Titanic - Machine Learning from Disaster | Kaggle 题目
Titanic Data Science Solutions | Kaggle 参考题解
notebookbe6ed1ba33 | Kaggle 下面项目我在Kaggle上的呈现
Titanic数据集 主要任务是表格数据处理 给定train.csv数据 预测test.csv中乘客的生还情况。
每个乘客有是否生还的标签,以及Pclass、Age、Sex等11项信息,我们可以
-
先对表格特征做一些基本分析/可视化 有初步了解。
-
再进行数据清洗,把空缺数据、字符串数据转化为易于机器学习模型处理的数值数据。
-
最后尝试一些机器学习模型,进行模型评估与答案预测。
目录
[1. 数据分析](#1. 数据分析)
[2. 数据清洗](#2. 数据清洗)
[3. 模型调用与预测](#3. 模型调用与预测)
1. 数据分析
Pandas 中的导入为 DataFrame; 再用 .head() .info() .describe() 得到一些基本信息
python
import pandas as pd
#kaggle导入 复制右侧路径
train_df = pd.read_csv('/kaggle/input/titanic/train.csv')
test_df = pd.read_csv('/kaggle/input/titanic/test.csv')
print(train_df.columns.values) #列的种类
train_df.head() #前五个
train_df.tail() #后五个
train_df.info()
print('_'*40)
test_df.info() # 列名、非空值数量、数据类型、内存占用 信息
train_df.describe() # 数值型列的 描述性统计量
train_df.describe(include=['O']) # 非数值型列(object/字符串) 的描述性统计量对于每一列 分为每一类别 求平均存活率 再降序排列
python
train_df[['Pclass', 'Survived']].groupby(['Pclass'], as_index=False).mean().sort_values(by='Survived', ascending=False)
train_df[["Sex", "Survived"]].groupby(['Sex'], as_index=False).mean().sort_values(by='Survived', ascending=False)
train_df[["SibSp", "Survived"]].groupby(['SibSp'], as_index=False).mean().sort_values(by='Survived', ascending=False)
train_df[["Parch", "Survived"]].groupby(['Parch'], as_index=False).mean().sort_values(by='Survived', ascending=False)三种Pclass下 幸存/死亡 3*2种情况下的年龄分布图
三种Embarked下 不同性别在三种Pclass下的 幸存/死亡率图
python
# 两个变量
grid = sns.FacetGrid(train_df, col='Survived', row='Pclass', height=2.2, aspect=1.6)
grid.map(plt.hist, 'Age', alpha=.5, bins=20)
# 三个变量
grid = sns.FacetGrid(train_df, row='Embarked', height=2.2, aspect=1.6)
grid.map(sns.pointplot, 'Pclass', 'Survived', 'Sex', palette='deep')
grid.add_legend() #图例2. 数据清洗
一些字符串列 有的没作用 有的需要提取转换为数字形式
我们在describe中知道 Ticket是票的编号(对分类没有帮助)Cabin有很多缺失值 遂踢除
python
train_df = train_df.drop(['Ticket', 'Cabin', 'PassengerId'], axis=1)
test_df = test_df.drop(['Ticket', 'Cabin'], axis=1)
combine = [train_df, test_df]Name那列 只有中间的 Mr Miss 这样的中间的位置对分类有帮助 提取出来更换标签
python
for dataset in combine:
dataset['Title'] = dataset.Name.str.extract(' ([A-Za-z]+)\.', expand=False)
pd.crosstab(train_df['Title'], train_df['Sex'])把Title和Sex两两比对 可以分为Master Miss Mr Mrs 和 Rare 五类分别对应1~5
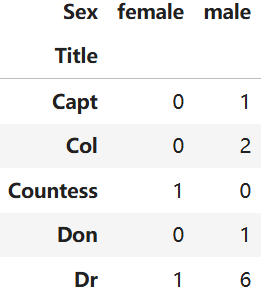
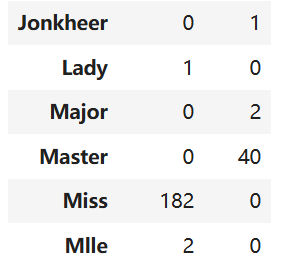
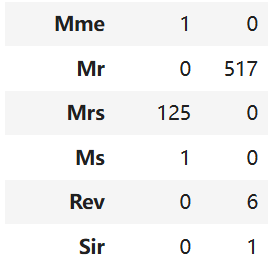
python
title_map = {
'Mr': 1,
'Miss': 2, 'Mlle': 2, 'Ms': 2,
'Mrs': 3, 'Mme': 3,
'Master': 4,
'Lady': 5, 'Countess': 5, 'Capt': 5, 'Col': 5, 'Don': 5,
