语句中,comment 用于为表或字段添加说明性文字,起到注释说明的作用。
当然也是可以不加的
MySQL 的存储引擎是决定表如何存储和处理数据的底层技术实现,相当于表的 "数据处理器"。
作用: 定义数据的存储格式、索引方式 决定事务支持、锁机制等特性 影响读写性能和数据可靠性
不同
不同存储引擎创建出来的表在linux下的文件个数和数量都不一样
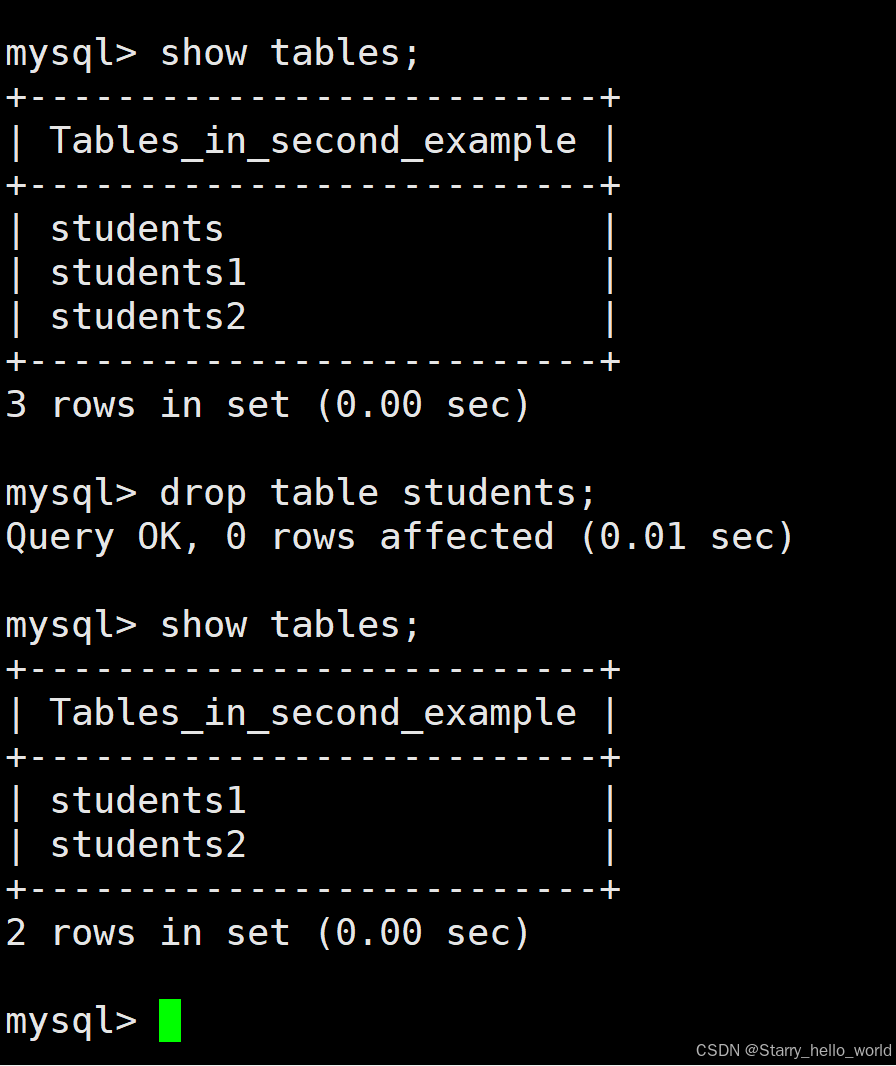
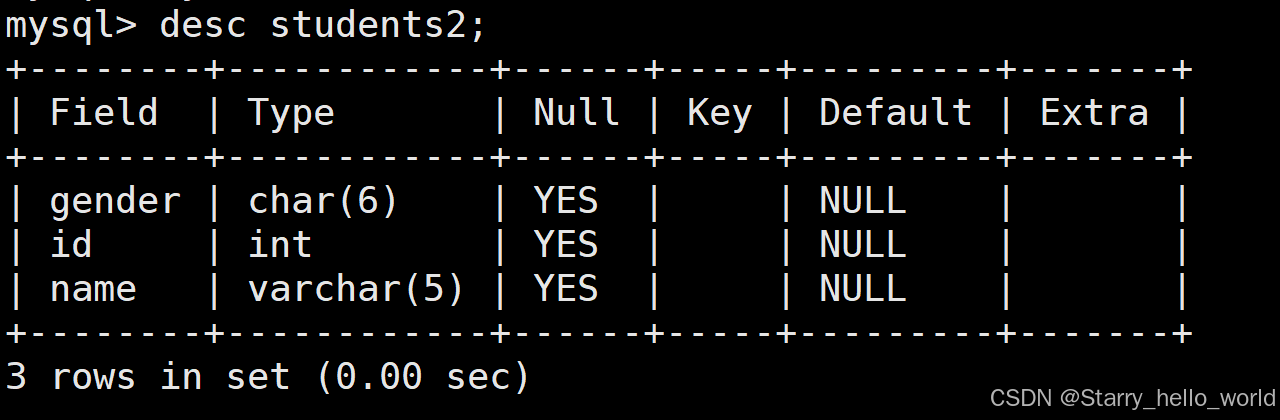
(2)查看表的结构/内容
sql
desc table_name;比如这个地方我们就可以查看原先创建的students2这个表
查看表的内容
sql
select*from table_name;
(3)表的插入
