RAG + Agent + Prompt 工程中:搭建本地向量数据库Qdrant、文档处理与多语言支持国际化
本文是 RAG 系统实战系列 的中间篇。在前一篇文章中,我们介绍了 RAG 的基本原理和 LangChain 的核心概念。今天,我们将深入实战环节------手把手教你如何搭建本地向量数据库(Qdrant),并重点讲解 文档预处理流程 和 多语言国际化支持 的完整实现方案。
附上项目源代码:lhlhlhlhl/assessment-rag
前言:为什么向量数据库如此重要?
在 RAG(检索增强生成)系统中,向量数据库 是连接"用户问题"与"知识库内容"的桥梁。它的作用是:
- 将你的文档内容转换为高维向量(即"嵌入")
- 快速找出与用户提问语义最相近的几段文本
- 为大模型提供精准的上下文,从而生成高质量回答
没有高效的向量存储和检索机制,RAG 就失去了"增强"的意义。
在本项目中,我们选择 Qdrant 作为本地向量数据库,并围绕它构建了一套完整的文档处理 + 多语言支持体系。
一、向量数据库选型:为什么是 Qdrant?
市面上有 Pinecone、Weaviate、Milvus、FAISS 等多种向量数据库,我们最终选择了 Qdrant,原因如下:
| 特性 | 说明 |
|---|---|
| 🚀 高性能 | 用 Rust 编写,内存效率高,单机每秒可处理数千次查询 |
| 📦 轻量易部署 | 支持 Docker 一键启动,也支持二进制直接运行 |
| 🔍 支持元数据过滤 | 不仅能按向量相似度搜索,还能结合标签、来源等条件筛选 |
| 🌐 双协议支持 | 同时提供 RESTful API 和 gRPC 接口,适配不同场景 |
| 🆓 开源免费 | 社区活跃,文档完善,适合本地开发和中小规模生产 |
二、两种部署方式:Docker vs 直接安装
方案一:推荐!使用 Docker Compose 一键部署(开发首选)
1. 创建 docker-compose.yml
yaml
version: '3.8'
services:
qdrant:
image: qdrant/qdrant:latest
container_name: smart_assessment_qdrant
ports:
- "6333:6333" # REST API 端口
- "6334:6334" # gRPC 端口(可选)
volumes:
- ./qdrant_storage:/qdrant/storage # 持久化数据
environment:
- QDRANT__SERVICE__GRPC_PORT=6334
restart: unless-stopped
networks:
- rag_network
networks:
rag_network:
driver: bridge💡 关键解释:
volumes将本地qdrant_storage/目录挂载到容器内,即使删除容器,数据也不会丢失restart: unless-stopped保证服务崩溃后自动重启- 自定义网络
rag_network便于未来扩展(如加入 LLM 服务)
2. 启动服务
docker-compose up -d3. 验证是否成功
bash
curl http://localhost:6333/collections如果返回 {"result":{"collections":[]},"status":"ok"},说明 Qdrant 已正常运行!
方案二:非 Docker 安装(适合无 Docker 环境)
Windows 用户:
-
从 GitHub Releases 下载
qdrant-windows-x86_64.zip -
解压后运行:
.\qdrant.exe
Linux/macOS 用户:
bash
# 方法1:APT 安装(Ubuntu/Debian)
echo "deb [trusted=yes] https://apt.qdrant.io stable main" | sudo tee /etc/apt/sources.list.d/qdrant.list
sudo apt update && sudo apt install qdrant
# 方法2:直接下载二进制
wget https://github.com/qdrant/qdrant/releases/latest/download/qdrant-linux-x86_64.tar.gz
tar xzf qdrant-linux-x86_64.tar.gz
./qdrant⚠️ 注意:非 Docker 方式需要手动管理配置、日志和数据目录,强烈建议开发阶段使用 Docker。
✅ 为什么我们推荐 Docker?