'Dr': 5, 'Major': 5, 'Rev': 5, 'Sir': 5, 'Jonkheer': 5, 'Dona': 5
}
for dataset in combine:
dataset['Title'] = dataset['Title'].map(title_map).astype('int8')
train_df.head()Name 列已经转换为 Title列 ; 把Sex中的 female -> 1 male -> 0
python
train_df = train_df.drop(['Name'], axis=1)
test_df = test_df.drop(['Name'], axis=1)
combine = [train_df, test_df]
for dataset in combine:
dataset['Sex'] = dataset['Sex'].map( {'female': 1, 'male': 0} ).astype(int)然后Age中还有缺失值; 可以拿全体人员的平均数填充; 也可以通过分类别填充中位数。
根据Pclass 和 Sex 3*2=6类别 先对不缺失的算出中位数 再填充。
再以 16,32,48,64 为界限把连续型的年龄划分为5类
python
# 1. 计算各分组的年龄中位数
guess_ages = np.zeros((2, 3))
for dataset in combine:
for i in range(2): # 性别: 0=男,1=女
for j in range(3): # 舱等: 1,2,3
guess_df = dataset[(dataset['Sex'] == i) & (dataset['Pclass'] == j+1)]['Age'].dropna()
age_guess = guess_df.median()
guess_ages[i, j] = int(age_guess/0.5 + 0.5) * 0.5
# 2. 定义分段条件和标签
age_bins = [0, 16, 32, 48, 64, np.inf]
age_labels = [0, 1, 2, 3, 4]
# 3. 填充缺失值并分段
for dataset in combine:
# 填充缺失值
for i in range(2):
for j in range(3):
mask = (dataset['Age'].isnull()) & (dataset['Sex'] == i) & (dataset['Pclass'] == j+1)
dataset.loc[mask, 'Age'] = guess_ages[i, j]
# 年龄分段
dataset['Age'] = pd.cut(dataset['Age'], bins=age_bins, labels=age_labels).astype(int)
# 验证结果
print("年龄分布:")
print(train_df['Age'].value_counts().sort_index())
print("\n各年龄段生存率:")
print(train_df.groupby('Age')['Survived'].mean())SibSp 和 Parch 兄弟姐妹父母子女的信息 可以统一归类为 是否独自一个人 'IsAlone'
python
for dataset in combine:
dataset['IsAlone'] = 1
dataset.loc[dataset['SibSp'] + dataset['Parch'] > 0, 'IsAlone'] = 0
train_df = train_df.drop(['Parch', 'SibSp'], axis=1)
test_df = test_df.drop(['Parch', 'SibSp'], axis=1)Embarked 港有两个缺失值 我们可以用.mode() 得到众数填充,然后有 S C Q三类转化为0 1 2。
python
freq_port = train_df.Embarked.dropna().mode()[0]
combine = [train_df, test_df]
for dataset in combine:
dataset['Embarked'] = dataset['Embarked'].fillna(freq_port)
train_df[['Embarked', 'Survived']].groupby(['Embarked'], as_index=False).mean().sort_values(by='Survived', ascending=False)
for dataset in combine:
dataset['Embarked'] = dataset['Embarked'].map( {'S': 0, 'C': 1, 'Q': 2} ).astype(int)Fare 乘客花费 test中有一个缺失均值填充 -> qcut 转化为区间 划分为4类 -> 转化为0~3
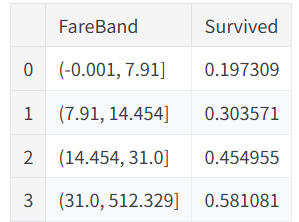
python
train_df['FareBand'] = pd.qcut(train_df['Fare'], 4)
train_df[['FareBand', 'Survived']].groupby(['FareBand'], as_index=False, observed=True).mean().sort_values(by='FareBand', ascending=True)
for dataset in combine:
# 中位数填充缺失值
dataset['Fare'] = dataset['Fare'].fillna(dataset['Fare'].dropna().median())
