引言
随着大型语言模型(LLM)的快速发展,越来越多的开发者和研究者希望在本地环境中运行这些模型,以保护数据隐私、降低成本并获得更灵活的控制。Ollama 提供了一个极简的框架,让本地运行 LLM 变得触手可及。然而,对于需要跨设备管理或希望通过图形界面进行操作的用户来说,命令行界面可能不够直观。
本文将详细介绍如何利用 Docker 部署 Ollama 服务,实现环境的快速搭建与隔离。在此基础上,我们将探讨如何结合 OllaMan 桌面应用,实现对远程 Docker 化 Ollama 实例的无缝管理,从而打造一个高效、便捷的 AI 模型工作流。
1. Docker部署Ollama
Docker 是一种容器化技术,它能将应用程序及其所有依赖项打包到一个独立的、可移植的容器中。使用 Docker 部署 Ollama 具有以下显著优势:
- 环境隔离: 避免与宿主机系统环境冲突,确保 Ollama 及其依赖的稳定运行。
- 快速部署: 通过简单的命令即可拉取并运行 Ollama 镜像,省去繁琐的环境配置。
- 高度可移植: Docker 容器可以在任何支持 Docker 的操作系统上运行,实现跨平台部署。
- 易于管理: 方便容器的启动、停止、重启和删除,简化生命周期管理。
1.1 部署前准备
在开始部署之前,请确保您的系统已安装 Docker。如果尚未安装,请根据您的操作系统(Windows、macOS、Linux)访问 Docker 官方网站获取安装指南。
1.2 Ollama Docker镜像
Ollama 官方提供了 Docker 镜像,您可以在 Docker Hub 上找到它:ollama/ollama。 
1.3 运行Ollama容器
根据您的硬件配置,选择相应的 Docker 运行命令。
1.3.1 仅CPU模式
如果您没有独立的 GPU,或者希望在 CPU 上运行 Ollama,可以使用以下命令:
bash
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama-d: 后台运行容器。-v ollama:/root/.ollama: 将宿主机的ollama命名卷挂载到容器内的/root/.ollama目录。这用于持久化 Ollama 下载的模型数据,即使容器被删除,模型数据也不会丢失。-p 11434:11434: 将容器内部的 11434 端口映射到宿主机的 11434 端口。Ollama 默认通过 11434 端口提供服务。--name ollama: 为容器指定一个易于识别的名称。ollama/ollama: 指定要使用的 Docker 镜像。
