01 | Background Introduction to Original Audio Video Translation
Hello everyone, we are the bilibilli Index team.
Recently, we've launched a new capability: supporting the translation of certain Chinese videos into foreign languages with a dubbed voice that preserves the original speaker's characteristics. This means viewers can now hear "this person speaking in another language," while their voice, tone, rhythm, and even personal expression remain almost identical to the original video. It's no longer the uniform "voice-over artist" sound typical of traditional dubbing, but sounds as natural as if the speaker themselves were speaking a foreign language. Behind this is actually a comprehensive upgrade in cross-modal, multilingual collaborative generation systems.
This series of technological explorations originated from an increasingly urgent need: as video content globalization deepens, multilingual dissemination has become a key medium for connecting cultures and communities. Audiences are no longer satisfied with merely "understanding the content"; they pursue "authenticity" and "presence"---hoping to hear the emotional nuances of the original voice and see natural alignment between lip movements and speech. Creators are also increasingly realizing that voice is not just a carrier of information, but a core medium for personal expression and emotional resonance.
To achieve a truly immersive cross-language experience, we must overcome key limitations present in current localization workflows. The most representative challenges fall into the following three categories:
- Loss of Vocal Identity: While traditional dubbing solves language barriers, it erases the creator's unique timbre, intonation, and accent---precisely the core identifiers of "who is speaking." In an era of personality-driven content, voice is a vital component of an IP. Once replaced by standardized voiceovers, the emotional connection breaks, and influence diminishes accordingly.
- Avoiding the Cognitive Load of Subtitles: Subtitles reduce audio to text, losing tone, emotion, and rhythm, thereby weakening the expressiveness of content. Additionally, the dual-input mode of "listening + reading" splits attention, significantly impairing comprehension efficiency and viewing experience, especially in knowledge-dense or immersive content.
- Reducing the Cost Barrier of Localization: Multilingual production relies on complex manual processes: voiceover recording, timeline synchronization, audio mixing, proofreading... With each additional language, costs rise exponentially. This makes globalization unaffordable for small and medium creators, turning it into a privilege for only a few.
In this article, we will systematically introduce the technical architecture and core challenges behind this capability, and share how we have progressively achieved these goals in practice.
02 | Speech Generation Modeling for Perceptual Consistency
Traditional Text-to-Speech (TTS) systems typically optimize for speech naturalness, intelligibility, and voice similarity, lacking multidimensional modeling capabilities for the original auditory scene. In contrast, video-level speech translation is fundamentally about reconstructing perceptual consistency, requiring coordinated modeling across three key dimensions---speaker identity characteristics, acoustic spatial attributes, and multi-source time-frequency structures---to achieve a complete transfer of auditory experience.
- Reconstruction of Speaker Identity Characteristics:
Traditional dubbing often uses fixed voice actors or generic voice libraries, causing a mismatch between the synthesized voice and the original speaker's vocal characteristics. This "voice distortion" weakens the original speaker's tone, personality, and expressiveness. To address this, our self-developed bilibilli IndexTTS2 focuses on high-precision voice cloning within the video speech translation scenario. It can accurately reconstruct the original speaker's vocal texture and pragmatic style using only minimal information from the original audio.
- Preservation of Acoustic Spatial Attributes:
Humans subconsciously perceive spatial audio cues such as reverberation characteristics, microphone distance, and ambient noise, which together form auditory spatial clues. This acoustic environmental information---including reverb, spatial echoes, mic distance, and background noise---is crucial for creating auditory authenticity. A key feature of bilibilli IndexTTS2 is its ability to preserve the original soundfield characteristics. This spatial consistency significantly enhances auditory coherence and avoids a sense of "disconnection from the scene."
- Fusion of Multi-Source Time-Frequency Structures:
In the original audio track, the interplay between speech, background music, and ambient sounds creates dynamic auditory rhythms and emotional tension. To prevent perceptual breaks from simple voice replacement, our audio synthesis incorporates perceptual weighting during reconstruction---integrating vocals, background sounds, and music---to closely match the original video's auditory feel.
2.1 An Integrated Solution to Cross-Lingual Challenges: Voice Consistency, Emotion Transfer,and Speech Rate Control
In real-world video translation scenarios, achieving a complete and natural "original voice style" experience involves far more than just translating the content into the target language. The real challenge lies in preserving the speaker's "vocal individuality" across languages at the speech generation level, while simultaneously maintaining emotional consistency and natural transitions in speech rate and rhythm. This presents several technical challenges:
- Inherent Gaps in Cross-Lingual Voice Consistency:
In cross-lingual settings, voice consistency naturally faces challenges. Many traditional speech synthesis systems tend to distort the speaker's voice when switching languages---for instance, a smooth, rounded vocal quality in Chinese may become sharp or harsh when rendered in English, making it sound like "someone else is speaking." Such voice deviations undermine the core perceptual foundation of authentic voice reconstruction.