# 然后进行分箱操作
dataset.loc[dataset['Fare'] <= 7.91, 'Fare'] = 0
dataset.loc[(dataset['Fare'] > 7.91) & (dataset['Fare'] <= 14.454), 'Fare'] = 1
dataset.loc[(dataset['Fare'] > 14.454) & (dataset['Fare'] <= 31), 'Fare'] = 2
dataset.loc[dataset['Fare'] > 31, 'Fare'] = 3
# 转换为整数类型
dataset['Fare'] = dataset['Fare'].astype(int)
train_df = train_df.drop(['FareBand'], axis=1)
combine = [train_df, test_df]
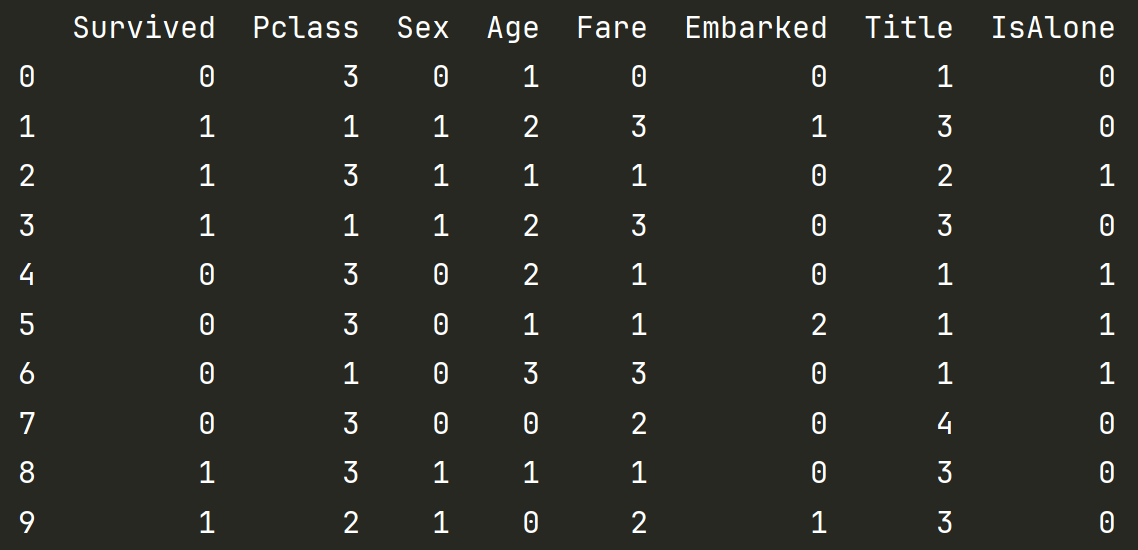
print(train_df.head(10))清洗后的最终数据变成了这样 均为不超过5个类别的 0~5的整数
小结之前的操作:变成现在的8类
Survived 保持0-1死活 Pclass 为1 2 3等 Sex男女换为0-1
Age 划分了5个年龄段 Fare票价分为了4段 Embarked的Q S C三个类别转换为0 1 2
Name中称谓信息转换为5个Title Sibsp和Parch 转化为是否一个人 IsAlone
3. 模型调用与预测
先准备好训练集X_train Y_train 和测试集 X_test
python
X_train = train_df.drop("Survived", axis=1)
Y_train = train_df["Survived"]
X_test = test_df.drop("PassengerId", axis=1).copy()
X_train.shape, Y_train.shape, X_test.shapeLogisticRegression 逻辑回归
python
from sklearn.linear_model import LogisticRegression
m1 = LogisticRegression()
m1.fit(X_train, Y_train)
Y_pred = m1.predict(X_test)
print(round(m1.score(X_train, Y_train) * 100, 2))还可以输出回归中每个量的系数
python
coeff_df = pd.DataFrame(train_df.columns.delete(0))
coeff_df.columns = ['Feature']
coeff_df["Correlation"] = pd.Series(m1.coef_[0])
coeff_df.sort_values(by='Correlation', ascending=False)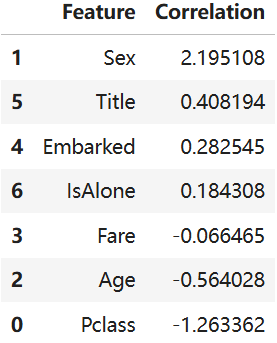
以下为一些模型的选用
python
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC, LinearSVC
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.linear_model import Perceptron, SGDClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
# 创建模型列表,每个元素是(模型名称,模型实例)的元组
models = [
("LogisticRegression", LogisticRegression()),
("SVC", SVC()),
("KNN", KNeighborsClassifier(n_neighbors=3)),
("GaussianNB", GaussianNB()),
("Perceptron", Perceptron()),
("LinearSVC", LinearSVC()),
("SGDClassifier", SGDClassifier()),
("DecisionTree", DecisionTreeClassifier()),
("RandomForest", RandomForestClassifier(n_estimators=100))
]
results = []
for name, model in models:
model.fit(X_train, Y_train)
acc = round(model.score(X_train, Y_train) * 100, 2)
results.append((name, acc))
# 输出结果:模型名称 + 准确率
results = sorted(results, key=lambda x: x[1], reverse=True)
for name, acc in results:
print(f"{name}模型准确率: {acc}%")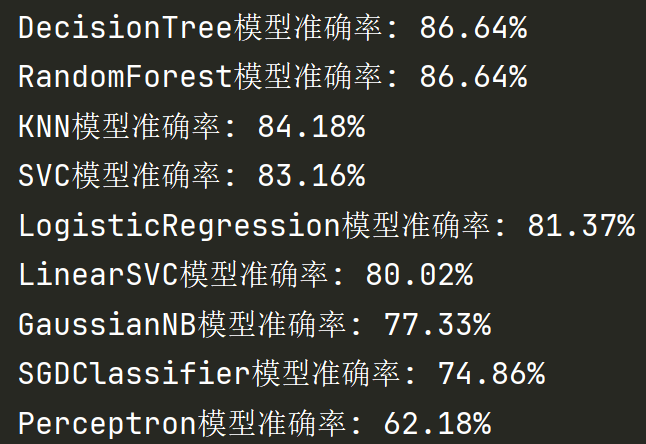
我们用随机森林预测之后 进行submission文件的生成和提交
python
model= RandomForestClassifier(n_estimators=100)
model.fit(X_train, Y_train)
Y_pred = model.predict(X_test)
submission = pd.DataFrame({
"PassengerId": test_df["PassengerId"],
"Survived": Y_pred
})
submission.to_csv('submission.csv', index=False)