一、YOLOv8的突破性创新
YOLOv8作为Ultralytics在2023年初推出的目标检测模型,代表了YOLO系列的又一次重大飞跃。这一版本并非简单的增量更新,而是在多个维度上实现了质的突破,为计算机视觉领域带来了全新的技术范式。
1. 技术背景与发展动机
在YOLOv5取得巨大成功后,研究团队面临着新的挑战:如何在保持实时性的同时进一步提升检测精度?传统的基于锚框的检测方法虽然成熟,但在处理复杂场景时存在局限性。YOLOv8的诞生正是为了解决这些痛点,通过架构重新设计和算法创新,实现了精度与速度的完美平衡。
2. 核心技术革新
YOLOv8最引人注目的创新在于其无锚框设计理念的全面采用。这种设计摒弃了传统的预设锚框机制,转而采用动态目标表示方法,使模型能够更灵活地适应不同尺度和形状的目标。
python
# YOLOv8检测头的核心实现
class DetectionHead(nn.Module):
def __init__(self, nc=80, ch=()):
super().__init__()
self.nc = nc # 类别数
self.reg_max = 16 # 回归最大值
# 分类和回归分支
self.cv2 = nn.ModuleList([nn.Conv2d(x, 4 * self.reg_max, 1) for x in ch])
self.cv3 = nn.ModuleList([nn.Conv2d(x, self.nc, 1) for x in ch])
def forward(self, x):
shape = x[0].shape
for i in range(len(x)):
x[i] = torch.cat((self.cv2[i](x[i]), self.cv3[i](x[i])), 1)
return x上述代码展示了YOLOv8检测头的基本结构,通过将分类和回归任务完全分离,模型能够更专注地处理各自的特定任务,从而提升整体性能。
二、架构设计的深度剖析
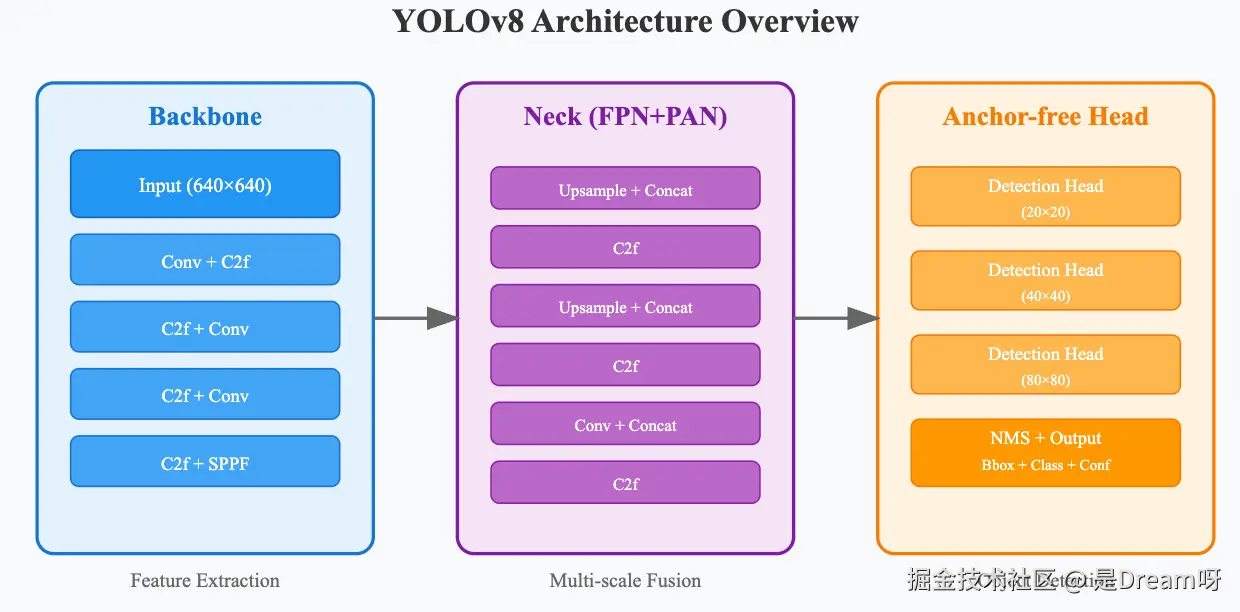
1. 骨干网络的演进
YOLOv8的骨干网络采用了改进的CSPDarknet架构,这种设计不仅保持了原有的特征提取能力,还通过引入更多的残差连接和特征重用机制,显著提升了网络的表达能力。
网络设计的关键在于平衡计算效率和特征丰富性。通过精心设计的卷积块组合,模型能够在不同层级提取到从细粒度纹理到高级语义的多层次特征。这种多尺度特征提取策略为后续的目标检测提供了坚实的基础。
2. 特征金字塔网络的优化
YOLOv8在特征融合方面采用了增强版的PAN(Path Aggregation Network)结构,这种设计能够更好地处理不同尺度目标之间的信息传递。
python
class C2f(nn.Module):
"""CSP Bottleneck with 2 convolutions"""