- Difficulty in Quantifying and Controlling Emotion Transfer:
The speaker's original tone, attitude, and semantic emphasis are expressed differently across languages. For example, skepticism in Chinese might be conveyed through intonation shifts, whereas in English it may rely more on grammatical structure and rhythmic patterns. If the model lacks the ability to model the original emotional structure, it produces flat, unengaging audio output, significantly degrading the viewer's experience.
- Complexity of Speech Rate Control in Translation Reconstruction:
Speech rate control is particularly challenging in translation due to significant differences in expression length across languages. The same sentence may be over 30% longer in English than in Chinese, while the original video's audio track duration is fixed. This requires the model to possess cross-lingual rhythm prediction and information compression capabilities. Otherwise, it risks unnatural effects such as "speaking too fast to be understood" or "finishing early with awkward silence."These issues in original-voice translation rarely occur in isolation---they often intertwine and amplify each other. For example, voice distortion can weaken emotional expression, and incorrect emotional rendering can further exaggerate the jarring effect of mismatched speech rate and rhythm. Ultimately, this leads to dubbed audio that sounds "fake" or "unnatural."
Therefore, in our system design, we must achieve true cross-language reconstruction in the original voice style through end-to-end collaborative modeling and unified optimization---spanning the entire pipeline from front-end modeling, voice encoding, and cross-lingual alignment, to speech rate control and voice synthesis.
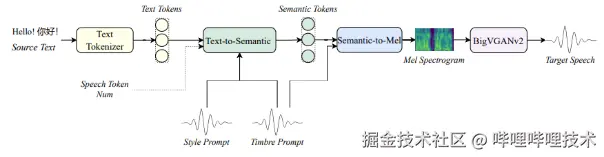
bilibilli IndexTTS2 Model Architecture
In bilibilli IndexTTS2, we innovatively proposed a "temporal encoding" mechanism universally applicable to AR systems, which for the first time solves the problem of traditional AR models being unable to precisely control speech duration. This design allows us to retain the advantages of the AR architecture in terms of prosody naturalness, style transfer capability, and multimodal extensibility, while also enabling the synthesis of speech with fixed durations.
bilibilli IndexTTS2 introduces a mechanism for disentangled modeling of voice timbre and emotion. Beyond supporting single audio references, it additionally supports specifying separate references for timbre and emotion, enabling more flexible and nuanced control over speech synthesis. Simultaneously, the model possesses text-description-based emotion control capabilities, allowing precise adjustment of the emotional tone of the synthesized speech through natural language descriptions, scene descriptions, or contextual cues.
This architecture empowers bilibilli IndexTTS2 with high expressiveness in cross-lingual synthesis, enabling the natural injection of the original speaker's personality and emotions into the target language across any language system. This achieves high-quality audiovisual reconstruction that preserves timbre, emotion, and style.
2.2 Addressing the Issue of Multi-Speaker Confusion During Viewing
In practical scenarios of original-voice translation, multiple speakers are extremely common. Reconstructing audio using only a single speaker greatly reduces fidelity and disrupts the original conversational atmosphere and character relationships in the video. However, the core prerequisite for preserving multi-speaker information is accurate speaker segmentation. If speaker segmentation is incorrect, it not only affects semantic understanding but also causes cascading impacts on subsequent translation and voice timbre synthesis, leading to severe distortions in the final output.
When processing multi-speaker videos in practice, speaker diarization faces a series of complex challenges. Traditional diarization methods often assume clear boundaries between speaker turns, relatively long speech durations, and acceptable signal-to-noise ratios. However, these assumptions frequently do not hold in real-world video scenarios. Additionally, the following are significant technical challenges:
- Frequent and tightly connected speaker alternations, sometimes with almost no gaps, and even significant speech overlap, making boundary identification extremely difficult;
- Videos often feature speakers with very short utterances, such as brief interjections like "um," "oh," or "yes," which, although short, carry semantic functions and are easily overlooked or misclassified by models;
- Some characters appear only once or twice throughout the entire video. These low-frequency speakers lack sufficient voiceprint characteristics for support, making them prone to being merged into other speakers during the clustering phase;
- In many videos, the voiceprint differences between speakers are small, compounded by strong interference from background music and ambient noise, further increasing the difficulty of distinction. Many subtle timbral features can only be discerned by careful human listening, while traditional algorithms often fall short.
