在前面两篇文章中,我们分别介绍了"文档加载"和"文本分割"。此时,知识库中的长文档已被拆分为一个个固定长度的文本片段。完成这两步后,实现 RAG 功能的下一步就是对这些文本片段进行向量化。
在文本向量化时,可以使用LangChain提供的文本嵌入组件:Embeddings,这也是本文的主角,本文将会详细介绍Embeddings组件的用法。
文中所有示例代码:github.com/wzycoding/l...
一、什么是文本嵌入模型
文本嵌入模型可以将一段文本转换为高维向量表示,向量可以理解为是一组数字,文本嵌入模型根据多个不同维度将文本转换为具有语义含义的向量数据,这个转换过程叫做文本嵌入。
之后,将这些向量存储到向量数据库中。当用户向LLM提出问题,先将问题文本进行向量化,得到问题文本的向量,使用这个向量在向量数据库中进行相似性搜索,就可以找到与提问文本语义最相近向量,进而找到文本片段信息。
文本嵌入流程如下图所示:
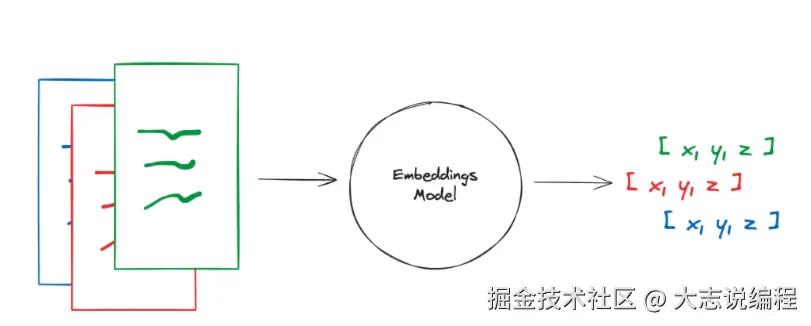
二、Embeddings类用法
2.1 Embeddings类介绍
在LangChain中,Embeddings类是为文本嵌入模型设计的标准接口,针对不同的文本嵌入模型供应商(如OpenAI、Hugging Face、通义千问等)提供不同的实现类。
Embeddings类提供了两个方法:
embed_documents:传入多个文本片段,将文本片段转换为多个向量返回
embed_query:传入查询文本,将查询文本转换为向量返回
将文本转换为向量被拆分为两个方法,是因为某些模型提供商对"文档嵌入"和"查询文本嵌入"提供了不同的方法。
2.2 OpenAIEmbeddings用法
下面以OpenAI提供的OpenAIEmbeddings类为例,介绍Embeddings类用法。
首先安装langchain-openai相关依赖
bash
pip install langchain-openai==0.1.8执行命令,生成依赖版本快照
bash
pip freeze > requirements.txt在.env文件中,添加OpenAI秘钥配置
properties
# OpenAI大模型
OPENAI_API_KEY=sk-************************
OPENAI_API_BASE=https://api.***OpenAIEmbeddings使用示例如下,使用embed_documents和embed_query分别对文档和查询文本进行嵌入,其中使用的模型是text-embedding-3-small,该模型生成的向量维度是1536,能接收最大的token数是8192。
python
import dotenv
from langchain_openai import OpenAIEmbeddings
dotenv.load_dotenv()
texts = [
"北宋著名文学家、书法家、画家,历史治水名人。与父苏洵、弟苏辙三人并称"三苏"。苏轼是北宋中期文坛领袖,在诗、词、散文、书、画等方面取得很高成就。",
"苏轼,(1037年1月8日-1101年8月24日)字子瞻、和仲,号铁冠道人、东坡居士,世称苏东坡、苏仙,汉族,眉州眉山(四川省眉山市)人",
"与辛弃疾同是豪放派代表,并称"苏辛";散文著述宏富,豪放自如,与欧阳修并称"欧苏",为"唐宋八大家"之一。苏轼善书,"宋四家"之一;擅长文人画,尤擅墨竹、怪石、枯木等。与韩愈、柳宗元和欧阳修合称"千古文章四大家"。",
]
# 1.创建embeddings对象
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
# 2.将文本转换为向量
vectors = embeddings.embed_documents(texts)
# 3.输出文档向量
print("文档向量:")
for vector in vectors:
print(f"{vector}")
print("=================================")
# 4.将查询转换为向量
query = "谁是苏东坡?"
query_vector = embeddings.embed_query(query)
# 5.输出查询文本向量
print("查询文本向量:")
print(query_vector)执行结果如下,可以看到三个文档分别生成了三个高维向量,查询文本也生成了一个对应的向量。由于向量维度较高,输出进行了部分省略。
python
文档向量:
[0.058245643973350525, -0.011029906570911407, 0.008078922517597675, -0.006782424636185169,省略...]
[-0.011653225868940353, -0.002974639181047678, -0.01643718034029007, 0.06390874087810516,省略...]
[0.028559477999806404, -0.015319629572331905, -0.010216659866273403, 0.014526311308145523,省略...]
