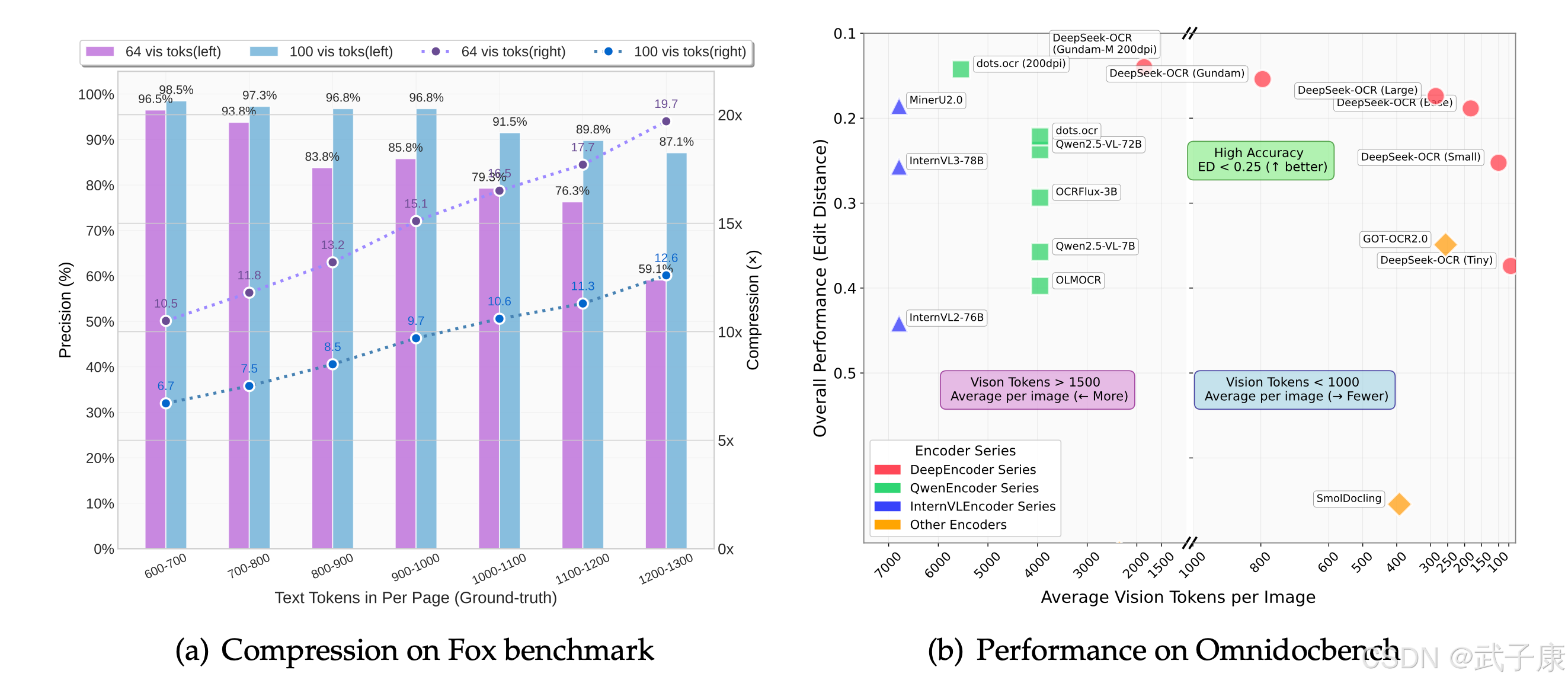
TL;DR
- 场景:私有化 OCR,整页图片/PDF 分页批处理,GPU 环境优先。
- 结论:3B/≈6.6GB 模型在 24GB 显存更稳;PyTorch 2.6.0、Transformers 4.46.3、FlashAttn 2.7.3 组合已跑通。
- 产出:加载/推理参数模板、版本矩阵、常见报错定位与修复清单。
版本矩阵
| 组件/特性 | 推荐/已测版本 | 已验证 | 说明 |
|---|---|---|---|
| Python | 3.12 | 是 | 与官方测试一致。 |
| PyTorch | 2.6.0 | 是 | 与 CUDA 匹配;支持 BF16。 |
| Transformers | 4.46.3 | 是 | 需 trust_remote_code=True 才有 infer 封装。 |
| FlashAttention | 2.7.3 | 是 | _attn_implementation="flash_attention_2" 提升吞吐。 |
| 模型权重 | DeepSeek-OCR(≈3B,≈6.6GB safetensors) | 是 | GPU 加载更稳;BF16 减显存。 |
| 推理模式 | Tiny/512、Base/1024、Large/1280 | 大 | 图建议 crop_mode=True 分块。 |
| 显存建议 | ≥24GB(如 RTX 3090) | 部分 | 社区已跑通;小显存需缩放/分块以避 OOM。 |
| vLLM 集成 | 按需 | 部分 | 适合批量/PDF;以环境为准调通。 |
| Jetson/ARM | 匹配 aarch64 Torch 轮子 | 条件 | 需升级 PyTorch 以支持新架构。 |
| 加载策略 | device_map="auto"/accelerate |
是 | 缓解首载与多卡/分布式场景。 |
推理使用方法
依赖安装与环境配置
要使用DeepSeek-OCR,需准备支持GPU的Python环境。根据官方说明,模型已在Python 3.12、PyTorch 2.6.0、Transformers 4.46.3下测试。
基本依赖包括torch、transformers、tokenizers,以及一些辅助库如einops(张量操作)、addict和easydict(配置处理)。为了提升推理速度,建议安装FlashAttention加速库(如flash-attn==2.7.3)。如果使用的是较新NVIDIA GPU(例如算力8.9以上),需要确保对应版本的CUDA和PyTorch匹配(有开发者在NVIDIA Jetson等ARM设备上运行时需升级PyTorch以支持新GPU架构)。