1.3.2 Nvidia GPU加速模式
如果您拥有 Nvidia GPU,并已安装 NVIDIA Container Toolkit,可以通过以下命令启用 GPU 加速:
bash
docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama--gpus=all: 允许容器访问宿主机上的所有 Nvidia GPU。
1.3.3 AMD GPU加速模式
对于 AMD GPU 用户,需要使用 rocm 标签的 Ollama 镜像,并映射相应的设备:
bash
docker run -d --device /dev/kfd --device /dev/dri -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama:rocm--device /dev/kfd --device /dev/dri: 映射 AMD GPU 所需的设备文件。ollama/ollama:rocm: 使用支持 ROCm 的 Ollama 镜像。
1.4 验证Ollama服务
容器启动后,您可以通过以下命令检查 Ollama 服务是否正常运行:
bash
docker logs ollama如果看到 Ollama 启动成功的日志信息,则表示服务已成功部署。您也可以尝试在宿主机上访问 http://localhost:11434,如果看到 "Ollama is running" 的提示,则部署成功。
2. Ollama模型基础操作
Ollama 提供了简洁的命令行接口来管理和运行模型。
2.1 拉取模型
从 Ollama 官方模型库拉取模型非常简单,例如拉取 llama3 模型:
bash
docker exec -it ollama ollama pull llama32.2 运行模型
拉取模型后,可以直接在容器内运行模型进行交互:
bash
docker exec -it ollama ollama run llama32.3 自定义模型与Modelfile