sql
insert into 表名 (字段1, 字段2, ...) values (值1, 值2, ...);
--如果插入的字段顺序与表定义的字段顺序完全一致,可以省略字段列表:
insert into 表名 students values (值1, 值2,...);
--不过建议保留字段列表,这样更清晰且能避免字段顺序变化导致的错误。
--当需要插入多条记录时,不必编写多个 INSERT 语句,可使用批量插入语法,效率更高:
insert into 表名 (字段1, 字段2, ...)
values
(值1, 值2, ...),
(值1, 值2, ...),
(值1, 值2, ...);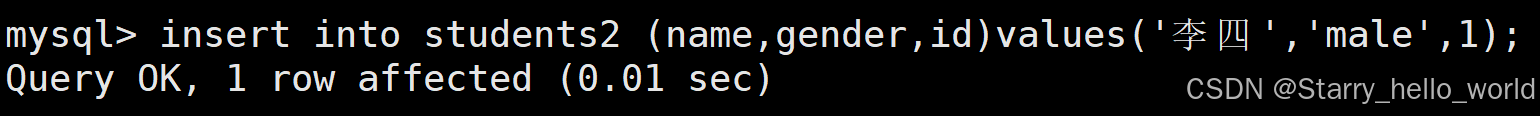



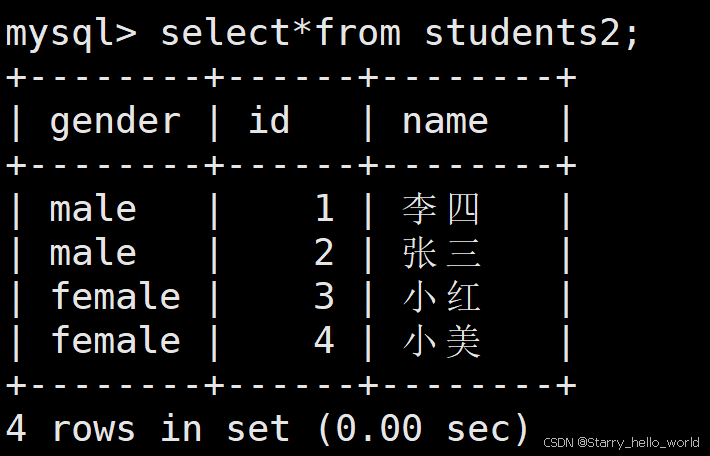