| 对比项 | 直接安装 | Docker |
|---|---|---|
| 安装复杂度 | 高(需处理依赖、路径、权限) | 极低(一条命令) |
| 跨平台一致性 | 差(Windows/Linux 行为可能不同) | 完美一致 |
| 数据隔离 | 无(文件散落在系统各处) | 完全隔离 |
| 版本切换 | 困难 | 修改镜像标签即可 |
| 卸载清理 | 容易残留 | docker-compose down -v 一键清空 |
🧩 打个比方 :
直接安装就像在客厅里搭帐篷------占地方、难收拾;
Docker 就像买了一个带轮子的集装箱------随时移动、干净整洁。
三、连接 Qdrant:代码实现详解
无论采用哪种部署方式,我们的 JavaScript 代码连接逻辑完全一致。以下是核心类 QdrantVectorStoreManager 的精要解读:
arduino
// 初始化客户端
this.client = new QdrantClient({
url: `http://${config.QDRANT_HOST}:${config.QDRANT_PORT}`,
timeout: 30000,
});
// 使用 Qwen 兼容 OpenAI 的 Embedding 模型
this.embeddings = new OpenAIEmbeddings({
openAIApiKey: config.QWEN_API_KEY,
modelName: config.EMBEDDING_MODEL,
configuration: { baseURL: config.QWEN_API_BASE }
});🔑 关键点 :虽然用了
OpenAIEmbeddings,但通过baseURL指向 Qwen 的 API,实现了"用 OpenAI 接口调 Qwen 模型"。
后续的 initCollection()、addDocuments()、search() 等方法封装了集合创建、文档插入和相似检索,完全兼容 LangChain 生态,可直接用于 RAG 链。
效果展示:
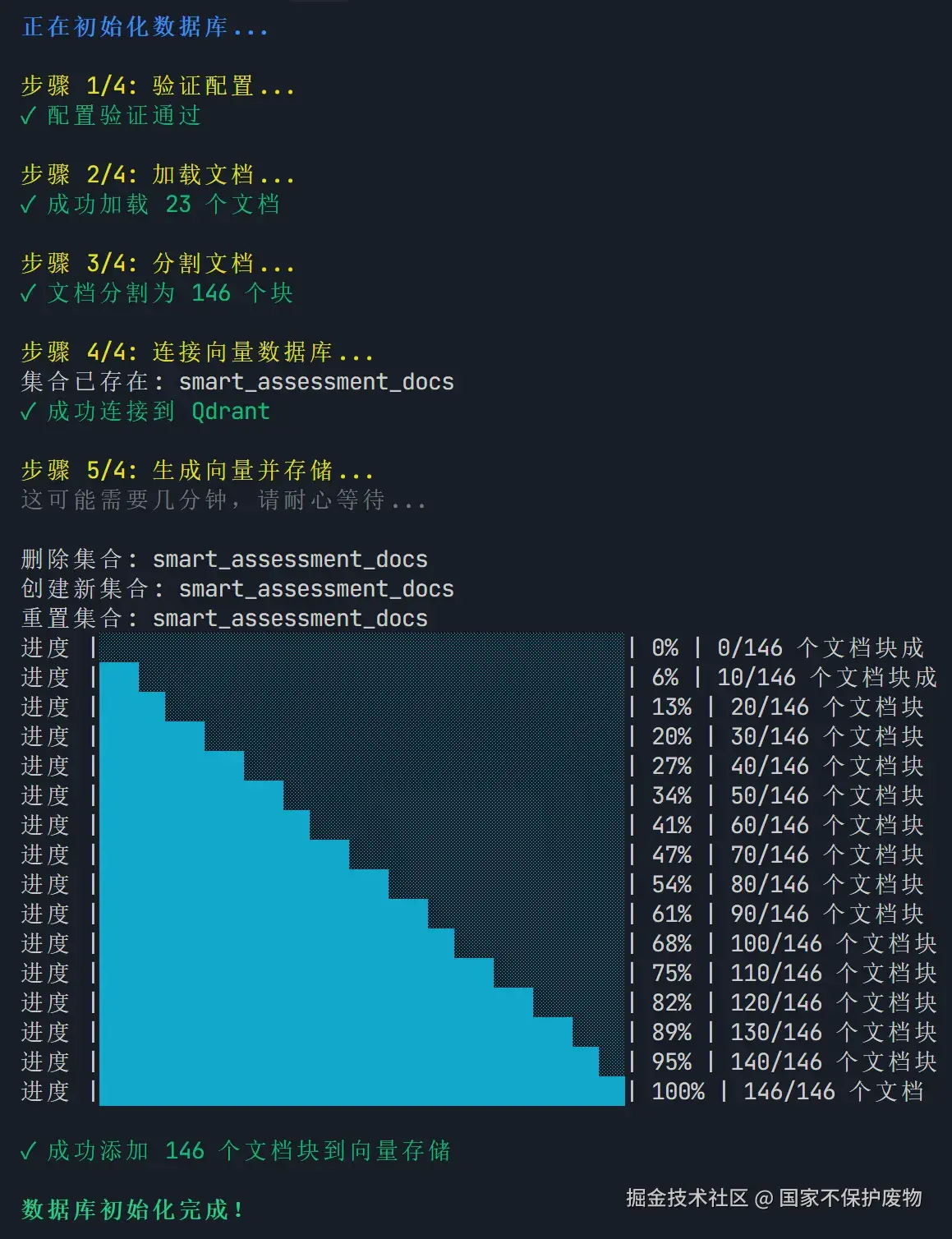
四、文档处理:从原始文件到向量存储
这是 RAG 效果好坏的关键!很多初学者直接把整篇文档丢进去,结果检索效果很差。正确的做法是 "分块 + 嵌入 + 存储" 。
步骤 1️⃣:加载文档(支持 Markdown)
我们设计了一个 DocumentLoader 类,专门用于递归扫描 docs/ 目录下的所有 .md 文件:
scss
// 递归查找所有 .md 文件
findMarkdownFiles(dirPath) {