These challenges, when combined, make speaker diarization the most sensitive and consequential step in the original-voice translation pipeline---any error in segmentation can disrupt semantic understanding, mislead subsequent translation and timbre synthesis, and ultimately amplify inaccuracies in the final output.
To address this, we have proposed an innovative speaker segmentation method specifically designed for the original-voice translation scenario.
First, we segment the audio stream into multiple fine-grained semantic segments based on semantics, then perform speaker clustering at the segment level, fundamentally alleviating the problems of blurred boundaries and overlapping interference. Second, we introduce an enhanced strategy for identifying low-frequency speakers at the clustering level, redesigning the similarity constraints of the clustering algorithm to prevent important but rare utterances from being ignored or merged. Furthermore, we have upgraded the foundational speaker feature model by adopting an end-to-end speaker training mechanism, significantly enhancing the model's ability to distinguish speakers in noisy backgrounds, enabling it to more accurately capture individual voice characteristics. This allows, during subsequent voice reconstruction, automatic matching of the original video's reverb and spatial sound imaging, naturally integrating multi-speaker audio into the video's original environment, enhancing spatial perception, presence, and realism, ultimately delivering a more consistent and harmonious audiovisual experience.
03 | Cross-lingual Semantic and Cultural Adaptation Modeling for Speech Alignment
The core challenges faced by video original audio translation go far beyond just "accurate translation." Compared to traditional text translation, original audio translation models must simultaneously understand context, semantic rhythm, and cross-cultural expression to achieve a realistic and credible voice reconstruction.
-
Dynamic Balance Between Speech Rhythm and Information Density: Significant differences exist in information density and syllable rates across languages, leading to inconsistencies in the semantic load carried by equally long speech segments. Therefore, the translation module needs duration-aware capabilities, using the original speech duration as a soft constraint, dynamically adjusting the length of generated text under the premise of semantic completeness: moderately expanding high-density languages and compressing low-density ones to ensure that the output text can be naturally read aloud and adapted to the target speech rhythm, avoiding overly long or too short outputs.
-
Context Understanding and Style Consistency: Translation needs to model speaker identity, dialogue structure, and domain-specific language styles to maintain consistent expression styles. The system identifies role references, tone patterns, and style types based on multimodal semantic priors and maintains consistency in terminology usage, sentence structures, and emotional tendencies during sequence generation, avoiding character confusion or stylistic drift.
-
Precise Adaptation of Proper Nouns and Culturally Loaded Words: For domain-specific terms, internet slang, and cultural metaphors, fine-grained disambiguation and adaptive translation are needed based on context and content categories. By building dynamic terminology databases and context-aware mapping mechanisms, it ensures that while maintaining literal accuracy, pragmatic functions and emotional tension are preserved, ensuring equivalent contextual understandability and emotional resonance of culturally loaded expressions in the target language.
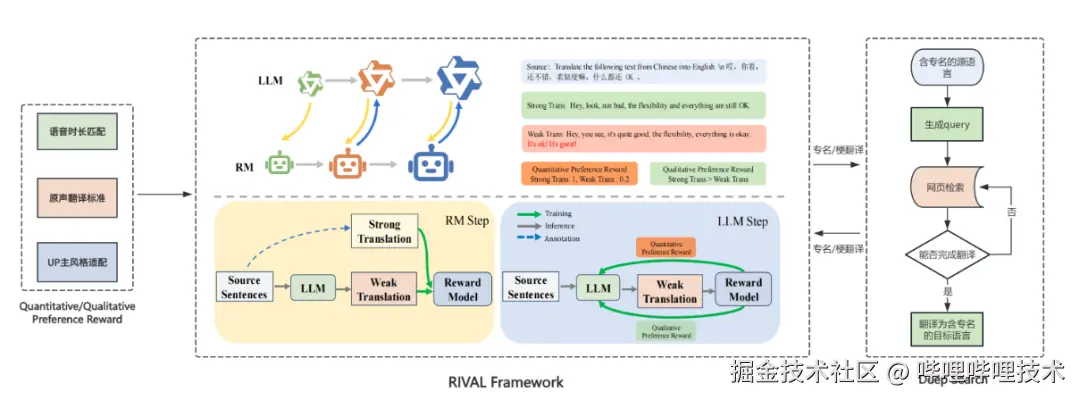
3.1 Adversarial Reinforcement Learning Framework RIVAL:Significantly Improving Translation Quality
In the context of original audio translation, there are two core challenges: firstly, how to ensure the accuracy, completeness, and fluency of translations while precisely controlling speech rhythms to authentically convey video content; secondly, how to effectively adapt to different UP master styles, accurately restoring their personality traits to enhance user experience.