Ollama 允许用户通过 Modelfile 文件自定义模型,例如导入 GGUF 格式的模型或设置自定义提示词、参数等。这为模型的个性化和微调提供了极大的灵活性。
3. Ollama远程访问配置
为了让 OllaMan 能够远程管理 Docker 部署的 Ollama,需要确保 Ollama 服务可以被外部网络访问。默认情况下,Docker 容器的端口映射 (-p 11434:11434) 已经将 Ollama 的 11434 端口暴露到宿主机。
如果您的 Ollama 部署在远程服务器上,并且您希望 OllaMan 在本地机器上连接它,您可能需要配置服务器的防火墙,允许 11434 端口的入站连接。
此外,Ollama 允许通过设置 OLLAMA_HOST 环境变量来指定其监听的 IP 地址。在 Docker 容器中,Ollama 默认监听 0.0.0.0,这意味着它会监听所有可用的网络接口,因此通常无需额外配置。
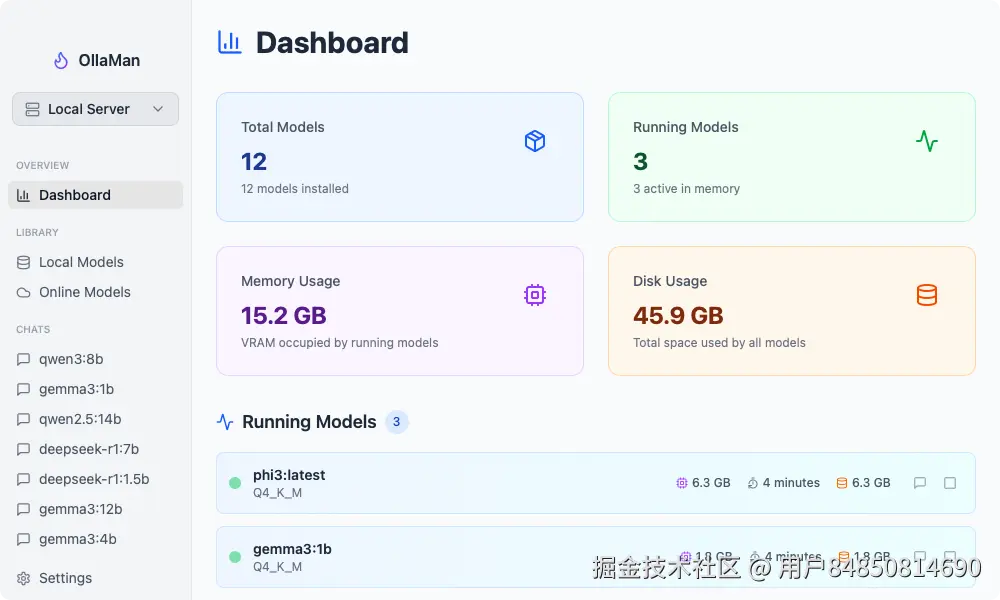
4. OllaMan:远程管理Ollama的利器
OllaMan 是一款专为 Ollama 设计的桌面 GUI 应用程序,它提供了一个直观、优雅的界面,极大地简化了 Ollama 模型的管理和交互。其"服务器管理"功能是实现远程管理的核心。 你可以通过访问 ollaman.com/download 来下载 OllaMan,该软件兼容 macOS、Windows 和 Linux 系统。
4.1 OllaMan的核心优势
- 直观的用户界面: 告别命令行,通过图形界面轻松管理模型。
- 模型发现与安装: 浏览 Ollama 模型库,一键安装所需模型。
- 会话管理: 方便地保存和管理聊天历史,支持多会话。
- 服务器管理: 这是实现远程管理的关键,允许用户添加、配置和切换不同的 Ollama 服务器实例。
4.2 结合OllaMan实现无缝远程管理
OllaMan 的设计理念之一就是简化 Ollama 的使用,包括远程管理。当您的 Ollama 服务通过 Docker 部署在远程服务器上并暴露了 11434 端口后,OllaMan 可以轻松连接并管理它。
以下是 OllaMan 连接远程 Ollama 实例的典型步骤:
- 启动 OllaMan 应用程序: 在您的本地桌面启动 OllaMan 应用。
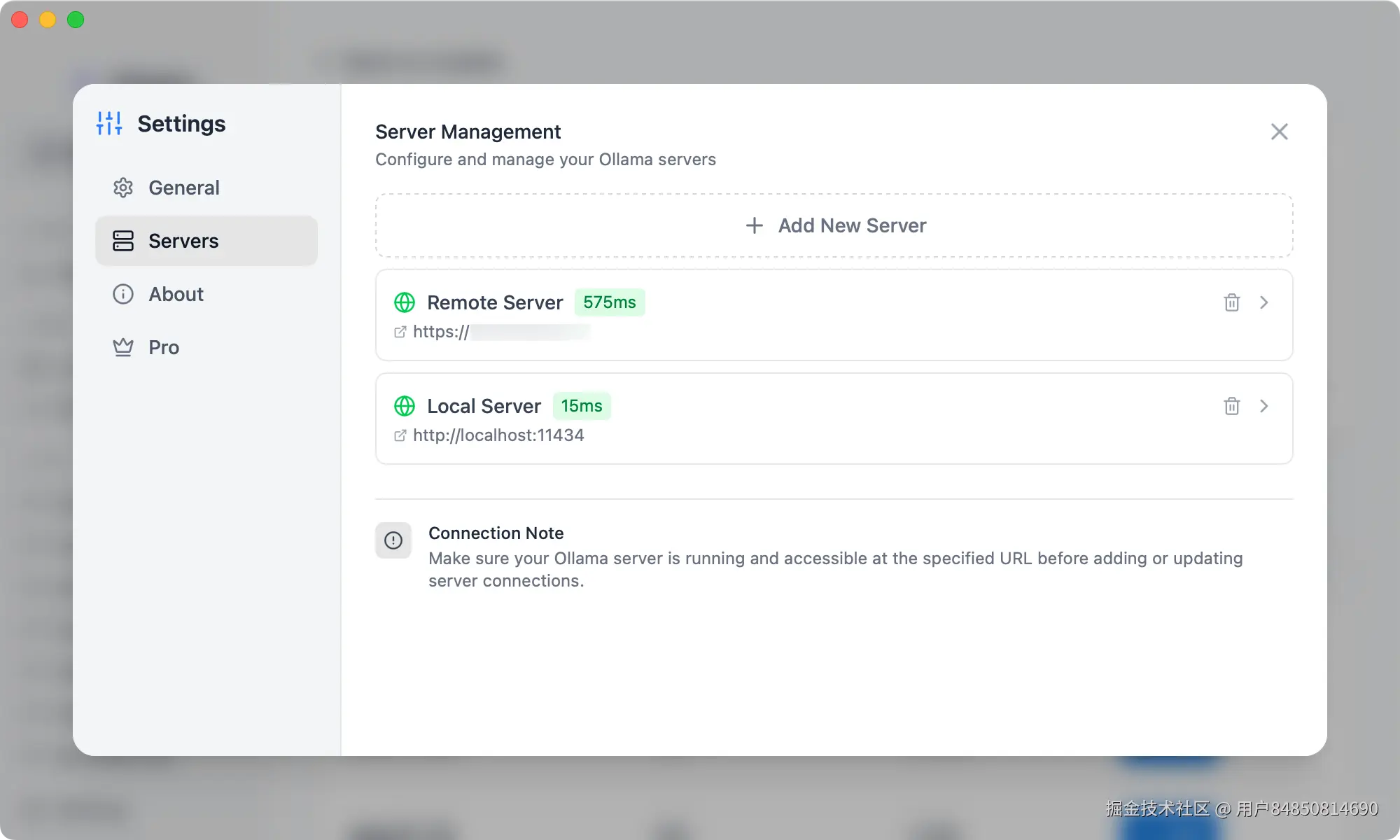