const files = [];
const items = fs.readdirSync(dirPath);
for (const item of items) {
const itemPath = path.join(dirPath, item);
if (fs.statSync(itemPath).isDirectory()) {
files.push(...this.findMarkdownFiles(itemPath)); // 递归
} else if (path.extname(item) === '.md') {
files.push(itemPath);
}
}
return files;
}每个文档被封装为一个 Document 对象,包含:
content:文件全文metadata:来源路径、文件名、加载时间等
步骤 2️⃣:智能文本分割(重中之重!)
为什么不能整篇存?
因为大模型有上下文长度限制(如 8192 tokens),而且长文本嵌入会丢失局部语义。
我们使用 LangChain 的 RecursiveCharacterTextSplitter,并针对中文做了优化:
csharp
new RecursiveCharacterTextSplitter({
chunkSize: 500, // 每块约 500 字符
chunkOverlap: 50, // 相邻块重叠 50 字,避免断句
separators: [
'\n\n', // 优先按段落切
'\n',
'。', '!', '?', // 中文句号、感叹号、问号
';', ',', // 分号、逗号
' ', // 英文空格
'' // 最后按字符切
]
})🌟 效果示例 :
原文:"Qwen 是阿里巴巴推出的 AI 模型。它支持多语言。"
→ 切分为两块:
块1:"Qwen 是阿里巴巴推出的 AI 模型。"
块2:"它支持多语言。"
这样既能保持语义完整,又避免跨句切割。
步骤 3️⃣:向量化 & 存入 Qdrant
这一步由 QdrantVectorStore.addDocuments() 自动完成:
- 调用
embeddings.embedDocuments()生成向量 - 将
[向量, 文本, 元数据]作为"点(Point)"存入 Qdrant
整个过程对开发者透明,你只需传入 Document[] 即可。
五、国际化(i18n):让系统支持中英文切换
为了让项目更专业、更易用,我们加入了完整的多语言支持。
1. 技术选型:i18next + JSON 资源文件
- i18next:业界标准的 JS 国际化库