When addressing these challenges, we found that Supervised Fine-Tuning (SFT) alone has limitations in generalization and struggles to significantly improve the model's translation capabilities; conventional Reinforcement Learning (RL) is prone to distribution shift effects, making model convergence difficult. To address these pain points, we innovatively proposed the RIVAL adversarial reinforcement learning training framework for the translation field. This framework models the translation optimization process as a dynamic game (min-max game) between a reward model (RM) and a large language model (LLM), achieving co-evolution through iterative updates of the dual models.
Specifically, the RIVAL framework integrates voice duration adaptation, native translation standards (accuracy, completeness, fluency, etc.), and UP master style adaptation into a preference reward model combining qualitative and quantitative elements:
- Qualitative Preference Reward Model: Used to distinguish the quality of translation results, driving the large language model (LLM) to continuously improve translation capabilities by narrowing the gap between superior and inferior models.
- Quantitative Preference Reward Model: Effectively enhances the stability of the training process and the generalization ability of the model by incorporating quantitative preference signals such as voice duration and translation statistics.
In summary, the RIVAL framework successfully unifies the three core challenges---speech rhythm control, translation quality assurance (accuracy/completeness/fluency), and personalized style adaptation---through innovative adversarial reinforcement learning mechanisms. By leveraging synergistic qualitative and quantitative reward signals, it significantly elevates the performance ceiling and generalization ability of translation models, paving new paths for high-quality, highly adaptable original video translation.
3.2 Overcoming Challenges with Proper Nouns and Cultural Adaptation
Translating proper nouns has always been a challenge in the translation field. Despite large models having powerful knowledge reserves and reasoning abilities, they still face numerous challenges when handling proper nouns: inefficiency in integrating domain knowledge, amplification of model biases in low-resource scenarios, real-time demands conflicting with model freeze states, especially in domains like anime and gaming where proper nouns and "memes" are densely populated.
To effectively address the core pain points of proper noun translation, we propose the Deep Search deep mining technology solution. This solution targets hard-to-translate proper noun cases, dynamically acquiring accurate translations through the process of generating queries → real-time web searches → summarizing translations. Simultaneously, by incorporating real-time embedded domain knowledge, it significantly improves the accuracy of proper noun translations.
04 | Video Information Reconstruction for Audio-Visual Alignment
After completing perceptual consistency reconstruction at the audio level, the system must further address temporal alignment and spatial consistency issues between audio and visual modalities. Voice replacement in video translation breaks the original audio-visual coupling relationship; without joint modeling, this introduces significant cross-modal mismatches. To this end, we formalize two key subtasks: semantic-visual disentangled reconstruction of subtitle regions and audio-driven lip movement sequence generation, achieving end-to-end visual alignment from speech to image.
-
Multimodal Localization and Restoration of Subtitle Regions: The content, rhythm, and timeline of translated audio no longer match the original subtitles. Retaining the original subtitles not only causes linguistic confusion but also disrupts visual immersion. Therefore, we have developed a collaborative architecture combining a multimodal content understanding large model with a traditional OCR model to accurately locate and erase subtitle regions, restoring the original scene as faithfully as possible.
-
High-Fidelity Lip Synchronization Based on Audio Driving: Furthermore, the translated audio inevitably differs significantly from the original in duration, rhythm, and syllabic composition. This results in misalignment between the reconstructed audio and the mouth movements of characters in the original video frames, creating a noticeable "lip-sync mismatch" phenomenon. This inconsistency greatly distracts viewers and undermines realism. Therefore, based on generative models, we have developed lip-sync technology using a diffusion-based foundation model to dynamically generate mouth movements precisely matched to the audio. Simultaneously, a reference network mechanism is introduced to ensure character ID fidelity, guaranteeing that the generated lip movements conform to the character's original appearance and achieve high visual fidelity.
4.1 Eliminating Original Subtitles
The timeline of the translated audio is completely out of sync with the original video subtitles. Retaining the original subtitles causes severe linguistic confusion and visual fragmentation, necessitating precise removal. The core challenges involve two main issues: First, accurate identification and differentiation---requiring all subtitle regions in the video to be located without omission or misjudgment, which is particularly difficult when subtitles are mixed with background text, watermarks, icons, and other interfering information. Second, ensuring frame-to-frame consistency to avoid subtitle flickering caused by inconsistencies between adjacent frames, which severely degrades the viewing experience.