- 进入服务器管理界面: 在 OllaMan 应用左下角点击"设置"按钮,然后在设置页面选择 "Servers" 选项。
- 添加新服务器: 在"服务器管理"界面,您可以看到已配置的服务器列表。点击"Add Server"按钮来添加一个新的远程 Ollama 实例。
- 配置远程Ollama信息:
- Server Name: 为您的远程 Ollama 实例指定一个易于识别的名称(例如:"我的远程Ollama服务器")。
- Server URL: 输入您远程服务器的公共 IP 地址或域名,并确保包含 Ollama 的端口(例如:
http://your_server_ip:11434)。 - Basic Authentication (Optional): 如果您的 Ollama 服务配置了基础认证,可以在此处输入用户名和密码。
- Test Connection: OllaMan 提供一个"Test Connection"按钮,点击它以验证是否能成功连接到远程 Ollama 服务。
- 保存并连接: 填写完信息并测试连接成功后,点击"Add Server"按钮保存配置。OllaMan 将自动连接到指定的远程 Ollama 实例。
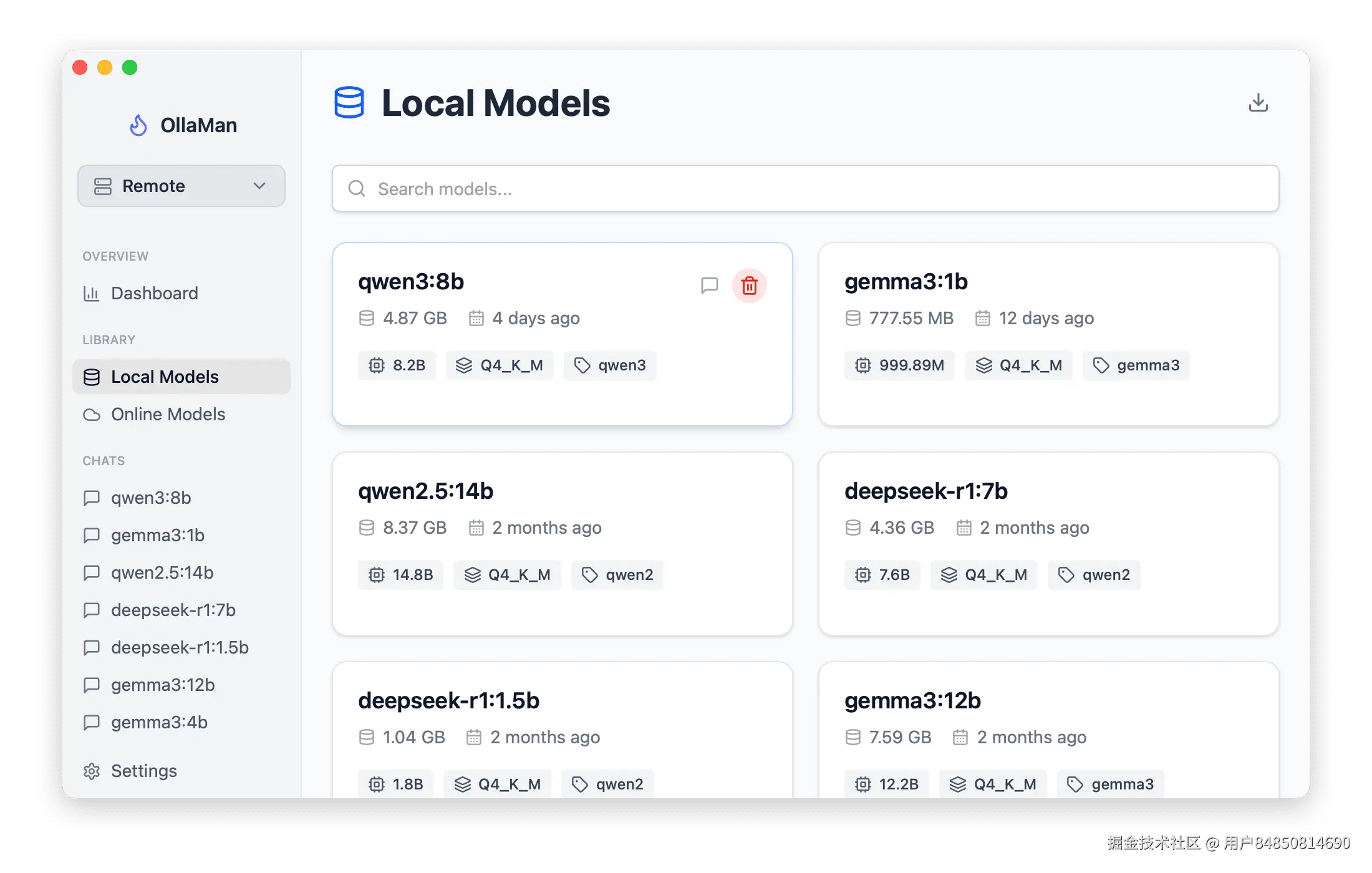
连接成功后,OllaMan 将显示远程 Ollama 实例上已安装的模型列表,并允许您执行以下操作:
- 模型发现与安装: 直接在 OllaMan 界面中浏览 Ollama 官方模型库,并远程安装模型到您的 Docker 化 Ollama 实例上。
- 模型管理: 查看、删除远程 Ollama 上的模型。
- 直观聊天: 通过 OllaMan 的聊天界面与远程 Ollama 上的模型进行交互,享受流畅的对话体验。
通过这种方式,OllaMan 将复杂的远程命令行操作抽象为简单的图形界面点击,极大地提升了用户体验和工作效率。
结语
将 Ollama 与 Docker 结合,为本地大模型的部署提供了强大的灵活性和可移植性。而 OllaMan 桌面应用的引入,则进一步将这种技术能力转化为直观易用的远程管理体验。无论是个人开发者还是小型团队,通过"Ollama Docker部署 + OllaMan远程管理"的组合,都能够轻松搭建和维护自己的 AI 模型工作流,专注于创新和应用,而无需深陷繁琐的底层配置。