- JSON 文件:按语言分类存储翻译文本,结构清晰
目录结构:
bash
src/i18n/
├── index.js # 国际化管理器
└── locales/
├── en/translation.json
└── zh-CN/translation.json2. 核心:I18nManager 单例类
javascript
class I18nManager {
async init(language = 'en') {
await i18next.use(Backend).init({
lng: language,
fallbackLng: 'en',
backend: {
loadPath: './locales/{{lng}}/translation.json'
}
});
}
t(key, options = {}) {
return i18next.t(key, options); // 如 t('messages.loading_docs', { count: 5 })
}
getPreferredLanguage() {
// 1. 读取系统环境变量 LANG
// 2. 自动匹配支持的语言(如 zh_CN → zh-CN)
// 3. 默认回退到英文
}
}✅ 优势:
- 支持插值(如
{{count}})- 自动语言检测
- 未翻译时回退到英文
3. 翻译文件示例(zh-CN/translation.json)
json
{
"document_loader": {
"loading_all_docs": "正在加载所有文档...",
"loaded_doc": "已加载文档: {{path}}",
"error_loading_doc": "加载文档失败 {{path}}: {{error}}"
},
"text_splitter": {
"splitting_docs": "正在分割文档...",
"split_doc": "文档 {{path}} 已分割为 {{count}} 个块"
},
"vector_store": {
"creating_collection": "正在创建集合: {{name}}",
"collection_exists": "集合 {{name}} 已存在",
"adding_batch": "正在添加 {{count}} 个文档块..."
}
}4. 在代码中使用
less
// 初始化(自动检测系统语言)
await i18nManager.init(i18nManager.getPreferredLanguage());
// 打印日志