模型加载与调用
DeepSeek-OCR已发布在Hugging Face Hub,可通过模型名称deepseek-ai/DeepSeek-OCR直接加载。使用时需要开启trust_remote_code=True,以便自动加载模型的自定义组件 。示例代码如下(假设已安装好依赖库):
python
import torch
from transformers import AutoModel, AutoTokenizer
model_name = "deepseek-ai/DeepSeek-OCR"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(
model_name, trust_remote_code=True, use_safetensors=True,
_attn_implementation="flash_attention_2" # 使用FlashAttention加速
)
model.eval().cuda().to(torch.bfloat16) # 模型转为评估模式,搬移到GPU并用bfloat16减少显存上述代码将模型权重下载并加载到GPU(需约6.6GB显存)。接下来准备输入:将待OCR的图片读取为文件,例如image_file = "document.jpg"。然后构造prompt,DeepSeek-OCR使用特殊格式标识图像和任务,例如:
python
prompt = "<image>\n<|grounding|>请将这份文件的内容转换成Markdown格式。"
result = model.infer(tokenizer, prompt=prompt, image_file=image_file,
base_size=1024, image_size=640, crop_mode=True,
save_results=False, test_compress=True)
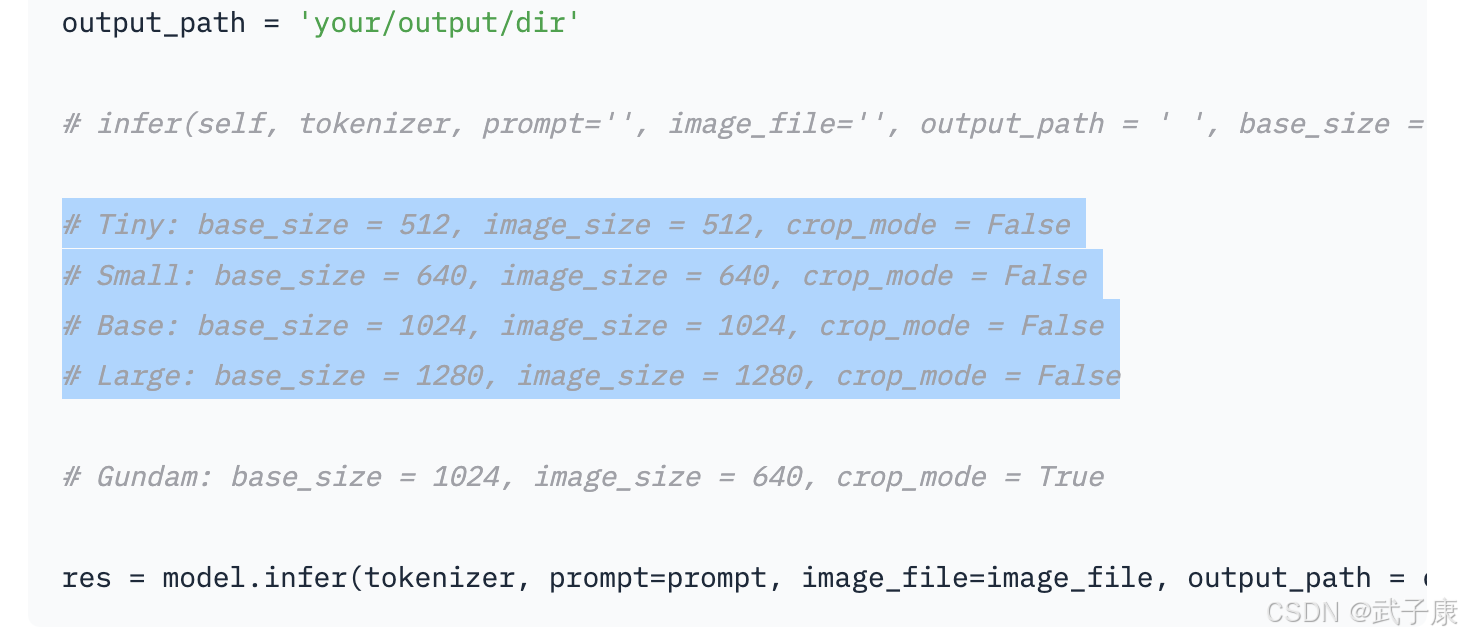
print(result)其中,model.infer()是DeepSeek-OCR提供的高层推理接口。base_size和image_size参数控制输入图像的缩放基准和切割大小,crop_mode=True表示使用"Gundam"模式对大图进行分块处理。官方在代码中给出了多种模式配置示例:如Tiny(512px,无裁剪)、Base(1024px),Large(1280px)等,可根据实际文档复杂度选择。执行上述推理后,result将返回模型的输出文本。