To address these challenges, we have designed a technical solution based on multimodal perception and cross-frame coordination. First, for single-frame subtitle perception, we constructed a heterogeneous model collaboration architecture, deeply integrating the high-level cognitive capabilities of multimodal large models in semantic understanding and content classification with the pixel-level precision advantages of traditional OCR models in spatial localization. Furthermore, based on the characteristics of content for international audiences, we implemented domain-knowledge-based prompt optimization to achieve precise differentiation between subtitle and non-subtitle text regions. Second, to improve frame-to-frame consistency, we applied cross-frame smoothing to the erased regions across three dimensions: cross-frame matching of OCR position results with large model subtitle recognition, cross-frame position inference when large model recognition does not match OCR positions, and completion of subtitle regions not detected in brief intervals.
4.2 Lip Sync Alignment
In the original voice translation pipeline, lip-sync technology is developed based on generative models. The overall process involves inputting a video with a lower-face mask, a reference video, and audio, then generating a corresponding video with modified mouth movements based on the audio. In bilibilli's self-developed technical solution, a 3D VAE is used as the video encoder-decoder to provide stronger temporal features, reducing jitter in lips and teeth. A reference network is added to enhance ID generation capabilities, enabling the creation of high-fidelity lip-sync segments. Furthermore, leveraging the foundation capabilities of diffusion models, the overall generation is more robust to large angles and occlusions, with greater scalability.
After translation, the audio becomes desynchronized with the original mouth movements of characters in the video. This audio-visual disconnection greatly distracts viewers, undermining realism and immersion. High-synchronization lip-sync technology faces several core challenges: first, identity preservation---while changing mouth movements, the speaker's identity (ID) must be strictly maintained to ensure the generated lower face still appears as the original character; second, dynamic robustness---stable lip-sync generation must be achieved under various complex content scenarios (e.g., large head rotations, occlusions, frequent scene cuts).
Therefore, we adopted a Diffusion model as the generative foundation, developing a high-fidelity, robust lip-sync technology. In the facial encoding stage, a 3D VAE is used to better capture and model temporal features of the video, significantly reducing issues like lip discoloration and tooth jitter. Simultaneously, a reference network mechanism is introduced to learn, extract, and inject identity features of the original character's face, ensuring generated frames strictly match the original character's features and appear natural and authentic visually. Additionally, the foundation capabilities of the diffusion model demonstrate stable performance in handling complex scenarios such as head rotations and occlusions, with stronger scalability.
05 | Conclusion
Today, cross-language content dissemination is increasingly merging with individual expression. From audience-driven subtitle collaboration to creators' active exploration of multilingual expression, people are no longer satisfied with simple language conversion. Instead, they pay greater attention to the authentic intonation, emotional traits, and cultural context behind voices. A creative trend emphasizing linguistic diversity and expressive authenticity is emerging---voice itself is becoming part of the meaning.
However, in the journey toward global dissemination, we must also confront real challenges: traditional dubbing, while solving language barriers, inadvertently erases vocal individuality and cultural genes; subtitles, though serving as information bridges, often become cognitive distractions, weakening immersive experiences and artistic expression; and high localization costs remain a barrier difficult for small and medium creators to overcome, limiting the possibility of content going global. Facing these issues, technology is becoming a key game-changer. Future original voice translation systems must not only achieve precise language conversion but also preserve vocal individuality, restore emotional tension, and adapt cultural contexts.
To better cover a diverse content ecosystem, for UGC scenarios, we focus on the needs of creators and consumers, planning to support more languages in the future to facilitate global multilingual communication. Meanwhile, for PGC scenarios, we have designed more rigorous and controllable workflows and technical solutions to ensure high-quality, multilingual, cross-modal audiovisual language migration experiences, achieving professional presentation and efficient production of content. We also plan to open-source the bilibilli IndexTTS2 model, hoping to drive technological progress across the industry. We welcome everyone to continue following and using it!
We are standing at a new starting point where content is borderless and voices carry warmth. When technology becomes not just a tool but part of expression itself, we will truly enter a global content ecosystem where we not only understand languages but also hear souls. We also welcome more AI researchers, content creators, and product developers to join us in refining this technology.
Experience link: click the vedio and turn on the AI DUBBING button

Reference:
2506.21619 IndexTTS2: A Breakthrough in Emotionally Expressive and Duration-Controlled Auto-Regressive Zero-Shot Text-to-Speech(*arxiv.org/abs/2506.21...
2506.05070 RIVAL: Reinforcement Learning with Iterative and Adversarial Optimization for Machine Translation(*arxiv.org/abs/2506.05...
-End-
Made by Index Team