我们来看看我们插入的结果
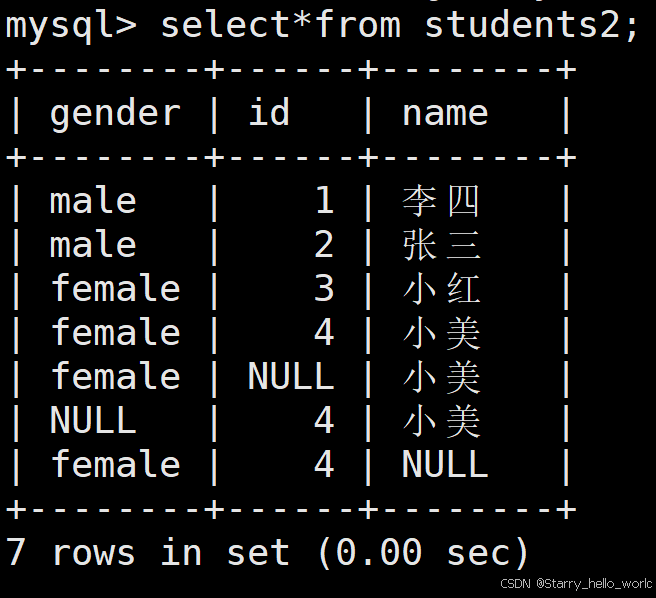
我们再来看看下面这些插入



sql
show tables; --查看库里面有哪些表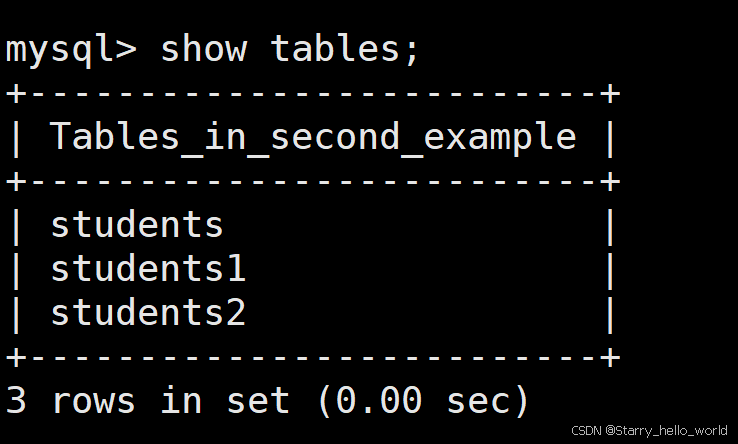
(4)表的修改
sql
--删除字段
alter 表名 drop 字段名;
-- 添加单个字段
alter table 表名 add 字段名 数据类型 [约束条件] [first|after 已有字段名];
-- 同时添加多个字段
alter table 表名
add 字段1 数据类型 [约束],
add 字段2 数据类型 [约束];
--修改字段
alter table 表名 modify 字段名 新数据类型 [新约束条件]