例如如果Prompt要求Markdown,输出可能是带有Markdown格式的文字;若Prompt是简单"\n<|grounding|>OCR this image.",则输出包括<|ref|>和<|det|>标记及坐标。开发者可以据需求调整Prompt和后处理结果。
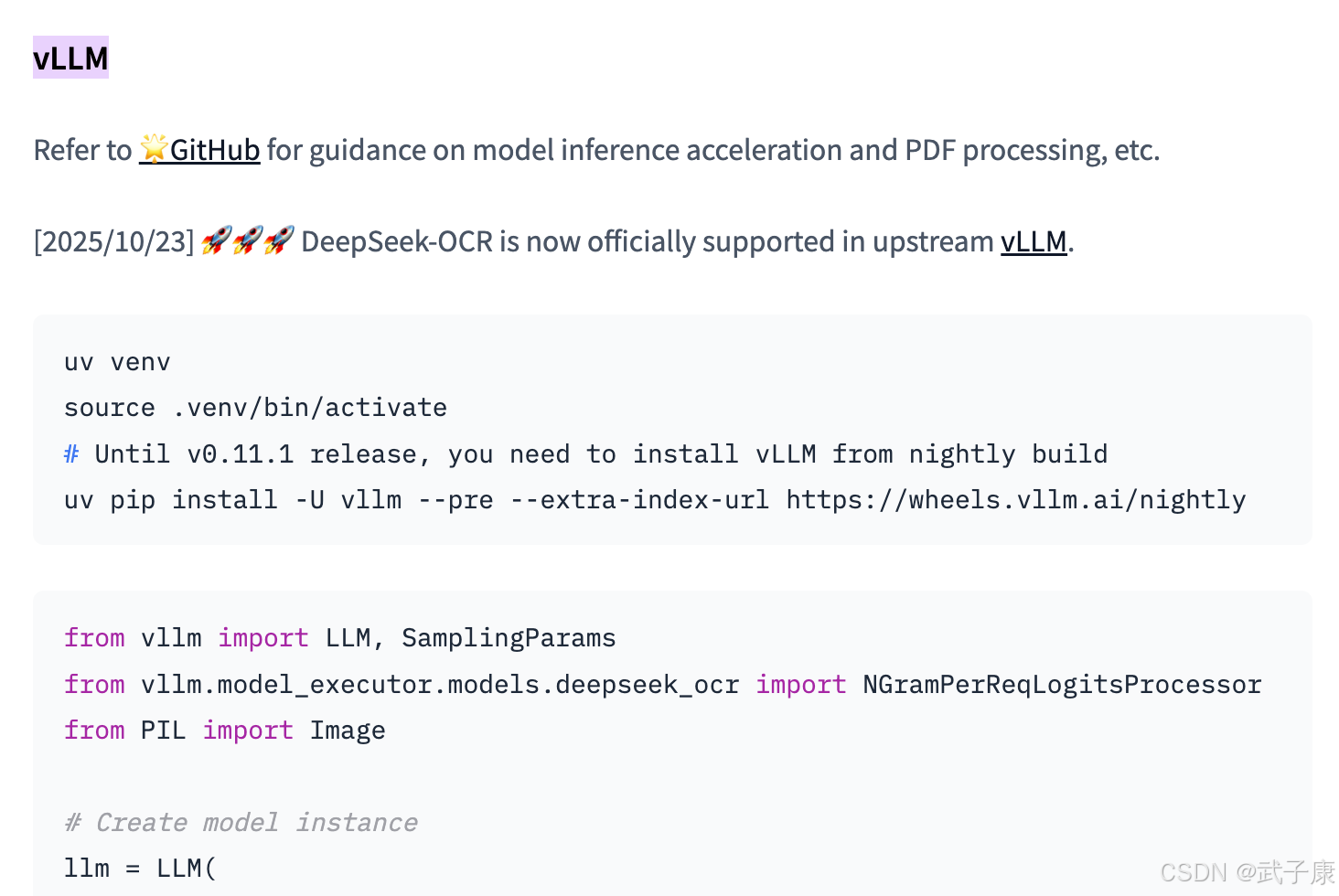
需要注意,由于默认代码中使用了.cuda()强制GPU,如果设备不支持CUDA,可能需要修改源码以在CPU上运行。此外初次加载大模型可能较慢,也可考虑开启device_map="auto"或使用accelerate库进行模型并行加载。DeepSeek-OCR也能借助vLLM等高效推理引擎加速,据官方介绍可用于批量PDF处理等场景。
信息来源 simonwillison: DeepSeek-OCR claude-code
总的来说,DeepSeek-OCR的推理使用流程对有深度学习经验的开发者来说比较顺畅:安装依赖 → 加载模型和Tokenizer → 准备图像和Prompt → 调用infer得到结果。开源代码封装了许多细节,降低了上手难度。
支持的数据格式
模型目前主要支持图像输入。常见格式如JPEG、PNG都可,内部会用PIL读取并处理。如果要OCR整份PDF,可以先将PDF按页转换为图片输入,或使用社区提供的脚本(GitHub有人分享了PDF拆分调用DeepSeek-OCR的方案)。输出数据可以是纯文本、标记文本(如Markdown/HTML)或带坐标的结构化文本,具体取决于Prompt和需求。
训练与微调
开源内容与训练管线
DeepSeek团队在开源时除了发布模型权重,也提供了论文和部分训练细节说明。

据官方博客,训练过程分两阶段:
- 阶段1:视觉编码器预训练 -- 单独训练DeepEncoder,使其学会从图像预测下一个token(类似语言模型的自监督,只不过预测的是图像patch序列)。使用的大致是图像-文本对数据,让编码器初步具备将图像映射到语义空间的能力。
- 阶段2:端到端联合训练 -- 加载预训练的编码器,与解码器一起在混合数据上继续训练。训练数据包括OCR任务数据(图像+文本的配对,要求还原文本)、一般视觉任务数据(保持对普通图像的理解能力,占比约20%)以及一定比例的纯文本数据(只输入文本,让解码器保持语言流畅度,占比约10%)。这一步相当于让模型既练OCR又练当语言模型。

DeepSeek-OCR的训练规模相当大。据报道其使用了20节点×8卡A100-40GB集群,单日吞吐量达700~900亿token。总计训练了数万亿级别的token。这种大投入保证了模型的高质量。