console.log(i18nManager.t('vector_store.adding_batch', { count: docs.length }));5. 命令行支持语言切换
sql
# 默认根据系统语言自动选择
npm run start
# 强制使用中文
npm run start -- -l zh-CN
# 强制使用英文
npm run start -- -l en效果展示:
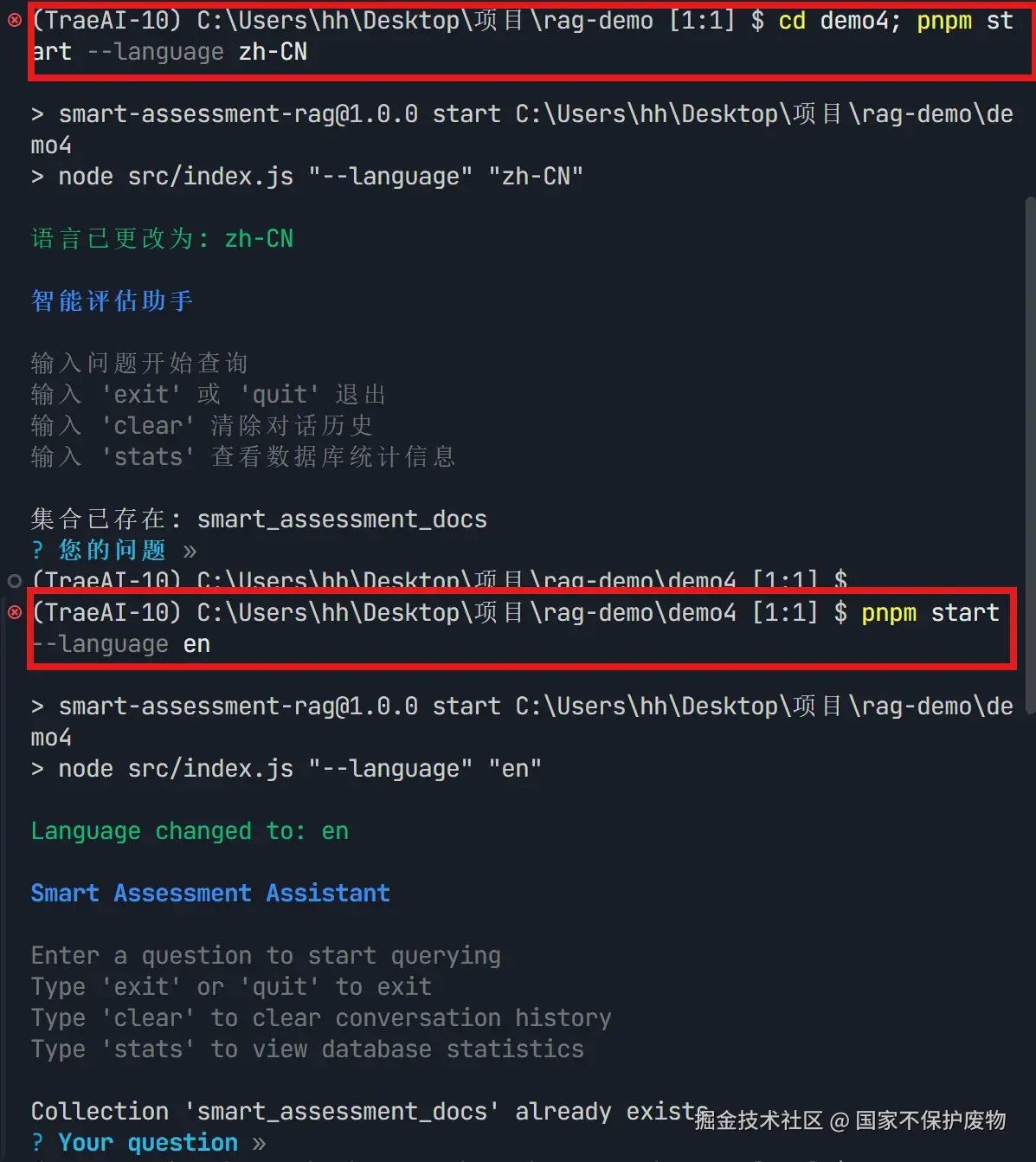
🌍 用户体验提升:非英语用户不再面对满屏英文报错,大大降低使用门槛。
六、完整流程:从零初始化到交互问答
整个系统启动流程如下:
- 验证配置 → 2. 加载文档 → 3. 智能分块 → 4. 连接 Qdrant → 5. 批量向量化存储
css
graph LR
A[验证配置] --> B[加载 docs/ 下所有 .md 文件]
B --> C[按语义分割为小块]
C --> D[连接 Qdrant]
D --> E[生成向量并存入]
E --> F[启动交互式问答]在问答阶段,用户输入问题后:
- 系统将问题向量化
- 在 Qdrant 中检索 Top-K 相似块
- 将结果 + 原始问题交给 LLM 生成答案
- 返回答案 + 来源引用(含相似度分数)
总结
本文我们完成了 RAG 系统的三大核心模块:
✅ 向量数据库搭建 :通过 Docker 快速部署 Qdrant,兼顾性能与便捷性
✅ 文档智能处理 :从加载、中文友好分块到向量化,确保检索质量
✅ 多语言支持:基于 i18next 实现中英文无缝切换,提升可用性
这些工作为后续的 Agent 决策、Prompt 优化、评估指标 等高级功能打下了坚实基础。(如果想看完整代码可到开头展示的代码仓库中查看,里面包含rag调用的完整代码)
📌 下期预告:我们将使用rag去做一个法律检索的专业ai问答助手,使用爬虫技术去完善我们的数据库,采用流式输出去展示我们的代码,将后端rag技术与前端页面结合起来。
附:常见问题
❓Q:为什么不用 FAISS?
→ FAISS 是纯向量库,无持久化、无过滤、无 API,适合实验;Qdrant 是完整数据库,适合产品。
❓Q:分块大小怎么选?
→ 中文建议 300--800 字符,英文 200--500 tokens。可通过 CHUNK_SIZE 配置调整。
❓Q:Qwen 的 embedding 维度是多少?
→ text-embedding-v2 输出 1536 维 ,务必在 config.EMBEDDING_DIMENSION 中正确设置!
希望这篇文章能帮你少走弯路,快速搭建出自己的 RAG 系统!欢迎点赞、收藏、评论交流 👇 ```