=================================
查询文本向量:
[-0.015014365315437317, -0.044838666915893555, -0.030710170045495033, 0.034821517765522, 省略...]三、CacheBackedEmbeddings结果缓存
当使用Embeddings类对一段文本进行嵌入后,再有同样的文本进行嵌入,如果每次都重新调用嵌入模型,不仅会显著增加处理时间,也会带来额外的调用成本。
因此,LangChain提供了CacheBackedEmbeddings可以对嵌入结果进行缓存,下次同样的文本进行嵌入,直接从缓存中读取,无需重复调用嵌入模型。
创建CacheBackedEmbeddings对象,需要通过from_bytes_store方法,该方法需要指定如下参数:
underlying_embedder: 真正用于文本嵌入Embeddings类。document_embedding_cache: 用于缓存文档嵌入向量数据的ByteStore(字节存储接口) ,ByteStore是 LangChain 提供的通用"字节存储接口",用于以二进制形式读写向量数据。常见实现包括本地文件系统(如LocalFileStore)、Redis(RedisStore) 等。batch_size: 可选参数,默认为None,在嵌入缓存未命中时,多少个文档为一批,去调用底层文本嵌入组件去文本嵌入并写入缓存。namespace: 可选参数,默认为"",文档缓存的命名空间。使用命名空间来避免和其他嵌入模型的缓存数据发生冲突。因此,可以将命名空间设置为所使用的嵌入模型的名称。query_embedding_cache: 可选参数,默认为None,传入False则不进行缓存,传入True使用与 文档缓存相同的ByteStore,也可以传入单独的ByteStore用于查询文本的缓存。
from_bytes_store方法定义如下:
python
@classmethod
def from_bytes_store(
cls,
underlying_embeddings: Embeddings,
document_embedding_cache: ByteStore,
*,
namespace: str = "",
batch_size: Optional[int] = None,
query_embedding_cache: Union[bool, ByteStore] = False,
) -> CacheBackedEmbeddings:
CacheBackedEmbeddings使用示例如下,在示例中,使用了OpenAIEmbeddings来作为真正进行文本嵌入的组件,并且,为文档向量缓存和查询文档向量缓存指定了两个不同的本地文件存储容器,还指定了命名空间为嵌入模型的名称。
python
import time
import dotenv
from langchain.embeddings import CacheBackedEmbeddings
from langchain.storage import LocalFileStore
from langchain_openai import OpenAIEmbeddings
dotenv.load_dotenv()
# 1.创建进行文本嵌入的embeddings对象
underlying_embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
# 2.创建CacheBackedEmbeddings对象
cache_embeddings = CacheBackedEmbeddings.from_bytes_store(underlying_embeddings=underlying_embeddings,
document_embedding_cache=LocalFileStore("./document_cache/"),
namespace=underlying_embeddings.model,
query_embedding_cache=LocalFileStore("./query_cache/"))
texts = [
"北宋著名文学家、书法家、画家,历史治水名人。与父苏洵、弟苏辙三人并称"三苏"。苏轼是北宋中期文坛领袖,在诗、词、散文、书、画等方面取得很高成就。",
"苏轼,(1037年1月8日-1101年8月24日)字子瞻、和仲,号铁冠道人、东坡居士,世称苏东坡、苏仙,汉族,眉州眉山(四川省眉山市)人",
"与辛弃疾同是豪放派代表,并称"苏辛";散文著述宏富,豪放自如,与欧阳修并称"欧苏",为"唐宋八大家"之一。苏轼善书,"宋四家"之一;擅长文人画,尤擅墨竹、怪石、枯木等。与韩愈、柳宗元和欧阳修合称"千古文章四大家"。",
]
# 3.将文本转换为向量
start_time = time.time()
vectors = cache_embeddings.embed_documents(texts)
print(f"文档嵌入执行时间:{time.time() - start_time:.4f} 秒")
# 5.将查询转换为向量
start_time = time.time()
query = "谁是苏东坡?"
query_vector = cache_embeddings.embed_query(query)
# 6.输出查询文本向量
print(f"查询文本嵌入执行时间:{time.time() - start_time:.4f} 秒")
第一次执行结果,整个文本嵌入执行时间比较长
python
文档嵌入执行时间:52.9221 秒
查询文本嵌入执行时间:13.4554 秒在当前文件目录就会生成两个缓存文件夹,分别用来缓存文档和查询文本向量信息,并且命名空间使用的是模型名称
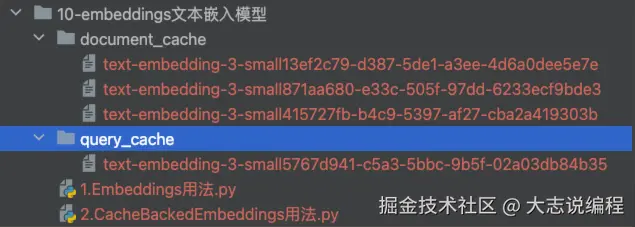
第二次执行程序,程序很快的返回结果,并且计算的执行时间也是非常的快,因为整个嵌入过程没有调用嵌入模型,而是读取了缓存中的数据。
python
文档嵌入执行时间:0.0036 秒
查询文本嵌入执行时间:0.0012 秒 四、总结
本文详细介绍了实现RAG功能的重要组件:文本嵌入组件,讲解了LangChain中的Embeddings类的使用方法,以及Embeddings类的核心方法,以OpenAI提供的 OpenAIEmbeddings 类为例,演示如何进行文本嵌入。
为了能提升文本嵌入执行效率、节省成本,LangChain还提供了CacheBackedEmbeddings类,通过在本地对文本嵌入信息缓存,当同样的文本再进行文本嵌入时,就可以从本地缓存中进行读取,有效提升了文本嵌入的整体性能。
相信通过本文,你已经掌握了如何使用Embeddings类进行文本嵌入,在下一篇文章中,我们将介绍向量数据库相关用法,敬请期待。