数据方面,团队构建了两个主要OCR数据集:一是OCR 1.0(约3000万页真实文档扫描,涵盖100+种语言),二是OCR 2.0(合成的结构化数据,如包含公式的学术资料、包含图表的报告等)。此外还有普通视觉图像数据(20%)和大规模文本语料(10%)混合作为训练料。可以说,DeepSeek-OCR的训练数据种类丰富、规模空前,这也是其能胜任复杂OCR任务的原因之一。
信息来源 Medium: DeepSeek-OCR is here
训练代码开放性
当前DeepSeek-OCR开源主要侧重推理使用,完整的训练代码和全部数据暂未完全开放(可能因为数据规模和来源限制)。但模型论文和官方博客详细描述了方法,核心架构代码在GitHub上可见。有能力的大厂或研究组可以据论文自己实现或复现。一般开发者若想训练,可以考虑微调fine-tune而非从头训练。
由于提供了模型权重,我们可以在特定数据上对DeepSeek-OCR做增量训练。例如,为提升模型对某些特殊文档(如医疗处方、手写笔记)的识别,可收集一些带标注的数据,然后以较小学习率在原模型上继续训练。需要准备的数据格式是图像-文本对,尽量贴近模型原输出格式(如果有版面结构,也按模型的标记方式标注)。利用Transformers库的Trainer或DeepSpeed等均可进行微调,但要注意显存占用和分布式训练配置。
如果只调整少量新数据,也可以尝试 Low-Rank Adaptation (LoRA) 等高效微调方法,将视觉encoder或部分解码器层进行适应性调整,而不改动大部分原权重。鉴于模型参数量3B不算极大,一两张高端GPU或小型多GPU集群即可在可接受时间内完成微调训练。
节点小结
总的来说,DeepSeek-OCR具备可微调性:开发者可以为自己的场景(特定语言、特殊字体、垂直领域文档)定制模型表现,这要优于闭源API无法定制的弊端。当然,要微调出色效果仍需足够的数据和经验,毕竟OCR任务的复杂度较高。但至少可能性是打开的。
模型规模、资源需求与部署
模型大小与运行资源
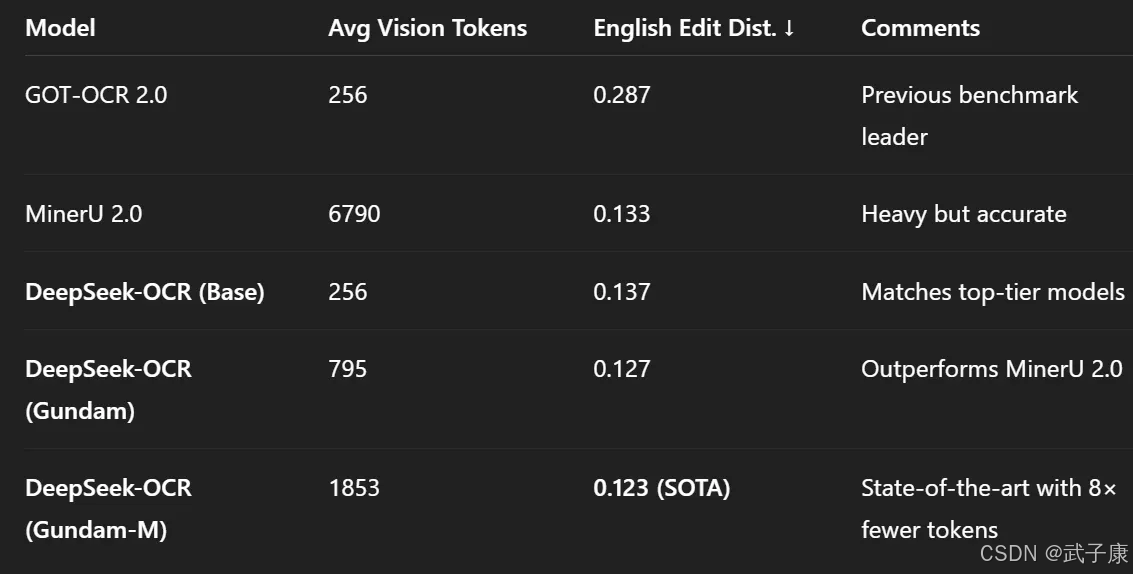
DeepSeek-OCR模型权重采用SafeTensors格式约6.6GB,包含了3B参数(BF16精度)。这对现代GPU来说中等偏上,一般需要>=16GB显存才能流畅推理整页文档。如果显存不足,可以尝试降低图像尺寸或分割处理(例如Tiny模式只需64个token,可大幅减少显存占用)。实际推理时,占用的显存还取决于输出序列长度(页面文本越长,生成token越多)。