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1)
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x):
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))这个C2f模块是YOLOv8特征提取的核心组件,通过多分支结构和梯度流优化,实现了更高效的特征学习。
3. 无锚框检测头的设计哲学
传统的基于锚框的检测方法需要预先定义大量的候选框,这不仅增加了计算复杂度,还可能导致正负样本不平衡的问题。YOLOv8的无锚框设计通过直接回归目标的中心点和边界框参数,实现了更直接、更高效的检测方式。
这种设计的核心思想是将每个网格点视为潜在的目标中心,通过学习偏移量和尺度信息来定位目标。这种方法不仅简化了后处理流程,还提升了检测的精度,特别是在密集目标场景下表现更为出色。
三、多任务统一框架的构建
1. 任务多样性的支持
YOLOv8最令人印象深刻的特点之一是其对多种视觉任务的统一支持。从基础的目标检测到复杂的实例分割,从人体姿态估计到有向目标检测,YOLOv8通过模块化设计实现了一套代码支持多种任务的目标。
这种设计理念的实现依赖于共享的特征提取器和任务特定的输出头。共享的骨干网络负责提取通用的视觉特征,而不同的输出头则针对特定任务进行优化。这种架构不仅提高了开发效率,还通过多任务学习的方式增强了模型的泛化能力。
2. 实例分割的技术实现
在实例分割任务中,YOLOv8采用了掩码分支设计,通过在检测头的基础上增加分割预测模块,实现像素级的目标分割。
python
class SegmentationHead(DetectionHead):
def __init__(self, nc=80, nm=32, npr=256, ch=()):
super().__init__(nc, ch)
self.nm = nm # 掩码数量
self.npr = npr # 原型数量
# 掩码分支
self.cv4 = nn.ModuleList([nn.Conv2d(x, self.nm, 1) for x in ch])
self.proto = Proto(ch[0], self.npr, self.nm)
def forward(self, x):
p = self.proto(x[0]) # 掩码原型
bs = p.shape[0]
for i in range(len(x)):
x[i] = torch.cat([
self.cv2[i](x[i]), # 回归分支
self.cv3[i](x[i]), # 分类分支
self.cv4[i](x[i]) # 掩码分支
], 1)