--修改表名
alter table 原表名 rename to 新表名; --这里的to可以省略

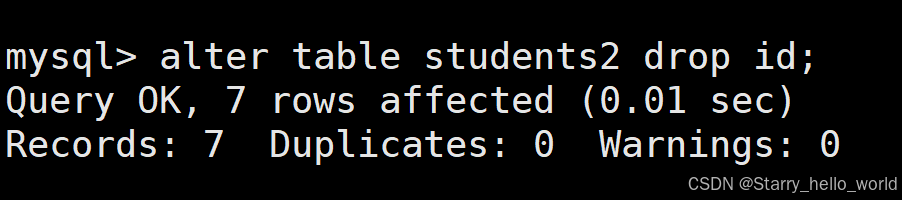
我们来看修改完成后的结果
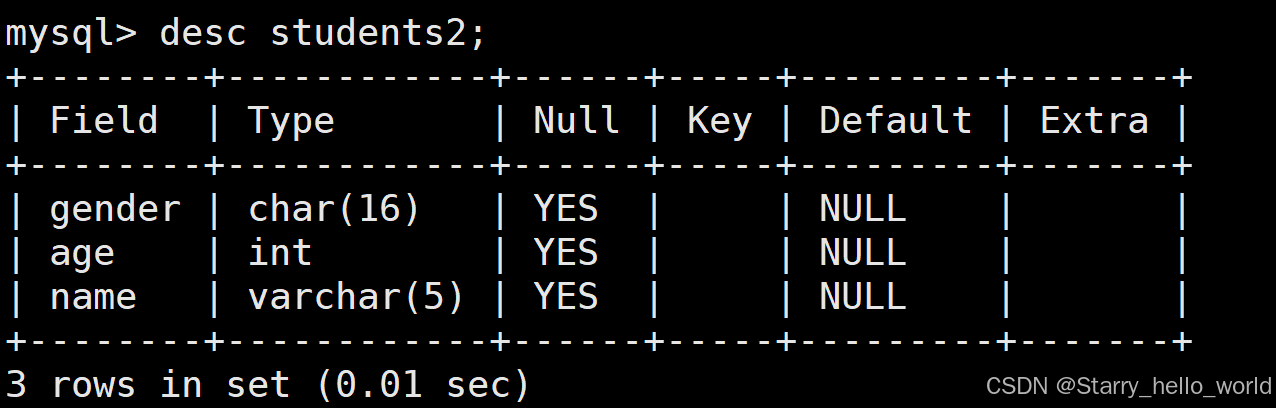
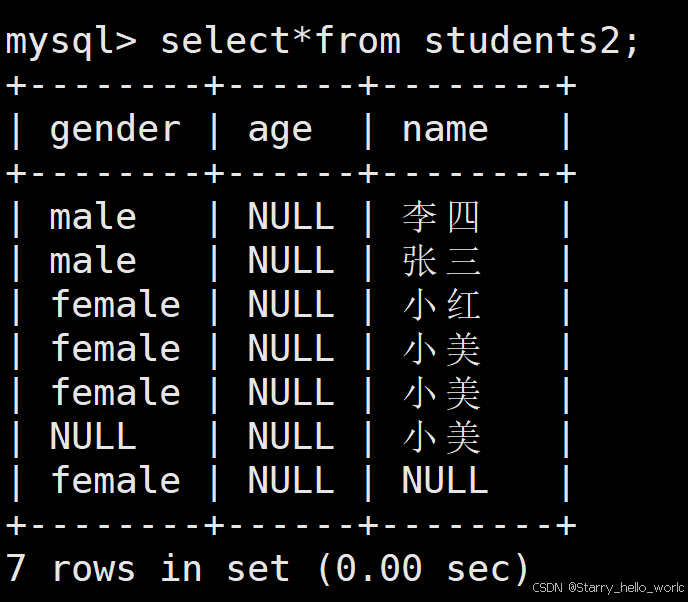
添加新的字段 原先数据的该字段部分为NULL
我们可以成功看到我们把原本的students2这个表的名字改成了students3了
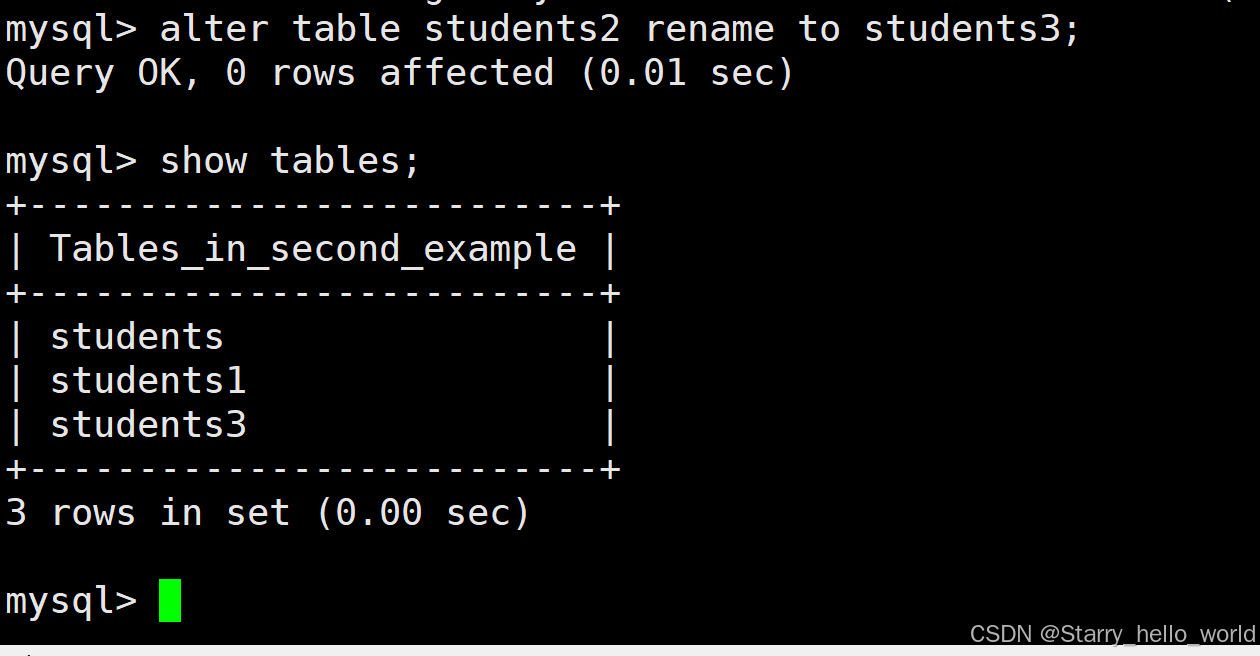
(5)删除表
sql
--删除表 删除表需谨慎 最好提前备份
--备份操作在库的操作文章那里
drop table 表名;