有开发者成功在24GB显存的RTX 3090上运行了模型,但也有在小显存卡上尝试失败的案例。因此建议使用24GB或更大显存的GPU,如A10G、A100、RTX 6000等,以防止OOM。如果没有足够GPU,也可以使用CPU推理,但会非常缓慢,不太适合实际应用。
部署选项
得益于开源和标准工具链,DeepSeek-OCR的部署路径很多样:
本地推理服务
可将模型封装成一个后端服务,如用Flask/FastAPI编写接口,加载模型后提供HTTP接口接收图片返回OCR结果。这种方案适合集成到现有业务系统,实现私有化部署。需要注意保持GPU驻留模型以免反复加载。结合队列可以批量处理文档。
Hugging Face Spaces/Gradio
如果不想从零搭建界面,可以直接fork官方的Gradio演示或者社区贡献的Spaces(如khang119966/DeepSeek-OCR-DEMO等)。在Spaces上部署只需提供接口推理代码,Hugging Face会在后端分配GPU实例跑,非常方便做展示或小规模内部使用。很多用户已经借助Spaces体验了DeepSeek-OCR,无需自己配置环境。
与其他系统集成
DeepSeek-OCR也可嵌入到文档处理的工作流中。例如,有人将其与本地LLM服务Ollama结合,实现先用DeepSeek读取PDF,再用小模型问答 。也可以配合LangChain等框架,把DeepSeek作为工具,让大模型在需要时调用OCR能力。由于DeepSeek输出Markdown等格式容易被解析,这种集成相对顺畅。
云服务/API
虽然目前没有官方API,但任何有该模型的服务器都能提供REST API。像一些AI托管平台(如Replicate等)可能上线DeepSeek模型供即调即付费使用。对于不方便自己部署的团队,这是个方向。但要小心的是,上传文档到第三方API有数据隐私风险,因此很多企业用户可能更倾向自行部署。
模型优化部署
有余力的开发者可以尝试进一步优化模型推理,如使用TensorRT或ONNX Runtime加速,或者通过模型蒸馏压缩出小一点的版本(比如将3B MoE蒸馏到1.5B dense模型)。另外,对于移动端或浏览器端,目前DeepSeek-OCR体量过大,无法直接运行。但未来不排除出现轻量级改进版,使之能在边缘设备运行,从而拓展应用场景。
节点小结
综上,DeepSeek-OCR部署灵活,在满足GPU资源的前提下,可以较容易地融入各种应用环境。完全开源让用户拥有自主控制权,不必依赖任何厂商,这对一些对数据敏感的行业(金融、政府)尤其有吸引力。
错误速查
| 症状 | 根因 | 定位修复 |
|---|---|---|