return (x, p) if self.training else (x, p)这种设计通过原型掩码的方式,将复杂的像素级分割问题转化为相对简单的掩码系数回归问题,既保证了分割质量,又维持了推理速度。
3. 姿态估计的关键点检测
在人体姿态估计任务中,YOLOv8通过关键点回归的方式实现人体骨架的检测。模型不仅需要定位人体目标,还需要准确预测关键关节点的位置,这对特征表示能力提出了更高的要求。
四、训练策略与优化技术
1. 损失函数的精心设计
YOLOv8在损失函数设计上采用了多项创新,包括改进的IoU损失、焦点损失变种以及任务自适应权重机制。这些改进使模型能够更好地处理困难样本和类别不平衡问题。
python
class YOLOLoss:
def __init__(self):
self.bce = nn.BCEWithLogitsLoss(reduction='none')
self.stride = None # 模型步长
self.nc = None # 类别数
def __call__(self, preds, targets):
loss = torch.zeros(3, device=targets.device)
feats = preds[1] if isinstance(preds, tuple) else preds
# 分类损失
loss[0] = self.bce(preds_cls, targets_cls).sum()
# 回归损失(IoU损失)
loss[1] = self.iou_loss(preds_box, targets_box)
# 分布式焦点损失
loss[2] = self.dfl_loss(preds_dfl, targets_dfl)
return loss.sum() * batch_size, loss.detach()这种多组件损失设计确保了模型在各个子任务上都能获得充分的监督信号。
2. 数据增强策略的革新
YOLOv8引入了更加智能的数据增强策略,包括自适应锚框缩放、多尺度训练以及混合精度优化。这些技术的综合应用显著提升了模型的鲁棒性和泛化能力。
动态数据增强是其中的亮点,模型能够根据训练进度自动调整增强强度,在训练早期使用强增强来提高泛化能力,在训练后期使用弱增强来稳定收敛。
3. 高效训练的实现机制
为了支持快速迭代和实验,YOLOv8在训练效率方面做了大量优化。包括梯度累积、动态批次大小调整以及智能学习率调度等技术,这些改进使得在有限的计算资源下也能训练出高质量的模型。
五、性能分析与基准测试
1. 精度性能的全面评估
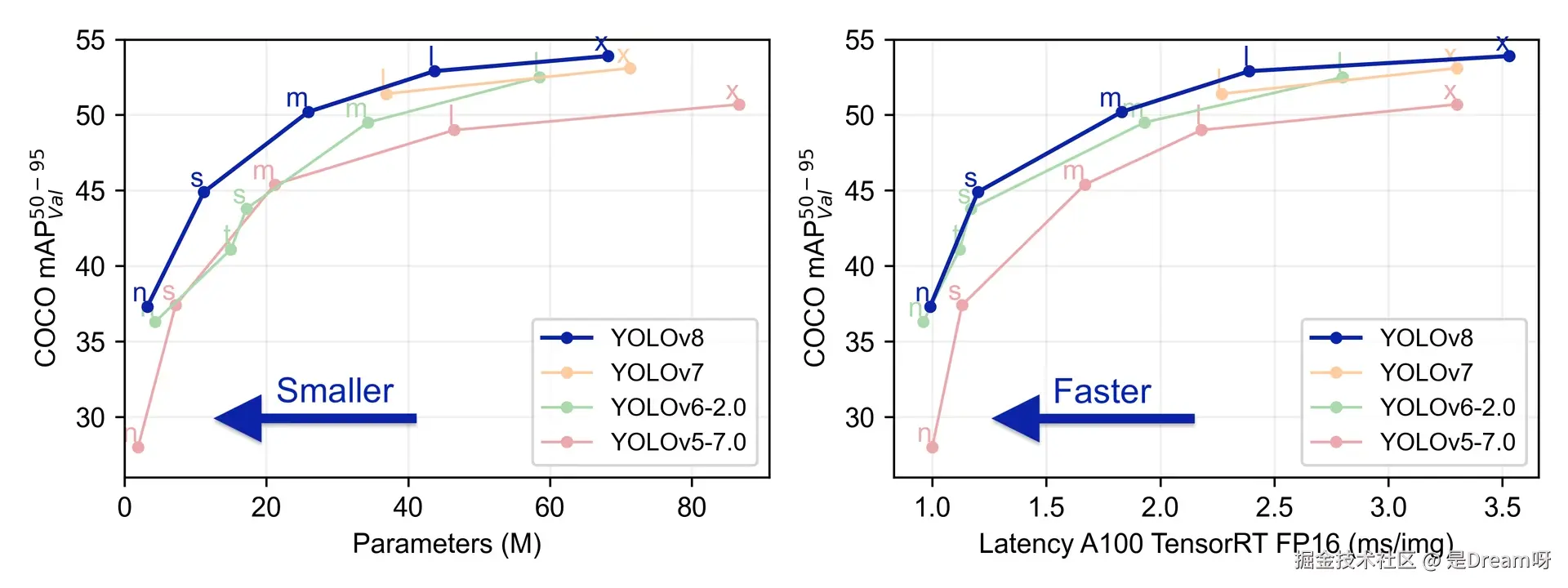
在COCO数据集上的测试结果显示,YOLOv8在各个尺度上都实现了显著的性能提升。从轻量级的YOLOv8n到高精度的YOLOv8x,模型系列覆盖了从移动端到服务器端的各种应用场景。