| AttributeError: 'AutoModel' has no attribute 'infer' | 未启用远程代码检查 | 加载参数trust_remote_code=True重新加载模型与分词器。 |
| ImportError: No module named flash_attn | 未装或版本不匹配 | pip show flash-attn安装flash-attn==2.7.3,与当前Torch/CUDA匹配后重启进程。 |
| CUDA OOM / 显存爆 | 输入过大或输出过长 | 观察显存、日志降image_size/base_size;启用crop_mode=True;切Tiny;BF16;控制生成长度。 |
| 加载极慢/被杀 | 首次载入占内存/显存高 | dmesg/监控固化常驻进程;用device_map="auto"或accelerate;保证交换区与ulimit。 |
| RuntimeError: CUDA error: invalid device | 无可用GPU/设备索引错 | nvidia-smi/可见性去掉强制.cuda();或设CUDA_VISIBLE_DEVICES正确;必要时改CPU路径。 |
| Jetson/ARM运行失败 | Torch轮子与架构不符 | python -c "import torch;print(torch.version)"安装匹配aarch64的PyTorch;按官方指引升级。 |
| BF16转换报错 | 编译环境不支持BF16 | Torch日志升级驱动/Torch;或改FP16/FP32;核对torch.cuda.is_bf16_supported()。 |
输出出现<ref>/<det |
CPU路径过慢 | 无GPU或禁用CUDA运行配置减小图像尺寸/裁剪;或切GPU;批处理走队列。 |
| vLLM启动失败/不出结果 | 环境未对齐/端口冲突 | 服务日志按vLLM版本对齐Torch/CUDA;避开端口冲突;先小样本压测再放量。 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南!
AI-调查研究-108-具身智能 机器人模型训练全流程详解:从预训练到强化学习与人类反馈
🔗 AI模块直达链接
💻 Java篇持续更新中(长期更新)
Java-154 深入浅出 MongoDB 用Java访问 MongoDB 数据库 从环境搭建到CRUD完整示例
MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
🔗 Java模块直达链接
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
🔗 大数据模块直达链接