特别值得注意的是,YOLOv8n在保持极小模型尺寸的同时,实现了37.3%的mAP@50-95,这一成绩在同等规模的模型中堪称优秀。而YOLOv8x则达到了53.9%的mAP@50-95,在精度上与当时的最先进方法相媲美。 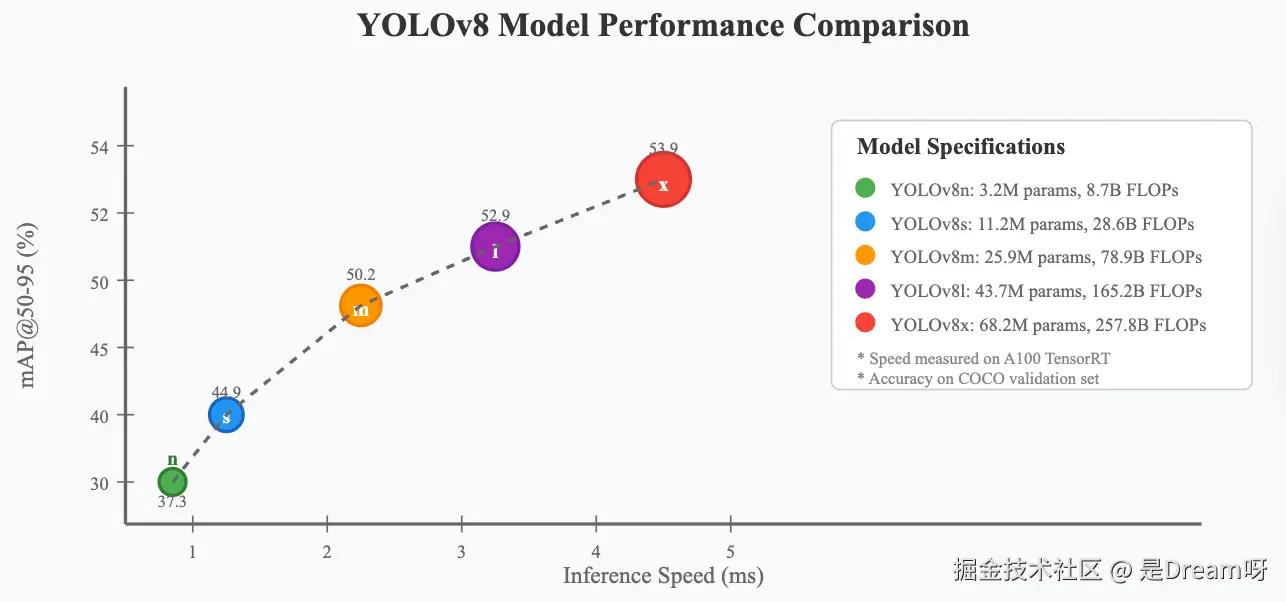
2. 速度性能的深度分析
在推理速度方面,YOLOv8展现出了卓越的性能。通过优化的网络结构和高效的后处理算法,模型在各种硬件平台上都能实现实时推理。特别是在GPU加速环境下,YOLOv8s仅需1.2ms就能完成一次前向推理,这为实时应用提供了强有力的支撑。
YOLO 的三个版本(v5、v7 和 v8)都表现出良好的性能。然而,根据我们的测试,YOLO v8 在这三个版本中似乎性能最佳。与 YOLO v5 相比,它在 COCO 数据集上提升了所有变体的 mAP,同时在 Orin 和 RTX 4070 Ti 上达到了相似的运行时间。如果你正在寻找一个快速可靠的物体检测框架,YOLO v8 可能是你的最佳选择。
六、实际应用与部署实践
1. 工业场景的应用案例
在工业质量检测领域,YOLOv8的高精度和实时性使其成为理想的解决方案。通过针对特定产品的微调,模型能够准确识别各种缺陷类型,为自动化质量控制提供了有力支撑。
python
# 工业检测的模型加载和推理
from ultralytics import YOLO
# 加载预训练模型
model = YOLO('yolov8n.pt')
# 针对工业数据进行微调
model.train(data='industrial_defect.yaml',
epochs=100,
imgsz=640,
batch=16)
# 部署推理
results = model.predict('production_line_image.jpg',
conf=0.25,
iou=0.45)这种简洁的API设计使得模型的部署和使用变得极其便利。
2. 移动端优化与部署
针对移动端应用的需求,YOLOv8提供了多种模型压缩和优化技术。通过量化、剪枝和知识蒸馏等方法,可以进一步减小模型尺寸并提升推理速度,使其能够在资源受限的设备上稳定运行。
3. 边缘计算的适配策略
在边缘计算场景下,YOLOv8展现出了良好的适应性。通过与TensorRT、ONNX等推理引擎的深度集成,模型能够充分利用硬件加速特性,实现最优的推理性能。
总结
YOLOv8作为YOLO系列的最新力作,通过在架构设计、训练策略和应用框架等多个维度的创新,实现了目标检测技术的又一次飞跃。其无锚框设计理念、多任务统一框架以及高效的推理性能,不仅推动了学术研究的进步,也为工业应用提供了更加强大的工具。
随着技术的不断演进和应用场景的不断拓展,YOLOv8必将在计算机视觉的历史进程中留下浓墨重彩的一笔。对于研究人员和工程师而言,深入理解YOLOv8的设计理念和技术细节,不仅有助于更好地应用这一技术,也为未来的创新研究提供了宝贵的借鉴和启发。